") 3種MongoDB的高可用架構(gòu)介紹
3種MongoDB的高可用架構(gòu)介紹
MongoDB 背景
MongoDB 是一款功能完善的分布式文檔數(shù)據(jù)庫,是一款非常出名的 NoSQL 數(shù)據(jù)庫。當(dāng)前國內(nèi)使用 Mongodb 的大型實踐越來越多,MongoDB 為我司提供了重要的數(shù)據(jù)庫存儲服務(wù),支撐著每天近千萬級 QPS 峰值讀寫,數(shù)萬億級數(shù)據(jù)量存儲服務(wù)。
MongoDB 在高性能、動態(tài)擴縮容、高可用、易部署、易使用、海量數(shù)據(jù)存儲等方面擁有很大優(yōu)勢。近些年,MongoDB 在 DB-Engines 流行度排行榜穩(wěn)居榜單 Top5 ,且歷年得分是持續(xù)增長的,具體如下圖所示:
DB-Engines 是一個對數(shù)據(jù)庫管理系統(tǒng)受歡迎程度進行排名的網(wǎng)站。
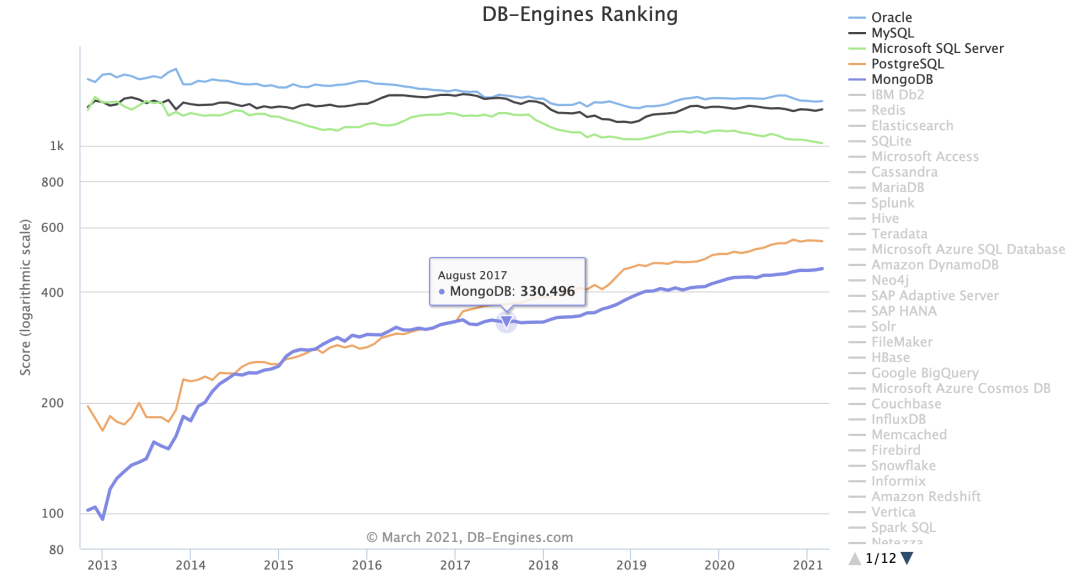
排名分?jǐn)?shù):
MongoDB 是 Top5 內(nèi)的唯一的非關(guān)系型數(shù)據(jù)庫。我們今天從比較高的層面來觀摩學(xué)習(xí)下 MongoDB 的幾種高可用架構(gòu)。通過觀察這幾種架構(gòu)我們甚至能體會到通用的分布式架構(gòu)的一個演進方向。
高可用架構(gòu)
高可用性 HA(High Availability)指的是縮短因正常運維或者非預(yù)期故障而導(dǎo)致的停機時間,提高系統(tǒng)可用性。
那么問題來了,都說自己的服務(wù)高可用,高可用能量化衡量嗎?能不能比出個高低呢?
可以,這里引出一個 SLA 的概念。SLA 是 Service Level Agreement 的縮寫,中文含義:服務(wù)等級協(xié)議。SLA 就是用來量化可用性的協(xié)議,在雙方認(rèn)可的前提條件下,服務(wù)提供商與用戶間定義的一種雙方認(rèn)可的協(xié)定。SLA 是判定服務(wù)質(zhì)量的重要指標(biāo)。
問題來了,SLA 是怎么量化的?其實就是按照停服時間算的。怎么算的?舉個例子:
1 年 = 365 天 = 8760 小時
99.9 停服時間:8760 * 0.1% = 8760 * 0.001 = 8.76小時
99.99 停服時間:8760 * 0.0001 = 0.876 小時 = 52.6 分鐘
99.999 停服時間:8760 * 0.00001 = 0.0876 小時 = 5.26分鐘
也就是說,如果一家公有云廠商提供對象存儲的服務(wù),SLA 協(xié)議指明提供 5 個 9 的高可用服務(wù),那就要保證一年的時間內(nèi)對象存儲的停服時間少于 5.26 分鐘,如果超過這個時間,就算違背了 SLA 協(xié)議,可以找公有云提出賠償。
說回高可用的話題,大白話就是,無論出啥事都不能讓承載的業(yè)務(wù)受影響,這就是高可用。
前面我們說過,無論是數(shù)據(jù)的高可靠,還是組件的高可用全都是一個解決方案:冗余。我們通過多個組件和備份導(dǎo)致對外提供一致性和不中斷的服務(wù)。冗余是根本,但是怎么來使用冗余則各有不同。
以下我們就按照不同的冗余處理策略,可以總結(jié)出 MongoDB 幾個特定的模式,這個也是通用性質(zhì)的架構(gòu),在其他的分布式系統(tǒng)也是常見的。
我們從 Mongo 的三種高可用模式逐一介紹,這三種模式也代表了通用分布式系統(tǒng)下高可用架構(gòu)的進化史,分別是 Master-Slave,Replica Set,Sharding 模式。
Master-Slave 模式
Mongodb 提供的第一種冗余策略就是 Master-Slave 策略,這個也是分布式系統(tǒng)最開始的冗余策略,這種是一種熱備策略。
Master-Slave 架構(gòu)一般用于備份或者做讀寫分離,一般是一主一從設(shè)計和一主多從設(shè)計。
Master-Slave 由主從角色構(gòu)成:
Master ( 主 )
可讀可寫,當(dāng)數(shù)據(jù)有修改的時候,會將 Oplog 同步到所有連接的Salve 上去。
Slave ( 從 )
只讀,所有的 Slave 從 Master 同步數(shù)據(jù),從節(jié)點與從節(jié)點之間不感知。
如圖:
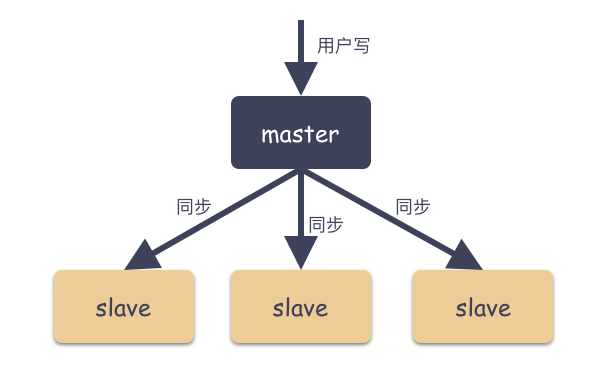
通過上面的圖,這是一種典型的扇形結(jié)構(gòu)。
Master-Slave 對讀寫分離的思考
Master 對外提供讀寫服務(wù),有多個 Slave 節(jié)點的話,可以用 Slave 節(jié)點來提供讀服務(wù)的節(jié)點。
思考,這種讀寫分離有什么問題?
有一個不可逾越的問題:數(shù)據(jù)不一致問題。根本原因在于只有 Master 節(jié)點可以寫,Slave 節(jié)點只能同步 Master 數(shù)據(jù)并對外提供讀服務(wù),所以你會發(fā)現(xiàn)這個是一個異步的過程。
雖然最終數(shù)據(jù)會被 Slave 同步到,在數(shù)據(jù)完全一致之前,數(shù)據(jù)是不一致的,這個時候去 Slave 節(jié)點讀就會讀到舊的數(shù)據(jù)。所以,總結(jié)來說:讀寫分離的結(jié)構(gòu)只適合特定場景,對于必須需要數(shù)據(jù)強一致的場景是不合適這種讀寫分離的。
Master-Slave 對容災(zāi)的思考
當(dāng) Master 節(jié)點出現(xiàn)故障的時候,由于 Slave 節(jié)點有備份數(shù)據(jù),有數(shù)據(jù)就好辦呀。只要有數(shù)據(jù)還在,對用戶就有交代。這種 Master 故障的時候,可以通過人為 Check 和操作,手動把 Slave 節(jié)點指定為 Master 節(jié)點,這樣又能對外提供服務(wù)了。
思考下這種模式有什么特點?
