 神經網絡中最經典的RNN模型介紹
神經網絡中最經典的RNN模型介紹
神經網絡是深度學習的載體,而神經網絡模型中,最經典非RNN模型所屬,盡管它不完美,但它具有學習歷史信息的能力。后面不管是encode-decode 框架,還是注意力模型,以及自注意力模型,以及更加強大的Bert模型家族,都是站在RNN的肩上,不斷演化、變強的。
這篇文章,闡述了RNN的方方面面,包括模型結構,優缺點,RNN模型的幾種應用,RNN常使用的激活函數,RNN的缺陷,以及GRU,LSTM是如何試圖解決這些問題,RNN變體等。
這篇文章最大特點是圖解版本,其次語言簡練,總結全面。
概述
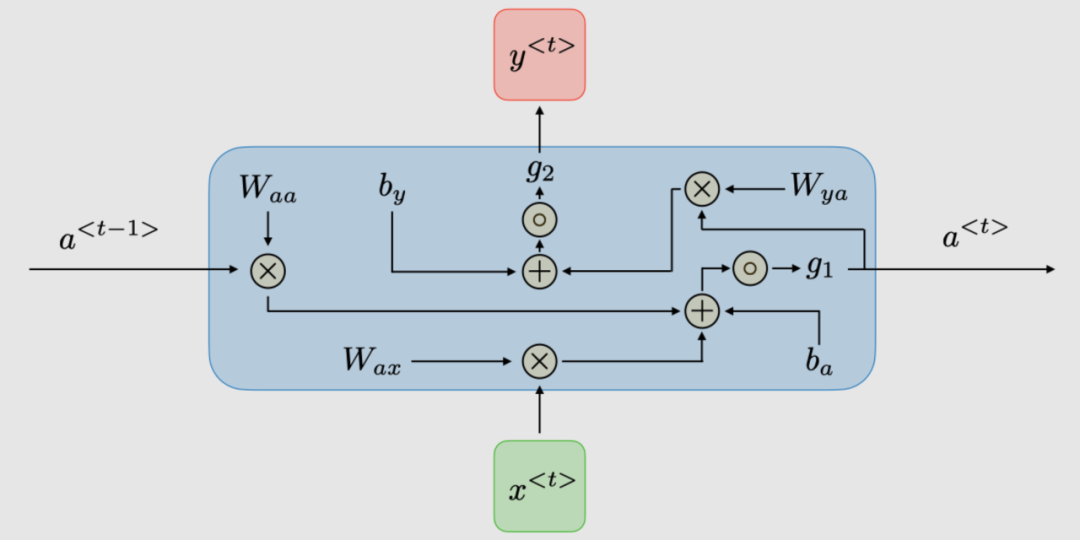
