 基于賽靈思FPGA的廣告推薦算法Wide and deep硬件加速案例
基于賽靈思FPGA的廣告推薦算法Wide and deep硬件加速案例
作者:雪湖科技 梅碧峰
在這篇文章里你可以了解到廣告推薦算法Wide and deep模型的相關知識和搭建方法,還能了解到模型優化和評估的方式。我還為你準備了將模型部署到賽靈思 FPGA上做硬件加速的方法,希望對你有幫助。閱讀這篇文章你可能需要20分鐘的時間。
早上起床打開音樂APP,會有今日歌單為你推薦一些歌曲。地鐵上閑來無事,刷一刷抖音等短視頻,讓枯燥的時光變得有趣。睡前打開購物APP,看一看今天是不是有新品上架。不知不覺大家已經習慣了這些APP,不知道大家有沒有留意到為什么這些APP這么懂你,知道你喜歡聽什么音樂,喜歡看什么類型的短視頻,喜歡什么樣的商品?
這些APP都會有類似“猜你喜歡”這類欄目。在使用時會驚嘆“它怎么知道我喜歡這個?!”,當然,也會有“我怎么可能喜歡這個?”的吐槽。其實這些推送都是由機器學習搭建的推薦系統預測的結果。今天就介紹一下推薦系統中的重要成員CTR預估模型,下面先讓大家對CTR預估模型有一個初步認識。
兩個名詞
CTR(Click-Through-Rate)點擊率:它是在一定時間內點擊量/曝光量*100%,意味著投放了A條廣告有 A*CTR 條被點擊了。
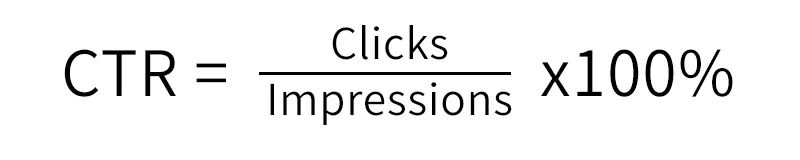
ECPM(earning cost per mille):每1000次曝光帶來收入。ECPM=1000*CTR*單條廣告點擊價格。
舉個“栗”子
廣告A:點擊率4%,每個曝光1元錢,廣告B:點擊率1%,每個曝光5元錢。假如你要投放1000條廣告,你會選擇廣告A,還是廣告B?
直觀上來看,廣告A的點擊率高,當然選擇投放廣告A。
那么:ECPM=1000*CTR*點擊出價
ECPM(A)=1000*4%*1=40
ECPM(B)=1000*1%*5=50
但是從ECPM指標來看的話廣告B帶來的收益會更高,這就是廣告競拍的關鍵計算規則。
我們可以看到CTR是為廣告排序用的,對于計算ECPM來說,只有CTR是未知的,只要準確得出CTR值就可以了。因此CTR預估也是廣告競拍系統的關鍵指標。廣告系統的CTR預估在具體的數值上比推薦系統要求更高,比如推薦系統可能只需要知道A的CTR比B大就可以排序了,而廣告由于不是直接用CTR進行排序,還加上了出價,因此廣告系統不僅要知道A的CTR比B大,而且還需要知道A的CTR比B的CTR大多少。
再舉個“栗”子
如果廣告A:點擊率是5%,廣告B:點擊率也是5%,點擊價格也相同,該選擇廣告A還是廣告B?
點擊率相同,點擊價格也相同 ,得出ECPM也相同,該怎么選擇投放廣告A還是B呢?
此時就可以根據廣告屬性做針對性推薦,針對不同的人群,做合適的推薦。例如:廣告A是包,廣告B是游戲,可做針對性推薦。即:針對女人這一群體投放廣告A、針對男人這一群體投放廣告B,這樣則會提高總廣告收益率。
CTR模型是怎么得出結果的呢?
