 深度學習的GPU共享工作
深度學習的GPU共享工作
當前機器學習訓練中,使用GPU提供算力已經非常普遍,對于GPU-based AI system的研究也如火如荼。在這些研究中,以提高資源利用率為主要目標的GPU共享(GPU sharing)是當下研究的熱點之一。 本篇文章希望能提供一個對GPU共享工作的分享,希望能和相關領域的研究者們共同討論。 GPU共享,是指在同一張GPU卡上同時運行多個任務。優勢在于:
(1)集群中可以運行更多任務,減少搶占。
(2)資源利用率(GPU/顯存/e.t.c.)提高;GPU共享后,總利用率接近運行任務利用率之和,減少了資源浪費。
(3)可以增強公平性,因為多個任務可以同時開始享受資源;也可以單獨保證某一個任務的QoS。
(4)減少任務排隊時間。
(5)總任務結束時間下降;假設兩個任務結束時間分別是x,y,通過GPU共享,兩個任務全部結束的時間小于x+y。
想要實現GPU共享,需要完成的主要工作有:
(1)資源隔離,是指共享組件有能力限制任務占據算力(線程/SM)及顯存的比例,更進一步地,可以限制總線帶寬。
(2)并行模式,主要指時間片模式和MPS模式。 資源隔離資源隔離是指共享組件有能力限制任務占據算力/顯存的比例。限制的方法就是劫持調用。圖一是在Nvidia GPU上,機器學習自上而下的視圖。由于Cuda和Driver不開源,因此資源隔離層一般處在用戶態。 在內核態做隔離的困難較大,但也有一些工作。順帶一提,Intel的Driver是開源的,在driver層的共享和熱遷移方面有一些上海交大和Intel合作的工作。
圖一/使用Nvidia GPU機器學習自上而下視圖 來自騰訊的Gaia(ISPA'18)[1]共享層在Cuda driver API之上,它通過劫持對Cuda driver API的調用來做到資源隔離。劫持的調用如圖二所示。 具體實現方式也較為直接,在調用相應API時檢查: (1)對于顯存,一旦該任務申請顯存后占用的顯存大小大于config中的設置,就報錯。(2)對于計算資源,存在硬隔離和軟隔離兩種方式,共同點是當任務使用的GPU SM利用率超出資源上限,則暫緩下發API調用。 不同點是如果有資源空閑,軟隔離允許任務超過設置,動態計算資源上限。而硬隔離則不允許超出設置量。該項目代碼開源在[2]。 實測即使只跑一個任務也會有較大JCT影響,可能是因為對資源的限制及守護程序的資源占用問題。KubeShare(HPDC '20)[3]的在資源隔離方面也是類似的方案。
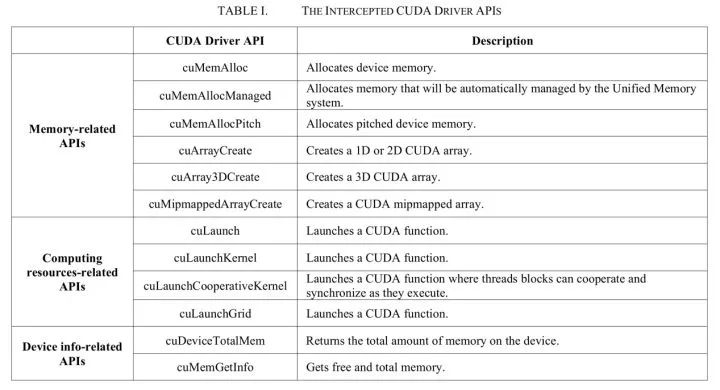
圖二/ Gaia限制的CUDA driver API 發了44篇論文(截止2020年3月)的rCuda[4]和Gaia有相似之處,他們都是在Cuda driver API之上,通過劫持調用來做資源隔離。 不同的是,rCuda除了資源隔離,最主要的目標是支持池化。池化簡單來講就是使用遠程訪問的形式使用GPU資源,任務使用本機的CPU和另一臺機器的GPU,兩者通過網絡進行通信。也是因為這個原因,共享模塊需要將CPU和GPU的調用分開。 然而正常情況下混合編譯的程序會插入一些沒有開源的Cuda API,因此需要使用作者提供的cuda,分別編譯程序的CPU和GPU部分。 圖三顯示了rCuda的架構。如果使用該產品,用戶需要重新編譯,對用戶有一定的影響。該項目代碼不開源。 另外vCUDA(TC '12)[5]和qCUDA(CloudCom '19)[18]也采用了和rCuda相似的技術。
