 電子發(fā)燒友App
電子發(fā)燒友App


列式存儲(chǔ)(Column-oriented Storage)并不是一項(xiàng)新技術(shù),最早可以追溯到 1983 年的論文 Cantor。然而,受限于早期的硬件條件和使用場(chǎng)景,主流的事務(wù)型數(shù)據(jù)庫(kù)(OLTP)大多采用行式存儲(chǔ),直到近幾年分析型數(shù)據(jù)庫(kù)(OLAP)的興起,列式存儲(chǔ)這一概念又變得流行。
總的來(lái)說(shuō),列式存儲(chǔ)的優(yōu)勢(shì)一方面體現(xiàn)在存儲(chǔ)上能節(jié)約空間、減少 IO,另一方面依靠列式數(shù)據(jù)結(jié)構(gòu)做了計(jì)算上的優(yōu)化。本文將著重介紹列式存儲(chǔ)的數(shù)據(jù)組織方式,包括數(shù)據(jù)的布局、編碼、壓縮等。
一、什么是列式存儲(chǔ)
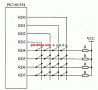
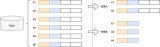
傳統(tǒng) OLTP 數(shù)據(jù)庫(kù)通常采用行式存儲(chǔ)。以下圖為例,所有的列依次排列構(gòu)成一行,以行為單位存儲(chǔ),再配合以 B+ 樹(shù)或 SS-Table 作為索引,就能快速通過(guò)主鍵找到相應(yīng)的行數(shù)據(jù):
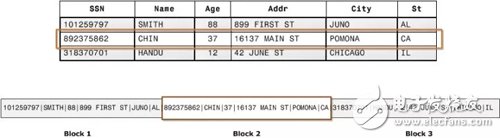
行式存儲(chǔ)對(duì)于 OLTP 場(chǎng)景是很自然的:大多數(shù)操作都以實(shí)體(Entity)為單位,即大多為增刪改查一整行記錄,顯然把一行數(shù)據(jù)存在物理上相鄰的位置是個(gè)很好的選擇。
然而,對(duì)于 OLAP 場(chǎng)景,一個(gè)典型的查詢需要遍歷整個(gè)表,進(jìn)行分組、排序、聚合等操作,這樣一來(lái)按行存儲(chǔ)的優(yōu)勢(shì)就不復(fù)存在了。更糟糕的是,分析型 SQL 常常不會(huì)用到所有的列,而僅僅對(duì)其中某些感興趣的列做運(yùn)算,那一行中無(wú)關(guān)的列也不得不參與掃描。
列式存儲(chǔ)就是為這樣的需求設(shè)計(jì)的。如下圖所示,同一列的數(shù)據(jù)被一個(gè)接一個(gè)緊挨著存放在一起,表的每列構(gòu)成一個(gè)長(zhǎng)數(shù)組:
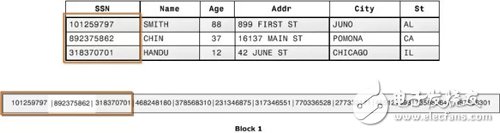
顯然,列式存儲(chǔ)對(duì)于 OLTP 不友好,一行數(shù)據(jù)的寫(xiě)入需要同時(shí)修改多個(gè)列。但對(duì) OLAP 場(chǎng)景有著很大的優(yōu)勢(shì):
當(dāng)查詢語(yǔ)句只涉及部分列時(shí),只需要掃描相關(guān)的列
每一列的數(shù)據(jù)都是相同類型的,彼此間相關(guān)性更大,對(duì)列數(shù)據(jù)壓縮的效率較高
小貼士:
BigTable(HBase)是列式存儲(chǔ)嗎?