Master-Slave 只區(qū)分兩種角色:Master 節(jié)點,Slave 節(jié)點;
Master-Slave 的角色是靜態(tài)配置的,不能自動切換角色,必須人為指定;
用戶只能寫 Master 節(jié)點,Slave 節(jié)點只能從 Master 拉數(shù)據(jù);
還有一個關(guān)鍵點:Slave 節(jié)點只和 Master 通信,Slave 之間相互不感知,這種好處對于 Master 來說優(yōu)點是非常輕量,缺點是:系統(tǒng)明顯存在單點,那么多 Slave 只能從 Master 拉數(shù)據(jù),而無法提供自己的判斷;
以上特點存在什么問題?
最大的第一個問題就是可用性差。因為很容易理解,因為主節(jié)點掛掉的時候,必須要人為操作處理,這里就是一個巨大的停服窗口;
Master-Slave 的現(xiàn)狀
MongoDB 3.6 起已不推薦使用主從模式,自 MongoDB 3.2 起,分片群集組件已棄用主從復(fù)制。因為 Master-Slave 其中 Master 宕機后不能自動恢復(fù),只能靠人為操作,可靠性也差,操作不當(dāng)就存在丟數(shù)據(jù)的風(fēng)險。
怎么搭建 Master-Slave 模式?
啟動 Master 節(jié)點:
mongod --master --dbpath /data/masterdb/
關(guān)鍵參數(shù):
--master :指定為 Master 角色;
啟動 Slave 節(jié)點:
mongod --slave --source 《masterhostname》《:《port》》 --dbpath /data/slavedb/
關(guān)鍵參數(shù):
--slave :指定為 Slave 角色;
--source :指定數(shù)據(jù)的復(fù)制來源,也就是 Master 的地址;
Replica Set 副本集模式
Replica Set 模式角色
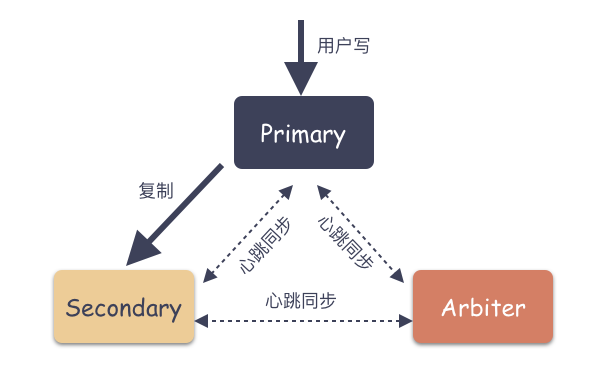
Replica Set 是 mongod 的實例集合,包含三類節(jié)點角色:
Primary( 主節(jié)點 )
只有 Primary 是可讀可寫的,Primary 接收所有的寫請求,然后把數(shù)據(jù)同步到所有 Secondary 。一個 Replica Set 只有一個 Primary 節(jié)點,當(dāng) Primary 掛掉后,其他 Secondary 或者 Arbiter 節(jié)點會重新選舉出來一個 Primary 節(jié)點,這樣就又可以提供服務(wù)了。
讀請求默認(rèn)是發(fā)到 Primary 節(jié)點處理,如果需要故意轉(zhuǎn)發(fā)到 Secondary 需要客戶端修改一下配置(注意:是客戶端配置,決策權(quán)在客戶端)。
那有人又會想了,這里也存在 Primary 和 Secondary 節(jié)點角色的分類,豈不是也存在單點問題?
這里和 Master-Slave 模式的最大區(qū)別在于,Primary 角色是通過整個集群共同選舉出來的,人人都可能成為 Primary ,人人最開始只是 Secondary ,而這個選舉過程完全自動,不需要人為參與。
Secondary( 副本節(jié)點 )
數(shù)據(jù)副本節(jié)點,當(dāng)主節(jié)點掛掉的時候,參與選主。
思考一個問題:Secondary 和 Master-Slave 模式的 Slave 角色有什么區(qū)別?
最根本的一個不同在于:Secondary 相互有心跳,Secondary 可以作為數(shù)據(jù)源,Replica 可以是一種鏈?zhǔn)降膹?fù)制模式。
Arbiter( 仲裁者 )
不存數(shù)據(jù),不會被選為主,只進行選主投票。使用 Arbiter 可以減輕在減少數(shù)據(jù)的冗余備份,又能提供高可用的能力。
如下圖:
副本集模式特點思考
MongoDB 的 Replica Set 副本集模式主要有以下幾個特點:
數(shù)據(jù)多副本,在故障的時候,可以使用完的副本恢復(fù)服務(wù)。注意:這里是故障自動恢復(fù);
讀寫分離,讀的請求分流到副本上,減輕主(Primary)的讀壓力;
節(jié)點直接互有心跳,可以感知集群的整體狀態(tài);
思考:這種有什么優(yōu)缺點呢?
可用性大大增強,因為故障時自動恢復(fù)的,主節(jié)點故障,立馬就能選出一個新的 Primary 節(jié)點。但是有一個要注意的點:每兩個節(jié)點之間互有心跳,這種模式會導(dǎo)致節(jié)點的心跳幾何倍數(shù)增大,單個 Replica Set 集群規(guī)模不能太大,一般來講最大不要超過 50 個節(jié)點。
思考:節(jié)點數(shù)有講究嗎?
有的,參與投票節(jié)點數(shù)要是奇數(shù),這個非常重要。為什么,因為偶數(shù)會導(dǎo)致腦裂,也就是投票數(shù)對等的情況,無法選出 Primary。
舉個例子,如果有 3 張票,那么一定是 2:1 ,有一個人一定會是多數(shù)票,如果是 4 張票,那么很有可能是 2:2 ,那么就有平票的現(xiàn)象。
Sharding 模式
按道理 Replica Set 模式已經(jīng)非常好的解決了可用性問題,為什么還會往后演進呢?因為在當(dāng)今大數(shù)據(jù)時代,有一個必須要考慮的問題:就是數(shù)據(jù)量。
用戶的數(shù)據(jù)量是永遠(yuǎn)都在增加的,理論是沒有上限的,但 Replica Set 卻是有上限的。怎么說?
舉個例子,假設(shè)說你的單機有 10TiB 的空間,內(nèi)存是 500 GiB,網(wǎng)卡是 40 G,這個就是單機的物理極限。當(dāng)數(shù)據(jù)量超過 10 TiB,這個 Replica Set 就無法提供服務(wù)了。你可能會說,那就加磁盤嘍,把磁盤的容量加大嘍。是可以,但是單機的容量和性能一定是有物理極限的(比如說你的磁盤槽位可能最多就 60 盤)。單機存在瓶頸怎么辦?
解決方案就是:利用分布式技術(shù)。
解決性能和容量瓶頸一般來說優(yōu)化有兩個方向:
縱向優(yōu)化
橫向優(yōu)化
縱向優(yōu)化是傳統(tǒng)企業(yè)最常見的思路,持續(xù)不斷的加大單個磁盤和機器的容量和性能。CPU 主頻不斷的提升,核數(shù)也不斷地加,磁盤容量從 128 GiB 變成當(dāng)今普遍的 12 TiB,內(nèi)存容量從以前的 M 級別變成現(xiàn)在上百 G 。帶寬從以前百兆網(wǎng)卡變成現(xiàn)在的普遍的萬兆網(wǎng)卡,但這些提升終究追不上用互聯(lián)網(wǎng)數(shù)據(jù)規(guī)模的增加量級。
橫向優(yōu)化通俗來講就是加節(jié)點,橫向擴容來解決問題。業(yè)務(wù)上要劃分系統(tǒng)數(shù)據(jù)集,并在多臺服務(wù)器上處理,做到容量和能力跟機器數(shù)量成正比。單臺計算機的整體速度或容量可能不高,但是每臺計算機只能處理全部工作量的一部分,因此與單臺高速大容量服務(wù)器相比,可能提供更高的效率。
擴展的容量僅需要根據(jù)需要添加其他服務(wù)器,這比一臺高端硬件的機器成本還低,代價就是軟件的基礎(chǔ)結(jié)構(gòu)要支持,部署維護要復(fù)雜。
那么,實際情況下,哪一種更具可行性呢?