圖三/rCuda架構 GPUShare(IPDPSW' 16)[6]也是劫持的方式,但不同的是,它采用預測執行時間的方式來實現計算資源的公平性。 作者認為比切換周期還小的短kernel不會影響公平使用,因此只限制了較大的kernel。 來自阿里的cGPU[7],其共享模塊在Nvidia driver層之上,也就是內核態。由于是在公有云使用,相對于用戶態的共享會更加安全。 它也是通過劫持對driver的調用完成資源隔離的,通過設置任務占用時間片長度來分配任務占用算力,但不清楚使用何種方式精準地控制上下文切換的時間。 值得一提的是,由于Nvidia driver是不開源的,因此需要一些逆向工程才可以獲得driver的相關method的name和ioctl參數的結構。 該方案在使用上對用戶可以做到無感知,當然JCT是有影響的。代碼沒有開源,也沒有論文。圖四是cGPU的架構圖。
圖四/cgpu架構圖 來自Nvidia的vGPU[8]其共享模塊在Nvidia driver里面。vGPU通過vfio-mdev提供了一個隔離性非常高的的硬件環境,主要面向的是虛擬機產品,無法動態調整資源比例。 來自Nvidia的產品當然沒有開源。圖五是vGPU的架構圖。
圖五/vGPU架構圖 Fractional GPU(RTAS' 19)[9]是一篇基于MPS的資源隔離方案。其共享模塊在Nvidia driver里面。該方案的隔離非常硬,核心就是綁定。 在計算隔離方面,它通過給任務綁定一定比例的可使用SM,就可以天然地實現計算隔離。MPS的計算隔離是通過限制任務的thread數,相較于Fractional GPU會限制地更加不準確。 在顯存隔離方面,作者深入地研究Nvidia GPU內存架構(包括一些逆向工程)圖六是Fractional GPU通過逆向得到的Nvidia GPU GTX 970的存儲體系架構。 通過頁面著色(Page Coloring)來完成顯存隔離。頁面著色的思想也是將特定的物理頁分配給GPU SM分區,以限制分區間互相搶占的問題。 該隔離方案整體上來說有一定損耗,而且只能使用規定好的資源比例,不能夠靈活地檢測和使用全部空閑資源。另外使用該方案需要修改用戶代碼。代碼開源在[10]。

圖六/Fractional GPU通過逆向得到的Nvidia GPU GTX 970的存儲體系架構 Mig( MULTI-INSTANCE GPU)[21]是今年A100機器支持的資源隔離方案,Nvidia在最底層硬件上對資源進行了隔離,可以完全地做到計算/通信/配置/錯誤的隔離。 它將SM和顯存均勻地分給GPU instance,最多支持將SM分7份(一份14個),顯存分8份(1份5GB)。順帶一提A100有SM108個,剩下的10個將無法用上。它可選的配置也是有限制的,如圖七所示。

圖七/Mig GPU Instance配置 并行模式并行模式指任務是以何種方式在同一個GPU上運行的。目前有兩種方式:
(1)分時復用。指劃分時間片,讓不同的任務占據一個獨立的時間片,需要進行上下文切換。在這種模式下,任務實際上是并發的,而不是并行的,因為同一時間只有一個任務在跑。
(2)合并共享。指將多個任務合并成一個上下文,因此可以同時跑多個任務,是真正意義上的并行。在生產環境中,更多使用分時復用的方式。 分時復用分時復用的模式大家都較為熟悉,CPU程序的時間片共享已經非常常見和易用,但在GPU領域還有一些工作要做。 如果在Nvidia GPU上直接啟動兩個任務,使用的就是時間片共享的方式。