很多文章將 BigTable 歸為列式存儲(chǔ)。但嚴(yán)格地說(shuō),BigTable 并非列式存儲(chǔ),雖然論文中提到借鑒了 C-Store 等列式存儲(chǔ)的某些設(shè)計(jì),但 BigTable 本身按 Key-Value Pair 存儲(chǔ)數(shù)據(jù),和列式存儲(chǔ)并無(wú)關(guān)系。
有一點(diǎn)迷惑的是 BigTable 的列簇(Column Family)概念,列簇可以被指定給某個(gè) Locality Group,決定了該列簇?cái)?shù)據(jù)的物理位置,從而可以讓同一主鍵的各個(gè)列簇分別存放在最優(yōu)的物理節(jié)點(diǎn)上。由于 Column Family 內(nèi)的數(shù)據(jù)通常具有相似性,對(duì)它做壓縮要比對(duì)整個(gè)表壓縮效果更好。
另外,值得強(qiáng)調(diào)的一點(diǎn)是:列式數(shù)據(jù)庫(kù)可以是關(guān)系型、也可以是 NoSQL,這和是否是列式并無(wú)關(guān)系。本文中討論的 C-Store 就采用了關(guān)系模型。
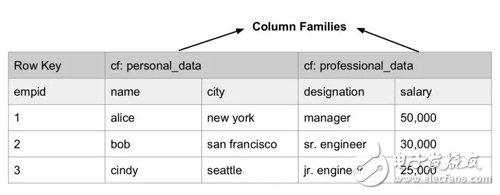
Column Families in BigTable
二、起源:DSM 分頁(yè)模式
我們知道,由于機(jī)械磁盤(pán)受限于磁頭尋址過(guò)程,讀寫(xiě)通常都以一塊(Block)為單位,故在操作系統(tǒng)中被抽象為塊設(shè)備,與流設(shè)備相對(duì)。這能幫助上層應(yīng)用更好地管理儲(chǔ)存空間、增加讀寫(xiě)效率等。
這一特性直接影響了數(shù)據(jù)庫(kù)儲(chǔ)存格式的設(shè)計(jì):數(shù)據(jù)庫(kù)的 Page 對(duì)應(yīng)一個(gè)或幾個(gè)物理扇區(qū),讓數(shù)據(jù)庫(kù)的 Page 和扇區(qū)對(duì)齊,提升讀寫(xiě)效率。
那如何將數(shù)據(jù)存放到頁(yè)上呢?
大多數(shù)服務(wù)于在線查詢的 DBMS 采用 NSM (N-ary Storage Model),即按行存儲(chǔ)的方式,將完整的行(即關(guān)系 relation)從 Header 開(kāi)始依次存放。頁(yè)的最后有一個(gè)索引,存放了頁(yè)內(nèi)各行的起始偏移量。由于每行長(zhǎng)度不一定是固定的,索引可以幫助我們快速找到需要的行,而無(wú)需逐個(gè)掃描。
NSM 的缺點(diǎn)在于:如果每次查詢只涉及很小的一部分列,那多余的列依然要占用掉寶貴的內(nèi)存以及 CPU Cache,從而導(dǎo)致更多的 IO。為了避免這一問(wèn)題,很多分析型數(shù)據(jù)庫(kù)采用 DSM(Decomposition Storage Model),即按列分頁(yè):將 Relation 按列拆分成多個(gè) Sub-relation。類似的,頁(yè)的尾部存放了一個(gè)索引:
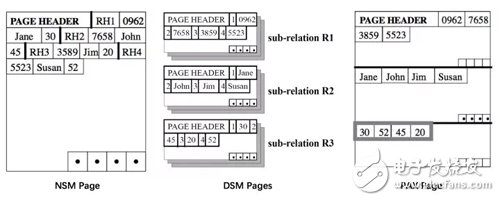
順便一提,2001 年 Ailamaki 等人提出 PAX (Partition Attributes Cross) 格式,嘗試將 DSM 的一些優(yōu)點(diǎn)引入 NSM,將兩者的優(yōu)點(diǎn)相結(jié)合。
