") 深度學(xué)習(xí):知識蒸餾的全過程
深度學(xué)習(xí):知識蒸餾的全過程
知識蒸餾的核心思想是通過遷移知識,從而通過訓(xùn)練好的大模型得到更加適合推理的小模型。本文作者介紹了知識蒸餾的全過程,以及引用Hinton等人的實驗結(jié)果解釋說明,并提出了知識蒸餾的一些延伸工作方向。
0. 寫在前面
有人說過:“神經(jīng)網(wǎng)絡(luò)用剩的logits不要扔,沾上雞蛋液,裹上面包糠...” 這兩天對知識蒸餾(Knowledge Distillation)萌生了一點興趣,正好寫一篇文章分享一下。這篇文章姑且算是一篇小科普。
1. 從模型壓縮開始
各種模型算法,最終目的都是要為某個應(yīng)用服務(wù)。在買賣中,我們需要控制收入和支出。類似地,在工業(yè)應(yīng)用中,除了要求模型要有好的預(yù)測(收入)以外,往往還希望它的「支出」要足夠小。具體來說,我們一般希望部署到應(yīng)用中的模型使用較少的計算資源(存儲空間、計算單元等),產(chǎn)生較低的時延。
在深度學(xué)習(xí)的背景下,為了達到更好的預(yù)測,常常會有兩種方案:1. 使用過參數(shù)化的深度神經(jīng)網(wǎng)絡(luò),這類網(wǎng)絡(luò)學(xué)習(xí)能力非常強,因此往往加上一定的正則化策略(如dropout);2. 集成模型(ensemble),將許多弱的模型集成起來,往往可以實現(xiàn)較好的預(yù)測。這兩種方案無疑都有較大的「支出」,需要的計算量和計算資源很大,對部署非常不利。這也就是模型壓縮的動機:我們希望有一個規(guī)模較小的模型,能達到和大模型一樣或相當(dāng)?shù)慕Y(jié)果。當(dāng)然,從頭訓(xùn)練一個小模型,從經(jīng)驗上看是很難達到上述效果的,也許我們能先訓(xùn)練一個大而強的模型,然后將其包含的知識轉(zhuǎn)移給小的模型呢?如何做到呢?
* 下文統(tǒng)一將要訓(xùn)練的小模型稱為新模型,將以及訓(xùn)練的大模型稱為原模型。
Rich Caruana等人在[1]中指出,可以讓新模型近似(approximate)原模型(模型即函數(shù))。注意到,在機器學(xué)習(xí)中,我們常常假定輸入到輸出有一個潛在的函數(shù)關(guān)系,這個函數(shù)是未知的:從頭學(xué)習(xí)一個新模型就是從有限的數(shù)據(jù)中近似一個未知的函數(shù)。如果讓新模型近似原模型,因為原模型的函數(shù)是已知的,我們可以使用很多非訓(xùn)練集內(nèi)的偽數(shù)據(jù)來訓(xùn)練新模型,這顯然要更可行。
這樣,原來我們需要讓新模型的softmax分布與真實標(biāo)簽匹配,現(xiàn)在只需要讓新模型與原模型在給定輸入下的softmax分布匹配了。直觀來看,后者比前者具有這樣一個優(yōu)勢:經(jīng)過訓(xùn)練后的原模型,其softmax分布包含有一定的知識——真實標(biāo)簽只能告訴我們,某個圖像樣本是一輛寶馬,不是一輛垃圾車,也不是一顆蘿卜;而經(jīng)過訓(xùn)練的softmax可能會告訴我們,它最可能是一輛寶馬,不大可能是一輛垃圾車,但絕不可能是一顆蘿卜[2]。
2. 為什么叫「蒸餾」?
