") 機(jī)器學(xué)習(xí)在線選擇模型和參數(shù),一鍵生成demo
機(jī)器學(xué)習(xí)在線選擇模型和參數(shù),一鍵生成demo
連機(jī)器學(xué)習(xí)的代碼,也可以套模(tou)版(lan)了。
現(xiàn)在,有一個Web應(yīng)用程序,可以生成用于機(jī)器學(xué)習(xí)的模板代碼(demo),目前支持PyTorch和scikit-learn。
同時,對于初學(xué)者來說,這也是一個非常好的工具。在模版中學(xué)習(xí)機(jī)器學(xué)習(xí)的代碼,可以少走一些彎路。
這也難怪開發(fā)者在項目的介紹中,這樣寫道:
這非常適合機(jī)器學(xué)習(xí)的初學(xué)者!
這個名為traingenerator的項目,已于最近成功上線,并沖上了reddit的熱榜。
這,究竟是一個什么樣的項目,就讓我們來看一下。
選擇模型和參數(shù),一鍵生成demo
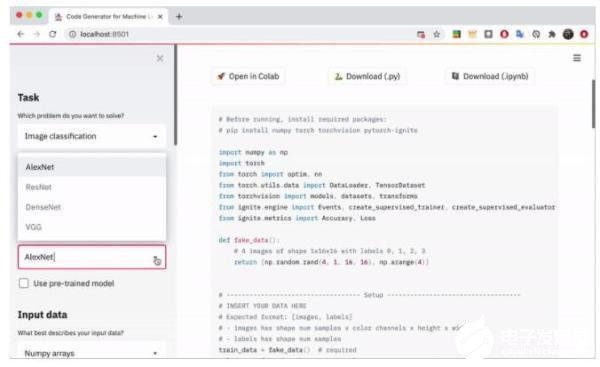
在任務(wù)處理上,目前的任務(wù)目標(biāo)只有圖像分類這一種可供選擇。
不過,開發(fā)者說,有更多功能正在路上,比如目標(biāo)檢測、語義分割等任務(wù)目標(biāo)。
而目前,Web支持的框架有PyTorch和scikit-learn,如下圖所示,在選定框架后,模版會自動變換。

在PyTorch下,可使用的模型有:AlexNet、ResNet、DenseNet及VGG。
而在scikit-learn下,可選擇的模型有:Support vectors、Random forest、Perceptron、K-nearest neighbors及Decision tree。
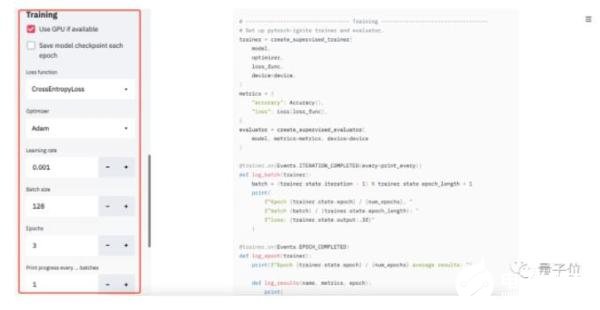
之后,在下方,在選擇不同的模型下,還可以調(diào)節(jié)不同的訓(xùn)練參數(shù)。
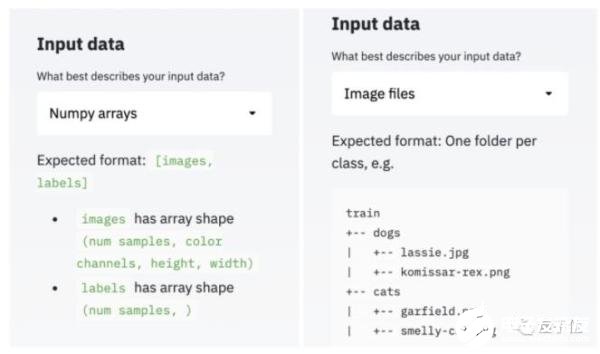
此外,可輸入的數(shù)據(jù)有著兩種選擇:Numpy arrays和Image files。
最后,在demo輸出上,你也有三個選擇,能夠分別導(dǎo)出.py、Jupyter notebook和Google Colab三種文件格式。