具體來(lái)說(shuō),NSM 能更快速地取出一行記錄,這是因?yàn)橐恍械臄?shù)據(jù)相鄰,保存在同一頁(yè);DSM 能更好地利用 CPU Cache 以及使用更緊湊的壓縮。PAX 的做法是將一個(gè)頁(yè)劃分成多個(gè) Minipage,Minipage 內(nèi)按列存儲(chǔ),而一頁(yè)中的各個(gè) Minipage 能組合成完整的若干 Relation。
如今,隨著分布式文件系統(tǒng)的普及和磁盤(pán)性能的提高,很多先進(jìn)的 DBMS 已經(jīng)拋棄了按頁(yè)存儲(chǔ)的模式。但是其中的某些思想,例如數(shù)據(jù)分區(qū)、分區(qū)內(nèi)索引、行列混合等,仍然處處可見(jiàn)于這些現(xiàn)代的系統(tǒng)中。
分布式儲(chǔ)存系統(tǒng)雖然不再有頁(yè)的概念,但是仍然會(huì)將文件切割成分塊進(jìn)行儲(chǔ)存,但分塊的粒度要遠(yuǎn)遠(yuǎn)大于一般扇區(qū)的大小(如 HDFS 的 Block Size 一般是128MB)。更大的讀寫(xiě)粒度是為了適應(yīng)網(wǎng)絡(luò) IO 更低的帶寬以獲得更大的吞吐量,但另一方面也犧牲了細(xì)粒度隨機(jī)讀寫(xiě)。
三、列數(shù)據(jù)的編碼與壓縮
無(wú)論對(duì)于磁盤(pán)還是內(nèi)存數(shù)據(jù)庫(kù),IO 相對(duì)于 CPU 通常都是系統(tǒng)的性能瓶頸,合理的壓縮手段不僅能節(jié)省空間,也能減少 IO 、提高讀取性能。列式存儲(chǔ)在數(shù)據(jù)編碼和壓縮上具有天然的優(yōu)勢(shì)。
以下介紹的是 C-Store 中的數(shù)據(jù)編碼方式,具有一定的代表性。
根據(jù):數(shù)據(jù)本身是否按順序排列(Self-Order)以及數(shù)據(jù)有多少不同的取值(Distinct Values),我們分成以下 4 種情況討論:
有序且Distinct值不多。使用一系列的三元組(v,f,n)對(duì)列數(shù)據(jù)編碼,表示數(shù)值v從第f行出現(xiàn),一共有n個(gè)(即f到f+n?1行)。例如:數(shù)值4出現(xiàn)在12-18行,則編碼為 (4,12,7)。
無(wú)序且Distinct值不多。對(duì)于每個(gè)取值v構(gòu)造一個(gè)二進(jìn)制串b,表示v所在位置的Bitmap。例如:如果一列的數(shù)據(jù)是0,0,1,1,2,1,0,2,1,則編碼為(0,110000100)、(1,001101001)和(2,000010010)。由于Bitmap是稀疏的,可以對(duì)其再進(jìn)行行程編碼。
有序且Distinct值多。對(duì)于這種情況,把每個(gè)數(shù)值表示為前一個(gè)數(shù)值加上一個(gè)變化量(Delta),當(dāng)然第一個(gè)數(shù)值除外。例如,對(duì)于一列數(shù)據(jù)1,4,7,7,8,12,可以表示為序列1,3,3,0,1,4。顯然編碼后的數(shù)據(jù)更容易被Dense Pack,且壓縮比更高。
無(wú)序且Distinct值多。對(duì)于這種情況沒(méi)有很好的編碼方式。