我們可以根據經驗判斷決定廣告點擊率的屬性:廣告行業、用戶年齡、用戶性別等。由此可分為三類屬性:
User:年齡、性別、收入、興趣、工作等。
Others:時間、投放位置、投放頻率、當前熱點等。
這些決定屬性在CTR預估模型中都叫做特征,而CTR預估模型中有一重要過程“特征工程”,將能影響點擊率的特征找到并進行處理,比如把特征變成0和1的二值化、把連續的特征離散化、把特征平滑化、向量化。這樣CTR模型相當于是無數特征(x)的一個函數,CTR=f(x1,x2,x3,x4,x5...),輸入歷史數據訓練,不斷調整參數(超參數),模型根據輸入的數據不斷更新參數(權重),最終到迭代很多次,參數(權重)幾乎不變化。當輸入新的數據,就會預測該數據的結果,也就是點擊率了。
那么有沒有很好奇如何搭建并訓練出一個好的CTR預估模型呢?
No.1、模型迭代過程
推薦系統這一場景常用的兩大分類:
CF-Based(協同過濾)、Content-Based(基于內容的推薦)
協同過濾(collaborative ?ltering)就是指基于用戶的推薦,用戶A和B比較相似,那么A喜歡的B也可能喜歡。
基于內容推薦是指物品item1和item2比較相似,那么喜歡item1的用戶多半也喜歡item2。
對于接下來的模型無論是傳統的機器學習還是結合現今火熱的深度學習模型都會針對場景需求構建特征建模。
LR(Logistics Regression)==> MLR(Mixed Logistic Regression)==> LR+GBDT(Gradient Boost Decision Tree)==> LR+DNN(Deep Neural Networks)即Wide&Deep==>
1.1、LR
所謂推薦也就離不開Rank這一問題,如何講不同的特征組通過一個表達式計算出分數的高低并排序是推薦的核心問題。通過線性回歸的方式找到一組滿足這一規律的參數,公式如下:
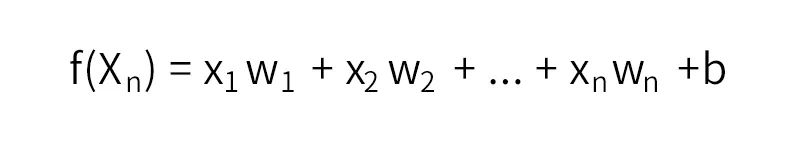