目前,該項目已經(jīng)在網(wǎng)站上線,可以直接在網(wǎng)頁上(網(wǎng)頁地址可在文末獲取)操作上述內(nèi)容,并直接生成demo。
運行方法
另外,如果你想要在本地運行或者部署,開發(fā)者還貼心地提供了使用指南。
安裝
git clone https://github.com/jrieke/traingenerator.git cd traingenerator pip install -r requirements.txt
如果要使「在Colab中打開」生效,還需要設(shè)置一個Github repo來存儲筆記本文件(因為Colab只能打開Github上的公共文件)。
設(shè)置repo后,創(chuàng)建一個.env文件其中包含:
GITHUB_TOKEN= REPO_NAME=《user/notebooks-repo》
本地運行
streamlit run app/main.py
確保總是從traingenerator目錄(而不是從應(yīng)用程序目錄)運行,否則應(yīng)用程序?qū)o法找到模板。
部署到Heroku
首先,安裝heroku并登錄。要創(chuàng)建新部署的話,便在traingenerator內(nèi)部運行:
heroku create git push heroku main heroku open
之后,更新已部署的應(yīng)用程序,提交更改并運行:
git push heroku main
如果你設(shè)置了一個Github repo來啟用「在Colab中打開」按鈕,你還需要運行:
heroku config:set GITHUB_TOKEN= heroku config:set REPO_NAME=《user/notebooks-repo》
測試
最后,進(jìn)行測試即可:
pytest 。/tests
該Web應(yīng)用程序上線了,并且代碼也已開源,感興趣的小伙伴可以點擊下方鏈接獲取。
Web應(yīng)用程序地址:
https://traingenerator.jrieke.com/
Github地址:
https://github.com/jrieke/traingenerator#installation
-
參數(shù)
+關(guān)注
關(guān)注
11文章
1859瀏覽量
32427 -
模型
+關(guān)注
關(guān)注
1文章
3307瀏覽量
49223 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8438瀏覽量
133086
發(fā)布評論請先 登錄
相關(guān)推薦
《具身智能機(jī)器人系統(tǒng)》第7-9章閱讀心得之具身智能機(jī)器人與大模型
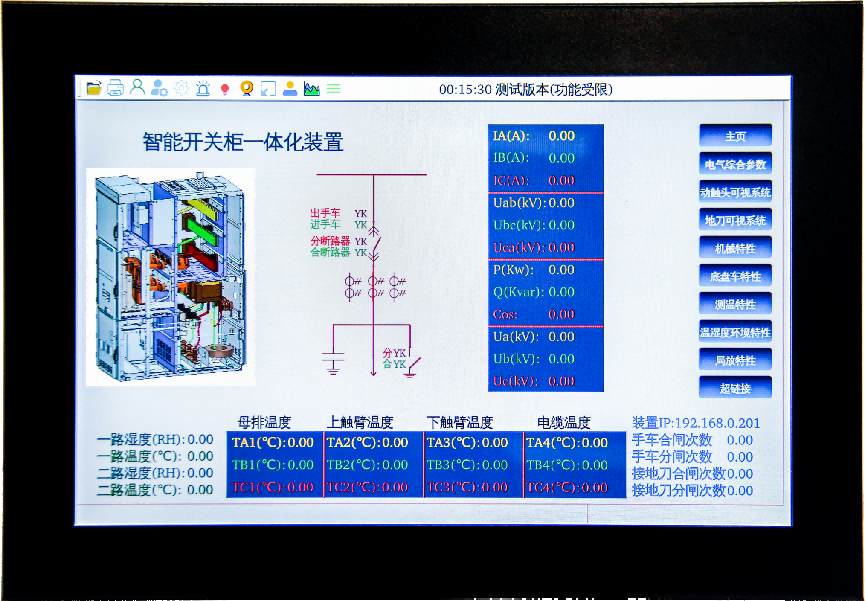
人機(jī)界面在開關(guān)柜一鍵順控中起到什么作用?
AI大模型與傳統(tǒng)機(jī)器學(xué)習(xí)的區(qū)別
10KV開關(guān)柜一鍵順控和110KV變電站一鍵順控哪些地方不同

LoRa無線一鍵報警安防建設(shè)系統(tǒng)
一鍵斷電開關(guān)的種類有哪些
一鍵斷電開關(guān)的控制原理是什么
一鍵生成屬于自己的AI客服:開啟智能服務(wù)新時代
【《大語言模型應(yīng)用指南》閱讀體驗】+ 基礎(chǔ)知識學(xué)習(xí)
變電站一鍵順控系統(tǒng)和開關(guān)柜一鍵順控有區(qū)別嗎?
光伏電站故障預(yù)警與在線監(jiān)測智能診斷系統(tǒng) 一鍵運檢 多維度故障對比
開關(guān)柜一鍵順控的技術(shù)難點和優(yōu)勢、發(fā)展趨勢?
Al大模型機(jī)器人
一鍵輕松配置 自連配置小程序上線啦!

