") 蘋(píng)果A系列SoC可作為新的AI算力范式,成為新的摩爾定律
蘋(píng)果A系列SoC可作為新的AI算力范式,成為新的摩爾定律
最近蘋(píng)果在發(fā)布會(huì)上公開(kāi)了新的A14 SoC。根據(jù)發(fā)布會(huì),該SoC將用于新的iPad上,而根據(jù)行業(yè)人士的推測(cè)該SoC也將會(huì)用在新的iPhone系列中。除了常規(guī)的CPU和GPU升級(jí)之外,A14最引人注目的就是Neural Engine的算力提升。我們認(rèn)為,蘋(píng)果A系列SoC在近幾年內(nèi)Neural Engine的算力增長(zhǎng)可以作為一種新的AI算力范式,成為新的摩爾定律。
A14上的新Neural Engine
蘋(píng)果公布的A14 SoC使用5nm工藝,而新的Neural Engine則使用16核心設(shè)計(jì),其峰值算力可達(dá)11 TOPS,遠(yuǎn)超上一代的Neural Engine(6TOPS)。在發(fā)布會(huì)上,蘋(píng)果明確表示該Neural Engine主要支持加速矩陣相乘。此外,蘋(píng)果還表示新的Neural Engine結(jié)合CPU上的機(jī)器學(xué)習(xí)加速,可以將實(shí)際的AI應(yīng)用體驗(yàn)相對(duì)于前代提升十倍。
新的Neural Engine的峰值算力大大提升可以說(shuō)是有些意料之外,但是又是情理之中。意料之外是因?yàn)锳14的其它關(guān)鍵指標(biāo),例如CPU和GPU等相對(duì)于前一代A13的提升并不多(發(fā)布會(huì)上給出的30%提升對(duì)比的是再前一代的A12 SoC,如果直接和上一代A13相比則CPU性能提升是16%而GPU則是10%左右),但是Neural Engine的性能提升則接近100%。而Neural Engine性能提升大大超過(guò)SoC其他部分是情理之中則是因?yàn)槲覀冋J(rèn)為如果仔細(xì)分析SoC性能提升背后的推動(dòng)力,則可以得出Neural Engine性能大幅提升是非常合理的。一方面,從應(yīng)用需求側(cè)來(lái)說(shuō),對(duì)應(yīng)CPU和GPU的相關(guān)應(yīng)用,例如游戲、網(wǎng)頁(yè)瀏覽、視頻等在未來(lái)可預(yù)見(jiàn)的幾年內(nèi)都沒(méi)有快速的需求增長(zhǎng),唯有人工智能有這樣的需求。另一方面,CPU和GPU的性能在給定架構(gòu)下的性能提升也較困難,很大一部分提升必須靠半導(dǎo)體工藝,而事實(shí)上半導(dǎo)體工藝的升級(jí)在未來(lái)幾年內(nèi)可預(yù)期將會(huì)越來(lái)越慢,每代工藝升級(jí)更注重于晶體管密度以及功耗,在晶體管性能方面的提升將越來(lái)越小。而AI加速器則還有相當(dāng)大的設(shè)計(jì)提升空間,相信在未來(lái)幾年仍將會(huì)有算力快速增長(zhǎng)。
Neural Engine算力增長(zhǎng)趨勢(shì)
我們不妨回顧一下過(guò)去幾代A系列SoC中Neural Engine的算力增長(zhǎng)。
最早加入Neural Engine的SoC是2017年發(fā)布的A11。該SoC使用10nm工藝,搭載第一代Neural Engine峰值算力為0.6TOPS,Neural Engine的芯片面積為1.83mm2。當(dāng)時(shí)Neural Engine主要針對(duì)的應(yīng)用是iPhone新推出的人臉識(shí)別鎖屏FaceID以及人臉關(guān)鍵點(diǎn)追蹤Animoji,且Neural Engine的算力并不對(duì)第三方應(yīng)用開(kāi)放。
第二代Neural Engine則是在2018年的A12 SoC上。該SoC使用7nm工藝,Neural Engine面積為5.8mm2,而其峰值算力則達(dá)到了5TOPS,相比前一代的Neural Engine翻了近10倍。而根據(jù)7nm和10nm工藝的晶體管密度折算則可以估計(jì)出Neural Engine的晶體管數(shù)量大約也是增加了6-7倍,基本和算力提升接近。