接續(xù)前面的討論,我們的目標(biāo)是讓新模型與原模型的softmax輸出的分布充分接近。直接這樣做是有問題的:在一般的softmax函數(shù)中,自然指數(shù) 先拉大logits之間的差距,然后作歸一化,最終得到的分布是一個arg max的近似 (參考我之前的文章:淺談Softmax函數(shù)),其輸出是一個接近one-hot的向量,其中一個值很大,其他的都很小。這種情況下,前面說到的「可能是垃圾車,但絕不是蘿卜」這種知識的體現(xiàn)是非常有限的。相較類似one-hot這樣的硬性輸出,我們更希望輸出更「軟」一些。
一種方法是直接比較logits來避免這個問題。具體地,對于每一條數(shù)據(jù),記原模型產(chǎn)生的某個logits是 ,新模型產(chǎn)生的logits是 ,我們需要最小化
文獻[2]提出了更通用的一種做法。考慮一個廣義的softmax函數(shù)
其中 是溫度,這是從統(tǒng)計力學(xué)中的玻爾茲曼分布中借用的概念。容易證明,當(dāng)溫度 趨向于0時,softmax輸出將收斂為一個one-hot向量(證明可以參考我之前的文章:淺談Softmax函數(shù),將 替換為 即可);溫度 趨向于無窮時,softmax的輸出則更「軟」。因此,在訓(xùn)練新模型的時候,可以使用較高的 使得softmax產(chǎn)生的分布足夠軟,這時讓新模型的softmax輸出近似原模型;在訓(xùn)練結(jié)束以后再使用正常的溫度 來預(yù)測。具體地,在訓(xùn)練時我們需要最小化兩個分布的交叉熵(Cross-entropy),記新模型利用公式 產(chǎn)生的分布是 ,原模型產(chǎn)生的分布是 ,則我們需要最小化
在化學(xué)中,蒸餾是一個有效的分離沸點不同的組分的方法,大致步驟是先升溫使低沸點的組分汽化,然后降溫冷凝,達到分離出目標(biāo)物質(zhì)的目的。在前面提到的這個過程中,我們先讓溫度升高,然后在測試階段恢復(fù)「低溫」,從而將原模型中的知識提取出來,因此將其稱為是蒸餾,實在是妙。
當(dāng)然,如果轉(zhuǎn)移時使用的是有標(biāo)簽的數(shù)據(jù),那么也可以將標(biāo)簽與新模型softmax分布的交叉熵加入到損失函數(shù)中去。這里需要將式 乘上一個 ,這是為了讓損失函數(shù)的兩項的梯度大致在一個數(shù)量級上(參考公式 ),實驗表明這將大大改善新模型的表現(xiàn)(考慮到加入了更多的監(jiān)督信號)。
3. 與直接優(yōu)化logits差異相比
由公式 ,對于交叉熵?fù)p失來說,其對于新模型的某個logit 的梯度是
由于 與 是等價無窮小(時**)**,易知,當(dāng) 充分大時,有
假設(shè)所有l(wèi)ogits對每個樣本都是零均值化的,即 ,則有
所以,如果:1. 非常大,2. logits對所有樣本都是零均值化的,則知識蒸餾和最小化logits的平方差(公式 )是等價的(因為梯度大致是同一個形式)。實驗表明,溫度 不能取太大,而應(yīng)該使用某個適中的值,這表明忽略極負(fù)的logits對新模型的表現(xiàn)很有幫助(較低的溫度產(chǎn)生的分布比較「硬」,傾向于忽略logits中極小的負(fù)值)。
4. 實驗與結(jié)論
Hinton等人做了三組實驗,其中兩組都驗證了知識蒸餾方法的有效性。在MNIST數(shù)據(jù)集上的實驗表明,即便有部分類別的樣本缺失,新模型也可以表現(xiàn)得很不錯,只需要修改相應(yīng)的偏置項,就可以與原模型表現(xiàn)相當(dāng)。在語音任務(wù)的實驗也表明,蒸餾得到的模型比從頭訓(xùn)練的模型捕捉了更多數(shù)據(jù)集中的有效信息,表現(xiàn)僅比集成模型低了0.3個百分點。總體來說知識蒸餾是一個簡單而有效的模型壓縮/訓(xùn)練方法。這大體上是因為原模型的softmax提供了比one-hot標(biāo)簽更多的監(jiān)督信號[3]。