編碼之后,還可以對(duì)數(shù)據(jù)進(jìn)行壓縮。由于一列的數(shù)據(jù)本身具有相似性,即使不做特殊編碼,也能取得相對(duì)較好的壓縮效果。通常采用 Snappy 等支持流式處理、吞吐量高的壓縮算法。
最后,編碼和壓縮不僅是節(jié)約空間的手段,更多時(shí)候也是組織數(shù)據(jù)的手段。在 PowerDrill、Dremel 等系統(tǒng)中,我們會(huì)看到很多編碼本身也兼具了索引的功能,例如在掃描中跳過(guò)不需要的分區(qū),甚至完全改表查詢執(zhí)行的方式。
四、列式存儲(chǔ)與分布式文件系統(tǒng)
在現(xiàn)代的大數(shù)據(jù)架構(gòu)中,GFS、HDFS 等分布式文件系統(tǒng)已經(jīng)成為存放大規(guī)模數(shù)據(jù)集的主流方式。分布式文件系統(tǒng)相比單機(jī)上的磁盤(pán),具備多副本高可用、容量大、成本低等諸多優(yōu)勢(shì),但也帶來(lái)了一些單機(jī)架構(gòu)所沒(méi)有的問(wèn)題:
讀寫(xiě)均要經(jīng)過(guò)網(wǎng)絡(luò),吞吐量可以追平甚至超過(guò)硬盤(pán),但是延遲卻要比硬盤(pán)大得多,且受網(wǎng)絡(luò)環(huán)境影響很大;
可以進(jìn)行大吞吐量的順序讀寫(xiě),但隨機(jī)訪問(wèn)性能很差,大多不支持隨機(jī)寫(xiě)入。為了抵消網(wǎng)絡(luò)的 Overhead,通常寫(xiě)入都以幾十MB為單位。
上述缺點(diǎn)對(duì)于重度依賴隨機(jī)讀寫(xiě)的 OLTP 場(chǎng)景來(lái)說(shuō)是致命的。所以我們看到,很多定位于 OLAP 的列式存儲(chǔ)選擇放棄 OLTP 能力,從而能構(gòu)建在分布式文件系統(tǒng)之上。
要想將分布式文件系統(tǒng)的性能發(fā)揮到極致,無(wú)非有幾種方法:按塊(分片)讀取數(shù)據(jù)、流式讀取、追加寫(xiě)入等。我們?cè)诤竺鏁?huì)看到一些開(kāi)源界流行的列式存儲(chǔ)模型,將這些優(yōu)化方法體現(xiàn)在存儲(chǔ)格式的設(shè)計(jì)中。
五、列式存儲(chǔ)系統(tǒng)案例
1、C-Store (2005) / Vertica
大多數(shù) DBMS 都是為了寫(xiě)優(yōu)化,而 C-Store 是第一個(gè)為了讀優(yōu)化的 OLTP 數(shù)據(jù)庫(kù)系統(tǒng),雖然從今天的視角看它應(yīng)當(dāng)算作 HTAP 。在 Ad-Hoc 的分析型查詢、ORM 的在線查詢等場(chǎng)景中,大多數(shù)操作都是查詢而非寫(xiě)入,在這些場(chǎng)景中列式存儲(chǔ)能取得更好的性能。像主流的 DBMS 一樣,C-Store 支持標(biāo)準(zhǔn)的關(guān)系型模型。
就像本文開(kāi)頭即提到——列式存儲(chǔ)不是新鮮事。C-Store 的主要貢獻(xiàn)有以下幾點(diǎn):
通過(guò)精心設(shè)計(jì)的 Projection 同時(shí)實(shí)現(xiàn)列數(shù)據(jù)的多副本和多種索引方式;
用讀寫(xiě)分層的方式兼顧了(少量)寫(xiě)入的性能;