第三代Neural Engine是2019年的A13,使用第二代N7工藝,其面積相比上一代減少到了4.64mm2,而算力則增加到了6TOPS。我們認(rèn)為這一代的Neural Engine是上一代的小幅改良版本,并沒(méi)有做大幅升級(jí)。
最近公布的A14則搭載了最新一代的Neural Engine,使用5nm工藝,Neural Engine的具體面積尚沒(méi)有具體數(shù)字,但是其算力則是達(dá)到了11TOPS,是上一代的接近兩倍。
從上面的分析可以看出Neural Engine每次主要升級(jí)都伴隨著算力的大幅上升,第一次上升了近十倍,而第二次則上升了近兩倍。如果按照目前兩年一次主要升級(jí)的節(jié)奏,我們認(rèn)為在未來(lái)數(shù)年內(nèi)Neural Engine乃至于廣義的AI芯片市場(chǎng)都會(huì)有每?jī)赡晷阅芴嵘齼杀兜囊?guī)律,類(lèi)似半導(dǎo)體的摩爾定律。我們認(rèn)為,這樣的規(guī)律可以認(rèn)為是AI芯片算力的新摩爾定律。
為什么AI芯片算力增長(zhǎng)會(huì)成為新的摩爾定律
AI芯片算力指數(shù)上升的主要驅(qū)動(dòng)力還是主流應(yīng)用對(duì)于AI的越來(lái)越倚重,以及AI神經(jīng)網(wǎng)絡(luò)模型對(duì)于算力需求的快速提升。
應(yīng)用側(cè)對(duì)于AI的需求正在越來(lái)越強(qiáng)。就拿智能設(shè)備為例,2017年蘋(píng)果A11中AI的主要應(yīng)用還是面部關(guān)鍵點(diǎn)識(shí)別和追蹤,而到了2018年開(kāi)始越來(lái)越多的應(yīng)用開(kāi)始使用AI,包括圖像增強(qiáng)、拍攝虛化效果等,在下一代智能設(shè)備中AI則更加普及,首先從人機(jī)交互來(lái)看,下一代智能設(shè)備中常見(jiàn)的人機(jī)交互方式手勢(shì)追蹤、眼動(dòng)追蹤、語(yǔ)音輸入等都需要AI,這就大大增加了AI算法的運(yùn)行頻率以及算力需求。此外,下一代智能設(shè)備中有可能會(huì)用到的一系列新應(yīng)用都倚重AI,包括游戲、增強(qiáng)現(xiàn)實(shí)等應(yīng)用中,都需要運(yùn)行大量的AI模型例如SLAM,關(guān)鍵點(diǎn)識(shí)別、物體檢測(cè)和追蹤、姿勢(shì)識(shí)別和追蹤等等。
另一方面,AI對(duì)于算力的需求也在快速提升。根據(jù)HOT CHIPS 2020上的特邀演講,AI模型每年對(duì)于算力需求的提升在10倍左右,因此可以說(shuō)AI模型對(duì)于硬件加速的需求非常強(qiáng)。
如果我們從另一個(gè)角度考慮,這其實(shí)就意味著AI加速芯片的算力提升在賦能新的場(chǎng)景和應(yīng)用——因?yàn)榭偸怯行碌男阅芨叩腁I模型需要更強(qiáng)的硬件去支持,而一旦支持了這樣的新模型則又能賦能新的應(yīng)用。從目前主流的計(jì)算機(jī)視覺(jué)相關(guān)的AI,到以BERT為代表的大規(guī)模自然語(yǔ)言處理算法,以及未來(lái)可能出現(xiàn)的將BERT和計(jì)算機(jī)視覺(jué)相結(jié)合的視覺(jué)高階語(yǔ)義理解等等,我們?cè)谖磥?lái)幾年內(nèi)尚未看到AI模型進(jìn)步的停止以及可能的新應(yīng)用場(chǎng)景的出現(xiàn),相反目前的瓶頸是AI加速硬件性能跟不上。這也就意味著,AI加速硬件才是AI模型落地的最終賦能者,這就像當(dāng)年摩爾定律大躍進(jìn)的PC時(shí)代,當(dāng)時(shí)每一次CPU處理器的進(jìn)步都意味著PC上能運(yùn)行更多的應(yīng)用,因此我們看到了CPU性能在當(dāng)時(shí)的突飛猛進(jìn);今天這一幕又重現(xiàn)了,只是今天的主角換成了AI加速芯片。
AI算力增長(zhǎng)來(lái)自何方?