再通過sigmoid函數將輸出映射到(0,1)之間,得出二分類概率值。
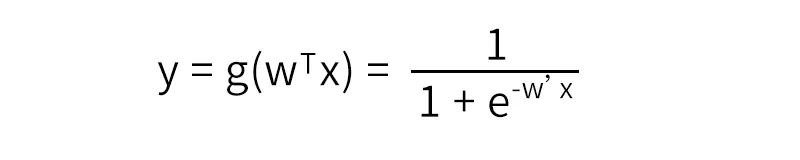
LR模型一直是CTR預估的benchmark模型,原理通俗易懂、可解釋性強。但是當特征與特征之間、特征與目標之間存在非線性關系時,模型效果就會大打折扣。因此模型十分依賴人們根據經驗提取、構建特征。另外,LR模型不能處理組合特征,例如:年齡和性別的組合,不同年齡段不同性別對目標的偏愛程度會不相同,但是模型無法自動挖掘這一隱含信息,依賴人工根據經驗組合特征。這也直接使得它表達能力受限,基本上只能處理線性可分或近似線性可分的問題。
為了讓線性模型能夠學習到原始特征與擬合目標之間的非線性關系,通常需要對原始特征做一些非線性轉換。常用的轉換方法包括:連續特征離散化、向量化、特征之間的交叉等。稍后會介紹為什么這樣處理。
1.2、MLR
它相當于聚類+LR的形式。將X聚成m類,之后把每個類單獨訓練一個LR。MLR相較于LR有更好的非線性表達能力,是LR的一種拓展。
我們知道softmax的公式:
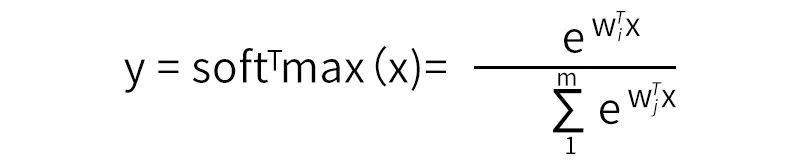
將x進行聚類,即得拓展之后的模型公式:
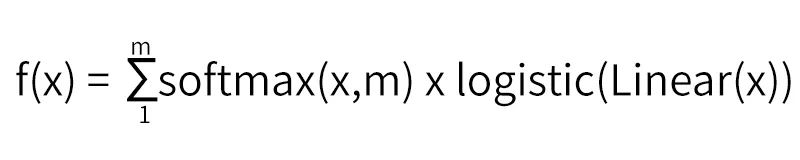
當聚類數目m=1時,退化為LR。m越大,模型的擬合能力越強,m根據具體訓練數據分布來設置。
圖1:MLR 模型結構
但是MLR與LR一樣,同樣需要人工特征工程處理,由于目標函數是非凸函數(易陷入局部最優解),需要預訓練,不然可能會不收斂,得不到好的模型。
1.3、LR+GBDT
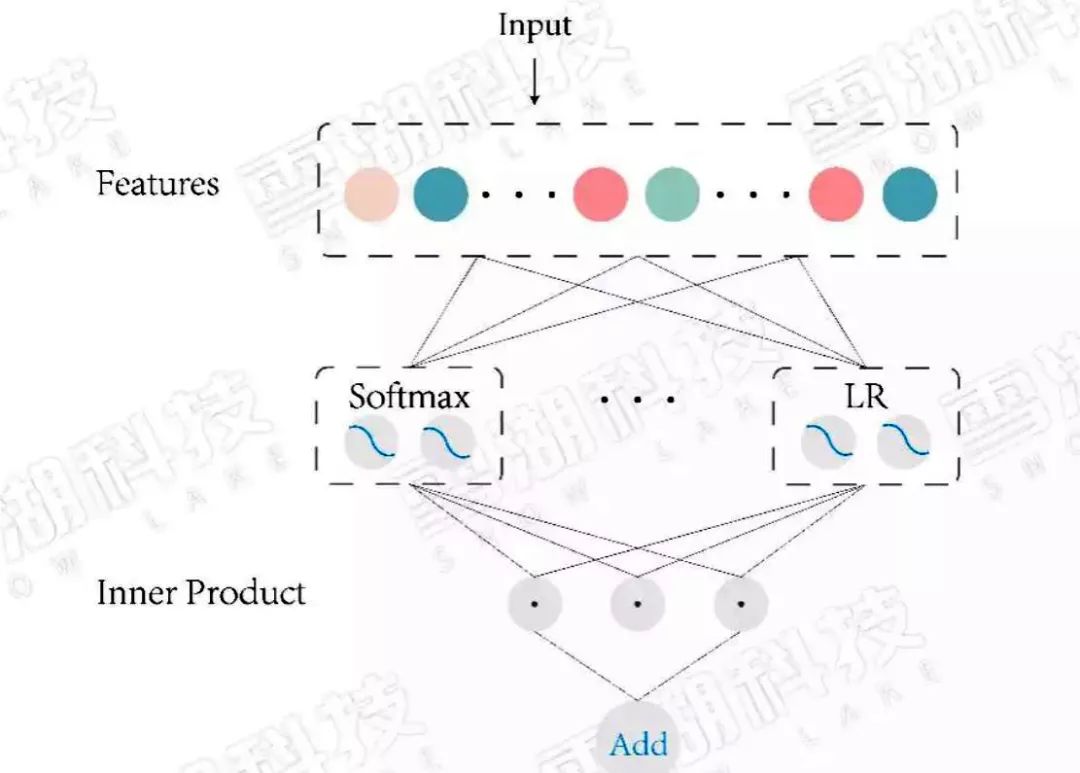
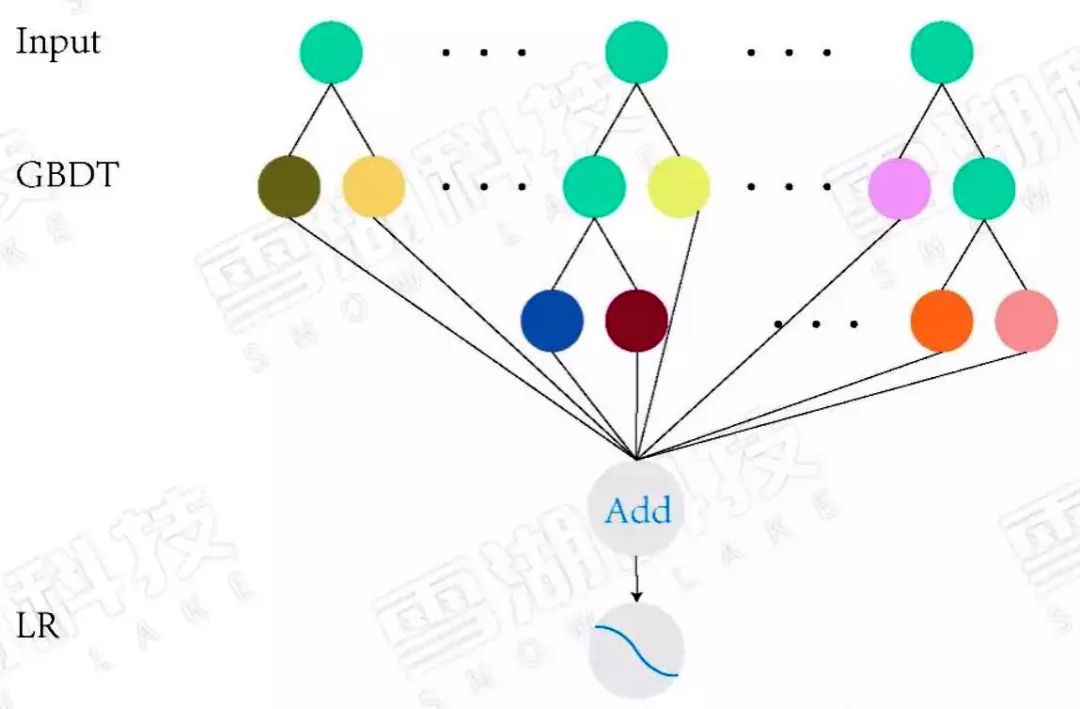
