 Kafka框架的工作原理及工作流程
Kafka框架的工作原理及工作流程
Kafka在大數據技術生態當中,以作為消息系統而聞名,面對活躍的流式數據,提供高吞吐量的服務,在實時大數據處理場景下,可以說是一大利器,國內外大廠都有應用。今天的大數據開發技術分享,我們就主要來講講Kafka框架的工作原理。
Kafka概述
官方定義,Kakfa是一個分布式的基于發布/訂閱模式的消息隊列,主要應用于大數據的實時處理領域。
通常來說,消息隊列的模式分為兩種:
①點對點模式:消息生產者發送消息到消息隊列中,然后消息消費者從隊列中取出并且消費消息,消息被消費后,隊列中不在存儲。
②發布/訂閱模式(一對多,消費者消費數據之后不會清除消息):消息生產者將消息發布到Topic中,同時有多個消息消費者(訂閱)消費該消息。
Kafka就是典型的發布/訂閱模式,更加適用于實時大數據場景下的消息服務。
Kafka基礎架構
Kafka的基礎架構主要有Broker、生產者、消費者組構成,當前還包括ZooKeeper。

生產者負責發送消息,Broker負責緩沖消息,Broker中可以創建Topic,每個Topic又有Partition和Replication的概念。
消費者組負責處理消息,同一個消費者組的消費者不能消費同一個Partition中的數據。
消費者組主要是提高消費能力,比如之前是一個消費者消費100條數據,現在是2個消費者消費100條數據,可以提高消費能力。
所以消費者組的消費者的個數要小于Partition的個數,不然就會有消費者沒有Partition可以消費,造成資源的浪費。
注意:不同消費者組的消費者是可以消費相同的Partition數據。
Kakfa如果要組件集群,則只需要注冊到一個ZooKeeper中就可以了,ZooKeeper中還保留消息消費的進度或者說偏移量或者消費位置:
0.9之前的版本偏移量存儲在ZooKeeper。
0.9之后的版本偏移量存儲在Kafka中。Kafka定義了一個系統Topic,專用用來存儲偏移量的數據。這樣做主要是考慮到頻繁更改偏移量,對ZooKeeper的壓力較大,而且Kafka本身自己的處理也較復雜。
Kafka不能保證消息的全局有序,只能保證消息在Partition內有序,因為消費者消費消息是在不同的Partition中隨機的。
Kafka工作流程
Kafka中的消息是以Topic進行分類的,生產者生成消息、消費者消費消息都面向Topic。
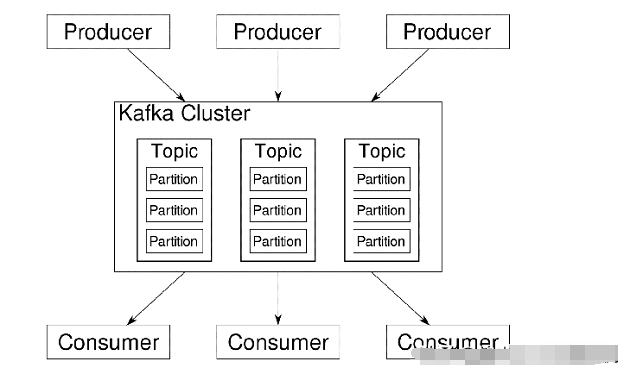
Topic是一個邏輯上的概念,而Partition是物理上的概念。每個Partition又有副本的概念。
每個Partition對應于一個Log文件,該Log文件中存儲的就是生產者生成的數據,生產者生成的數據會不斷的追加到該Log的文件末端。
且每條數據都有自己的Offset,消費者都會實時記錄自己消費到了那個Offset,以便出錯的時候從上次的位置繼續消費,這個Offset就保存在Index文件中。
Kafka的Offset是分區內有序的,但是在不同分區中是無順序的,Kafka不保證數據的全局有序。
關于大數據開發,Kafka工作原理入門,以上就為大家做了簡單的介紹了。Kafka在大數據技術生態當中,普及度是非常高的,尤其是擁有豐富數據資源的企業,更加青睞于使用kafka。
責任編輯人:CC
-
大數據
+關注
關注
64文章
8908瀏覽量
137791 -
kafka
+關注
關注
0文章
52瀏覽量
5243
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論