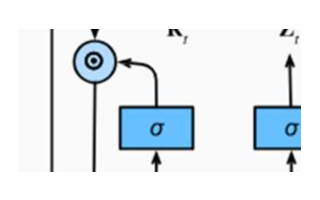
傳統RNN的體系結構。Recurrent neural networks,也稱為RNNs,是一類允許先前的輸出用作輸入,同時具有隱藏狀態的神經網絡。它們通常如下所示:
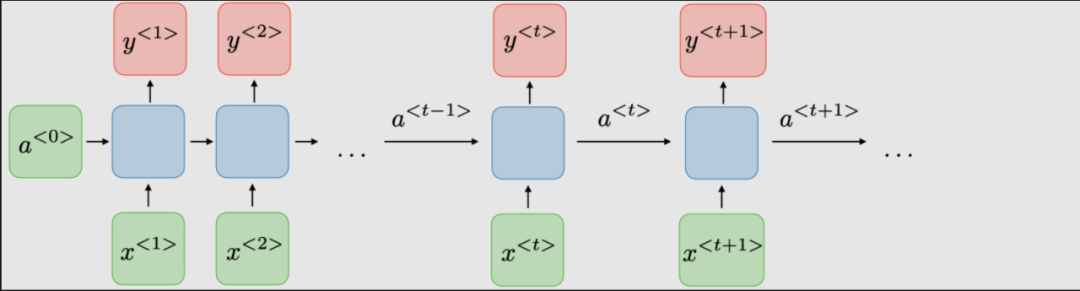
對于每一時步, 激活函數 ,輸出被表達為:
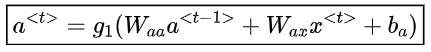
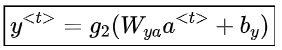