顧名思義LR模型和GBDT模型組合。GBDT可做回歸與分類,這個看自己的需求。在CTR預估這一任務中要使用的是回歸樹而非決策樹。梯度提升也就是朝著梯度下降的方向上建樹,通過不斷更新弱分類器,得到強分類器的過程。 每一子樹都是學習之前樹的結論和的殘差,通過最小化 log 損失函數找到最準確的分支,直到所有葉子節點的值唯一 ,或者達到樹的深度達到預設值。如果某葉子節點上的值不唯一,計算平均值作為預測值輸出。
LR+GBDT:
Facebook 率先提出用GBDT模型解決LR模型的組合特征問題。特征工程分為兩部分,一部分特征通過GBDT模型訓練,把每顆樹的葉子節點作為新特征,加入原始特征中,再用LR得到最終的模型。
GBDT模型能夠學習高階非線性特征組合,對應樹的一條路徑(用葉子節點來表示)。通常用GBDT模型訓練連續值特征、值空間不大(value種類較少)的特征,空間很大的特征在LR模型中訓練。這樣就能把高階特征進行組合,同時又能利用線性模型處理大規模稀疏特征。
圖2:LR+GBDT 模型結構圖
1.4、LR+DNN(Wide&Deep)
先回想一下我們學習的過程。從出生時代,不斷學習歷史知識,通過記憶達到見多識廣的效果。然后通過歷史知識泛化(generalize)到之前沒見過的。但是泛化的結果不一定都準確。記憶(memorization)又可以修正泛化的規則(generalized rules),作為特殊去處理。這就是通過Memorization和Generalization的學習方式。
推薦系統需要解決兩個問題:
記憶能力: 比如通過歷史數據知道“喜歡吃水煮魚”的人也“喜歡吃回鍋肉”,當輸入為“喜歡吃水煮魚”,推出“喜歡吃回鍋肉”。
泛化能力: 推斷在歷史數據中從未見過的情形,“喜歡吃水煮魚”,“喜歡吃回鍋肉”,推出喜歡吃川菜,進而推薦出其他川菜。
但是,模型普遍都存在兩個問題:
a) 偏向于提取低階或者高階的組合特征,不能同時提取這兩種類型的特征。
b) 需要專業的領域知識來做特征工程。
線性模型結合深度神經網絡為什么叫做wide and deep呢?