但該模式存在多任務干擾問題:即使兩個機器學習任務的GPU利用率和顯存利用率之和遠小于1,單個任務的JCT也會高出很多。究其原因,是因為計算碰撞,通信碰撞,以及GPU的上下文切換較慢。 計算碰撞很好理解,如果切換給另一個任務的時候,本任務正好在做CPU計算/IO/通信,而需要GPU計算時,時間片就切回給本任務,那么就不會有JCT的影響。但兩個任務往往同時需要使用GPU資源。 通信碰撞,是指任務同時需要使用顯存帶寬,在主機內存和設備顯存之間傳輸數據。GPU上下文切換慢,是相對CPU而言的。 CPU上下文切換的速度是微秒級別,而GPU的切換在毫秒級別。在此處也會有一定的損耗。圖八是分時復用模式的常見架構。
圖八/分時復用架構圖 上文提到的Gaia,KubeShare,rCuda,vCuda,qCuda,cGPU,vGPU均為分時復用的模式。 由于上文所述的問題,他們的單個任務完成時間(JCT)都會受到較大的影響。V100測試環境下,兩個任務同時運行,其JCT是單個任務運行時的1.4倍以上。 因此在生產環境下,我們需要考慮如何減少任務之間互相影響的問題。上述方案都沒有考慮機器學習的特性,只要共享層接收到kernel下發,檢查沒有超過設置上限,就會繼續向下傳遞。 另外也限制任務顯存的使用不能超過設置上限,不具備彈性。因此針對特定的生產場景,有一些工作結合機器學習任務的特性,進行了資源的限制及優化。
服務質量(QoS)保障在生產環境的GPU集群中常會有兩類任務,代稱為高優先級任務和低優先級任務。高優任務是時間敏感的,在它需要資源時需要立刻提供給它。 而低優任務是時間不敏感的,當集群有資源沒被使用時,就可以安排它填充資源縫隙以提高集群利用率。因此共享模塊需要優先保障高優先級任務的JCT不受影響,以限制低優任務資源占用的方式。 Baymax(ASPLOS '16)[11]通過任務重排序保障了高優任務的QoS。Baymax作者認為多任務之間的性能干擾通常是由排隊延遲和PCI-e帶寬爭用引起的。 也就是說,當高優任務需要計算或IO通信時,如果有低優的任務排在它前面,高優任務就需要等待,因此QoS無法保障。針對這兩點Baymax分別做了一些限制:
(1)在排隊延遲方面,Baymax利用KNN/LR模型來預測持續時間。然后Baymax對發給GPU的請求進行重新排序。 簡單來說,就是共享模塊預測了每個請求的執行時間,當它認為發下去的請求GPU還沒執行完時,新下發的請求就先進入隊列里。 同時將位于隊列中的任務重排序,當需要下發請求時,先下發隊列中的高優任務請求。
(2)在PCI-e帶寬爭用方面,Baymax限制了并發數據傳輸任務的數量。Baymax作者在第二年發表了Prophet(ASPLOS '17)[12],用于預測多任務共置時QoS的影響程度。 在論文最后提到的實驗中,表示如果預測到多個任務不會影響QoS,就將其共置,但此處共置使用的是MPS,也就是沒有使用分時復用的模式了。 在該研究中,預測是核心。預測準確性是否能適應復雜的生產環境,預測的機器負載是否較大,還暫不清楚。 來自阿里的AntMan(OSDI '20)[13]也認為排隊延遲和帶寬爭用是干擾的原因,不同的是,它從DL模型的特點切入,來區分切換的時機。
在算力限制方面,AntMan通過限制低優任務的kernel launch保證了高優任務的QoS。圖九是AntMan算力共享機制的對比。 AntMan算力調度最小單元,在論文中描述似乎有些模糊,應該是Op(Operator),AntMan“會持續分析GPU運算符的執行時間“,并在空隙時插入另一個任務的Op。 但如何持續分析,論文中并沒有詳細描述。在顯存隔離方面,AntMan沒有限制顯存的大小,而是盡力讓兩個任務都能運行在機器上。但兩個或多個任務的顯存申請量可能會造成顯存溢出,因此AntMan做了很多顯存方面的工作。 首先需要了解任務在顯存中保存的內容:首先是模型,該數據是大小穩定的,當它在顯存中時,iteration才可以開始計算。