分析完了AI加速芯片的需求側(cè),我們不妨再來(lái)看看供給側(cè)——即目前的技術(shù)還能支持AI芯片多少算力提升。
首先,AI加速器芯片和傳統(tǒng)CPU的一個(gè)核心差異在于,CPU要處理的通用程序中往往很大一部分難以并行化,因此即使增加CPU的核心數(shù)量,其性能的增加與核心數(shù)也并非線性關(guān)系;而AI模型的計(jì)算通常較為規(guī)整,且很容易就可以做并行化處理,因此其算力提升往往與計(jì)算單元數(shù)量呈接近線性的關(guān)系。這在我們之前對(duì)比A11和A12 Neural Engine的晶體管數(shù)量和算力提升之間的關(guān)系也有類(lèi)似的結(jié)論。目前,以Neural Engine為代表的AI加速器占芯片總面積約為5%,未來(lái)如果AI加速器的面積能和GPU有類(lèi)似的面積(20%左右),則AI加速器的計(jì)算單元數(shù)量也即算力至少還有4倍的提升空間。此外,如果考慮兩年兩倍的節(jié)奏并考慮未來(lái)幾年內(nèi)可能會(huì)落地的3nm工藝,則我們認(rèn)為AI加速器算力兩年兩倍的提升速度從這方面至少還有5-6年的空間可挖。
除了單純?cè)黾佑?jì)算單元數(shù)目之外,另一個(gè)AI加速器算力重要的提升空間來(lái)自于算法和芯片的協(xié)同設(shè)計(jì)。從算法層面,目前主流的移動(dòng)端模型使用的是8-bit計(jì)算精度,而在學(xué)術(shù)界已經(jīng)有許多對(duì)于4-bit甚至1-bit計(jì)算的研究都取得了大幅降低計(jì)算量和參數(shù)量的同時(shí)幾乎不降低模型精度。另外,模型的稀疏化處理也是一個(gè)重要的方向,目前許多模型經(jīng)過(guò)稀疏化處理可以降低50-70%的等效計(jì)算量而不降低精度。因此如果考慮模型和芯片和協(xié)同設(shè)計(jì)并在加速器中加入相關(guān)的支持(如低精度計(jì)算和稀疏化計(jì)算),我們預(yù)計(jì)還能在計(jì)算單元之外額外帶來(lái)至少10倍等效算力提升。
最后,當(dāng)峰值算力的潛力已經(jīng)被充分挖掘之后,還有一個(gè)潛力方向是針對(duì)不同AI模型的專(zhuān)用化設(shè)計(jì),也即異構(gòu)設(shè)計(jì)。AI模型中,常用于機(jī)器視覺(jué)的卷積神經(jīng)網(wǎng)絡(luò)和常用于機(jī)器翻譯/語(yǔ)音識(shí)別的循環(huán)卷積網(wǎng)絡(luò)無(wú)論是在計(jì)算方法還是內(nèi)存訪問(wèn)等方面都大相徑庭,因此如果能做專(zhuān)用化設(shè)計(jì),則有可能在峰值算力不變的情況下,實(shí)際的計(jì)算速度仍然取得數(shù)倍的提升。
結(jié)合上面討論的一些方向,我們認(rèn)為AI加速芯片的算力在未來(lái)至少還有數(shù)十倍甚至上百倍的提升空間,再結(jié)合之前討論的應(yīng)用側(cè)對(duì)于算力的強(qiáng)烈需求,我們認(rèn)為在未來(lái)數(shù)年內(nèi)都會(huì)看到AI加速芯片的算力一兩年翻倍地指數(shù)上升。在這一領(lǐng)域,事實(shí)上中國(guó)的半導(dǎo)體行業(yè)有很大的機(jī)會(huì)。如前所述,AI芯片性能提升主要來(lái)自于設(shè)計(jì)的提升而非工藝提升,而中國(guó)無(wú)論是在半導(dǎo)體電路設(shè)計(jì)領(lǐng)域還是AI模型領(lǐng)域都并不落后,因此有機(jī)會(huì)能抓住這個(gè)機(jī)會(huì)。
編輯;hfy
-
cpu
+關(guān)注
關(guān)注
68文章
10905瀏覽量
213031 -
gpu
+關(guān)注
關(guān)注
28文章
4777瀏覽量
129360 -
5nm
+關(guān)注
關(guān)注
1文章
342瀏覽量
26137 -
A14處理器
+關(guān)注
關(guān)注
0文章
15瀏覽量
2089
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
擊碎摩爾定律!英偉達(dá)和AMD將一年一款新品,均提及HBM和先進(jìn)封裝

AI時(shí)代的存儲(chǔ)墻,哪種存算方案才能打破?