無論是線性模型、梯度下降樹、因子分解機模型,都是通過不斷學習歷史數據特征,來適應新的數據,預測出新數據的表現。這說明模型要具備一個基本特征記憶能力,也就是wide 部分。
但是當輸入一些之前沒有學習過的數據,此時模型表現卻不優秀,不能根據歷史數據,有機組合,推出新的正確結論。此時單單依賴記憶能力是不夠的。深度學習卻可以構建多層隱層通過FC(全連接)的方式挖掘到特征與特征之間的深度隱藏的信息,來提高模型的泛化能力,也就是deep部分。將這兩部分的輸出通過邏輯回歸,得出預測類別。
圖3:Wide & Deep 模型結構圖
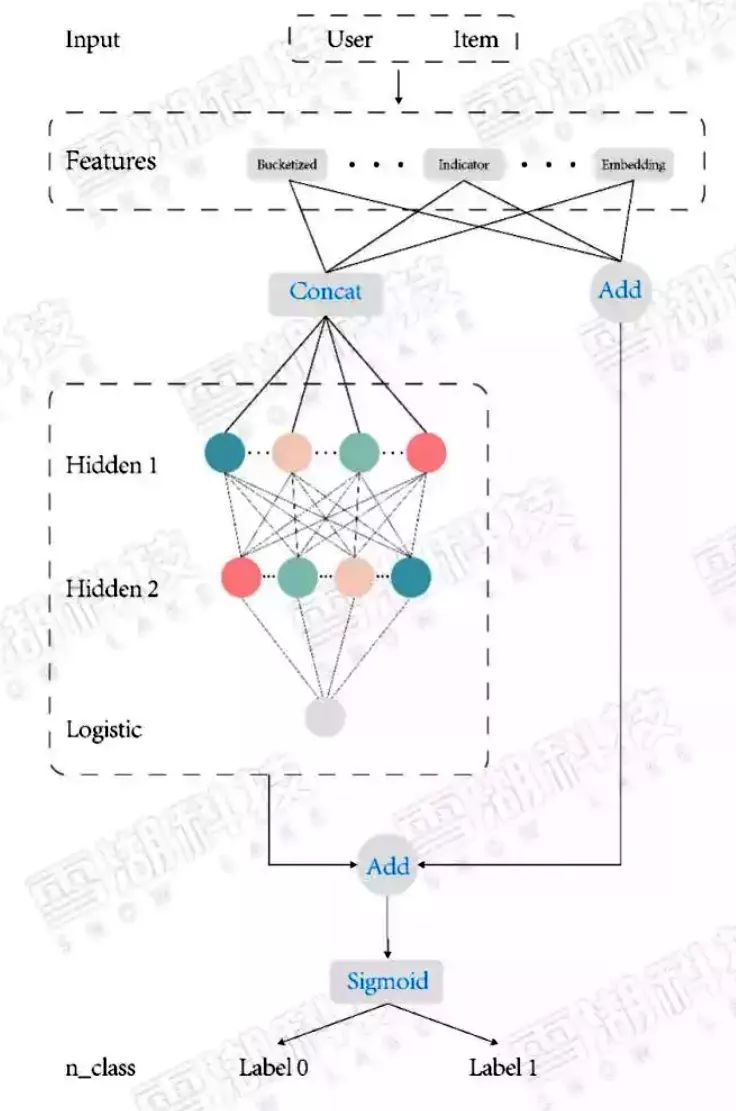
它混合了一個線性模型(Wide part)和Deep模型(Deep part)。這兩部分模型需要不同的輸入,而Wide part部分的輸入,依舊依賴人工特征工程。本質上是線性模型(左邊部分, Wide model)和DNN的融合(右邊部分,Deep Model)。
對于歷史數據特征保證一定的記憶能力,對于新的數據特征擁有推理泛化能力。較大地提高了預測的準確率,這也是一次大膽的嘗試,在推薦系統中引入深度學習,在之后的CTR模型發展中大多也都是按照此設計思路進行的。
1.5、數據處理
CTR預估數據特點:
a) 輸入中包含類別型和連續型數據。類別型數據需要one-hot(獨熱編碼),連續型數據可以先離散化再one-hot,也可以直接保留原值。
b) 維度非常高,特征值特別多。
c) 數據非常稀疏。如:city包含各種不同的地方。
d) 特征按照Field分組。如:city、brand、category等都屬于一個Field,或者將這些Field拆分為多個Fidld。
e) 正負樣本不均衡。點擊率一般都比較小,大量負樣本存在。
如何高效的提取這些組合特征?CTR預估重點在于學習組合特征。注意,組合特征包括二階、三階甚至更高階的,復雜的特征,網絡不太容易學習、表達。一般做法是人工設置相關知識,進行特征工程。但是這樣做會非常耗費人力,另外人工引入知識也不能做到全面。
1.6、模型搭建
以Wide and Deep為例,介紹網絡的搭建。在tensorflow.estimator下有構建好的API,使用方法如下:
Wide中不斷提到這樣一種變換用來生成組合特征:
tf.feature_column.categorical_column_with_vocabulary_list(file)()。知道所有的不同取值,而且取值不多。可以通過list或者file的形式,列出需要訓練的value。
