") 深度過(guò)濾電子郵件里的“垃圾”的AI算法
深度過(guò)濾電子郵件里的“垃圾”的AI算法
目前,全球每天發(fā)出的3000億封電子郵件中,至少有半數(shù)屬于垃圾郵件。郵件服務(wù)供應(yīng)商的首要任務(wù)自然是過(guò)濾掉這些垃圾郵件,以確保用戶能夠快速找到真正具有價(jià)值的重要郵件。
但垃圾郵件的檢測(cè)本身相當(dāng)復(fù)雜。首先,垃圾郵件與正常郵件之間的界限非常模糊,而且評(píng)判標(biāo)準(zhǔn)往往會(huì)隨時(shí)間推移而有所變化。截至目前,各家郵件服務(wù)商普遍采用自動(dòng)化垃圾郵件檢測(cè)方法,而機(jī)器學(xué)習(xí)已經(jīng)成為其中最有效、也最受青睞的核心選項(xiàng)。雖然我們或多或少還是會(huì)看到垃圾郵件,但在機(jī)器學(xué)習(xí)算法的強(qiáng)大支持之下,大多數(shù)垃圾郵件已經(jīng)被從收件箱中直接清除。
那么,機(jī)器學(xué)習(xí)技術(shù)是怎么確定哪些是垃圾郵件、而哪些屬于正常郵件的?在本文中,我們將具體聊聊其中的工作原理。
挑戰(zhàn)所在
垃圾郵件有著多種不同風(fēng)格。有些只是些市場(chǎng)調(diào)研的信息,只是想引誘收件人打開(kāi)郵件或者傳播虛假信息。但也有一些屬于偽造型郵件,目標(biāo)是引導(dǎo)收件者點(diǎn)擊惡意鏈接或下載惡意軟件。
但二者的共同點(diǎn)在于,它們都跟收件人的實(shí)際需求沒(méi)有半毛錢關(guān)系。垃圾郵件檢測(cè)算法需要找到可靠的垃圾郵件過(guò)濾方法,在屏蔽不必要內(nèi)容的同時(shí),避免清理掉那些用戶希望接收并查看的真實(shí)郵件。此外,算法本身還得持續(xù)適應(yīng)新的趨勢(shì)性動(dòng)態(tài)——例如由新冠疫情引發(fā)的群體恐慌、選舉消息以及加密貨幣社區(qū)的迅速升溫等等。
靜態(tài)規(guī)則適合解決這類需求。例如,如果郵件包含大量抄送方、正文部分極短以及主題部分全部大寫,那么其很可能屬于垃圾郵件。同樣,某些發(fā)送方的域名可能已經(jīng)被列入垃圾郵件黑名單。但在大多數(shù)情況下,垃圾郵件檢測(cè)主要還是依賴于對(duì)郵件內(nèi)容的具體分析。
樸素貝葉斯機(jī)器學(xué)習(xí)
機(jī)器學(xué)習(xí)算法使用統(tǒng)計(jì)模型對(duì)數(shù)據(jù)進(jìn)行分類。在檢測(cè)垃圾郵件這一使用場(chǎng)景下,經(jīng)過(guò)訓(xùn)練的機(jī)器學(xué)習(xí)模型必須能夠根據(jù)郵件中的詞匯順序,判斷其可能屬于垃圾郵件抑或是正常郵件。
不同的機(jī)器學(xué)習(xí)算法都具備一定的垃圾郵件檢測(cè)能力,但目前最受關(guān)注的仍然是“樸素貝葉斯”算法。顧名思義,樸素貝葉斯算法以“貝葉斯定理”為基礎(chǔ),即基于先驗(yàn)知識(shí)對(duì)事件的概率做出描述。
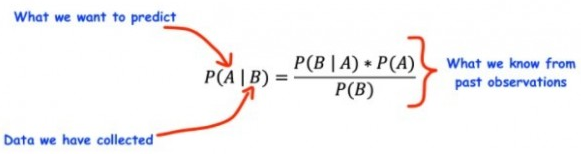
之所以被冠名以“樸素”,是因?yàn)樗紫燃僭O(shè)觀測(cè)的特征只獨(dú)立存在。例如,如果使用樸素貝葉斯機(jī)器學(xué)習(xí)方法來(lái)預(yù)測(cè)是否會(huì)下雨,那么只需要濕度及溫度等少數(shù)特征,即可對(duì)是否降雨這個(gè)事件做出預(yù)測(cè)。