論文中表示90%的任務模型使用500mb以內的顯存。其次是iteration開始時申請的臨時顯存,這部分顯存理論上來說,在iteration結束后就會釋放。 但使用的機器學習框架有緩存機制,申請的顯存不會退回,該特性保障了速度,但犧牲了共享的可能性。 因此AntMan做了一些顯存方面最核心的機制是,當顯存放不下時,就轉到內存上。在此處論文還做了很多工作,不再盡述。 論文描述稱AntMan可以規避總線帶寬爭用問題,但似乎從機制上來說無法避免。 除此之外,按照Op為粒度進行算力隔離是否會需要大量調度負載也是一個疑問,另外Op執行時間的差異性較大,尤其是開啟XLA之后,這也可能帶來一些不確定性。該方案需要修改機器學習框架(Tensorflow和Pytorch),對用戶有一定的影響。 代碼開源在[20],目前還是WIP項目(截止2020/11/18),核心部分(local-coordinator)還沒能開源。
圖九/AntMan算力共享機制的對比 如果最小調度單元是iteration,則會更加簡單。首先需要了解一下DL訓練的特征:訓練時的最小迭代是一個iteration,分為四個過程: IO,進行數據讀取存儲以及一些臨時變量的申請等;前向,在此過程中會有密集的GPU kernel。NLP任務在此處也會有CPU負載。后向,計算梯度更新,需要下發GPU kernel;更新,如果非一機一卡的任務,會有通信的過程。之后更新合并后的梯度,需要一小段GPU時間。 可以看出前向后向和通信之后的更新過程,是需要使用GPU的,通信和IO不需要。
因此可以在此處插入一些來自其他任務的kernel,同時還可以保證被插入任務的QoS。更簡單的方式是,通過在iteration前后插入另一個任務的iteration來完成共享。 當然這樣就無法考慮通信的空隙,可以被理解是一種tradeoff。另外也因為iteration是最小調度單元,避免了計算資源和顯存帶寬爭用問題。 另外,如果不考慮高優任務,實現一個退化版本,貪心地放置iteration而不加以限制。可以更簡單地提高集群利用率,也可以讓任務的JCT/排隊時間減小。 針對推理的上下文切換在上文中描述了分時復用的三個問題,其中上下文切換是一個耗時點。
來自字節跳動的PipeSwitch(OSDI '20)[14]針對推理場景的上下文切換進行了優化。具體生產場景是這樣的:訓練推理任務共享一張卡,大多數時候訓練使用資源。當推理請求下發,上下文需要立刻切換到推理任務。 如果模型數據已經在顯存中,切換會很快,但生產環境中模型一般較大,訓練和推理的模型不能同時加載到顯存中,當切換到推理時,需要先傳輸整個模型,因此速度較慢。
在該場景下,GPU上下文切換的開銷有: (1)任務清理,指釋放顯存。(2)任務初始化,指啟動進程,初始化Cuda context等。(3)Malloc。(4)模型傳輸,從內存傳到顯存。
在模型傳輸方面,PipeSwitch作者觀察到,和訓練不同的是推理只有前向過程,因此只需要知道上一層的輸出及本層的參數就可以開始計算本層。 目前的加載方式是,將模型數據全部加載到顯存后,才會開始進行計算,但實際上如果對IO和計算做pipeline,只加載一層就開始計算該層,就會加快整體速度。當然直接使用層為最小粒度可能會帶來較大開銷,因此進行了grouping合并操作。 圖十顯示了pipeline的對比。在任務清理和初始化方面,設置了一些常駐進程來避免開銷。最后在Malloc方面也使用了統一的內存管理來降低開銷。 可以說做的非常全面。由于需要獲知層級結構,因此需要對Pytorch框架進行修改,對用戶有一定影響。代碼開源在[19].
