") 云計算、AI與邊緣計算的三方面結(jié)合與優(yōu)化
云計算、AI與邊緣計算的三方面結(jié)合與優(yōu)化
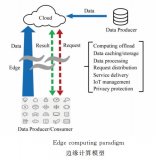
在面向物聯(lián)網(wǎng)、大流量等場景下,為了滿足更廣連接、更低時延、更好控制等需求,云計算在向一種更加全局化的分布式節(jié)點(diǎn)組合形態(tài)進(jìn)階,邊緣計算是其向邊緣側(cè)分布式拓展的新觸角。
以物聯(lián)網(wǎng)場景舉例,設(shè)備產(chǎn)生大量數(shù)據(jù),上傳到云端進(jìn)行處理,會對云端造成巨大壓力,為分擔(dān)云端的壓力,邊緣計算節(jié)點(diǎn)可以負(fù)責(zé)自己范圍內(nèi)的數(shù)據(jù)計算。
同時,經(jīng)過處理的數(shù)據(jù)從邊緣節(jié)點(diǎn)匯聚到中心云,云計算做大數(shù)據(jù)分析挖掘、數(shù)據(jù)共享,同時進(jìn)行算法模型的訓(xùn)練和升級,升級后的算法推送到邊緣,使邊緣設(shè)備更新和升級,完成自主學(xué)習(xí)閉環(huán)。
對于邊緣AI總體來說,核心訴求是高性能、低成本、高靈活性。其技術(shù)發(fā)展趨勢可總結(jié)為以下幾點(diǎn):
可編程性、通用性;
伸縮性,同一個架構(gòu)支持不同場景
低功耗,適應(yīng)更多邊緣場景的環(huán)境和電力要求
軟硬件深度結(jié)合
高效的分布式互聯(lián)和協(xié)作計算能力
筆者分別從邊緣計算AI加速、端/邊/云協(xié)同以及邊緣計算AI框架等三個部分繼續(xù)深入剖析AI應(yīng)用與邊緣計算結(jié)合之后的雙向優(yōu)化,進(jìn)一步優(yōu)化AI應(yīng)用的用戶體驗(yàn)。
邊緣計算AI加速
針對基于邊緣計算場景進(jìn)行AI加速,筆者參考相關(guān)論文認(rèn)為大致可歸結(jié)為以下四個方面:
云邊協(xié)同(云端訓(xùn)練、邊緣推理)
為彌補(bǔ)邊緣設(shè)備計算、存儲等能力的不足,滿足人工智能方法訓(xùn)練過程中對強(qiáng)大計算能力、存儲能力的需求,研究人員提出云計算和邊緣計算協(xié)同服務(wù)架構(gòu)。如下圖所示,研究人員提出將訓(xùn)練過程部署在云端,而將訓(xùn)練好的模型部署在邊緣設(shè)備。顯然,這種服務(wù)模型能夠在一定程度上彌補(bǔ)人工智能在邊緣設(shè)備上對計算、存儲等能力的需求。
模型分割(云邊協(xié)同推理)
為了將人工智能方法部署在邊緣設(shè)備,如下圖提出了切割訓(xùn)練模型,它是一種邊緣服務(wù)器和終端設(shè)備協(xié)同訓(xùn)練的方法。它將計算量大的計算任務(wù)卸載到邊緣端服務(wù)器進(jìn)行計算,而計算量小的計算任務(wù)則保留在終端設(shè)備本地進(jìn)行計算。顯然,上述終端設(shè)備與邊緣服務(wù)器協(xié)同推斷的方法能有效地降低深度學(xué)習(xí)模型的推斷時延。然而,不同的模型切分點(diǎn)將導(dǎo)致不同的計算時間,因此需要選擇最佳的模型切分點(diǎn),以最大化地發(fā)揮終端與邊緣協(xié)同的優(yōu)勢。
模型裁剪
為了減少人工智能方法對計算、存儲等能力的需求,一些研究人員提出了一系列的技術(shù),在不影響準(zhǔn)確度的情況下裁剪訓(xùn)練模型,如在訓(xùn)練過程中丟棄非必要數(shù)據(jù)、稀疏數(shù)據(jù)表示、稀疏代價函數(shù)等。下圖展示了一個裁剪的多層感知網(wǎng)絡(luò),網(wǎng)絡(luò)中許多神經(jīng)元的值為零,這些神經(jīng)元在計算過程中不起作用,因而可以將其移除,以減少訓(xùn)練過程中對計算和存儲的需求,盡可能使訓(xùn)練過程在邊緣設(shè)備進(jìn)行。在參考文獻(xiàn)中,作者也提出了一些壓縮、裁剪技巧,能夠在幾乎不影響準(zhǔn)確度的情況下極大地減少網(wǎng)絡(luò)神經(jīng)元的個數(shù)。
