 激光雷達融合方法與挑戰和潛在影響因素研究
激光雷達融合方法與挑戰和潛在影響因素研究
本文是,加拿大滑鐵盧大學CogDrive實驗室,對當前最新的基于深度學習的相機-激光雷達融合(camera-LiDAR Fusion)方法的綜述。
本篇綜述評價了基于相機-激光雷達融合的深度補全,對象檢測,語義分割和跟蹤方向的最新論文,并根據其融合層級進行組織敘述并對比。最后討論了當前學術研究與實際應用之間的差距和被忽視的問題。基于這些觀察,我們提出了自己的見解及可能的研究方向。

01.背景
基于單目視覺的感知系統以低成本實現了令人滿意的性能,但卻無法提供可靠的3D幾何信息。雙目相機可以提供3D幾何信息,但計算成本高,且無法在高遮擋和無紋理的環境中可靠的工作。此外,基于視覺的感知系統在光照條件復雜的情況下魯棒性較低,這限制了其全天候能力。而激光雷達不受光照條件影響,且能提供高精度的3D幾何信息。但其分辨率和刷新率低,且成本高昂。
相機-激光雷達融合感知,就是為了提高性能與可靠性并降低成本。但這并非易事,首先,相機通過將真實世界投影到相機平面來記錄信息,而點云則將幾何信息以原始坐標的形式存儲。此外,就數據結構和類型而言,點云是不規則,無序和連續的,而圖像是規則,有序和離散的。這導致了圖像和點云處理算法方面的巨大差異。在圖1中,我們比較了點云和圖像的特性。

圖1.點與數據和圖像數據的比較
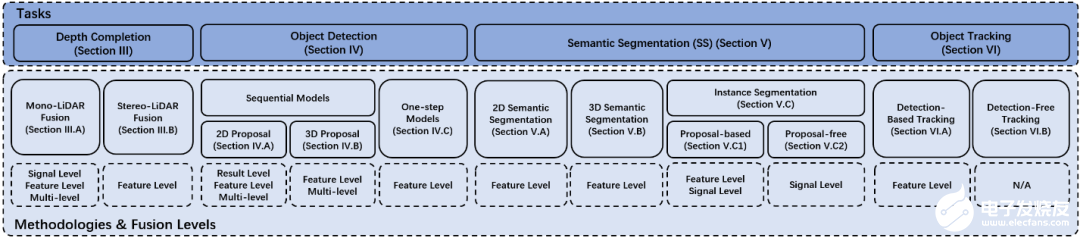
圖2. 論文總體結構
02.趨勢,挑戰和未來研究方向
無人駕駛汽車中的感知模塊負責獲取和理解其周圍的場景,其輸出直接影響著下游模塊(例如規劃,決策和定位)。因此,感知的性能和可靠性是整個無人駕駛系統的關鍵。通過攝像頭-激光雷達融合感知來加強其性能和可靠性,改善無人駕駛車輛在復雜的場景下的感知(例如城市道路,極端天氣情況等)。因此在本節中,我們總結總體趨勢,并討論這方面的挑戰和潛在影響因素。如表IV所示,我們將討論如何改善融合方法的性能和魯棒性,以及與工程實踐相關的其他重要課題。如下是我們總結的圖像和點云融合的趨勢:
2D到3D:隨著3D特征提取方法的發展,在3D空間中定位,跟蹤和分割對象已成為研究的熱點。
單任務到多任務:一些近期的研究結合了多個互補任務,例如對象檢測,語義分割和深度完成,以實現更好的整體性能并降低計算成本。
信號級到多級融合:早期的研究經常利用信號級融合,將3D幾何圖形轉換到圖像平面以利用現成的圖像處理模型,而最近的模型則嘗試在多級融合圖像和點云(例如早期融合,晚期融合)并利用時間上下文。