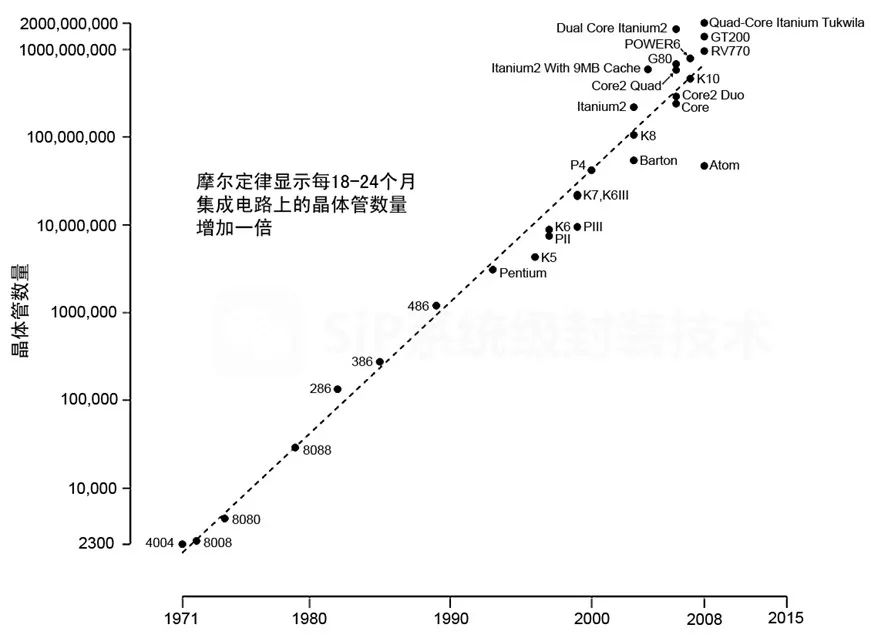
石墨烯互連技術(shù):延續(xù)摩爾定律的新希望
摩爾定律是什么 影響了我們哪些方面
企業(yè)AI算力租賃模式的好處
后摩爾定律時(shí)代,提升集成芯片系統(tǒng)化能力的有效途徑有哪些?
企業(yè)AI算力租賃是什么
GPU算力開(kāi)發(fā)平臺(tái)是什么
AI算力芯片供電電源測(cè)試?yán)?費(fèi)思低壓大電流系列電子負(fù)載

高算力AI芯片主張“超越摩爾”,Chiplet與先進(jìn)封裝技術(shù)迎百家爭(zhēng)鳴時(shí)代

“自我實(shí)現(xiàn)的預(yù)言”摩爾定律,如何繼續(xù)引領(lǐng)創(chuàng)新
摩爾線程張建中:以國(guó)產(chǎn)算力助力數(shù)智世界,滿足大模型算力需求
封裝技術(shù)會(huì)成為摩爾定律的未來(lái)嗎?

功能密度定律是否能替代摩爾定律?摩爾定律和功能密度定律比較





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論