tf.feature_column.categorical_column_with_hash_bucket(),不知道所有不同取值,或者取值多。
通過hash的方式,生成對應的hash_size個值,但是可能會出現哈希沖突的問題,一般不會產生什么影響。
tf.feature_column.numeric_column(),對number類型的數據進行直接映射。一般會對number類型feature做歸一化,標準化。
tf.feature_column.bucketized_column(),分桶離散化構造為sparse特征。這種做法的優點是模型可解釋高,實現快速高效,特征重要度易于分析。特征分區間之后,每個區間上目標(y)的分布可能是不同的,從而每個區間對應的新特征在模型訓練結束后都能擁有獨立的權重系數。特征離散化相當于把線性函數變成了分段線性函數,從而引入了非線性結構。比如不同年齡段的用戶的行為模式可能是不同的,但是并不意味著年齡越大就對擬合目標(比如,點擊率)的貢獻越大,因此直接把年齡作為特征值訓練就不合適。而把年齡分段(分桶處理)后,模型就能夠學習到不同年齡段的用戶的不同偏好模式。
tf.feature_column.indicator_column(),離散類型數據轉換查找,將類別型數據進行one-hot,稀疏變量轉換為稠密變量。
tf.feature_column.embedding_column(),(加深feature維度,將特征向量化,可使模型學到深層次信息),對于RNN中有tf.nn.embedding_lookup(),將文字信息轉為向量,具體算法可以自行查一下。
離散化的其他好處還包括對數據中的噪音有更好的魯棒性(異常值也落在一個劃分區間,異常值本身的大小不會過度影響模型預測結果);離散化還使得模型更加穩定,特征值本身的微小變化(只有還落在原來的劃分區間)不會引起模型預測值的變化。
tf.feature_column.crossed_column(),構建交叉類別,將兩個或者兩個以上的features根據hash值拼接,對hash_key(交叉類別數)取余。特征交叉是另一種常用的引入非線性性的特征工程方法。通常CTR預估涉及到用戶、物品、上下文等幾方面的特征,有時某個單個feature對目標判定的影響會較小,而多種類型的features組合在一起就能夠對目標的判定產生較大的影響。比如user的性別和item的類別交叉就能夠刻畫例如“女性偏愛女裝”,“男性喜歡男裝”的知識。交叉類別可以把領域知識(先驗知識)融入模型。