設(shè)計輕量級加速體系架構(gòu)
在工業(yè)界,有很多公司開始研究低功耗加速芯片。如寒武紀(jì)公司推出的思元系列及華為公司推出的昇騰系列,能夠適配并兼容多樣化的硬件架構(gòu),進(jìn)而支撐邊緣計算典型的應(yīng)用場景。
在學(xué)術(shù)界,對于邊緣AI硬件的設(shè)計工作主要集中在提高深度神經(jīng)網(wǎng)絡(luò)及相關(guān)算法如CNN、FCN和RNN等的計算性能和效率。研究人員利用神經(jīng)網(wǎng)絡(luò)的冗余和彈性等特性來優(yōu)化計算操作和數(shù)據(jù)移動,以降低NN算法在專用硬件上的功耗并提高性能。
AI在過去幾年中,為互聯(lián)網(wǎng)應(yīng)用、工業(yè)互聯(lián)網(wǎng)、醫(yī)學(xué)和生物學(xué)及自動駕駛等領(lǐng)域帶來了突飛猛進(jìn)的進(jìn)展。同時,隨著邊緣計算的逐步成熟,業(yè)界必將更加關(guān)注邊緣計算AI加速方面的研究進(jìn)展。
由于邊緣計算場景的特點(diǎn),其硬件的異構(gòu)化程度會顯著高于傳統(tǒng)數(shù)據(jù)中心,對現(xiàn)有計算框架也會有非常大的挑戰(zhàn)。如何快速支持異構(gòu)的計算芯片并保證計算的高效,也非常值得產(chǎn)業(yè)內(nèi)的研發(fā)力量持續(xù)投入。
端/邊/云協(xié)同
資源協(xié)同
對于邊緣計算,需要對計算資源和網(wǎng)絡(luò)資源有全局的判斷,比如邊緣設(shè)備、邊緣節(jié)點(diǎn)及中心云資源的使用情況,站在全局角度,進(jìn)行資源的合理分配,確保性能、成本、服務(wù)最優(yōu)。
數(shù)據(jù)協(xié)同
邊緣AI會處理用戶的數(shù)據(jù),可以從兩個維度來考慮。
一方面,橫向考慮,邊緣的網(wǎng)絡(luò)環(huán)境多種多樣,終端用戶設(shè)備具有移動性,可能會從一個服務(wù)節(jié)點(diǎn)移動到另一個服務(wù)節(jié)點(diǎn),從一個邊緣移動到另一個邊緣,從WiFi切換為5G移動網(wǎng)絡(luò),甚至從一個運(yùn)營商切換到另一個運(yùn)營商,那么用戶在舊的環(huán)境中產(chǎn)生的數(shù)據(jù)如何與新環(huán)境中的AI程序進(jìn)行同步會成為一個問題。這里的數(shù)據(jù)協(xié)同不僅需要技術(shù)上的支持,更需要商業(yè)模式上的支持。
另一方面,縱向考慮,如下圖所示,用戶在邊緣側(cè)產(chǎn)生的數(shù)據(jù)按照隱私級別可以分為不同類型,如User-Private、Edge-Private、Public等,這些數(shù)據(jù)可以自下而上分層儲存在云邊協(xié)同系統(tǒng)中的不同層級的數(shù)據(jù)庫中,同時也可以對應(yīng)不同算力支持的邊緣AI的訪問權(quán)限,例如可以允許云上運(yùn)行的AI程序讀取Public數(shù)據(jù)來訓(xùn)練一個通用的模型,在邊緣側(cè)的AI可以讀取Edge-Private數(shù)據(jù)來在通用模型的基礎(chǔ)上訓(xùn)練邊緣模型等等。
算力協(xié)同
通過合理的模型拆解,將不同的服務(wù)模型根據(jù)資源、成本、質(zhì)量、時延等要求部署在合適的位置。通過完成的協(xié)同計算框架,確保各子模型之間的協(xié)同處理。比如結(jié)合產(chǎn)品設(shè)計,我們可以將簡單的識別推理全部置于端側(cè)設(shè)備,如需要判斷視頻中的物體屬于動物還是植物等。