這里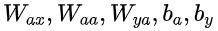 是時間維度網絡的共享權重系數 ?是激活函數
是時間維度網絡的共享權重系數 ?是激活函數
下表總結了典型RNN架構的優缺點:
| 處理任意長度的輸入 | 計算速度慢 |
| 模型形狀不隨輸入長度增加 | 難以獲取很久以前的信息 |
| 計算考慮了歷史信息 | 無法考慮當前狀態的任何未來輸入 |
| 權重隨時間共享 | |
| 優點 | 缺點 |
|---|
RNNs應用
RNN模型主要應用于自然語言處理和語音識別領域。下表總結了不同的應用:
| 1對1 |
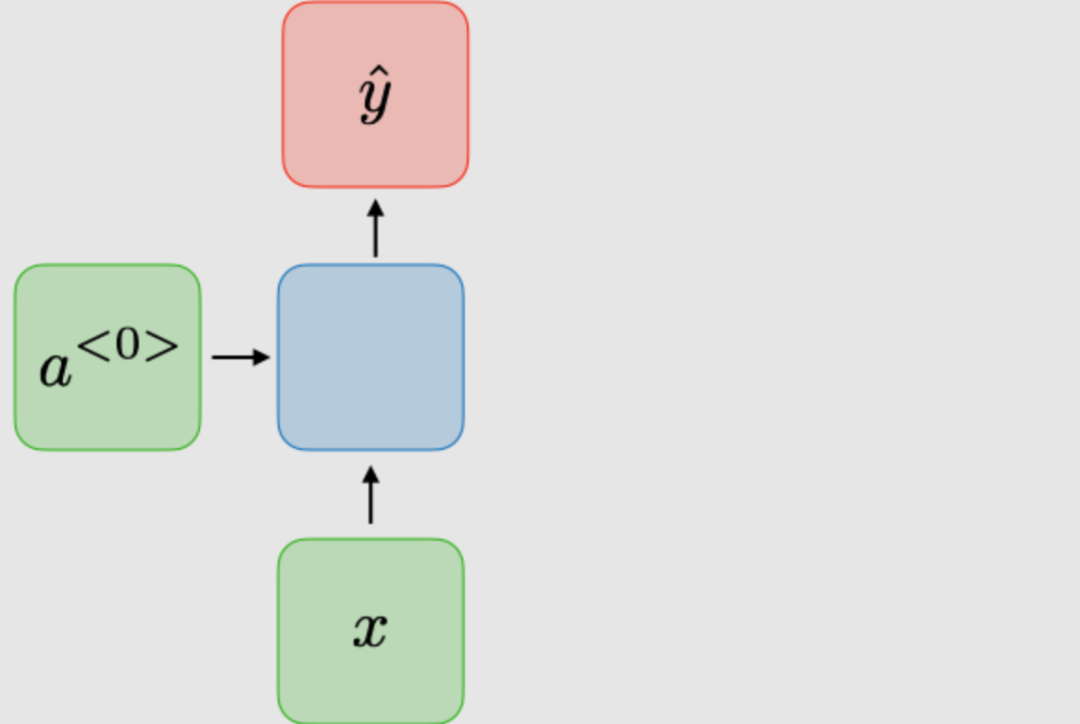
| 傳統神經網絡 | |
| 1對多 |