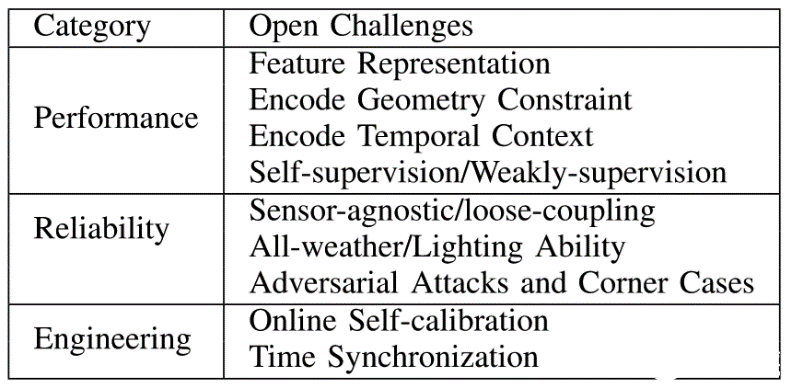
表I. 當前的挑戰
A.與性能相關的開放研究問題
1)融合數據的(Feature/Signal Representation)特征/信號表示形式:
融合數據的Feature/Signal Representation是設計任何數據融合算法的基礎。當前的特征/信號表示形式包括:
a) 在RGB圖像上的附加深度信息通道(RGB-D)。此方法由于可以通過現成的圖像處理模型進行處理,因此早期的信號級融合常使用這種表達形式。但是,其結果也限制于2D圖像平面,這使其不適用于自動駕駛。
b) 在點云上的附加RGB通道。此方法可以通過將點投影到像平面進行像素點關聯來實現。但是,高分辨率圖像和低分辨率點云之間的分辨率不匹配會影響此方式的效率。
c) 將圖像和點云特征/信號均轉換為(intermediate data representation)其他的數據表示形式。當前的intermediate data representation包括:(voxelized point cloud)體素化點云[75],(lattice)晶格[88]。未來的研究可以探索其他新穎的中間數據結構,例如(graph)圖,(tree)樹等,從而提高性能。
2)(Encoding Geometric Constraint)加入幾何約束:
與其他三維數據源(如來自立體相機或結構光的RGBD數據)相比,LiDAR有更長的有效探測范圍和更高的精度,可提供詳細而準確的3D幾何形狀。幾何約束已成為圖像和點云融合流程中的常識,其提供了額外的信息來引導深度學習網絡實現更好的性能。將點云以RGBD圖像的形式投影到圖像平面似乎是最自然的解決方法,但是點云的稀疏性會產生空洞。深度補全和點云上采樣可以在某種程度上解決該問題。除此之外利用單眼圖像預測深度信息以及在連續幀之間引入自我監督學習,也有望緩解這個問題。但是,如何將這種幾何信息加入到融合流程中仍是當前研究實踐中尚需解決的問題。
3)(Encoding Temporal Context)加入時間上下文:
還有一些工程問題阻礙了無人駕駛汽車的實際部署,例如LiDAR與攝像頭之間的時間不同步,LiDAR的低刷新率導致車速高時的點云變形,LiDAR傳感器測距誤差。這些問題將導致圖像與點云,點云與實際環境之間的不匹配。根據深度補全方面的經驗,可以采用連續幀之間的時間上下文來改善姿態估計,從而改善特征融合的性能并使得下游的的header網絡受益。在自動駕駛中,準確估算周圍車輛的運動狀態至關重要,時間上下文有助于獲得更平滑,更穩定的結果。此外,時間上下文可能有益于在線自校準。因此,應對加入時間上下文進行更多的研究。 4)深度學習網絡結構設計:
要回答這個問題,我們首先需要回答點云的最佳深度學習網絡結構是什么。對于圖像處理,CNN是最佳選擇,并已被廣泛接受。但點云處理仍然是一個開放的研究問題。同時沒有點云深度學習網絡的設計原則,被廣泛的接受或被證明是最有效的。當前大多數傳感器融合網絡都是基于對應的圖像的網絡結構,或者是基于經驗或實驗來進行設計的。因此,采用神經網絡結構搜索(NAS)[95]的方法可能會帶來進一步的性能提升。
5)無監督或弱監督的學習框架:
人工標注圖像和點云數據既昂貴又耗時,這限制了當前多傳感器數據集的大小。采用無監督和弱監督的學習框架,可以使網絡在更大的未標記/粗標簽的數據集上進行訓練,從而提升性能。 B.與可靠性相關的開放研究問題
1)與傳感器無關的融合框架:
從工程角度來看,自動駕駛汽車的冗余設計對其安全至關重要。盡管將LiDAR和攝像頭融合在一起可以改善感知性能,但是它也會帶來信號耦合問題。如果在工作時有一條信號路徑失效,那么整個流程都可能會發生故障,并影響下游模塊。這對于在安全關鍵環境中運行的自動駕駛汽車是不可接受的。這一問題可以通過加入能接受不同傳感器輸入的多個融合模塊,或異步多模數據、多路徑的融合模塊來解決。但最佳解決方案仍有待進一步的研究。 2)全天候/光線下的工作能力:
自動駕駛汽車需要在所有天氣和光照條件下工作。然而,當前的數據集和方法主要集中在具有良好照明和天氣條件的場景上。這會導致在現實世界中表現不佳,因為其光照和天氣條件更加復雜。
3)(Adversarial Attacks and Corner Cases)對抗攻擊和極端案例:
針對基于圖像的感知系統的對抗已被證明是有效的,這對自動駕駛汽車構成了嚴重的危險。在這種情況下,可以進一步探索如何利用LiADR的準確3D幾何信息和圖像來共同識別這些攻擊。
由于自動駕駛汽車需要在不可預測的開放環境中運行,因此也必須考慮感知中的(edge cases)極端案例。在設計感知系統時,應該考慮到不常見的特殊障礙物,例如奇怪的行為和極端的天氣。例如,打印在大型車輛上的人和物體(車體廣告)以及穿著怪異服裝的人。利用多模數據來識別這些極端情況,可能會比用單模傳感器更為有效、可靠和簡單。在這個方向上的進一步研究可以幫助提高自動駕駛技術的安全性和加快其商用。
C.與工程有關的開放研究問題
1)傳感器在線自校準:
相機和LiDAR融合的前提和假設是相機和LiDAR之間的精確校準,其中包括相機內部參數和相機與LiDAR之間的外部參數。但在實際上做到校準參數一直準確很難。即使在對相機和LiDAR進行了完美的校準之后,在車輛機械振動,熱量等因素的影響下,其校準參數也會隨時間變化而變得不準。由于大多數融合方法對校準誤差極為敏感,因此這會嚴重削弱其性能和可靠性。此外校準過程大多需要從頭進行,所以不斷的人工更新校準參數既麻煩又不切實際。然而此問題受到的關注較少,因為這個問題在已發布的數據集中不太明顯。盡管如此,仍然有必要研究相機和LiDAR在線自校準的方法。最近的一些研究采用了運動引導[96]和無目標[97]自校準。在這個重要方向上進行更多的研究是有必要的。
2)傳感器時間同步:
明確來自多個傳感器數據幀的確切時間對于實時傳感器融合至關重要,這將直接影響融合結果。但在實踐中,我們很難保證完美的時間同步。首先,LiDAR和相機具有不同的刷新率,并且每個傳感器都有自己的時間源。此外,感知系統的許多部分(數據傳輸,傳感器曝光時間等)都可能發生不可控制的時間延遲。幸運的是,有幾種緩解該問題的方法。首先可以增加傳感器刷新率以減少時間偏差。也可以使用GPS PPS時間源與主機保持同步,并且由主機將時間戳同步請求發送到每個傳感器,以使每個傳感器都在同一時間軸上。此外如果傳感器可以由外部信號觸發,則帶有晶振的特定電路硬件可以記錄精確的時間戳,該時間戳可用于在幾乎同時觸發每個傳感器。該方法被認為是目前最有效的。
03.深度補全
激光點云的稀疏性極大地制約了3D感知算法并使之復雜化。深度補全旨在通過將稀疏的,不規則的深度數據,上采樣為密集的規則的數據來解決此問題。基于相機-激光雷達融合的方法通常利用高分辨率圖像來引導深度上采樣,并采用(encoder-decoder)編碼器-解碼器架構,這也意味著pixel-wise fusion。圖2是深度補全模型的發展時間軸和其對應的數據融合層級。表I列出了KITTI深度補全基準測試中各模型的結果比較和對應的數據融合的層級,并在圖3中繪制成散點圖。
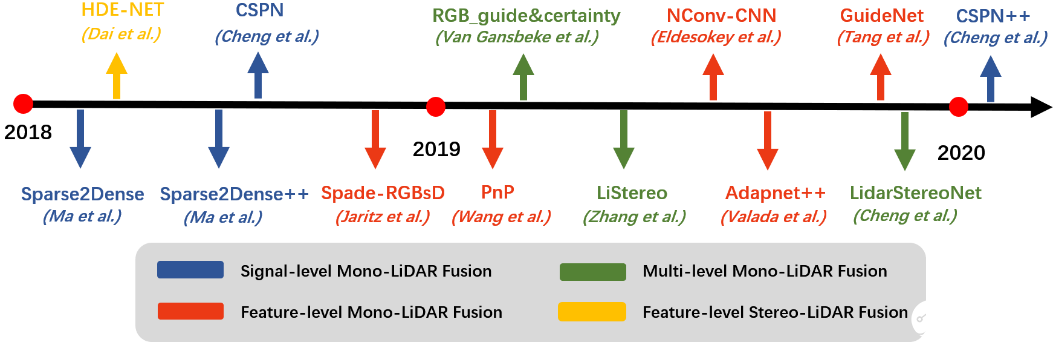
圖3. 深度補全模型的發展時間軸和其對應的數據融合層級
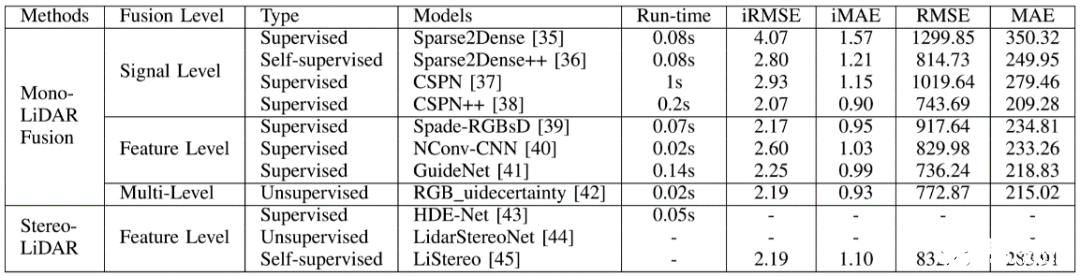
表II. KITTI深度補全基準測試中各模型的結果比較和對應的數據融合的層級
當前大多數研究使用單目圖像來引導深度補全。這些方法認為圖像的顏色,材質等信息包含著幾何信息,故可以將其作為深度上采樣的參考。與單目圖像相比,由立體相機的視差計算得到的幾何信息更豐富,更精確。在深度補全任務上,立體相機和激光雷達在理論上更具互補性,應該能從中計算出更密集,更準確的深度信息。但在實際應用中,立體攝像機的有效距離范圍有限(與激光雷達的有效距離不匹配),且其在高遮擋,無紋理的環境中不可靠(如部分城市道路),這使其目前不太適用于自動駕駛。
