 淺談時序差分的在線控制算法—SARSA
淺談時序差分的在線控制算法—SARSA
在強化學習(五)用時序差分法(TD)求解中,我們討論了用時序差分來求解強化學習預測問題的方法,但是對控制算法的求解過程沒有深入,本文我們就對時序差分的在線控制算法SARSA做詳細的討論。
SARSA這一篇對應Sutton書的第六章部分和UCL強化學習課程的第五講部分。
1.SARSA算法的引入
SARSA算法是一種使用時序差分求解強化學習控制問題的方法,回顧下此時我們的控制問題可以表示為:給定強化學習的5個要素:狀態集SS, 動作集AA, 即時獎勵RR,衰減因子γγ, 探索率??, 求解最優的動作價值函數q?q?和最優策略π?π?。
這一類強化學習的問題求解不需要環境的狀態轉化模型,是不基于模型的強化學習問題求解方法。對于它的控制問題求解,和蒙特卡羅法類似,都是價值迭代,即通過價值函數的更新,來更新當前的策略,再通過新的策略,來產生新的狀態和即時獎勵,進而更新價值函數。一直進行下去,直到價值函數和策略都收斂。
再回顧下時序差分法的控制問題,可以分為兩類,一類是在線控制,即一直使用一個策略來更新價值函數和選擇新的動作。而另一類是離線控制,會使用兩個控制策略,一個策略用于選擇新的動作,另一個策略用于更新價值函數。
我們的SARSA算法,屬于在線控制這一類,即一直使用一個策略來更新價值函數和選擇新的動作,而這個策略是????貪婪法,在強化學習(四)用蒙特卡羅法(MC)求解中,我們對于????貪婪法有詳細講解,即通過設置一個較小的??值,使用1??1??的概率貪婪地選擇目前認為是最大行為價值的行為,而用??的概率隨機的從所有m個可選行為中選擇行為。用公式可以表示為:
π(a|s)={?/m+1???/mifa?=argmaxa∈AQ(s,a)elseπ(a|s)={?/m+1??ifa?=arg?maxa∈AQ(s,a)?/melse
2. SARSA算法概述
作為SARSA算法的名字本身來說,它實際上是由S,A,R,S,A幾個字母組成的。而S,A,R分別代表狀態(State),動作(Action),獎勵(Reward),這也是我們前面一直在使用的符號。這個流程體現在下圖:
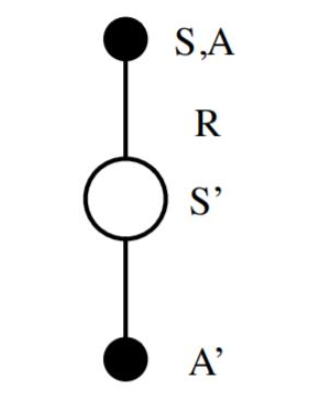
在迭代的時候,我們首先基于????貪婪法在當前狀態SS選擇一個動作AA,這樣系統會轉到一個新的狀態S′S′, 同時給我們一個即時獎勵RR, 在新的狀態S′S′,我們會基于????貪婪法在狀態S‘′S‘′選擇一個動作A′A′,但是注意這時候我們并不執行這個動作A′A′,只是用來更新的我們的價值函數,價值函數的更新公式是:
Q(S,A)=Q(S,A)+α(R+γQ(S′,A′)?Q(S,A))Q(S,A)=Q(S,A)+α(R+γQ(S′,A′)?Q(S,A))
其中,γγ是衰減因子,αα是迭代步長。這里和蒙特卡羅法求解在線控制問題的迭代公式的區別主要是,收獲GtGt的表達式不同,對于時序差分,收獲GtGt的表達式是R+γQ(S′,A′)R+γQ(S′,A′)。這個價值函數更新的貝爾曼公式我們在強化學習(五)用時序差分法(TD)求解第2節有詳細講到。
除了收獲GtGt的表達式不同,SARSA算法和蒙特卡羅在線控制算法基本類似。
3. SARSA算法流程
下面我們總結下SARSA算法的流程。
算法輸入:迭代輪數TT,狀態集SS, 動作集AA, 步長αα,衰減因子γγ, 探索率??,
輸出:所有的狀態和動作對應的價值QQ
1. 隨機初始化所有的狀態和動作對應的價值QQ. 對于終止狀態其QQ值初始化為0.