此外,C-Store 可能是第一個(gè)現(xiàn)代的列式存儲(chǔ)數(shù)據(jù)庫(kù)實(shí)現(xiàn),其設(shè)計(jì)啟發(fā)了無(wú)數(shù)后來(lái)的商業(yè)或開(kāi)源數(shù)據(jù)庫(kù),就比如 Vertica。
數(shù)據(jù)模型
C-Store 是關(guān)系型數(shù)據(jù)庫(kù),它的邏輯表和其他數(shù)據(jù)庫(kù)中的并沒(méi)有什么不同。但是在 C-Store 內(nèi)部,邏輯表被縱向拆分成 Projections,每個(gè) Projection 可以包含一個(gè)或多個(gè)列,甚至可以包含來(lái)自其他邏輯表的列(構(gòu)成索引)。當(dāng)然,每個(gè)列至少會(huì)存在于一個(gè) Projection 上。
下圖的例子中,EMP 表被存儲(chǔ)為 3 個(gè) Projections,DEPT 被存儲(chǔ)為 1 個(gè) Projection。每個(gè) Projection 按照各自的 Sort key 排序,在圖中用下劃線表示 Sort key。
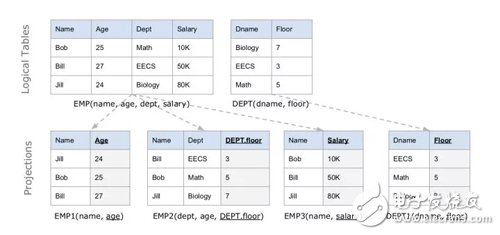
Projection 內(nèi)是以列式存儲(chǔ)的:里面的每個(gè)列分別用一個(gè)數(shù)據(jù)結(jié)構(gòu)存放。為了避免列太長(zhǎng)引起問(wèn)題,也支持每個(gè) Projection 以 Sort key 的值做橫向切分。
查詢時(shí) C-Store 會(huì)先選擇一組能覆蓋結(jié)果中所有列的 Projections 集合作為 Covering set,然后進(jìn)行 Join 計(jì)算重構(gòu)出原來(lái)的行。為了能高效地進(jìn)行 Projections 的 Join(即按照另一個(gè) Key 重新排序),引入 Join Index 作為輔助,其中存儲(chǔ)了 Proj1 到 Proj2 的下標(biāo)映射關(guān)系。
Projection 是有冗余性的,常常 1 個(gè)列會(huì)出現(xiàn)在多個(gè) Projections 中,但是它們的順序也就是 Sort key 并不相同,因此 C-Store 在查詢時(shí)可以選用最優(yōu)的一組 Projections,使得查詢執(zhí)行的代價(jià)最小。
巧妙的是,C-Store 的 Projection 冗余性還用來(lái)實(shí)現(xiàn) K-safe 高可用(容忍最多 K 臺(tái)機(jī)器故障),當(dāng)部分節(jié)點(diǎn)宕機(jī)時(shí),只要 C-Store 還能找到某個(gè) Covering set 就能執(zhí)行查詢,雖然不一定是最優(yōu)的 Covering set 組合。
從另一個(gè)角度看,C-Store 的 Projection 可以看作是一種物化(Materialized)的查詢結(jié)果,即查詢結(jié)果在查詢執(zhí)行前已經(jīng)被預(yù)先計(jì)算好。并且由于每個(gè)列至少出現(xiàn)在一個(gè) Projection 當(dāng)中,沒(méi)有必要再保存原來(lái)的邏輯表。