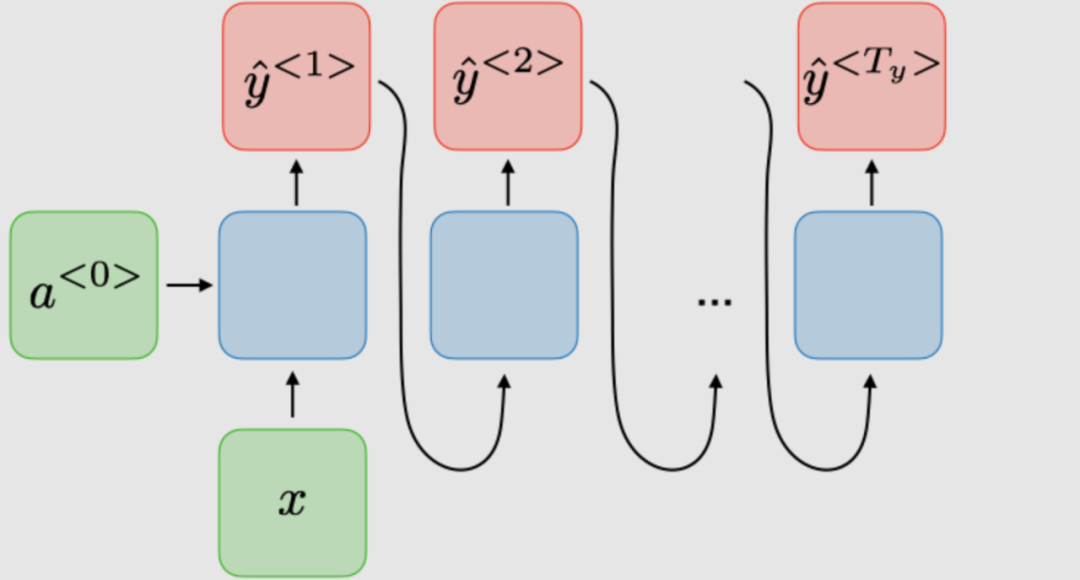
| 音樂生成 | |
| 多對1 |
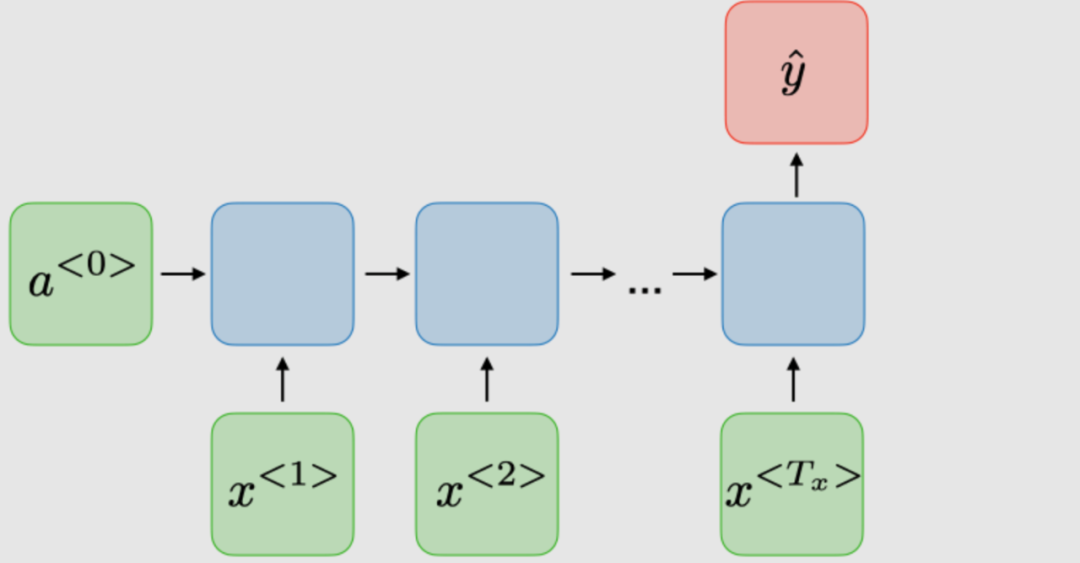
| 情感分類 | |
| 多對多 |
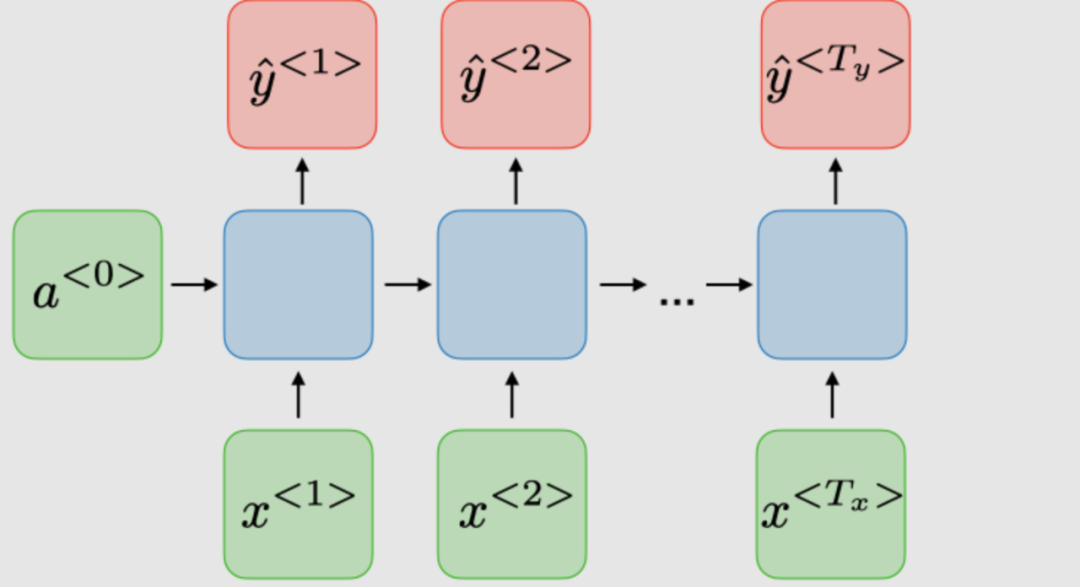
| 命名實體識別 | |
| 多對多 |
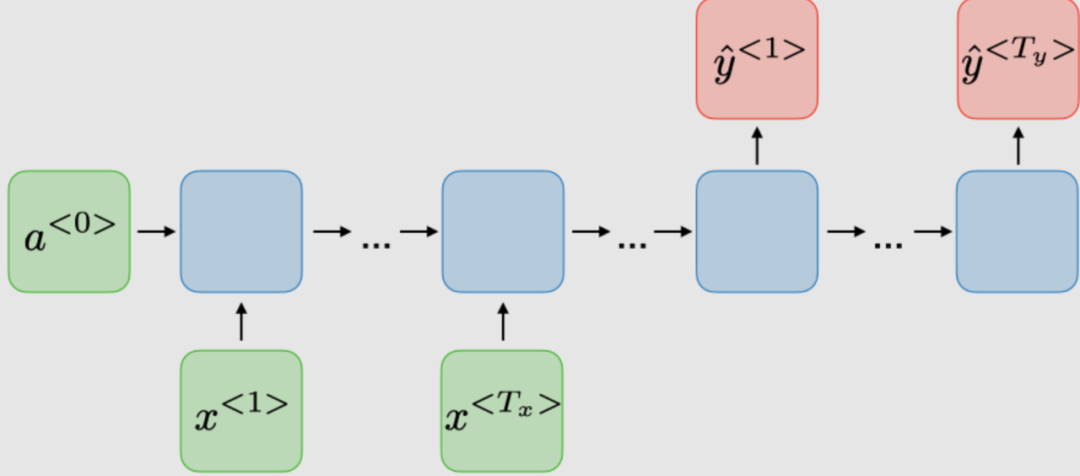
| 機器翻譯 | ||
| RNN 類型 | 圖解 | 例子 |
|---|
損失函數 對于RNN網絡,所有時間步的損失函數 是根據每個時間步的損失定義的,如下所示:
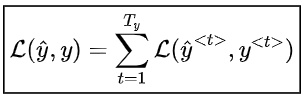
時間反向傳播
在每個時間點進行反向傳播。在時間步,損失相對于權重矩陣的偏導數表示如下:
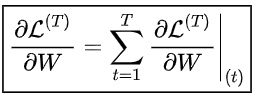
處理長短依賴
常用激活函數
RNN模塊中最常用的激活函數描述如下:
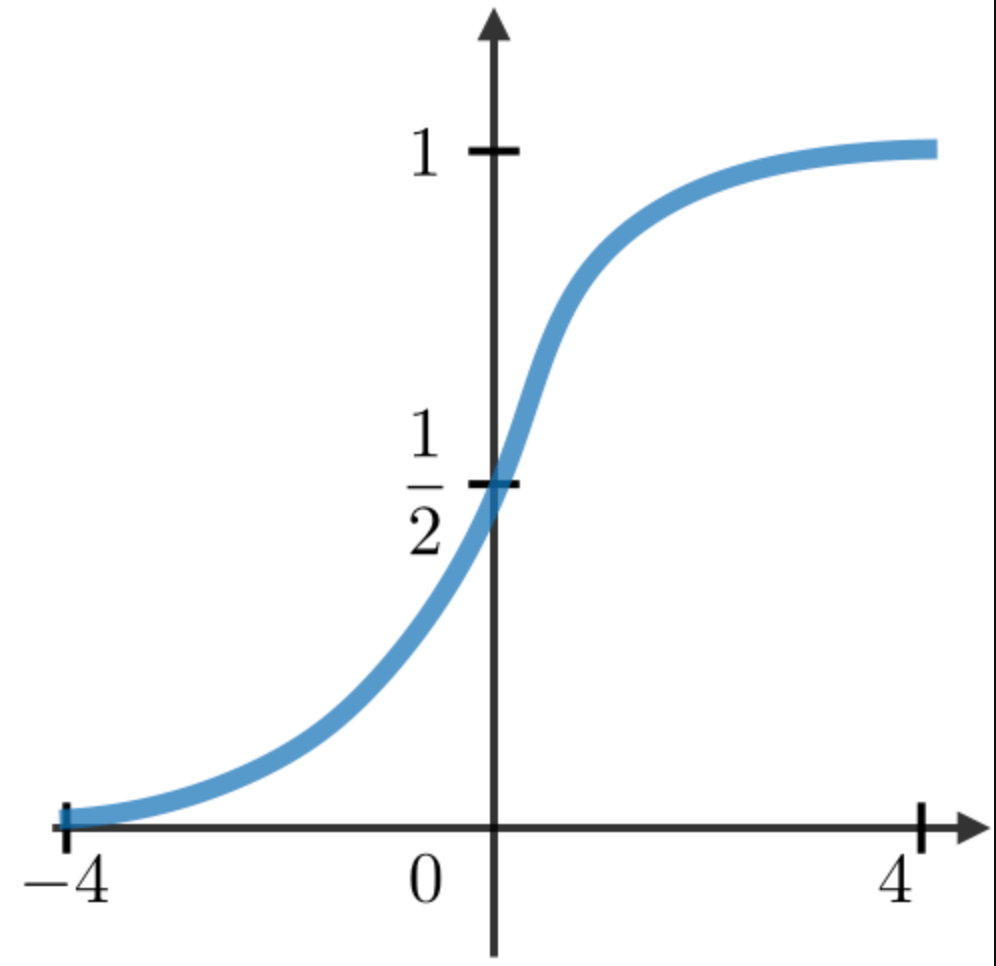
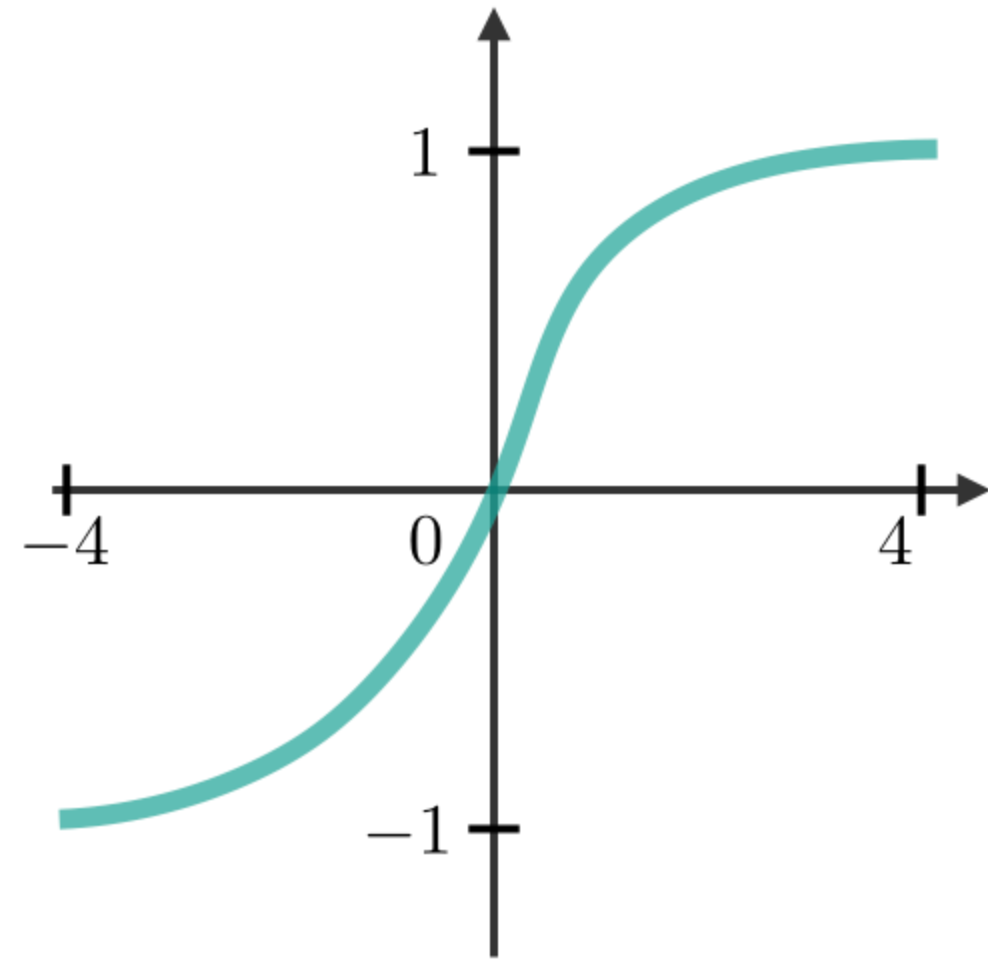
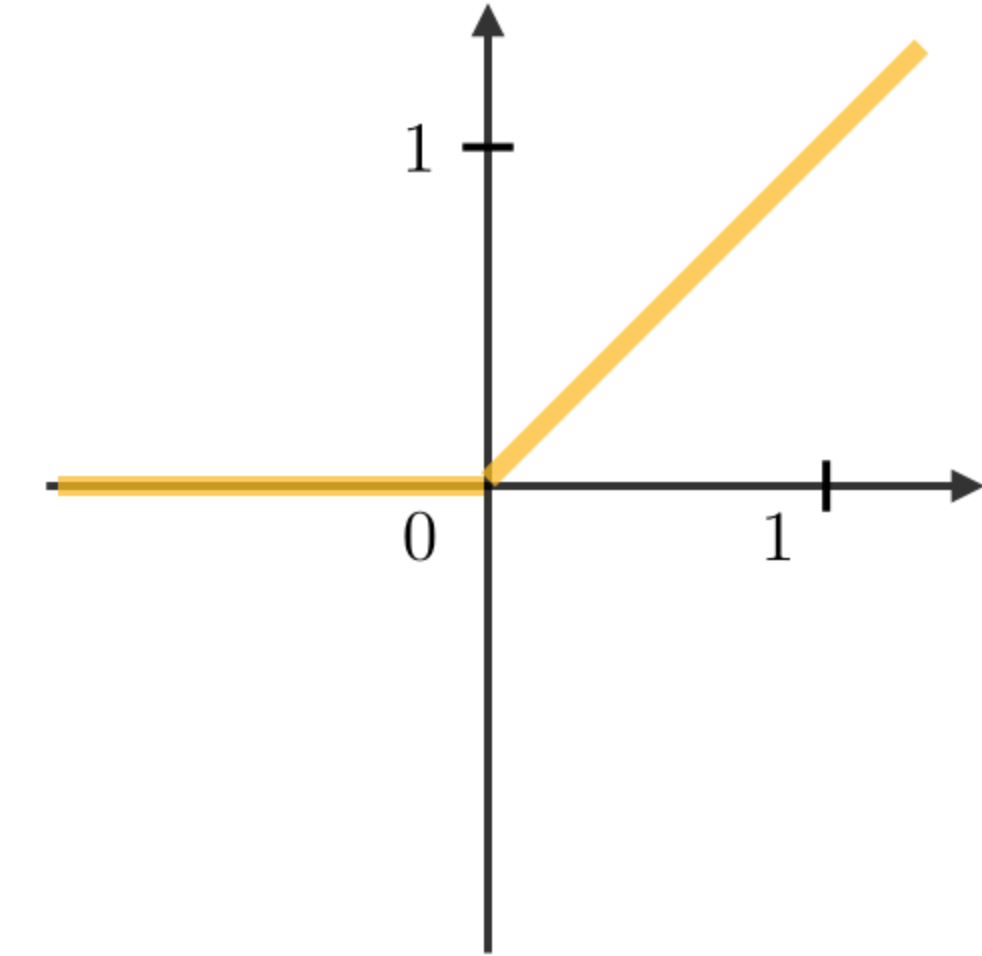
| Sigmoid | Tanh | RELU |