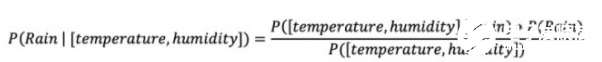
在檢測(cè)垃圾郵件時(shí),情況無(wú)疑更為復(fù)雜。我們的目標(biāo)變量為給定電子郵件屬于“垃圾”或者“非垃圾”。其特征則為電子郵件正文中包含的單詞或單詞組合。簡(jiǎn)而言之,我們希望根據(jù)文本內(nèi)容判斷出當(dāng)前郵件屬于垃圾郵件的可能性。
這里需要強(qiáng)調(diào)的是,檢測(cè)垃圾郵件時(shí)使用的各項(xiàng)特征不一定彼此獨(dú)立。例如,我們可以將詞匯“烤”、“奶酪”和“三明治”結(jié)合起來(lái),其在郵件語(yǔ)境下是否連續(xù)存在將表達(dá)出完全不同的含義。另一個(gè)更明確的例子就是“不”和“好玩”,獨(dú)立與非獨(dú)立分析將帶來(lái)徹底相反的結(jié)論。但好消息是,雖然文本數(shù)據(jù)內(nèi)的特征獨(dú)立性往往非常復(fù)雜,但只要正確加以配置,樸素貝葉斯分類器同樣能夠有效處理大部分自然語(yǔ)言處理任務(wù)。
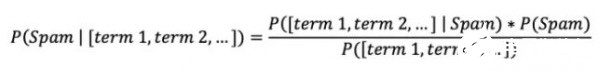
關(guān)于數(shù)據(jù)
垃圾郵件檢測(cè)屬于有監(jiān)督機(jī)器學(xué)習(xí)問(wèn)題。這意味著您需要為機(jī)器學(xué)習(xí)模型提供大量垃圾郵件與正常消息示例,幫助其從中找出相應(yīng)模式以準(zhǔn)確將二者區(qū)分開(kāi)來(lái)。
大多數(shù)電子郵件服務(wù)商都擁有自己的標(biāo)記郵件數(shù)據(jù)集。例如,每當(dāng)您在Gmail賬戶內(nèi)將一封電子郵件標(biāo)記為垃圾郵件,谷歌方面就會(huì)使用這部分?jǐn)?shù)據(jù)訓(xùn)練自己的機(jī)器學(xué)習(xí)算法。(請(qǐng)注意,谷歌使用的垃圾郵件檢測(cè)算法要比本文示例復(fù)雜得多,而且他們還擁有一套用于防止「報(bào)告垃圾郵件」功能遭到濫用的完善機(jī)制。)

目前也有不少值得一試的開(kāi)源數(shù)據(jù)集,例如加利福尼亞大學(xué)歐文分校的垃圾郵件數(shù)據(jù)庫(kù)數(shù)據(jù)集以及安然垃圾郵件數(shù)據(jù)集。但請(qǐng)注意,這些數(shù)據(jù)集僅供教育及測(cè)試使用,對(duì)于生產(chǎn)級(jí)機(jī)器學(xué)習(xí)模型的創(chuàng)建沒(méi)有太大實(shí)際意義。
自行托管電子郵件服務(wù)器的供應(yīng)商可以創(chuàng)建起專門的數(shù)據(jù)集,并根據(jù)具體行業(yè)及用語(yǔ)對(duì)機(jī)器學(xué)習(xí)模型加以調(diào)整。例如,金融服務(wù)類企業(yè)的數(shù)據(jù)集在內(nèi)容上將與建筑類企業(yè)存在巨大差異。
訓(xùn)練機(jī)器學(xué)習(xí)模型
盡管近年來(lái),自然語(yǔ)言處理技術(shù)取得了令人振奮的進(jìn)步,但人工智能算法本身仍然無(wú)法像人類那樣順暢理解語(yǔ)言內(nèi)容。