2. for i from 1 to T,進行迭代。
a) 初始化S為當前狀態序列的第一個狀態。設置AA為????貪婪法在當前狀態SS選擇的動作。
b) 在狀態SS執行當前動作AA,得到新狀態S′S′和獎勵RR
c) 用????貪婪法在狀態S′S′選擇新的動作A′A′
d) 更新價值函數Q(S,A)Q(S,A):
Q(S,A)=Q(S,A)+α(R+γQ(S′,A′)?Q(S,A))Q(S,A)=Q(S,A)+α(R+γQ(S′,A′)?Q(S,A))
e)S=S′,A=A′S=S′,A=A′
f) 如果S′S′是終止狀態,當前輪迭代完畢,否則轉到步驟b)
這里有一個要注意的是,步長αα一般需要隨著迭代的進行逐漸變小,這樣才能保證動作價值函數QQ可以收斂。當QQ收斂時,我們的策略????貪婪法也就收斂了。
4. SARSA算法實例:Windy GridWorld
下面我們用一個著名的實例Windy GridWorld來研究SARSA算法。
如下圖一個10×7的長方形格子世界,標記有一個起始位置 S 和一個終止目標位置 G,格子下方的數字表示對應的列中一定強度的風。當個體進入該列的某個格子時,會按圖中箭頭所示的方向自動移動數字表示的格數,借此來模擬世界中風的作用。同樣格子世界是有邊界的,個體任意時刻只能處在世界內部的一個格子中。個體并不清楚這個世界的構造以及有風,也就是說它不知道格子是長方形的,也不知道邊界在哪里,也不知道自己在里面移動移步后下一個格子與之前格子的相對位置關系,當然它也不清楚起始位置、終止目標的具體位置。但是個體會記住曾經經過的格子,下次在進入這個格子時,它能準確的辨認出這個格子曾經什么時候來過。格子可以執行的行為是朝上、下、左、右移動一步,每移動一步只要不是進入目標位置都給予一個 -1 的懲罰,直至進入目標位置后獲得獎勵 0 同時永久停留在該位置。現在要求解的問題是個體應該遵循怎樣的策略才能盡快的從起始位置到達目標位置。
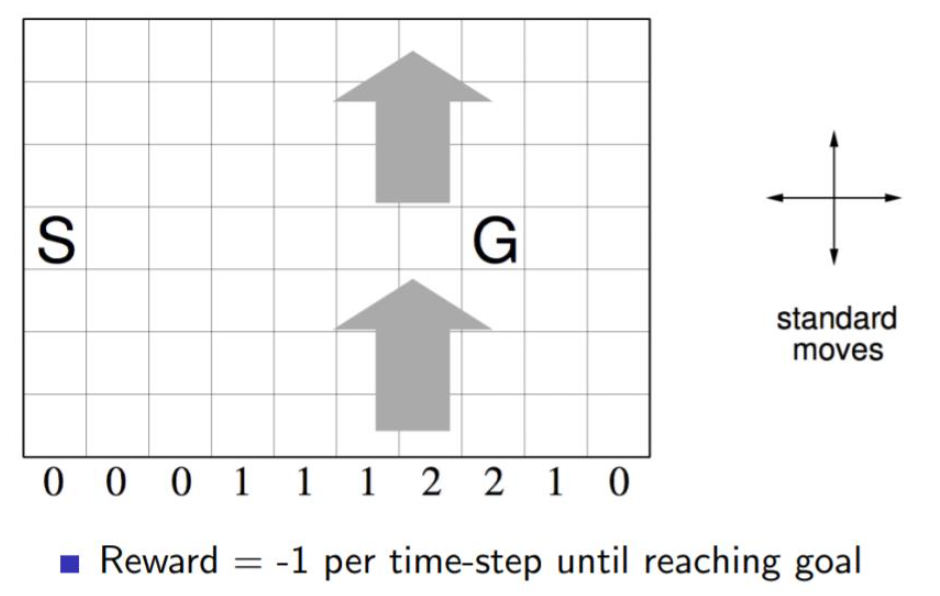
邏輯并不復雜,完整的代碼在我的github。這里我主要看一下關鍵部分的代碼。
算法中第2步步驟a,初始化SS,使用????貪婪法在當前狀態SS選擇的動作的過程:
# initialize state
state = START
# choose an action based on epsilon-greedy algorithm
if np.random.binomial(1, EPSILON) == 1:
action = np.random.choice(ACTIONS)
else:
values_ = q_value[state[0], state[1], :]
action = np.random.choice([action_ for action_, value_ in enumerate(values_) if value_ == np.max(values_)])
算法中第2步步驟b,在狀態SS執行當前動作AA,得到新狀態S′S′的過程,由于獎勵不是終止就是-1,不需要單獨計算:
def step(state, action):
i, j = state
if action == ACTION_UP:
return [max(i - 1 - WIND[j], 0), j]
elif action == ACTION_DOWN:
return [max(min(i + 1 - WIND[j], WORLD_HEIGHT - 1), 0), j]
elif action == ACTION_LEFT:
return [max(i - WIND[j], 0), max(j - 1, 0)]
elif action == ACTION_RIGHT:
return [max(i - WIND[j], 0), min(j + 1, WORLD_WIDTH - 1)]
else:
assert False
算法中第2步步驟c,用????貪婪法在狀態S‘S‘選擇新的動作A′A′的過程:
next_state = step(state, action)
if np.random.binomial(1, EPSILON) == 1:
next_action = np.random.choice(ACTIONS)
else:
values_ = q_value[next_state[0], next_state[1], :]
next_action = np.random.choice([action_ for action_, value_ in enumerate(values_) if value_ == np.max(values_)])
算法中第2步步驟d,e,更新價值函數Q(S,A)Q(S,A)以及更新當前狀態動作的過程:
# Sarsa update
q_value[state[0], state[1], action] += \
ALPHA * (REWARD + q_value[next_state[0], next_state[1], next_action] -
q_value[state[0], state[1], action])
state = next_state
action = next_action
代碼很簡單,相信大家對照算法,跑跑代碼,可以很容易得到這個問題的最優解,進而搞清楚SARSA算法的整個流程。
5. SARSA(λλ)
在強化學習(五)用時序差分法(TD)求解中我們講到了多步時序差分TD(λ)TD(λ)的價值函數迭代方法,那么同樣的,對應的多步時序差分在線控制算法,就是我們的SARSA(λ)SARSA(λ)。
TD(λ)TD(λ)有前向和后向兩種價值函數迭代方式,當然它們是等價的。在控制問題的求解時,基于反向認識的SARSA(λ)SARSA(λ)算法將可以有效地在線學習,數據學習完即可丟棄。因此SARSA(λ)SARSA(λ)算法默認都是基于反向來進行價值函數迭代。
在上一篇我們講到了TD(λ)TD(λ)狀態價值函數的反向迭代,即:
δt=Rt+1+γV(St+1)?V(St)δt=Rt+1+γV(St+1)?V(St)
V(St)=V(St)+αδtEt(S)V(St)=V(St)+αδtEt(S)
對應的動作價值函數的迭代公式可以找樣寫出,即:
δt=Rt+1+γQ(St+1,At+1)?Q(St,At)δt=Rt+1+γQ(St+1,At+1)?Q(St,At)
Q(St,At)=Q(St,At)+αδtEt(S,A)Q(St,At)=Q(St,At)+αδtEt(S,A)
除了狀態價值函數Q(S,A)Q(S,A)的更新方式,多步參數λλ以及反向認識引入的效用跡E(S,A)E(S,A),其余算法思想和SARSA類似。這里我們總結下SARSA(λ)SARSA(λ)的算法流程。
算法輸入:迭代輪數TT,狀態集SS, 動作集AA, 步長αα,衰減因子γγ, 探索率??,多步參數λλ
輸出:所有的狀態和動作對應的價值QQ
1. 隨機初始化所有的狀態和動作對應的價值QQ. 對于終止狀態其QQ值初始化為0.
2. for i from 1 to T,進行迭代。
a) 初始化所有狀態動作的效用跡EE為0,初始化S為當前狀態序列的第一個狀態。設置AA為????貪婪法在當前狀態SS選擇的動作。
b) 在狀態SS執行當前動作AA,得到新狀態S′S′和獎勵RR
c) 用????貪婪法在狀態S′S′選擇新的動作A′A′
d) 更新效用跡函數E(S,A)E(S,A)和TD誤差δδ:
E(S,A)=E(S,A)+1E(S,A)=E(S,A)+1
δ=Rt+1+γQ(St+1,At+1)?Q(St,At)δ=Rt+1+γQ(St+1,At+1)?Q(St,At)
e) 對當前序列所有出現的狀態s和對應動作a, 更新價值函數Q(s,a)Q(s,a)和效用跡函數E(s,a)E(s,a):
Q(s,a)=Q(s,a)+αδE(s,a)Q(s,a)=Q(s,a)+αδE(s,a)
E(s,a)=γλE(s,a)E(s,a)=γλE(s,a)
f)S=S′,A=A′S=S′,A=A′
g) 如果S′S′是終止狀態,當前輪迭代完畢,否則轉到步驟b)
對于步長αα,和SARSA一樣,一般也需要隨著迭代的進行逐漸變小才能保證動作價值函數QQ收斂。
6. SARSA小結
SARSA算法和動態規劃法比起來,不需要環境的狀態轉換模型,和蒙特卡羅法比起來,不需要完整的狀態序列,因此比較靈活。在傳統的強化學習方法中使用比較廣泛。
但是SARSA算法也有一個傳統強化學習方法共有的問題,就是無法求解太復雜的問題。在 SARSA 算法中,Q(S,A)Q(S,A)的值使用一張大表來存儲的,如果我們的狀態和動作都達到百萬乃至千萬級,需要在內存里保存的這張大表會超級大,甚至溢出,因此不是很適合解決規模很大的問題。當然,對于不是特別復雜的問題,使用SARSA還是很不錯的一種強化學習問題求解方法。
-
算法
+關注
關注
23文章
4630瀏覽量
93348 -
控制算法
+關注
關注
4文章
166瀏覽量
21792 -
SARSA
+關注
關注
0文章
2瀏覽量
1330
發布評論請先 登錄
相關推薦
對Rijndael的JAVA差分攻擊與防范
SHACAL-2算法的差分故障攻擊
修正的強跟蹤有限差分濾波算法
基于差分隱私的軌跡模式挖掘算法

基于鄰域差分和協方差信息處理單目標優化的進化算法
面向隨機森林的差分隱私保護算法
淺談Q-Learning和SARSA時序差分算法
強化學習的雙權重最小二乘Sarsa算法

基于北斗衛星差分定位法的導線舞動在線監測-風河智能







 工商網監
工商網監
評論