自然是分布式技術(shù)的方案,縱向優(yōu)化的方案非常容易到達(dá)物理極限,橫向優(yōu)化則對個體要求不高,而是群體發(fā)揮效果(但是對軟件架構(gòu)提出更高的要求)。
2003年,Google 發(fā)布 Google File System 論文,這是一個可擴展的分布式文件系統(tǒng),用于大型的、分布式的、對大量數(shù)據(jù)進行訪問的應(yīng)用。它運行于廉價的普通硬件上,提供分布式容錯功能。GFS 正式拉開分布式技術(shù)應(yīng)用的大門。
MongoDB 的 Sharding 模式就是 MongoDB 橫向擴容的一個架構(gòu)實現(xiàn)。我們下面就看一下 Sharding 模式和之前 Replica Set 模式有什么特殊之處吧。
Sharding 模式角色
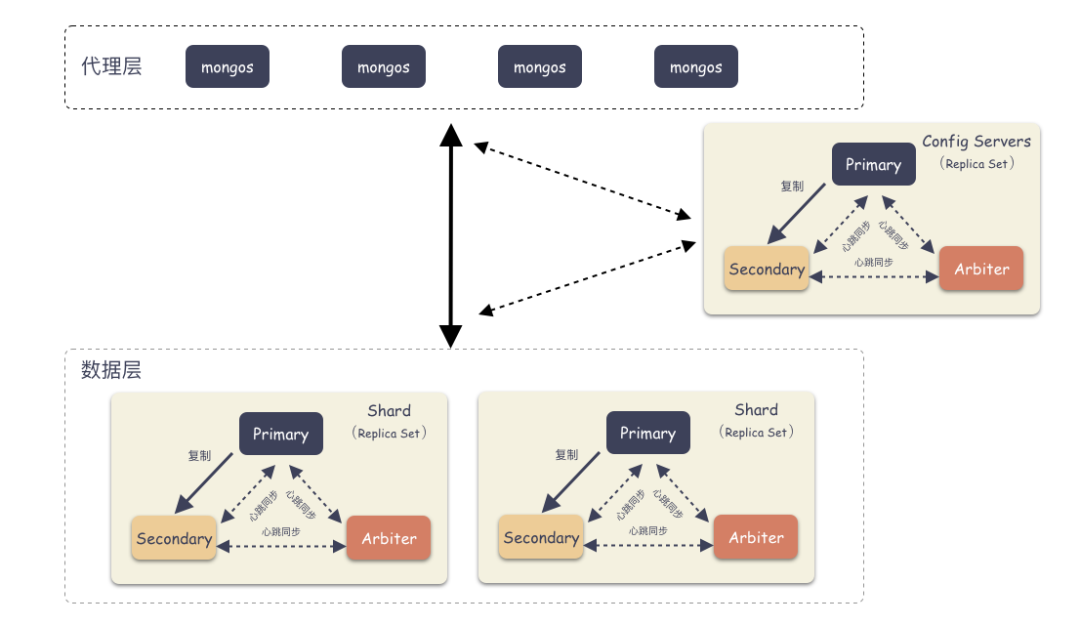
Sharding 模式下按照層次劃分可以分為 3 個大模塊:
代理層:mongos
配置中心:副本集群(mongod)
數(shù)據(jù)層:Shard 集群
簡要如下圖:
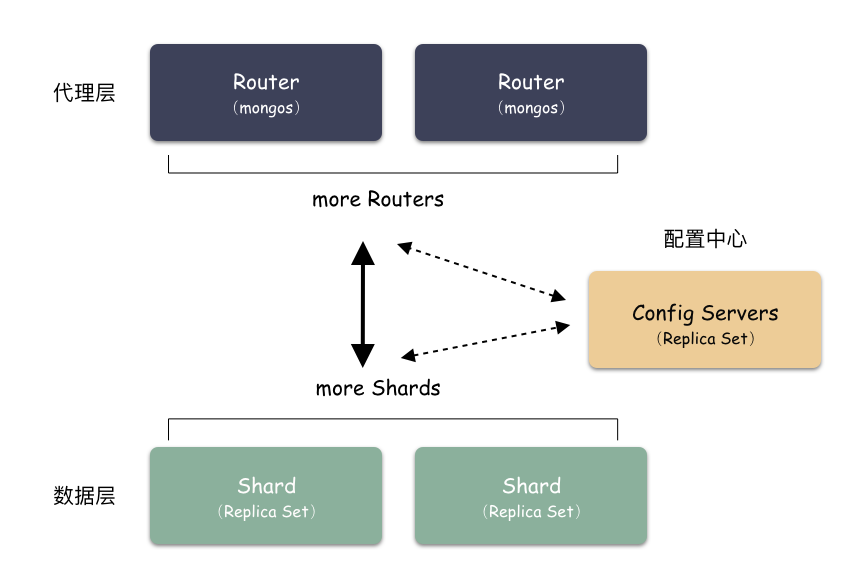
代理層:
代理層的組件也就是 mongos ,這是個無狀態(tài)的組件,純粹是路由功能。向上對接 Client ,收到 Client 寫請求的時候,按照特定算法均衡散列到某一個 Shard 集群,然后數(shù)據(jù)就寫到 Shard 集群了。收到讀請求的時候,定位找到這個要讀的對象在哪個 Shard 上,就把請求轉(zhuǎn)發(fā)到這個 Shard 上,就能讀到數(shù)據(jù)了。
數(shù)據(jù)層:
數(shù)據(jù)層是啥?就是存儲數(shù)據(jù)的地方。你會驚奇的發(fā)現(xiàn),其實數(shù)據(jù)層就是由一個個 Replica Set 集群組成。在前面我們說過,單個 Replica Set 是有極限的,怎么辦?那就搞多個 Replica Set ,這樣的一個 Replica Set 我們就叫做 Shard 。理論上,Replica Set 的集群的個數(shù)是可以無限增長的。
配置中心:
代理層是無狀態(tài)的模塊,數(shù)據(jù)層的每一個 Shard 是各自獨立的,那總要有一個集群統(tǒng)配管理的地方,這個地方就是配置中心。里面記錄的是什么呢?