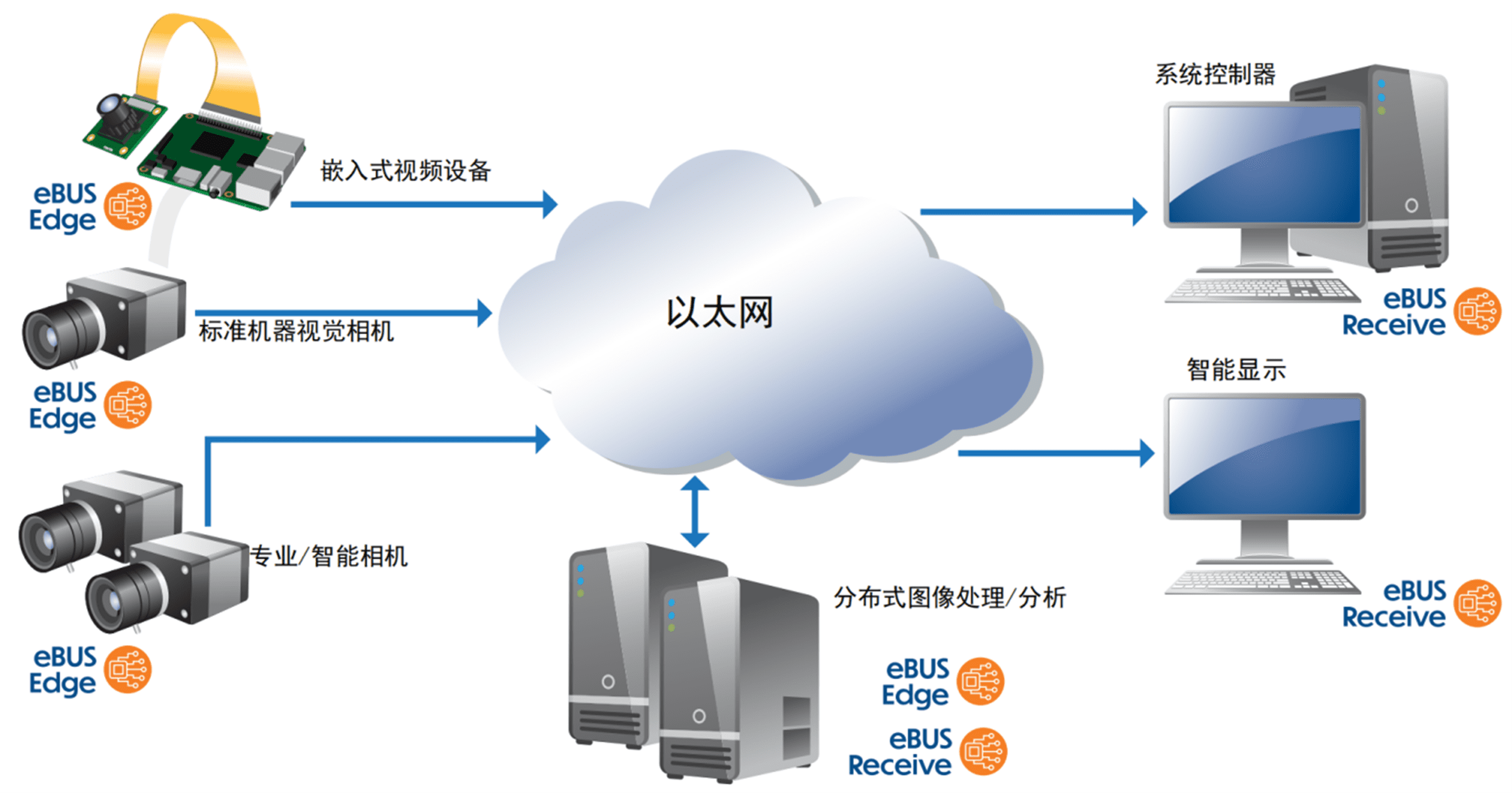
一鍵解鎖:將任意圖像設(shè)備秒變GigE Vision設(shè)備的終極秘訣





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論