Deep部分,通過build_columns(),得到可分別得到wide 和deep部分,通過tf.estimator.DNNLinearCombinedClassifier(),可設置隱藏層層數,節點數,優化方法(dnn中Adagrad,linear中Ftrl),dropout ,BN,激活函數等。將linear和dnn連接起來。將點擊率設置為lebel1,從經驗實測效果上說,理論原因這里就不贅述了。
將訓練數據序列化為protobuf格式,加快io時間,設置batch_size、epoch等參數就可以訓練模型了。
No.2、模型優化
對于不同數據,選用不同的features,不同的數據清理方式,模型效果也會有不同,通過測試集驗證模型評價指標,對于CTR預估模型來說,AUC是關鍵指標(稍后介紹)。同時監測查準(precision),查全率(recall),確定模型需要優化的方向,對于正負不均衡情況還可以加大小樣本的權重系數。
一般來說,AUC指標可以達到0.7-0.8。當AUC在這個范圍時,如果準確率較低,說明模型效果還有待提高,可以調整隱藏層數目(3-5)層和節點數(2**n,具體看自己的features輸出維度),構建組合特征,構建交叉特征。學習率可設置一個稍微大點的初始值,然后設置逐漸衰減的學習率,加快收斂。優化手段千變萬化,掌握其本質,在盡可能學習到更多的特征性避免過擬合。具體優化優化方法由模型的表現來決定。
No.3、模型評估
AUC(Area under Curve):Roc曲線下的面積,介于0.5和1之間。AUC作為數值可以直觀的評價分類器的好壞,值越大越好。
直觀理解就是:AUC是一個概率值,當你隨機挑選一個正樣本以及負樣本,當前的分類算法根據計算得到的Score值將這個正樣本排在負樣本前面的概率就是AUC值,AUC值越大,當前分類算法越有可能將正樣本排在負樣本前面,從而能夠更好地分類。
下表是經過調整后,不同算法實現的模型效果對比表:
圖4:模型效果對比表
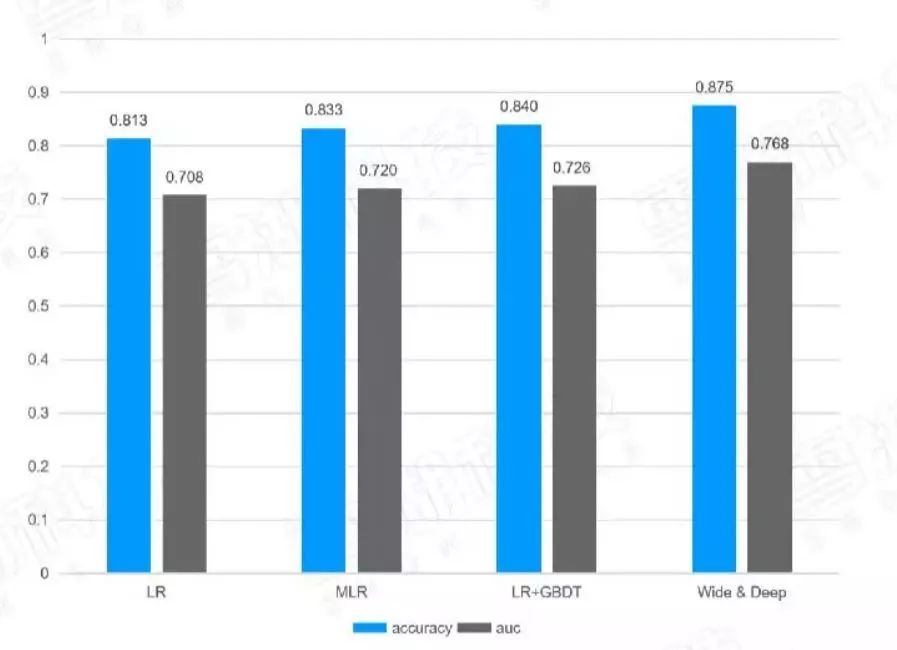
不斷優化后得出幾個模型的不同效果,將每一次廣告曝光按照預測的CTR從小到大排序,可以根據預測的CTR值根據ECPM公式,按照單位曝光量統計出預估的ECPM和真實的ECMP進行比較,就可以知道預估的CTR值是否可靠了。正確預估CTR是為了把真正高CTR的廣告挑出并展示出來么,錯誤地預估——把高的CTR低估或把低的CTR高估都會讓高的ECPM不會排在最前面。在實際的實踐過程中,CTR預測正確通常ECPM、CTR、收入這些指標通常都會漲。