比如:有多少個 Shard,每個 Shard 集群又是由哪些節(jié)點組成的。每個 Shard 里大概存儲了多少數(shù)據(jù)量(以便做均衡)。這些東西就是在配置中心的。
配置中心存儲的就是集群拓?fù)洌芾淼呐渲?a target="_blank">信息。這些信息也非常重要,所以也不能單點存儲,怎么辦?配置中心也是一個 Replica Set 集群,數(shù)據(jù)也是多副本的。
詳細(xì)架構(gòu)圖:
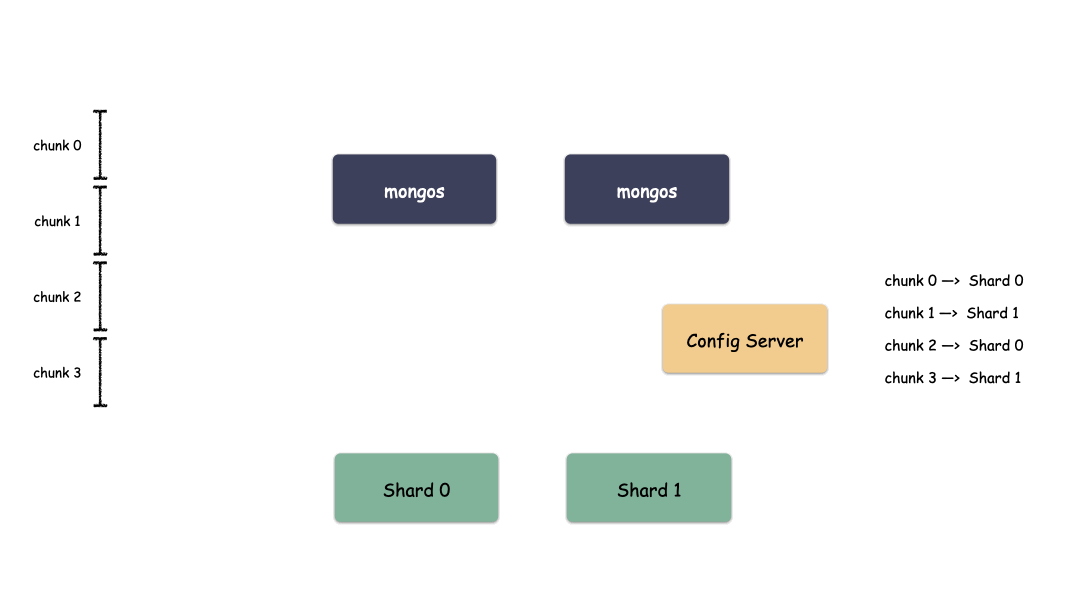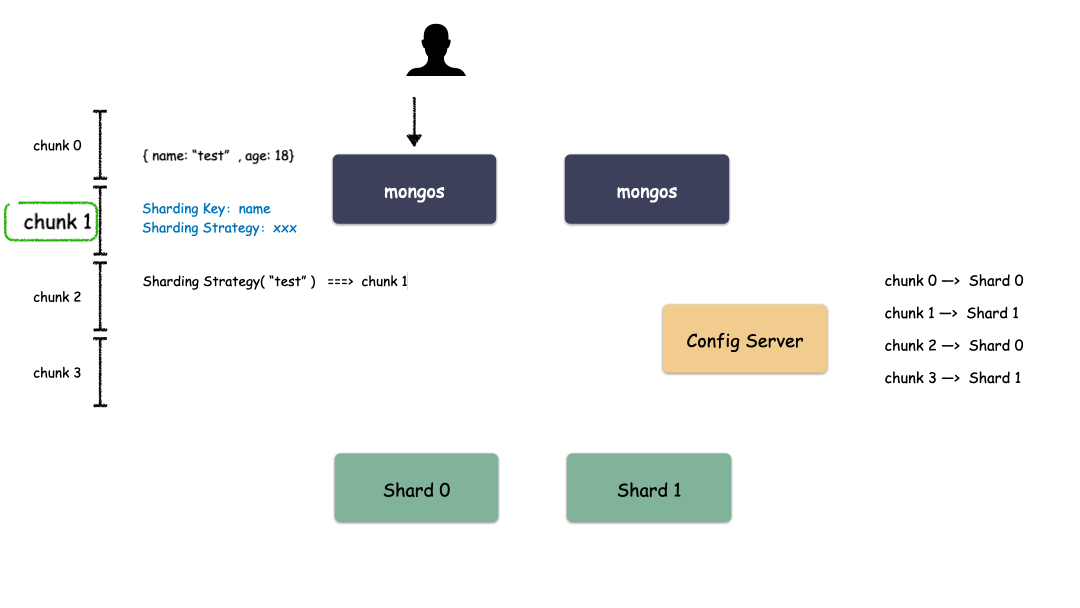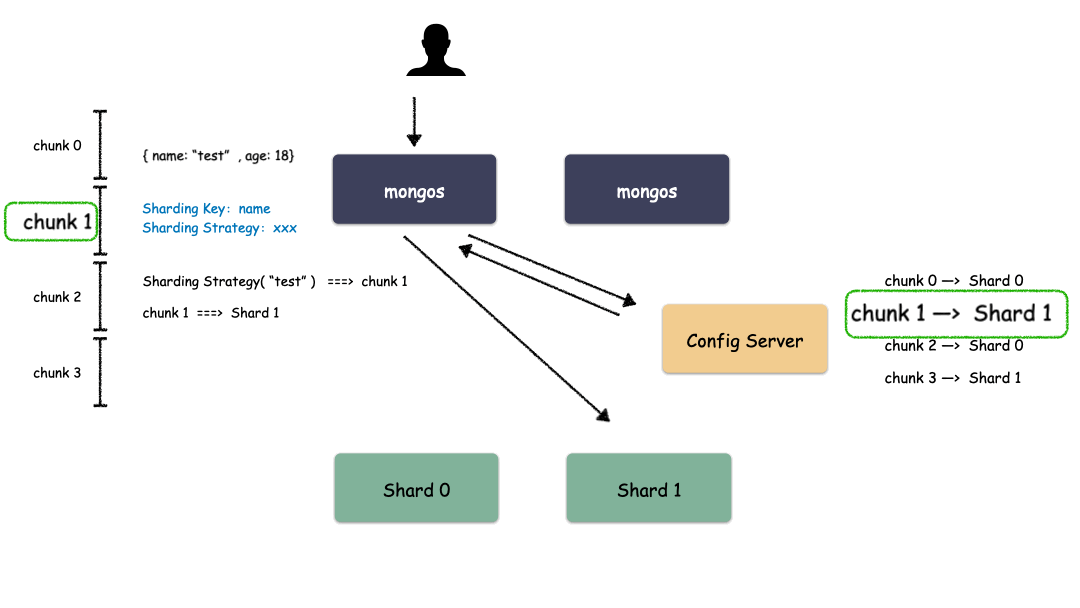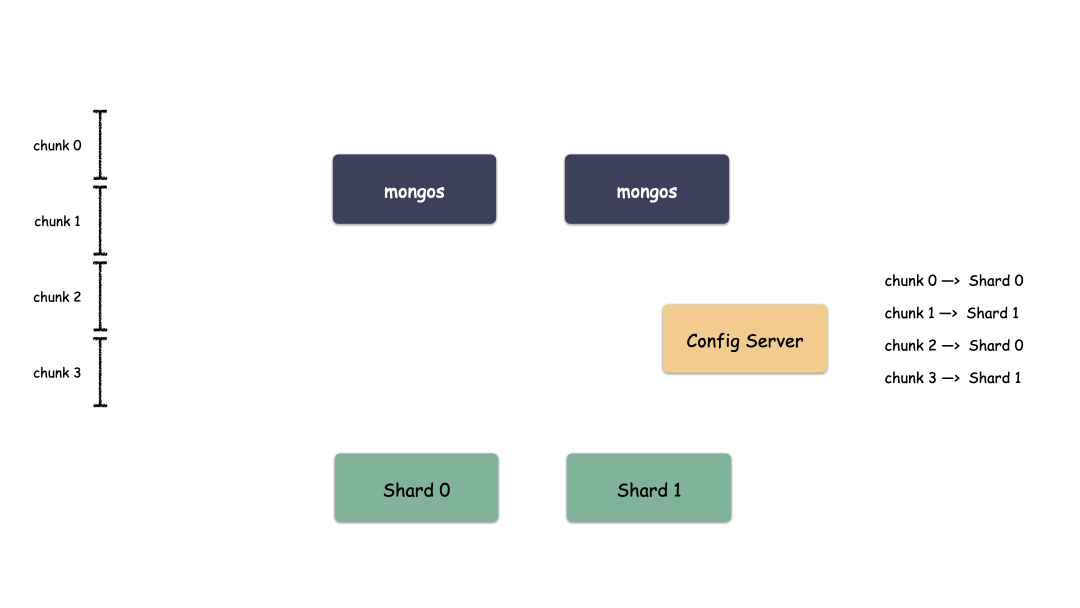
Sharding 模式怎么存儲數(shù)據(jù)?
我們說過,縱向優(yōu)化是對硬件使用者最友好的,橫向優(yōu)化則對硬件使用者提出了更高的要求,也就是說軟件架構(gòu)要適配。
單 Shard 集群是有限的,但 Shard 數(shù)量是無限的,Mongo 理論上能夠提供近乎無限的空間,能夠不斷的橫向擴容。那么現(xiàn)在唯一要解決的就是怎么去把用戶數(shù)據(jù)存到這些 Shard 里?MongDB 是怎么做的?