但是進(jìn)一步的識別功能,我們可以結(jié)合邊緣側(cè)的推理能力,識別動物為貓科動物或犬科動物等。如果用戶需要更加精細(xì)的識別,我們可以將邊緣側(cè)的識別結(jié)果及處理之后得到的特征數(shù)據(jù)發(fā)送至云端,結(jié)合云端完善的數(shù)據(jù)模型和知識體系,將該貓科動物判定為是東北虎還是華南虎。這樣通過端、邊、云三者的協(xié)同,能夠在極大保證用戶體驗(yàn)的同時,合理的使用各類資源。
合理利用算力協(xié)同,也能夠做到在邊緣側(cè)進(jìn)行訓(xùn)練。目前工業(yè)界還沒有成熟的模式,但學(xué)術(shù)界有相關(guān)的研究。如下圖所示的ICE智能協(xié)同計算框架,將邊緣AI的訓(xùn)練分為三個階段:
第一階段為預(yù)訓(xùn)練階段(pre-train),云上的應(yīng)用可以通過讀取云端存儲的公共數(shù)據(jù),來訓(xùn)練一個通用的模型,這是邊緣AI的底座,如果沒有云端強(qiáng)大算力的幫助,只靠邊緣側(cè)算力是難以得到比云端訓(xùn)練更優(yōu)秀的AI模型。
第二階段將通用模型下發(fā)至邊緣側(cè),讀取邊緣私有數(shù)據(jù),通過轉(zhuǎn)移學(xué)習(xí)(Transfer Learning),來得到邊緣模型。
第三階段讀取增量數(shù)據(jù),利用增量學(xué)習(xí)(Incremental Learning)生成最終邊緣模型,這個最終邊緣模型就可以用于用戶側(cè)的推理了。
這種三步學(xué)習(xí)的算力協(xié)同的模式,可以更好地滿足邊緣智能的個性化服務(wù)需求。
通過資源協(xié)同、算力協(xié)同以及數(shù)據(jù)協(xié)同,邊緣智能能夠高效合理的利用端、邊、云的各類資源,極大地優(yōu)化AI應(yīng)用在邊緣計算場景下的用戶體驗(yàn),進(jìn)一步放大AI應(yīng)用的商業(yè)價值。
邊緣計算AI計算框架
在云數(shù)據(jù)中心中,算法執(zhí)行框架更多地執(zhí)行模型訓(xùn)練任務(wù),在訓(xùn)練過程中需要接收大規(guī)模、批量化的信息數(shù)據(jù),比較關(guān)注訓(xùn)練的迭代速度和收斂率等。而在邊緣設(shè)備上更多的是執(zhí)行預(yù)測任務(wù),輸入一般是實(shí)時的小規(guī)模數(shù)據(jù),大多數(shù)場景下執(zhí)行預(yù)測任務(wù),因此更加關(guān)注于預(yù)測算法執(zhí)行速度及端側(cè)或邊緣側(cè)的資源開銷。
目前業(yè)界針對邊緣計算場景,也提出了針對性的設(shè)計方案,例如用于移動設(shè)備或嵌入式設(shè)備的輕量級解決方案TensorFlow Lite,Caffe2和Pytorch等。
TensorFlow Lite
TensorFlow Lite 提供了轉(zhuǎn)換 TensorFlow 模型,并在移動端(mobile)、嵌入式(embeded)和物聯(lián)網(wǎng)(IoT)設(shè)備上運(yùn)行 TensorFlow 模型所需的所有工具。
特點(diǎn):
只含推理(inference)功能,使用的模型文件需要通過離線的方式訓(xùn)練得到。
最終生成的模型文件較小,均小于500kB。
為了提升執(zhí)行速度,都使用了ARM NEON指令進(jìn)行加速。
Caffe2
Caffe2 是一個兼具表現(xiàn)力、速度和模塊性的深度學(xué)習(xí)框架,是 Caffe 的實(shí)驗(yàn)性重構(gòu),能以更靈活的方式組織計算。Caffe2可幫助開發(fā)人員和研究人員 訓(xùn)練大規(guī)模機(jī)器學(xué)習(xí)模型,并在移動應(yīng)用中提供 AI 驅(qū)動的用戶體驗(yàn)。現(xiàn)在,開發(fā)人員可以獲取許多相同的工具,能夠在大規(guī)模分布式場景訓(xùn)練模型,并為移動設(shè)備創(chuàng)建機(jī)器學(xué)習(xí)應(yīng)用。
特點(diǎn):