No.4、模型部署
通常對于AI算法模型都是通過GPU服務器部署模型,但是對于推薦系統類算法邏輯計算較多,在速度上反而沒有優勢,部署成本也比較高,經濟性很差。所以大都通過CPU云服務器部署,但是速度又不夠理想。那么有沒有另外一種可能?
答案是肯定的,可以通過FPGA+CPU的方式,大型推薦系統的上線都是通過云端部署,同時用在線和離線方式更新模型。雪湖科技FPGA開發團隊把以Wide and Deep為基礎網絡的模型移植到阿里云FPGA服務器F3(FPGA:賽靈思 VU9P)上,用戶可以通過鏡像文件部署。根據最近的更新數據顯示,模型精度損失可控制在十萬分之二。相較于CPU服務器,FPGA服務器的吞吐量提高了3~5倍。當模型更新時,通過雪湖科技提供的工具可直接載入模型參數,可做到一鍵式更新模型參數。
No.5、CTR模型發展
Wide&Deep 雖然效果很好,但是隨著算法的不斷迭代基于Wide&Deep 模型思想,有很多新的模型被開發出來,基本思想是用FM、FFM代替LR部分,通過串聯或者并聯的方式與DNN部分組合成新的模型,例如FNN,PNN,DeepFM,DeepFFM,AFM,DeepCross等等,雪湖科技公司也致力于將所有CTR預估模型都完美兼容,在保證精度的前提下,增大吞吐量。
作者介紹:
本文作者為雪湖科技算法工程師 梅碧峰,現負責人工智能算法開發。在AI算法領域工作超過5年,喜歡戴著Sony降噪耳機埋頭研究各類算法模型。理想主義的現實工作者,致力于用算法解放人工,實現1+1>2的問題。
-
FPGA
+關注
關注
1630文章
21798瀏覽量
606026 -
賽靈思
+關注
關注
32文章
1794瀏覽量
131509 -
機器學習
+關注
關注
66文章
8439瀏覽量
133087 -
硬件加速
+關注
關注
0文章
29瀏覽量
11159
發布評論請先 登錄
相關推薦
數據中心中的FPGA硬件加速器
賽靈思低溫失效的原因,有沒有別的方法或者一些見解?
易靈思FPGA產品的主要特點

FPGA加速深度學習模型的案例

思爾芯賽題正式發布,邀你共戰EDA精英挑戰賽!

PSoC 6 MCUBoot和mbedTLS是否支持加密硬件加速?
新思科技硬件加速解決方案技術日在成都和西安站成功舉辦

【國產FPGA+OMAPL138開發板體驗】(原創)7.硬件加速Sora文生視頻源代碼
音視頻解碼器硬件加速:實現更流暢的播放效果






 工商網監
工商網監
評論