圖十/PipeSwitch pipeline的對比 合并共享合并共享是指,多個任務合并成一個上下文,因此可以共享GPU資源,同時發送kernel到GPU上,也共同使用顯存。最具有代表性的是Nvidia的MPS[15]。 該模式的好處是顯而易見的,當任務使用的資源可以同時被滿足時,其JCT就基本沒有影響,性能可以說是最好的。可以充分利用GPU資源。 但壞處也是致命的:錯誤會互相影響,如果一個任務錯誤退出(包括被kill),如果該任務正在執行kernel,那么和該任務共同share IPC和UVM的任務也會一同出錯退出。 目前還沒有工作能夠解決這一問題,Nvidia官方也推薦使用MPS的任務需要能夠接受錯誤影響,比如MPI程序。 因此無法在生產場景上大規模使用。另外,有報告稱其不能支持所有DL框架的所有版本。 在資源隔離方面,MPS沒有顯存隔離,可以通過限制同時下發的thread數粗略地限制計算資源。它位于Nvidia Driver之上。圖十一是MPS的架構圖。
圖十一/MPS架構圖 Salus(MLSys '20)[16]也采取了合并共享的方式,作者通過Adaptor將GPU請求合并到同一個context下,去掉了上下文切換。 當然,和MPS一樣會發生錯誤傳播,論文中也沒有要解決這一問題,因此無法在生產環境中使用。 但筆者認為這篇論文中更大的價值在顯存和調度方面,它的很多見解在AntMan和PipeSwitch中也有體現。調度方面,以iteration為最小粒度,并且詮釋了原因:使用kernel為粒度,可以進一步利用資源,但會增加調度服務的開銷。 因此折中選擇了iteration,可以實現性能最大化。
顯存方面,一些觀察和AntMan是一致的:顯存變化具有周期性;永久性顯存(模型)較小,只要模型在顯存中就可以開始計算;臨時性顯存在iteration結束后就應該釋放。 也描述了機器學習框架緩存機制的死鎖問題。不過Salus實現上需要兩個任務所需的顯存都放到GPU顯存里,沒有置換的操作。 論文中也提到了推理場景下的切換問題:切換后理論上模型傳輸時間比推理延遲本身長幾倍。 除此之外論文中也有一些其他的觀察點,值得一看。圖十二展示了Salus架構。該項目代碼開源在[17]。Salus也需要修改DL框架。作者也開源了修改后的tensorflow代碼。

圖十二/Salus架構圖 如果在合并共享模塊之上做分時復用,應可以繞過硬件的限制,精準地控制時間片和切換的時機,也可以去除上下文切換的開銷。但在這種情況下是否還會有錯誤影響,還需要進一步驗證。 場景展望目前GPU共享已經逐漸開始進入工業落地的階段了,若需要更好地滿足用戶對使用場景的期待,除了更高的性能,筆者認為以下幾點也需要注意。 1、能夠提供穩定的服務,運維便捷。比如MPS的錯誤影響是不能被接受的,另外對于帶有預測的實現,也需要更高的穩定性。共享工作負載盡量降低。 2、更低的JCT時延,最好具有保障部分任務QoS的能力。對于一個已有的GPU集群進行改造時,需要盡量減少對已有的用戶和任務的影響。 3、不打擾用戶,盡量不對用戶的代碼和框架等做修改,另外也需要考慮框架和其他庫的更新問題。 參考資料:
[1]J. Gu, S. Song, Y. Li and H. Luo, "GaiaGPU: Sharing GPUs in Container Clouds," 2018 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Ubiquitous Computing & Communications, Big Data & Cloud Computing, Social Computing & Networking, Sustainable Computing & Communications (ISPA/IUCC/BDCloud/SocialCom/SustainCom), Melbourne, Australia, 2018, pp. 469-476, doi: 10.1109/BDCloud.2018.00077.
[2]github.com/tkestack/vcu
[3]Ting-An Yeh, Hung-Hsin Chen, and Jerry Chou. 2020. KubeShare: A Framework to Manage GPUs as First-Class and Shared Resources in Container Cloud. In Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing (HPDC '20). Association for Computing Machinery, New York, NY, USA, 173–184. DOI:doi.org/10.1145/3369583
[4]José Duato, Francisco D. Igual, Rafael Mayo, Antonio J. Pe?a, Enrique S. Quintana-Ortí, and Federico Silla. An efficient implementation of GPU virtualization in high performance clusters. In Euro-Par 2009, Parallel Processing - Workshops, volume 6043 of Lecture Notes in Computer Science, pages 385-394. Springer-Verlag, 2010.