首先,要選一個字段(或者多個字段組合也可以)用來做 Key,這個 Key 可以是你任意指定的一個字段。我們現(xiàn)在就是要使用這個 Key 來,通過某種策略算出發(fā)往哪個 Shard 上。這個策略叫做:Sharding Strategy ,也就是分片策略。
我們把 Sharding Key 作為輸入,按照特點的 Sharding Strategy 計算出一個值,值的集合形成了一個值域,我們按照固定步長去切分這個值域,每一個片叫做 Chunk ,每個 Chunk 出生的時候就和某個 Shard 綁定起來,這個綁定關(guān)系存儲在配置中心里。
所以,我們看到 MongoDB 的用 Chunk 再做了一層抽象層,隔離了用戶數(shù)據(jù)和 Shard 的位置,用戶數(shù)據(jù)先按照分片策略算出落在哪個 Chunk 上,由于 Chunk 某一時刻只屬于某一個 Shard,所以自然就知道用戶數(shù)據(jù)存到哪個 Shard 了。
Sharding 模式下數(shù)據(jù)寫入過程:
Sharding 模式下數(shù)據(jù)讀取過程:
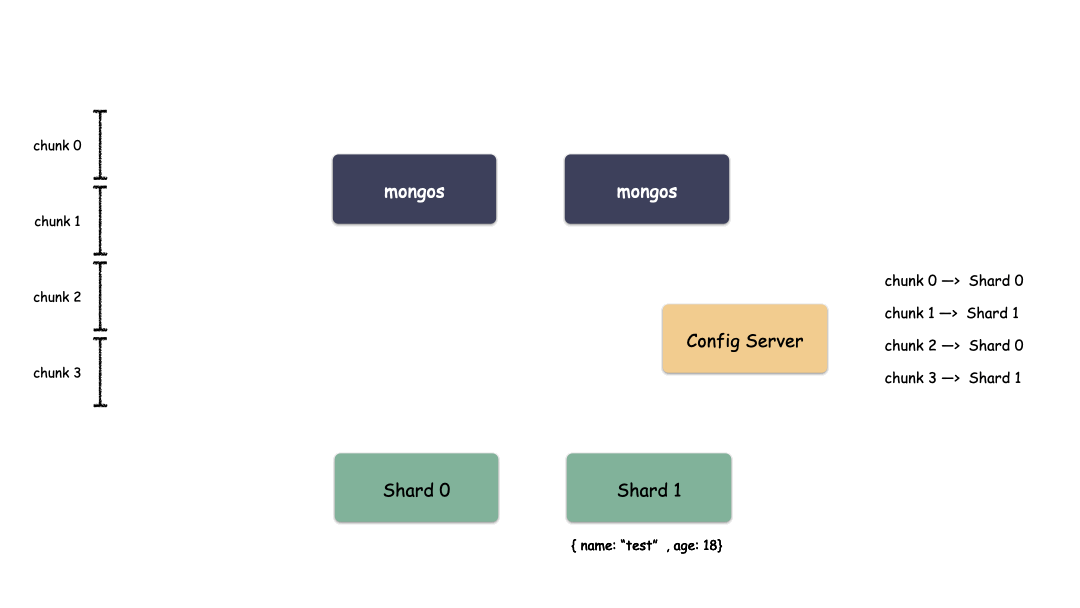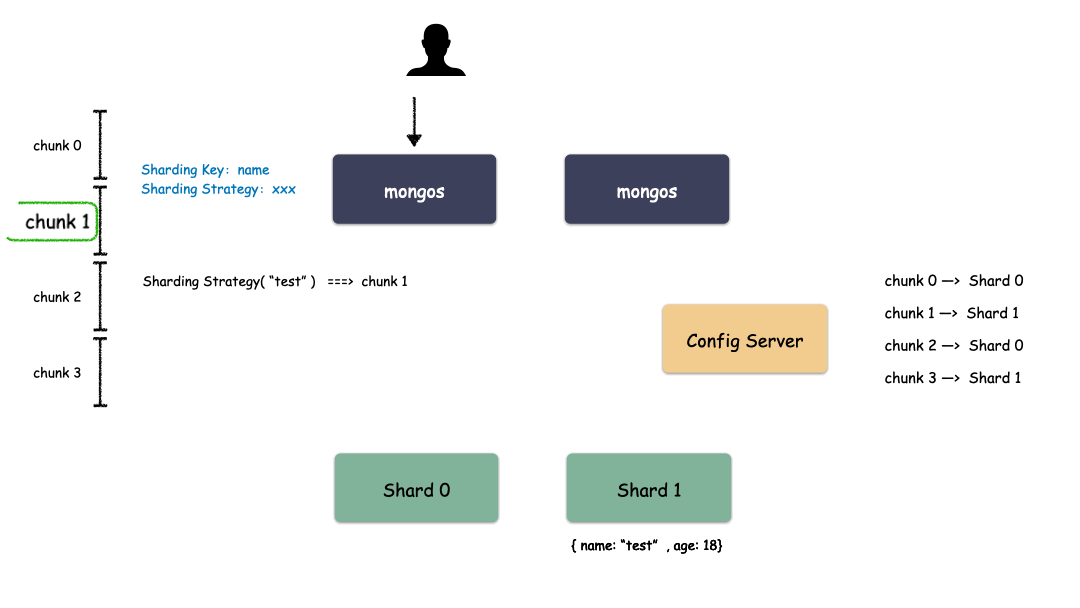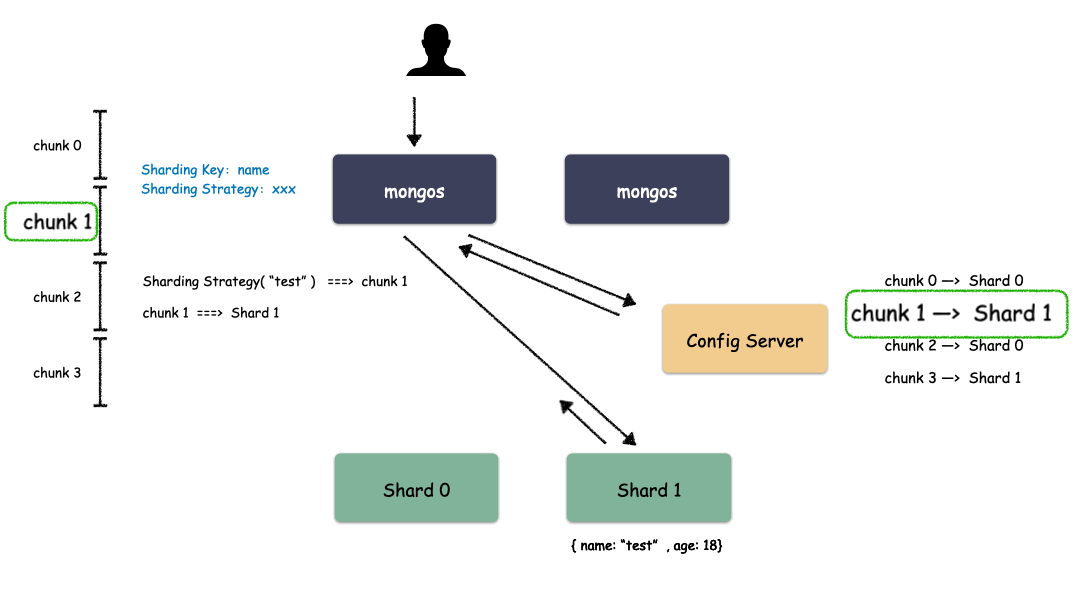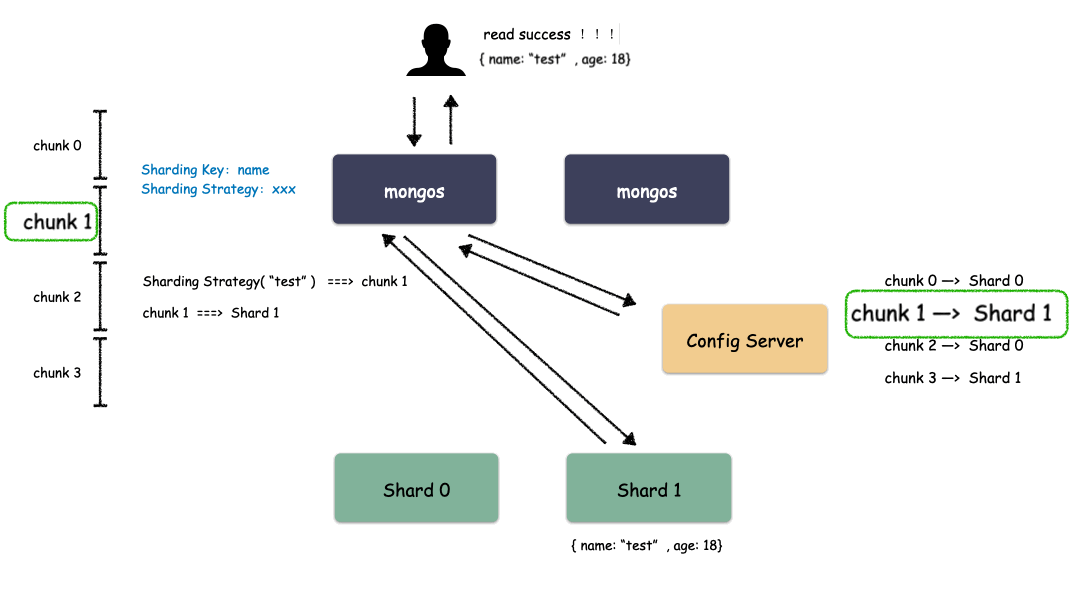
通過上圖我們也看出來了,mongos 作為路由模塊其實就是尋路的組件,寫的時候先算出用戶 key 屬于哪個 Chunk,然后找出這個 Chunk 屬于哪個 Shard,最后把請求發(fā)給這個 Shard ,就能把數(shù)據(jù)寫下去。讀的時候也是類似,先算出用戶 key 屬于哪個 Chunk,然后找出這個 Chunk 屬于哪個 Shard,最后把請求發(fā)給這個 Shard ,就能把數(shù)據(jù)讀上來。
實際情況下,mongos 不需要每次都和 Config Server 交互,大部分情況下只需要把 Chunk 的映射表 cache 一份在 mongos 的內(nèi)存,就能減少一次網(wǎng)絡(luò)交互,提高性能。
為什么要多一層 Chunk 這個抽象?