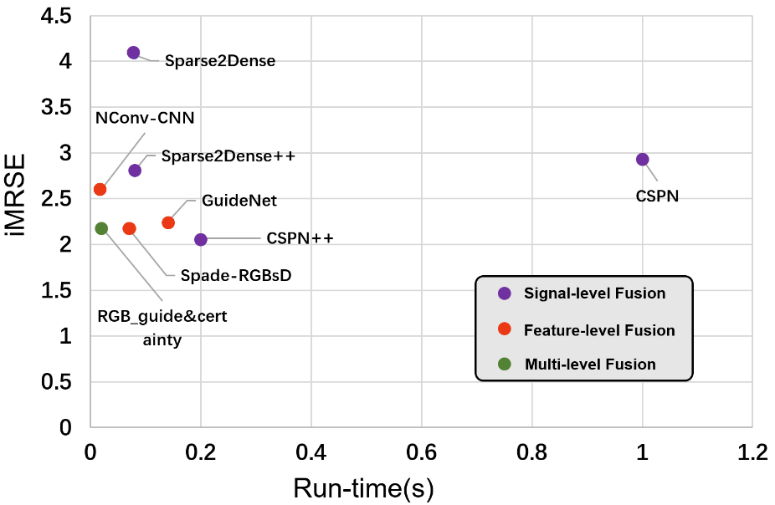
圖4. KITTI深度補全基準測試中各模型的結果散點圖
各模型介紹與對比的詳細內容見原文。
04.3D目標識別
3D目標檢測旨在3D空間中定位,分類并估計具備方向性的(bbox)目標邊界框。當前有兩種主要的目標檢測流程:(Sequential/ two-stage)多階段和(single-shot/one-stage)單階段。基于多階段的模型大體由(proposal stage)候選框階段和3D邊界框(3D bbox regression)回歸階段組成。在候選框階段,檢測并提出所有可能包含感興趣對象的區域。在(bbox)目標邊界框回歸階段,根據候選的區域的特征對區域進行進一步甄別。但是,該模型的性能受到每個階段的限制。在另一方面,single-shot模型只包含一個階段,其通常以并行的方式處理2D和3D信息。3D對象檢測模型的發展時間軸和其對應的數據融合層級如圖4所示。表II和圖6展示了在KITTI 3D目標檢測基準測試中各模型的性能對比和對應的數據融合的層級。

圖5.3D對象檢測模型的發展時間軸和其對應的數據融合層級
A. 基于(2D Proposal)2D候選區域的多階段模型:
這部分模型首先基于2D圖像語義生成2D候選區域,這使其能利用現成的圖像處理模型。更具體的來說,這些方法利用2D圖像目標檢測器生成2D候選區域,并將其投影回3D點云空間中,形成3D搜索空間,并在這些3D搜索空間內進一步完成3D bbox的回歸檢測。這其中有兩種將2D候選區域轉換到3D點云空間的投影方法。第一個是將圖像平面中的邊界框投影到3D點云,從而形成一個錐形的3D搜索空間。而第二種方法將點云投影到圖像平面,將點云逐點與對應的2D語義信息聯系起來。但在點云中,遠處的或被遮擋的物體通常只由少量的稀疏點組成,這增加了第二階段中3D bbox回歸的難度。
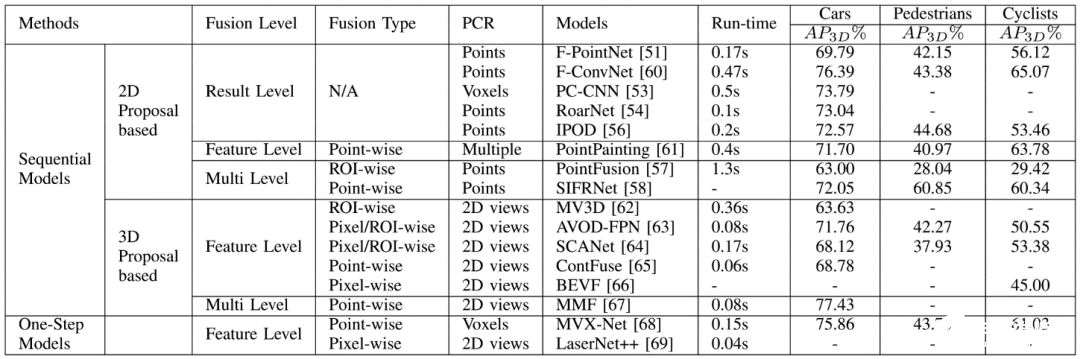
表III. KITTI 3D目標檢測基準測試中各模型的性能對比和對應的數據融合的層級。
B. 基于(3D Proposal)3D候選區域的多階段模型:
基于3D候選區域的模型直接從2D或3D數據中生成3D候選區域。其通過消除2D到3D轉換,極大地縮小了3D搜索空間。用于3D候選區域生成的常見方法包括(multi-view)多視角方法和(point cloud voxelization)點云體素化方法。基于多視角的方法利用點云的鳥瞰(BEV representation)圖來生成3D候選區域。鳥瞰圖避免了透視遮擋,并保留了對象的方向信息和x,y坐標的原始信息。這些方向和x,y坐標信息對于3D對象檢測至關重要,且鳥瞰圖和其他視角之間的坐標轉換較為直接。而基于點云體素化的模型,將連續的不規則數據結構轉換為離散的規則數據結構。這讓應用(standard 3D discrete convolution)標準3D離散卷積,并利用現有網絡模型來處理點云變得可能。其缺點是失去了部分空間分辨率,細粒度的3D結構信息以及引入了(boundary artifacts)邊界痕跡。
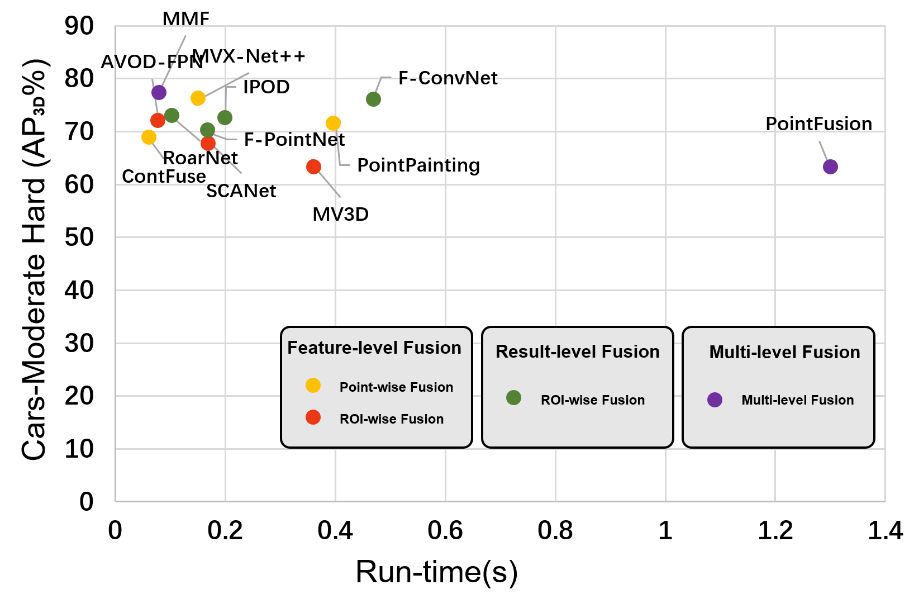
圖6. KITTI 3D目標檢測基準測試中各模型的性能散點圖。 C. 單階段模型單階段模型將候選區域生成和bbox回歸階段融合為一個步驟,這些模型通常在計算效率上更高。這使它們更適合于移動計算平臺上的實時應用。
各模型介紹與對比的詳細內容請見原文。
05.2D/3D語義分割
本節回顧了用于2D語義分割,3D語義分割和實例分割的現有Camera-LiDAR融合方法。2D / 3D語義分割旨在預測每個像素和每個點的類型標簽,而實例分割還關心單個實例。圖6給出了3D語義分割網絡的時間順序概述和對應的數據融合的層級。詳細內容請見原文。
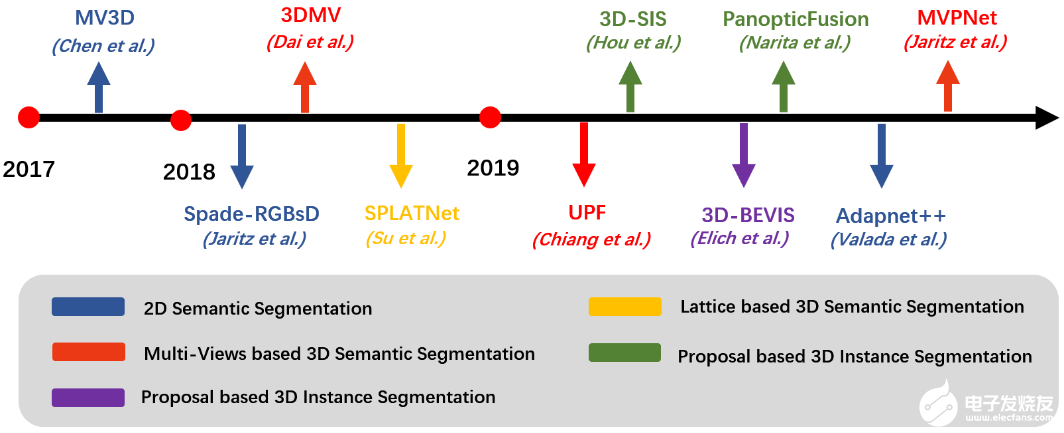
圖7. 3D語義分割網絡的發展時間軸和其對應的數據融合層級
06.跟蹤
多目標跟蹤(MOT)對于自動駕駛汽車的決策是不可或缺的。為此,本節回顧了基于相機-激光雷達融合的對象跟蹤方法,并在表III中的KITTI多對象跟蹤基準(汽車)[47]上比較了它們的性能。
A. Detection-Based Tracking (DBT)/Tracking-by-Detection
檢測跟蹤框架包括兩個階段。在第一階段為目標檢測。第二階段在時間軸上將這些目標關聯起來,并計算軌跡,這些軌跡可被表示成線性程序。
表IV. KITTI 跟蹤基準測試中各模型的性能對比和對應的方法。
責任編輯:gt
-
激光
+關注
關注
19文章
3250瀏覽量
64848 -
雷達
+關注
關注
50文章
2966瀏覽量
118018 -
深度學習
+關注
關注
73文章
5513瀏覽量
121550
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論