可以在iOS系統(tǒng)、Android系統(tǒng)和樹莓派(Raspberry Pi)上訓(xùn)練和部署模型;
使用比較簡單,只需要運(yùn)行幾行代碼即可調(diào)用Caffe2中預(yù)先訓(xùn)練好的Model Zoo模型;
NVIDIA(英偉達(dá)),Qualcomm(高通),Intel(英特爾),Amazon(亞馬遜)和Microsoft(微軟)等公司的云平臺都已支持Caffe2;
PyTorch
PyTorch 是最新的深度學(xué)習(xí)框架之一,由 Facebook 的團(tuán)隊開發(fā),并于 2017 年在 GitHub 上開源。PyTorch 很簡潔、易于使用、支持動態(tài)計算圖而且內(nèi)存使用很高效,因此越來越受歡迎。
特點(diǎn):
改進(jìn)現(xiàn)有的神經(jīng)網(wǎng)絡(luò),提供了更快速的方法——不需要從頭重新構(gòu)建整個網(wǎng)絡(luò),這是由于 PyTorch 采用了動態(tài)計算圖(dynamic computational graph)結(jié)構(gòu),而不是大多數(shù)開源框架(TensorFlow、Caffe、CNTK、Theano 等)采用的靜態(tài)計算圖;
強(qiáng)大的社區(qū)支持,facebook的FAIR強(qiáng)力支持,F(xiàn)AIR是全球TOP3的AI研究機(jī)構(gòu)。PyTorch論壇,文檔,tutorial,一應(yīng)俱全。FAIR的幾位工程師更是全職維護(hù)開發(fā),github上PyTorch每天都有許多pull request和討論。
支持iOS系統(tǒng)、Android系統(tǒng)運(yùn)行
這些邊緣AI執(zhí)行框架通過優(yōu)化移動應(yīng)用程序內(nèi)核、預(yù)先激活和量化內(nèi)核等方法來減少執(zhí)行預(yù)測任務(wù)的延遲和內(nèi)存占用量。
此外,邊緣計算在AI訓(xùn)練提速、安全信息預(yù)處理、邊云一體的AI算法上仍處于起步階段。設(shè)計面向輕量級、高效和可擴(kuò)展的邊緣計算AI框架是實(shí)現(xiàn)邊緣智能,極大拓展更多邊緣AI場景落地的重要步驟。
結(jié)語
AI和邊緣計算已獲得國內(nèi)外學(xué)術(shù)界和工業(yè)界的廣泛關(guān)注和認(rèn)可,并且已經(jīng)在很多商業(yè)場景下發(fā)揮作用。將AI應(yīng)用部署至邊緣已成為提升智能服務(wù)的有效途徑。
盡管目前邊緣智能仍處于發(fā)展的初期,然而,筆者相信,邊緣智能夠產(chǎn)生極大的促進(jìn)效果,并成為各行各業(yè)的黏合劑和智能產(chǎn)業(yè)發(fā)展的催化劑,促進(jìn)多個行業(yè)的升級轉(zhuǎn)型。
-
云計算
+關(guān)注
關(guān)注
39文章
7850瀏覽量
137877 -
AI
+關(guān)注
關(guān)注
87文章
31536瀏覽量
270352 -
邊緣計算
+關(guān)注
關(guān)注
22文章
3122瀏覽量
49528
發(fā)布評論請先 登錄
相關(guān)推薦
HPC云計算的技術(shù)架構(gòu)
emulation和云計算的結(jié)合應(yīng)用前景
機(jī)智云榮登2024邊緣計算TOP100榜單
研華科技邊緣AI平臺榮獲2024年IoT邊緣計算卓越獎
Orin芯片與邊緣計算結(jié)合
邊緣計算的未來發(fā)展趨勢
邊緣計算與云計算的區(qū)別
云計算與邊緣計算的結(jié)合
數(shù)據(jù)輕松上云——明達(dá)Mbox邊緣計算網(wǎng)關(guān)

AI云平臺與傳統(tǒng)云計算的區(qū)別
邊緣AI硬件技術(shù)、算法、平臺正在不斷創(chuàng)新/升級優(yōu)化
邊緣計算與云計算:有什么區(qū)別?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論