[5]L. Shi, H. Chen, J. Sun and K. Li, "vCUDA: GPU-Accelerated High-Performance Computing in Virtual Machines," in IEEE Transactions on Computers, vol. 61, no. 6, pp. 804-816, June 2012, doi: 10.1109/TC.2011.112.
[6]A. Goswami et al., "GPUShare: Fair-Sharing Middleware for GPU Clouds," 2016 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Chicago, IL, 2016, pp. 1769-1776, doi: 10.1109/IPDPSW.2016.94.
[7]alibabacloud.com/help/z
[8]docs.nvidia.com/grid/10
[9]S. Jain, I. Baek, S. Wang and R. Rajkumar, "Fractional GPUs: Software-Based Compute and Memory Bandwidth Reservation for GPUs," 2019 IEEE Real-Time and Embedded Technology and Applications Symposium (RTAS), Montreal, QC, Canada, 2019, pp. 29-41, doi: 10.1109/RTAS.2019.00011.
[10]github.com/sakjain92/Fr
[11]Quan Chen, Hailong Yang, Jason Mars, and Lingjia Tang. 2016. Baymax: QoS Awareness and Increased Utilization for Non-Preemptive Accelerators in Warehouse Scale Computers. In Proceedings of the Twenty-First International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS '16). Association for Computing Machinery, New York, NY, USA, 681–696. DOI:doi.org/10.1145/2872362
[12]Quan Chen, Hailong Yang, Minyi Guo, Ram Srivatsa Kannan, Jason Mars, and Lingjia Tang. 2017. Prophet: Precise QoS Prediction on Non-Preemptive Accelerators to Improve Utilization in Warehouse-Scale Computers. In Proceedings of the Twenty-Second International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS '17). Association for Computing Machinery, New York, NY, USA, 17–32. DOI:doi.org/10.1145/3037697
[13]Xiao, Wencong, et al. "AntMan: Dynamic Scaling on {GPU} Clusters for Deep Learning." 14th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 20). 2020.
[14]Bai, Zhihao, et al. "PipeSwitch: Fast Pipelined Context Switching for Deep Learning Applications." 14th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 20). 2020.
[15]docs.nvidia.com/deploy/
[16]Yu, Peifeng, and Mosharaf Chowdhury. "Salus: Fine-grained gpu sharing primitives for deep learning applications." arXiv preprint arXiv:1902.04610 (2019).
[18]Y. Lin, C. Lin, C. Lee and Y. Chung, "qCUDA: GPGPU Virtualization for High Bandwidth Efficiency," 2019 IEEE International Conference on Cloud Computing Technology and Science (CloudCom), Sydney, Australia, 2019, pp. 95-102, doi: 10.1109/CloudCom.2019.00025.
[19]netx-repo/PipeSwitch
[20]alibaba/GPU-scheduler-for-deep-learning
[21]NVIDIA Multi-Instance GPU User Guide
責任編輯:xj
原文標題:深度剖析:針對深度學習的GPU共享
文章出處:【微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
-
gpu
+關注
關注
28文章
4772瀏覽量
129348 -
深度學習
+關注
關注
73文章
5513瀏覽量
121540
原文標題:深度剖析:針對深度學習的GPU共享
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深度學習工作負載中GPU與LPU的主要差異

GPU在深度學習中的應用 GPUs在圖形設計中的作用
NPU在深度學習中的應用
pcie在深度學習中的應用
PyTorch GPU 加速訓練模型方法
AI大模型與深度學習的關系
FPGA做深度學習能走多遠?
深度學習中的時間序列分類方法
深度學習與nlp的區別在哪
深度學習與卷積神經網絡的應用
新手小白怎么學GPU云服務器跑深度學習?
深度解析深度學習下的語義SLAM






 工商網監
工商網監
評論