為了靈活,因為一旦是用戶數(shù)據(jù)直接映射到 Shard 上,那就相當(dāng)于是用戶數(shù)據(jù)和底下的物理位置綁定起來了,這個萬一 Shard 空間已經(jīng)滿了,怎么辦?
存儲不了呀,又不能存儲到其他地方去。有同學(xué)就會想了,那我可以把這個變化的映射記錄下來呀,記錄下來理論上行得通,但是每一個用戶數(shù)據(jù)記錄一條到 Shard 的映射,這個量級是非常大的,實際中沒有可行性。
而現(xiàn)在多了一層 Chunk 空間,就靈活了。用戶數(shù)據(jù)不再和物理位置綁定,而是只映射到 Chunk 上就可以了。如果某個 Shard 數(shù)據(jù)不均衡,那么可以把 Chunk 空間分裂開,遷走一半的數(shù)據(jù)到其他 Shard ,修改下 Chunk 到 Shard 的映射,Chunk 到 Shard 的映射條目很少,完全 Hold 住,并且這種均衡過程用戶完全不感知。
講回 Sharding Strategy 是什么?本質(zhì)上 Sharding Strategy 是形成值域的策略而已,MongoDB 支持兩種 Sharding Strategy:
Hashed Sharding 的方式
Range Sharding 的方式
Hashed Sharding
把 Key 作為輸入,輸入到一個 Hash 函數(shù)中,計算出一個整數(shù)值,值的集合形成了一個值域,我們按照固定步長去切分這個值域,每一個片叫做 Chunk ,這里的 Chunk 則就是整數(shù)的一段范圍而已。
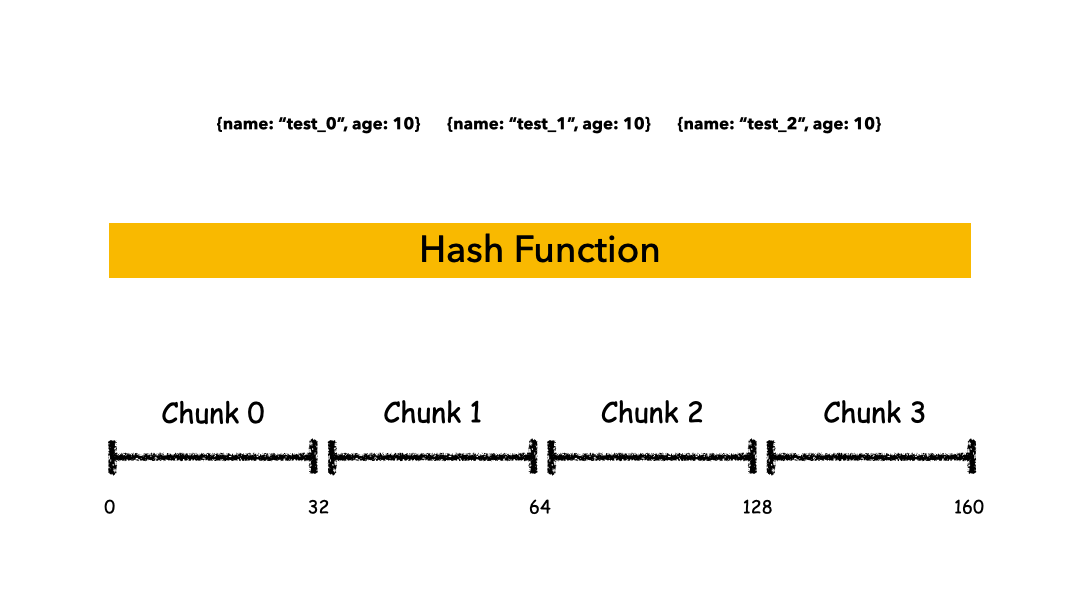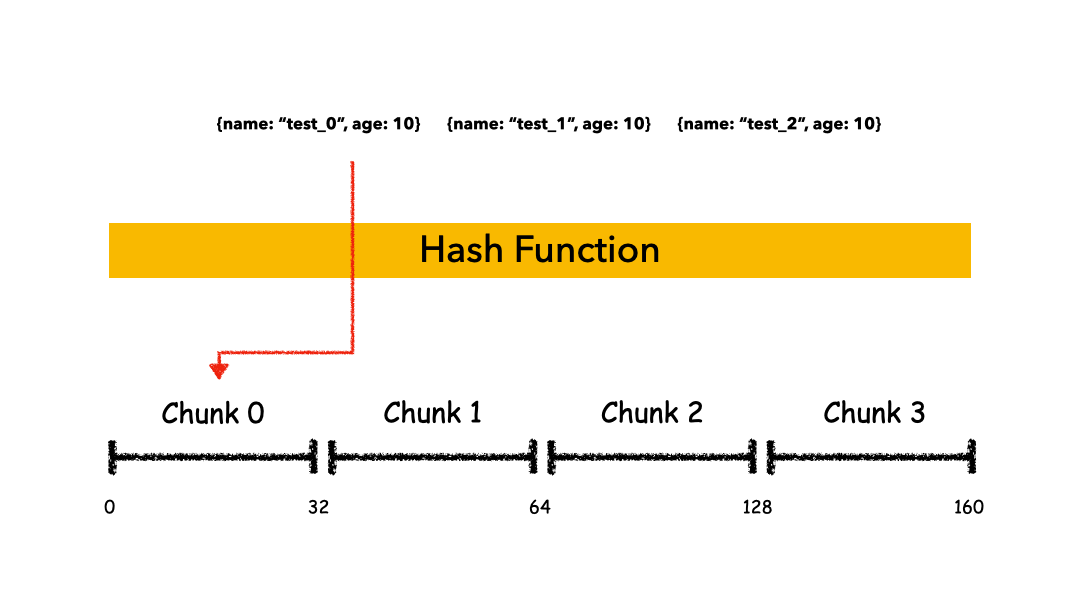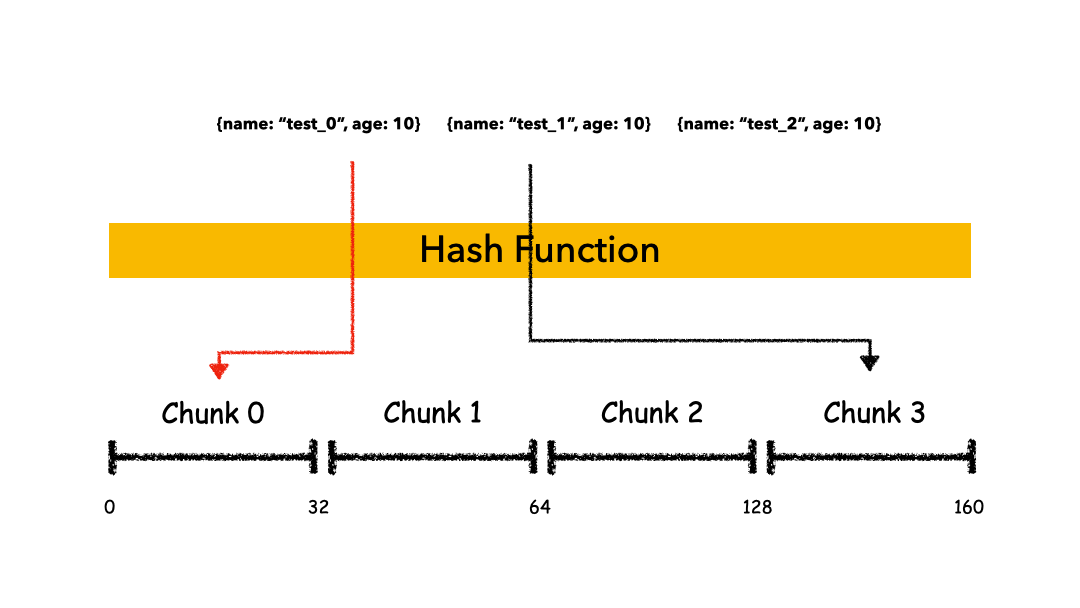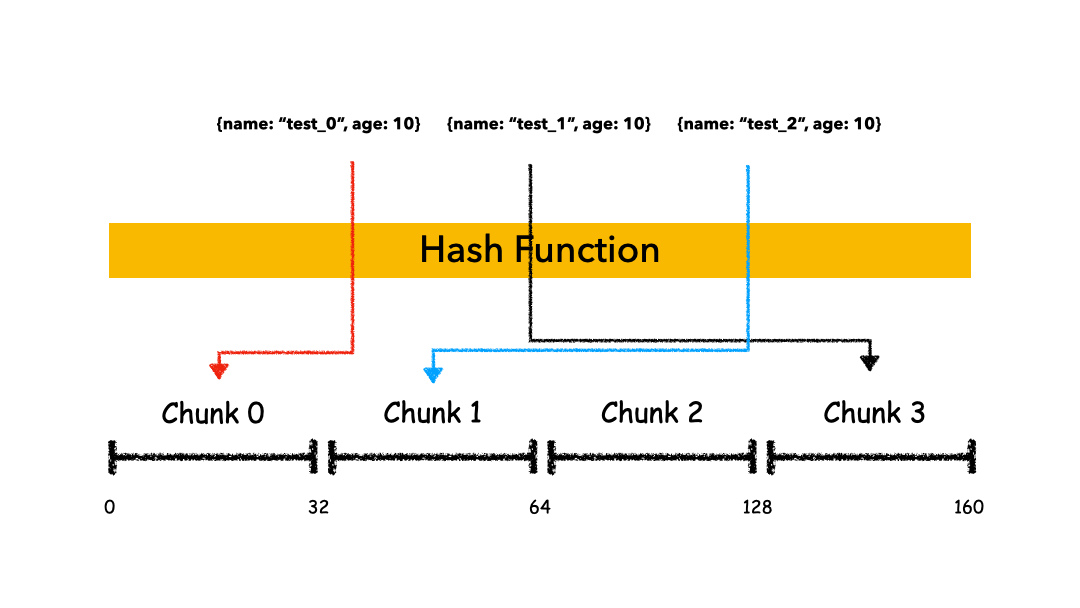
這種計算值域的方式有什么優(yōu)缺點呢?