為任意查詢預(yù)先計(jì)算好結(jié)果顯然不現(xiàn)實(shí),但是如果物化某些經(jīng)常用到的中間視圖,就能在預(yù)計(jì)算代價(jià)和查詢代價(jià)之間獲得一個(gè)平衡。C-Store 物化的正是以某個(gè) Sort key 排好序(甚至 JOIN 了其他表)的一組列數(shù)據(jù),同時(shí)預(yù)計(jì)算的還有 Join Index。
2、Apache ORC
Apache ORC 最初是為支持 Hive 上的 OLAP 查詢開(kāi)發(fā)的一種文件格式,如今在 Hadoop 生態(tài)系統(tǒng)中有廣泛的應(yīng)用。ORC 支持各種格式的字段,包括常見(jiàn)的 Int、String 等,也包括 Struct、List、Map 等組合字段,字段的 meta 信息就放在 ORC 文件的尾部(這被稱為自描述的)。
數(shù)據(jù)結(jié)構(gòu)及索引
為分區(qū)構(gòu)造索引是一種常見(jiàn)的優(yōu)化方案,ORC 的數(shù)據(jù)結(jié)構(gòu)分成以下 3 個(gè)層級(jí),在每個(gè)層級(jí)上都有索引信息來(lái)加速查詢:
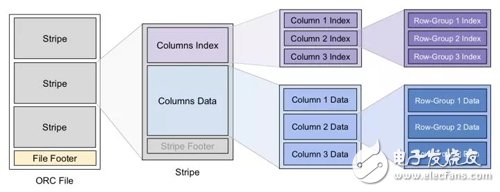
File Level:即一個(gè) ORC 文件,F(xiàn)ooter 中保存了數(shù)據(jù)的 meta 信息,還有文件數(shù)據(jù)的索引信息,例如各列數(shù)據(jù)的最大最小值(范圍)、NULL 值分布、布隆過(guò)濾器等,這些信息可用來(lái)快速確定該文件是否包含要查詢的數(shù)據(jù)。每個(gè) ORC 文件中包含多個(gè) Stripe。
Stripe Level:對(duì)應(yīng)原表的一個(gè)范圍分區(qū),里面包含該分區(qū)內(nèi)各列的值。每個(gè) Stripe 也有自己的一個(gè)索引放在 Footer 里,和 File-Level 索引類似。
Row-Group Level :一列中的每 10000 行數(shù)據(jù)構(gòu)成一個(gè) Row-Group,每個(gè) Row-Group 擁有自己的 Row-Level 索引,信息同上。
ORC 里的 Stripe 就像傳統(tǒng)數(shù)據(jù)庫(kù)的頁(yè),它是 ORC 文件批量讀寫(xiě)的基本單位。這是由于分布式儲(chǔ)存系統(tǒng)的讀寫(xiě)延遲較大,一次 IO 操作只有批量讀取一定量的數(shù)據(jù)才劃算。這和按頁(yè)讀寫(xiě)磁盤(pán)的思路也有共通之處。
像其他很多儲(chǔ)存格式一樣,ORC 選擇將統(tǒng)計(jì)數(shù)據(jù)和 Metadata 放在 File 和 Stripe 的尾部而不是頭部。
但 ORC 在 Stripe 的讀寫(xiě)上還有一點(diǎn)優(yōu)化,那就是把分區(qū)粒度小于 Stripe 的結(jié)構(gòu)(如 Column 和 Row-Group)的索引統(tǒng)一抽取出來(lái)放到 Stripe 的頭部。這是因?yàn)樵谂幚碛?jì)算中一般是把整個(gè) Stripe 讀入批量處理的,將這些索引抽取出來(lái)可以減少在批處理場(chǎng)景下需要的 IO(批處理讀取可以跳過(guò)這一部分)。
ACID 支持
Apache ORC 提供有限的 ACID 事務(wù)支持。受限于分布式文件系統(tǒng)的特點(diǎn),文件不能隨機(jī)寫(xiě),那如何把修改保存下來(lái)呢?