因此,開(kāi)發(fā)垃圾郵件檢測(cè)類機(jī)器學(xué)習(xí)模型的一大關(guān)鍵步驟,在于準(zhǔn)備數(shù)據(jù)以進(jìn)行統(tǒng)計(jì)處理。在訓(xùn)練樸素貝葉斯分類器之前,必須通過(guò)特定步驟整理出垃圾郵件與正常郵件的語(yǔ)料庫(kù)。
考慮一套包含以下語(yǔ)句的數(shù)據(jù)集:
Steve想為聚會(huì)買點(diǎn)烤芝士三明治
Sally正為晚飯燒烤雞肉
我買了奶油芝士做蛋糕
在訓(xùn)練模型以及隨后對(duì)新數(shù)據(jù)進(jìn)行預(yù)測(cè)時(shí),我們首先需要對(duì)文本數(shù)據(jù)進(jìn)行“令牌化”,而后將其添加到機(jī)器學(xué)習(xí)算法當(dāng)中。在本質(zhì)上,令牌化是指將文本數(shù)據(jù)拆分成較小的部分。如果您將上述數(shù)據(jù)集按用詞進(jìn)行拆分,那么將獲得以下詞匯。請(qǐng)注意,每個(gè)詞只出現(xiàn)一次。
Steve、想為、聚會(huì)、買、烤、芝士、三明治、Sally、正、晚飯、燒烤、雞肉、我、買了、奶油、蛋糕
我們可以刪除掉那些垃圾郵件和正常郵件中都會(huì)出現(xiàn)的詞匯,因?yàn)檫@些詞匯沒(méi)法幫我們區(qū)分出郵件本身的性質(zhì)。這些被稱為“停用詞”,常見(jiàn)的例子包括這、那、是、要、某等。在以上數(shù)據(jù)集中,刪除停用詞之后,我們的詞匯量將快速縮減為5個(gè)。
我們還可以使用其他技術(shù),例如“詞干提取”與“詞條化”等,借此將詞匯轉(zhuǎn)換為更基礎(chǔ)的形式。繼續(xù)來(lái)看我們的示例數(shù)據(jù)集,其中的“買了”和“買”有著相同的詞根,“烤”和“燒烤”也有相同的詞根。通過(guò)這樣的處理,我們可以進(jìn)一步簡(jiǎn)化機(jī)器模型。
在某些情況下,大家還可以考慮使用雙詞(包含兩個(gè)詞的令牌)、三詞(包含三個(gè)詞的令牌)或者更長(zhǎng)的N字令牌。例如,使用雙詞形式對(duì)上述數(shù)據(jù)集進(jìn)行標(biāo)記,將得到“芝士蛋糕”表達(dá);三詞形式則會(huì)帶來(lái)“烤芝士三明治”表達(dá)。
在數(shù)據(jù)處理完成之后,您將獲得一份術(shù)語(yǔ)表,這些術(shù)語(yǔ)定義了機(jī)器學(xué)習(xí)模型中的各項(xiàng)特征。接下來(lái),您需要確定哪些詞匯或者詞匯序列(如果使用N詞表達(dá))與垃圾郵件及正常郵件相關(guān)。
在訓(xùn)練數(shù)據(jù)集上訓(xùn)練機(jī)器學(xué)習(xí)模型時(shí),需要根據(jù)不同術(shù)語(yǔ)在垃圾郵件及正常郵件中出現(xiàn)的次數(shù)為其分配權(quán)重。例如,如果“贏大獎(jiǎng)”屬于其中一項(xiàng)特征,而且只出現(xiàn)在垃圾郵件當(dāng)中,那么任何具有此特征的郵件都很可能被歸類為垃圾郵件。與之對(duì)應(yīng),如果“重要會(huì)議”只出現(xiàn)在正常電子郵件中,那么任何具有此特征的郵件都很可能被歸類為正常郵件。