好處是:
計算速度快
均衡性好,純隨機
壞處是:
正因為純隨機,排序列舉的性能極差,比如你如果按照 name 這個字段去列舉數(shù)據(jù),你會發(fā)現(xiàn)幾乎所有的 Shard 都要參與進來;
Range Sharding
Range 的方式本質(zhì)上是直接用 Key 本身來做值,形成的 Key Space 。
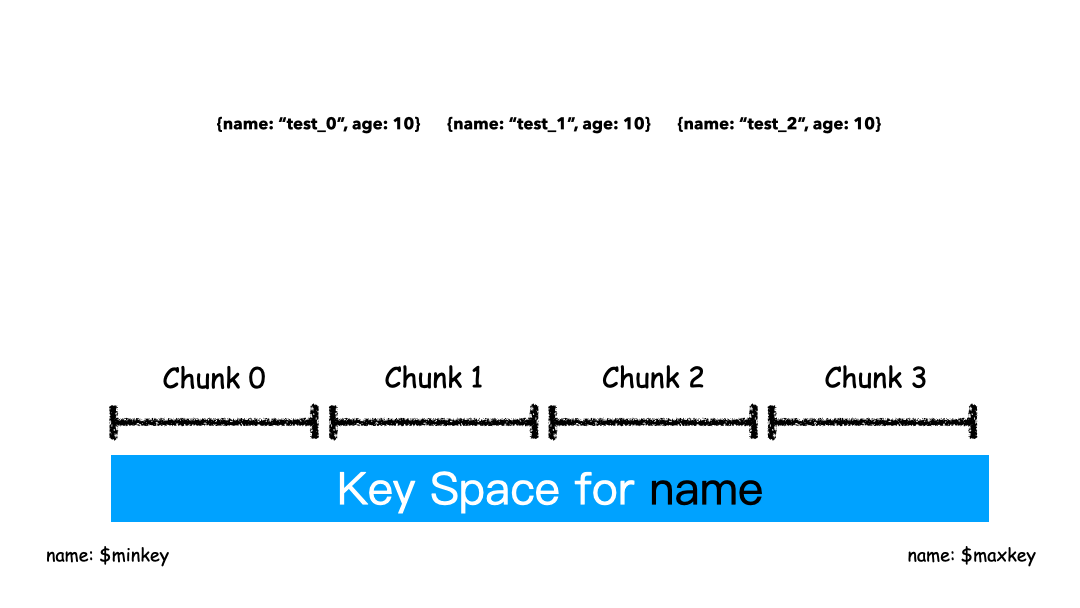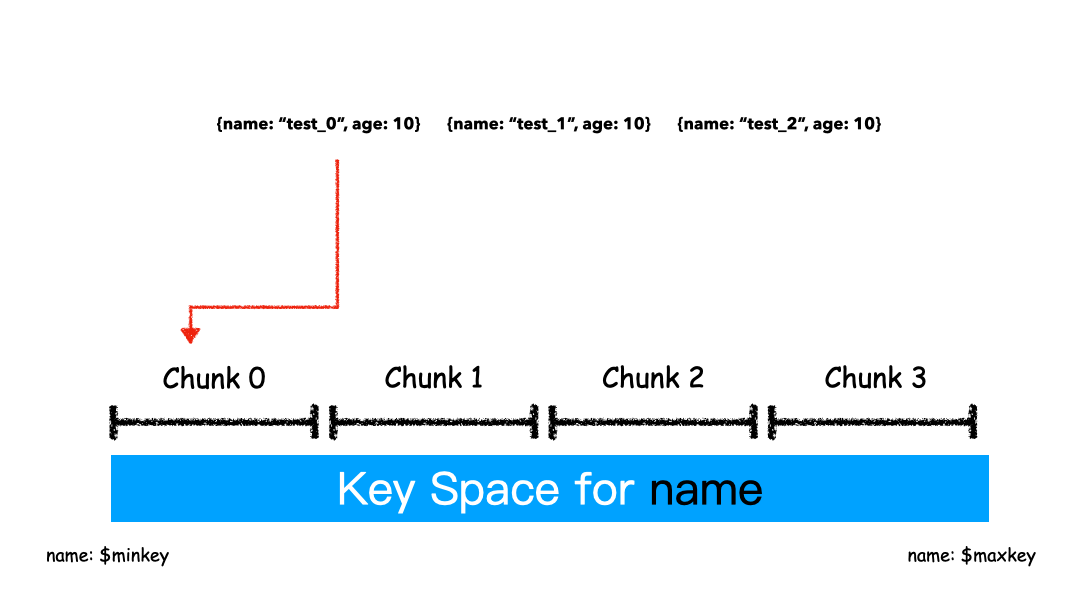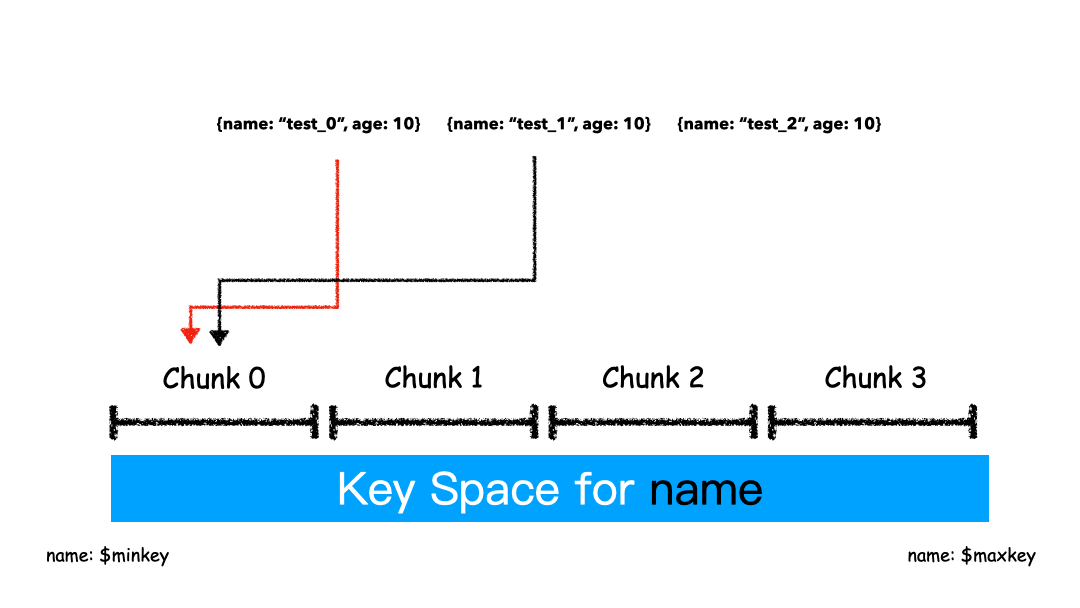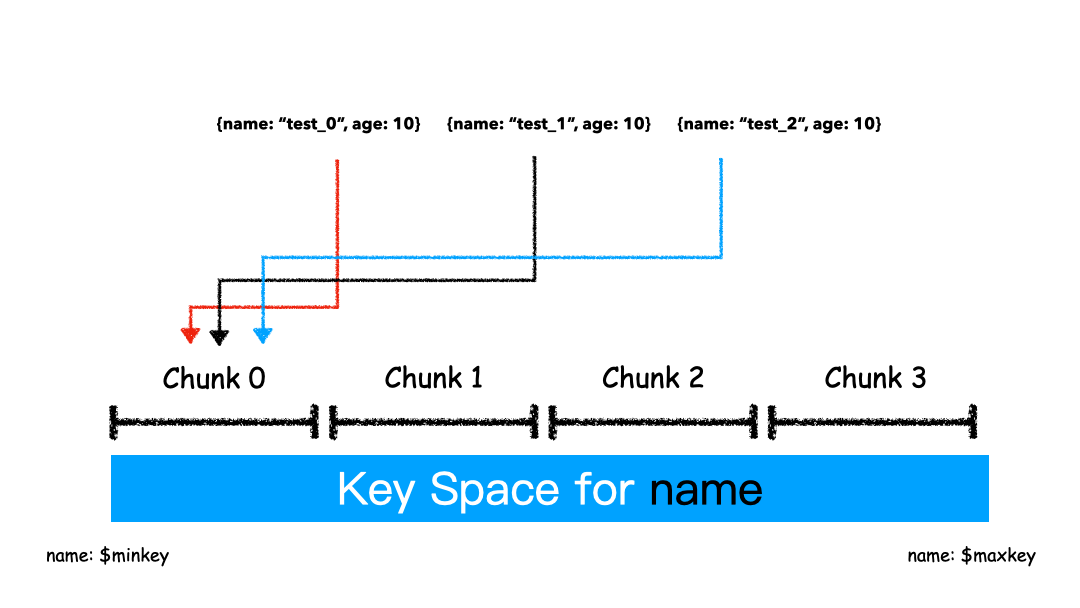
如上圖例子,Sharding Key 選為 name 這個字段,對于 “test_0”,“test_1”,“test_2” 這樣的 key 排序就是挨著的,所以就全都分配在一個 Chunk 里。
這 3 條 Docuement 大概率是在一個 Chunk 上,因為我們就是按照 Name 來排序的。這種方式有什么優(yōu)缺點?
好處是:
對排序列舉場景非常友好,因為數(shù)據(jù)本來就是按照順序依次放在 Shard 上的,排序列舉的時候,順序讀即可,非常快速;
壞處是:
容易導(dǎo)致熱點,舉個例子,如果 Sharding Key 都有相同前綴,那么大概率會分配到同一個 Shard 上,就盯著這個 Shard 寫,其他 Shard 空閑的很,卻幫不上忙;
可用性的進一步提升
為什么說 Sharding 模式不僅是容量問題得到解決,可用性也進一步提升?
因為 Shard(Replica Set)集群個數(shù)多了,即使一個或多個 Shard 不可用,Mongo 集群對外仍可以 提供讀取和寫入服務(wù)。因為每一個 Shard 都有一個 Primary 節(jié)點,都可以提供寫服務(wù),可用性進一步提升。
推薦使用姿勢
上面已經(jīng)介紹了歷史演進的 3 種高可用模式,Master-Slave 模式已經(jīng)在不推薦了,Relicate Set 和 Sharding 模式都可以保證數(shù)據(jù)的高可靠和高可用,但是在我們實踐過程中,發(fā)現(xiàn)客戶端存在非常大的配置權(quán)限,也就是說如果用戶在使用 MongoDB 的時候使用姿勢不對,可能會導(dǎo)致達(dá)不到你的預(yù)期。
使用姿勢一:怎么保證高可用?
如果是 Replicate Set 模式,那么客戶端要主動感知主從切換。以前用過 Go 語言某個版本的 MongoDB client SDK,發(fā)現(xiàn)在主從切換的時候,并沒有主動感知,導(dǎo)致請求還一直發(fā)到已經(jīng)故障的節(jié)點,從而導(dǎo)致服務(wù)不可用。
所以針對這種形式要怎么做?有兩個方案:
用 Sharding 模式,因為 Sharding 模式下,用戶打交道的是 mongos ,這個是一個代理,幫你屏蔽了底層 Replica Set 的細(xì)節(jié),主從切換由它幫你做好;
客戶端自己感知,定期刷新(這種就相對麻煩);
使用姿勢二:怎么保證數(shù)據(jù)的高可靠?
客戶端配置寫多數(shù)成功才算成功。沒錯,這個權(quán)限交由由客戶端配置。如果沒有配置寫多數(shù)成功,那么很可能寫一份數(shù)據(jù)成功就成功了,這個時候如果發(fā)生故障,或者切主,那么數(shù)據(jù)可能丟失或者被主節(jié)點 rollback ,也等同用戶數(shù)據(jù)丟失。