知識蒸餾在后續(xù)也有很多延伸工作。在NLP方面比較有名的有Yoon Kim等人的Sequence-Level Knowledge Distillation 等。總的來說,對一些比較臃腫、不便部署的模型,可以將其「知識」轉(zhuǎn)移到小的模型上。比如,在機器翻譯中,一般的模型需要有較大的容量(capacity)才可能獲得較好的結(jié)果;現(xiàn)在非常流行的BERT及其變種,規(guī)模都非常大;更不用提,一些情形下我們需要將這些本身就很大的深度模型集成為一個ensemble,這時候,可以用知識蒸餾壓縮出一個較小的、「便宜」的模型。
文章地址:https://arxiv.org/abs/1606.07947
另外,在多任務(wù)的情境下,使用一般的策略訓(xùn)練一個多任務(wù)模型,可能達不到比單任務(wù)更好的效果,文獻[3]探索了使用知識蒸餾,利用單任務(wù)的模型來指導(dǎo)訓(xùn)練多任務(wù)模型的方法,很值得參考。
補充
鑒于評論區(qū)有知友對公式 有疑問,簡單補充一下這里梯度的推導(dǎo)(其實就是交叉熵?fù)p失對softmax輸入的梯度,LOL)。
* 這部分有一點繁瑣,能接受公式 的讀者可以跳過。
由鏈?zhǔn)椒▌t,有
注意到 是原模型產(chǎn)生的softmax輸出,與 無關(guān)。
后一項 比較容易得到,因為 ,所以
則 是一個 維向量
前一項 是一個 的方陣,分類討論可以得到。參考公式 ,記 ,由除法的求導(dǎo)法則,輸出元素 對輸入 的偏導(dǎo)是
注意上面右側(cè)加方框部分,可以進一步展開
這樣,代入公式 ,并且將括號展開,可以得到
左側(cè)方框內(nèi)偏導(dǎo)可以分類討論得到
帶入式 ,得到
所以 形式如下
代入式 ,可得
所以有公式 , 。
參考
[1] Caruana et al., Model Compression, 2006
[2] Hinton et al., Distilling the Knowledge in a Neural Network, 2015
[3] Kevin Clark et al., BAM! Born-Again Multi-Task Networks for Natural Language Understanding
責(zé)任編輯:xj
原文標(biāo)題:知識蒸餾是什么?一份入門隨筆
文章出處:【微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4781瀏覽量
101176 -
模型
+關(guān)注
關(guān)注
1文章
3313瀏覽量
49231 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5516瀏覽量
121554
原文標(biāo)題:知識蒸餾是什么?一份入門隨筆
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
大連理工提出基于Wasserstein距離(WD)的知識蒸餾方法
GPU深度學(xué)習(xí)應(yīng)用案例
AI大模型與深度學(xué)習(xí)的關(guān)系
天合光能獲“全過程功率測量控制評估認(rèn)證”證書
利用Matlab函數(shù)實現(xiàn)深度學(xué)習(xí)算法
紅豆Cat 1開源 項目四: 從0-1設(shè)計一款TCP版本DTU產(chǎn)品的軟硬件全過程

紅豆Cat 1開源 項目三: 從0-1設(shè)計一款HTTP版本RTU 支持GNSS 產(chǎn)品的軟硬件全過程
紅豆Cat 1開源 項目二: 從0-1設(shè)計一款MQTT版本DTU 支持GNSS 產(chǎn)品的軟硬件全過程
紅豆Cat 1開源 項目一: 從0-1設(shè)計一款TCP版本RTU 支持Modbus+GNSS 產(chǎn)品的軟硬件全過程
解讀PyTorch模型訓(xùn)練過程
深度學(xué)習(xí)的典型模型和訓(xùn)練過程
深度學(xué)習(xí)模型訓(xùn)練過程詳解
精準(zhǔn)到毫米:H9激光切管機鋁材切割與打孔全過程解析

物聯(lián)網(wǎng)與醫(yī)療廢物處置全過程電子信息化跟蹤管理系統(tǒng)研究
永磁同步電機全速域矢量控制的全過程介紹
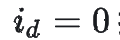





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論