在數(shù)據(jù)處理完成,并對(duì)各特征分配了權(quán)重之后,您的機(jī)器學(xué)習(xí)模型即可過(guò)濾垃圾郵件。在收到一封新郵件之后,其中的文本將接受標(biāo)記并按照貝葉斯公式運(yùn)行。郵件正文中的每個(gè)術(shù)語(yǔ)均將乘以其權(quán)重,權(quán)重的總和即代表該電子郵件屬于垃圾郵件的可能性。(實(shí)際計(jì)算過(guò)程要更為復(fù)雜,但這里為了簡(jiǎn)便起見(jiàn),我們直接求取所有權(quán)重之和。)
使用機(jī)器學(xué)習(xí)技術(shù)實(shí)現(xiàn)高級(jí)垃圾郵件檢測(cè)
聽(tīng)起來(lái)很簡(jiǎn)單,但樸素貝葉斯機(jī)器學(xué)習(xí)算法在處理大部分文本分類任務(wù)(包括垃圾郵件檢測(cè))時(shí)都取得了不錯(cuò)的效果。
但它仍然不夠完美,這是肯定的。
與其他機(jī)器學(xué)習(xí)算法一樣,樸素貝葉斯算法無(wú)法理解語(yǔ)言的上下文,只能依靠詞匯之間的統(tǒng)計(jì)關(guān)系來(lái)判斷一段文本是否屬于某個(gè)類別。這意味著,如果發(fā)件人在郵件末尾添加一些符合正常郵件條件的詞匯,或者將符合垃圾郵件特征的某些術(shù)語(yǔ)替換為其他同義詞或相關(guān)詞,那么樸素貝葉斯算法很可能將垃圾郵件錯(cuò)誤判斷為正常郵件。
樸素貝葉斯方法當(dāng)然不是唯一能夠檢測(cè)出垃圾郵件的機(jī)器學(xué)習(xí)算法。其他流行的算法選項(xiàng)還包括遞歸神經(jīng)網(wǎng)絡(luò)(RNN)與transformers,它們都能高效處理電子郵件及文本消息等有序數(shù)據(jù)。
最后需要注意的是,垃圾郵件檢測(cè)一直在不斷發(fā)展。就在開(kāi)發(fā)者利用AI乃至其他技術(shù)檢測(cè)并過(guò)濾電子郵件中的有害消息時(shí),垃圾郵件發(fā)送者也在尋求新的方法,希望騙過(guò)檢測(cè)系統(tǒng)、將垃圾郵件發(fā)送到收件者手中。也正因?yàn)槿绱耍娮余]件服務(wù)商才需要持續(xù)運(yùn)用用戶的數(shù)據(jù)改進(jìn)并更新其垃圾郵件檢測(cè)器。
責(zé)編AJX
-
算法
+關(guān)注
關(guān)注
23文章
4630瀏覽量
93348 -
AI
+關(guān)注
關(guān)注
87文章
31513瀏覽量
270309 -
電子郵件
+關(guān)注
關(guān)注
0文章
110瀏覽量
15395
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
電子郵件的使用培圳教程
電子郵件的使用教程
基于協(xié)同過(guò)濾的垃圾郵件過(guò)濾系統(tǒng)
代價(jià)敏感支持向量機(jī)在垃圾郵件過(guò)濾中的應(yīng)用
基于樸素貝葉斯算法的垃圾郵件網(wǎng)關(guān)
基于Bayes的一種改良垃圾郵件過(guò)濾模型
垃圾郵件(Spam)與郵件過(guò)濾技術(shù)
電子郵件使用模擬實(shí)驗(yàn)
病毒和蠕蟲如何在電子郵件中傳播?
垃圾郵件詳解
CCERT中文垃圾郵件過(guò)濾解決方案
中文垃圾郵件過(guò)濾郵件服務(wù)器的實(shí)現(xiàn)_李玉峰
如何向您選擇的某人發(fā)送電子郵件





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論