mongodb 有完善的 rollback 及寫入策略(WriteConcern)機制,但是也要使用得當(dāng)。怎么保證高可靠?一定要寫多數(shù)成功才算成功。
使用姿勢三:怎么保證數(shù)據(jù)的強一致性?
客戶端要配置兩個東西:
寫多數(shù)成功,才算成功;
讀使用 strong 模式,也就是只從主節(jié)點讀;
只有這兩個配置一起上,才能保證用戶數(shù)據(jù)的絕對安全,并且對外提供數(shù)據(jù)的強一致性。
總結(jié)
本文介紹了 3 種 MongoDB 的高可用架構(gòu),Master-Slave 模式,Replica Set 模式,Sharding 模式,這也是常見的架構(gòu)演進的過程;
MongdbDB Master-Slave 已經(jīng)不推薦,甚至新版已經(jīng)不支持這種冗余模式;
Replica Set 通過數(shù)據(jù)多副本,組件冗余提高了可靠性,并且通過分布式自動選主算法,減少了停服時間窗,提高了可用性;
Sharding 模式通過橫向擴容的方式,為用戶提供了近乎無限的空間;
MongoDB 客戶端掌握了很大的配置權(quán)限,通過指定寫多數(shù)策略和 strong 模式(只從主節(jié)點讀數(shù)據(jù))能保證數(shù)據(jù)的高可靠和強一致性;
后記
今天從比較大的層面來分析了下 MongoDB 的高可用架構(gòu),這 3 種架構(gòu)也是分布式系統(tǒng)里常見的架構(gòu)模式,非常實用,你學(xué) fei 了嗎?MongoDB 作為當(dāng)前火熱的 NoSQL 數(shù)據(jù)庫,是有很多值得學(xué)習(xí)的地方的,有機會從原理和實踐的角度深入分析下。
原文標(biāo)題:全面剖析 MongoDB 高可用架構(gòu)
文章出處:【微信公眾號:數(shù)據(jù)分析與開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
責(zé)任編輯:haq
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7145瀏覽量
89591 -
mongpdb
+關(guān)注
關(guān)注
0文章
2瀏覽量
2134
原文標(biāo)題:全面剖析 MongoDB 高可用架構(gòu)
文章出處:【微信號:DBDevs,微信公眾號:數(shù)據(jù)分析與開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
確保網(wǎng)站無縫運行:Keepalived高可用與Nginx集成實戰(zhàn)
?ISP算法及架構(gòu)分析介紹

使用bq769x0對高可用性系統(tǒng)進行故障監(jiān)控

使用LM74502的3種方式使用高邊開關(guān)驅(qū)動器
RISC--V架構(gòu)的目標(biāo)和特點
B站高可用用架構(gòu)實踐
華為云 FunctionGraph 構(gòu)建高可用系統(tǒng)的實踐
MongoDB數(shù)據(jù)恢復(fù)—MongoDB數(shù)據(jù)庫文件損壞的數(shù)據(jù)恢復(fù)案例
超融合架構(gòu)解決方案
華為云網(wǎng)站高可用解決方案引爆華為云開年采購季:助力多場景下業(yè)務(wù)高可用、數(shù)據(jù)高可靠
fpga芯片架構(gòu)介紹
MongoDB主從切換功能測試





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論