類似于 LSM-Tree 中的 MVCC 那樣,Writer 并不是直接修改數(shù)據(jù),而是為每個(gè)事務(wù)生成一個(gè) Delta 文件,文件中的修改被疊加在原始數(shù)據(jù)之上。當(dāng) Delta 文件越來(lái)越多時(shí),通過(guò) Minor Compaction 把連續(xù)多個(gè) Delta 文件合成一個(gè);當(dāng) Delta 變得很大時(shí),再執(zhí)行 Major Compaction 將Delta 和原始數(shù)據(jù)合并。
這種保持基線數(shù)據(jù)不變、分層疊加 Delta 數(shù)據(jù)的優(yōu)化方式在列式存儲(chǔ)系統(tǒng)中十分常見(jiàn),是一種通用的解決思路。
別忘了 ORC 的 Delta 文件也是寫(xiě)入到分布式儲(chǔ)存中的,因此每個(gè) Delta 文件的內(nèi)容不宜過(guò)短。這也解釋了 ORC 文件雖然支持事務(wù),但主要是對(duì)批量寫(xiě)入的事務(wù)比較友好,不適合頻繁且細(xì)小地寫(xiě)入事務(wù)的原因。
3、Dremel (2010) / Apache Parquet
Dremel 是 Google 研發(fā)的用于大規(guī)模只讀數(shù)據(jù)的查詢系統(tǒng),用于進(jìn)行快速的 Ad-Hoc 查詢,彌補(bǔ) MapReduce 交互式查詢能力的不足。為了避免對(duì)數(shù)據(jù)的二次拷貝,Dremel 的數(shù)據(jù)就放在原處,通常是 GFS 這樣的分布式文件系統(tǒng),為此需要設(shè)計(jì)一種通用的文件格式。
Dremel 的系統(tǒng)設(shè)計(jì)和大多 OLAP 的列式數(shù)據(jù)庫(kù)相比,并無(wú)太多創(chuàng)新點(diǎn),但是其精巧的存儲(chǔ)格式卻變得流行起來(lái),Apache Parquet 就是它的開(kāi)源復(fù)刻版。要注意的是,Parquet 和 ORC 一樣都是一種存儲(chǔ)格式,而非完整的系統(tǒng)。
嵌套數(shù)據(jù)模型
Google 內(nèi)部大量使用 Protobuf 作為跨平臺(tái)、跨語(yǔ)言的數(shù)據(jù)序列化格式,相比 JSON 要更緊湊并具有更強(qiáng)的表達(dá)能力。Protobuf 不僅允許用戶定義必須(Required)和可選(Optinal)字段,還允許用戶定義 Repeated 字段,意味著該字段可以出現(xiàn) 0~N 次,類似變長(zhǎng)數(shù)組。
Dremel 格式的設(shè)計(jì)目的就是按列來(lái)存儲(chǔ) Protobuf 的數(shù)據(jù)。由于 Repeated 字段的存在,這要比按列存儲(chǔ)關(guān)系型的數(shù)據(jù)困難一些。一般的思路可能是用終止符表示每個(gè) Repeat 結(jié)束,但是考慮到數(shù)據(jù)可能很稀疏,Dremel 引入了一種更為緊湊的格式。
作為例子,下圖左半邊展示了數(shù)據(jù)的 Schema 和 2 個(gè) Document 的實(shí)例,右半邊是序列化之后的各個(gè)列:
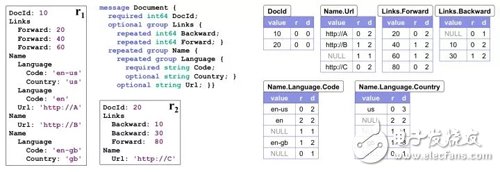
序列化之后的列多出了 R、D 兩列,分別代表 Repetition Level 和 Definition Level,通過(guò)這兩個(gè)值就能確保唯一地反序列化出原本的數(shù)據(jù)。
Repetition Level 表示當(dāng)前值在哪一個(gè)級(jí)別上重復(fù)。對(duì)于非 Repeated 字段只要填上 Trivial 值 0 即可;否則,只要這個(gè)字段可能出現(xiàn)重復(fù)(無(wú)論本身是 Repeated 還是外層結(jié)構(gòu)是 Repeated),應(yīng)當(dāng)為 R 填上當(dāng)前值在哪一層上 Repeat。
舉個(gè)例子說(shuō)明,對(duì)于 Name.Language.Code 我們一共有三條非 NULL 的記錄:
第一個(gè)是 en-us,出現(xiàn)在第一個(gè) Name 的第一個(gè) Lanuage 的第一個(gè) Code 里面。在此之前,這三個(gè)元素是沒(méi)有重復(fù)過(guò)的,都是第一次出現(xiàn)。所以其 R=0
第二個(gè)是 en,出現(xiàn)在下一個(gè) Language 里面。也就是說(shuō) Language 是重復(fù)的元素。Name.Language.Code 中Language 排第二個(gè),所以其 R=2
第三個(gè)是 en-gb,出現(xiàn)在下一個(gè) Name 中,Name 是重復(fù)元素,排第一個(gè),所以其 R=1
注意到 en-gb 是屬于第3個(gè) Name 的而非第2個(gè)Name,為了表達(dá)這個(gè)事實(shí),我們?cè)?en 和 en-gb中間放了一個(gè) R=1 的 NULL。
Definition Level 是為了說(shuō)明 NULL 被定義在哪一層,也就宣告那一層的 Repeat 到此為止。對(duì)于非 NULL 字段只要填上 Trivial 值,即數(shù)據(jù)本身所在的 Level 即可。
同樣舉個(gè)例子,對(duì)于 Name.Language.Country 列:
us 非 NULL 值填上 Country 字段的 Level 即 D=3
NULL 在 R1 內(nèi)部,表示當(dāng)前 Name 之內(nèi)、后續(xù)所有 Language 都不含有 Country 字段,所以D為2。
NULL 在 R1 內(nèi)部,表示當(dāng)前 Document 之內(nèi)、后續(xù)所有 Name 都不含有 Country 字段,所以D為1。
gb 非 NULL 值填上 Country 字段的 Level 即 D=3
NULL 在 R2 內(nèi)部,表示后續(xù)所有 Document 都不含有 Country 字段,所以D為0。
可以證明,結(jié)合 R、D 兩個(gè)數(shù)值一定能唯一構(gòu)建出原始數(shù)據(jù)。為了高效編解碼,Dremel 在執(zhí)行時(shí)首先構(gòu)建出狀態(tài)機(jī),之后利用狀態(tài)機(jī)處理列數(shù)據(jù)。不僅如此,狀態(tài)機(jī)還會(huì)結(jié)合查詢需求和數(shù)據(jù)的 Structure 直接跳過(guò)無(wú)關(guān)的數(shù)據(jù)。
狀態(tài)機(jī)實(shí)現(xiàn)可以說(shuō)是 Dremel 論文的最大貢獻(xiàn)。但是受限于篇幅,有興趣的同學(xué)請(qǐng)參考文末的“文章參考”。
六、總結(jié)
本文介紹了列式存儲(chǔ)的存儲(chǔ)結(jié)構(gòu)設(shè)計(jì)。拋開(kāi)種種繁復(fù)的細(xì)節(jié),我們看到,以下這些思想或設(shè)計(jì)是具有共性的:
跳過(guò)無(wú)關(guān)的數(shù)據(jù)。從行存到列存,就是消除了無(wú)關(guān)列的掃描;ORC 中通過(guò)三層索引信息,能快速跳過(guò)無(wú)關(guān)的數(shù)據(jù)分片。
編碼既是壓縮,也是索引。Dremel 中用精巧的嵌套編碼避免了大量 NULL 的出現(xiàn);C-Store 對(duì) Distinct 值的編碼同時(shí)也是對(duì) Distinct 值的索引;PowerDrill 則將字典編碼用到了極致。
假設(shè)數(shù)據(jù)不可變。無(wú)論 C-Store、Dremel 還是 ORC,它們的編碼和壓縮方式都完全不考慮數(shù)據(jù)更新。如果一定要有更新,暫時(shí)寫(xiě)到別處、讀時(shí)合并即可。
數(shù)據(jù)分片。處理大規(guī)模數(shù)據(jù),既要縱向切分也要橫向切分,不必多說(shuō)。












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論