|---|
梯度消失/爆炸
在RNN中經常遇到梯度消失和爆炸現象。之所以會發生這種情況,是因為很難捕捉到長期的依賴關系,因為乘法梯度可以隨著層的數量呈指數遞減/遞增。
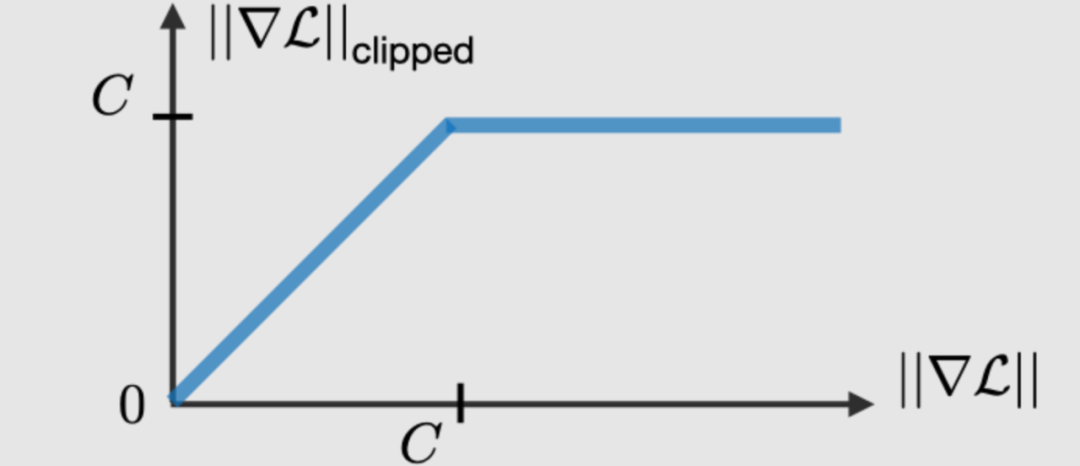
梯度修剪 梯度修剪是一種技術,用于執行反向傳播時,有時遇到的梯度爆炸問題。通過限制梯度的最大值,這種現象在實踐中得以控制。
門的類型
為了解決消失梯度問題,在某些類型的RNN中使用特定的門,并且通常有明確的目的。它們通常標注為,等于:
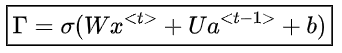
其中,是特定于門的系數,是sigmoid函數。主要內容總結如下表:
| 更新門 | 過去對現在有多重要? | GRU, LSTM |
| 關聯門 | 丟棄過去信息? | GRU, LSTM |
| 遺忘門 | 是不是擦除一個單元? | LSTM |
| 輸出門 | 暴露一個門的多少? | LSTM |
| 門的種類 | 作用 | 應用 |
|---|
GRU/LSTM Gated Recurrent Unit(GRU)和長-短期記憶單元(LSTM)處理傳統RNNs遇到的消失梯度問題,LSTM是GRU的推廣。下表總結了每種結構的特征方程:
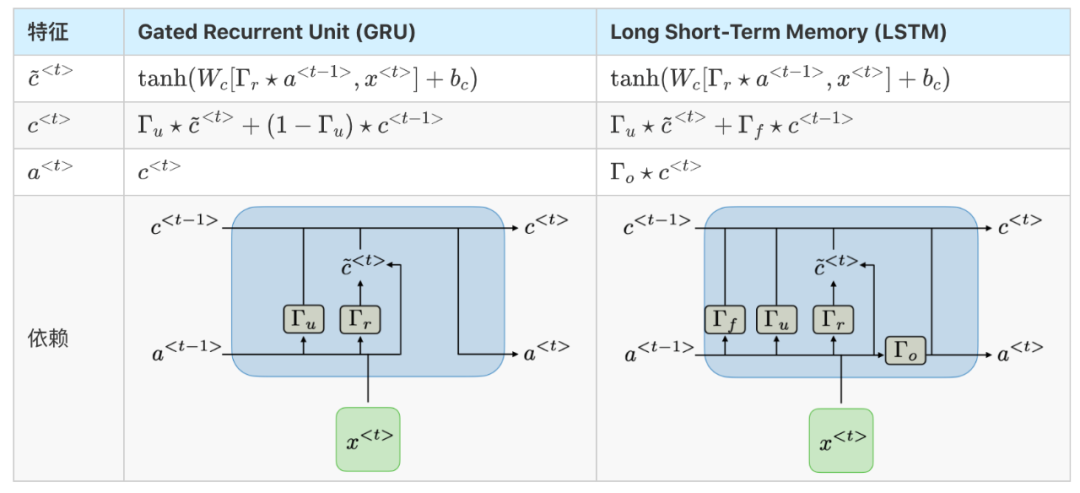
注:符號表示兩個向量之間按元素相乘。
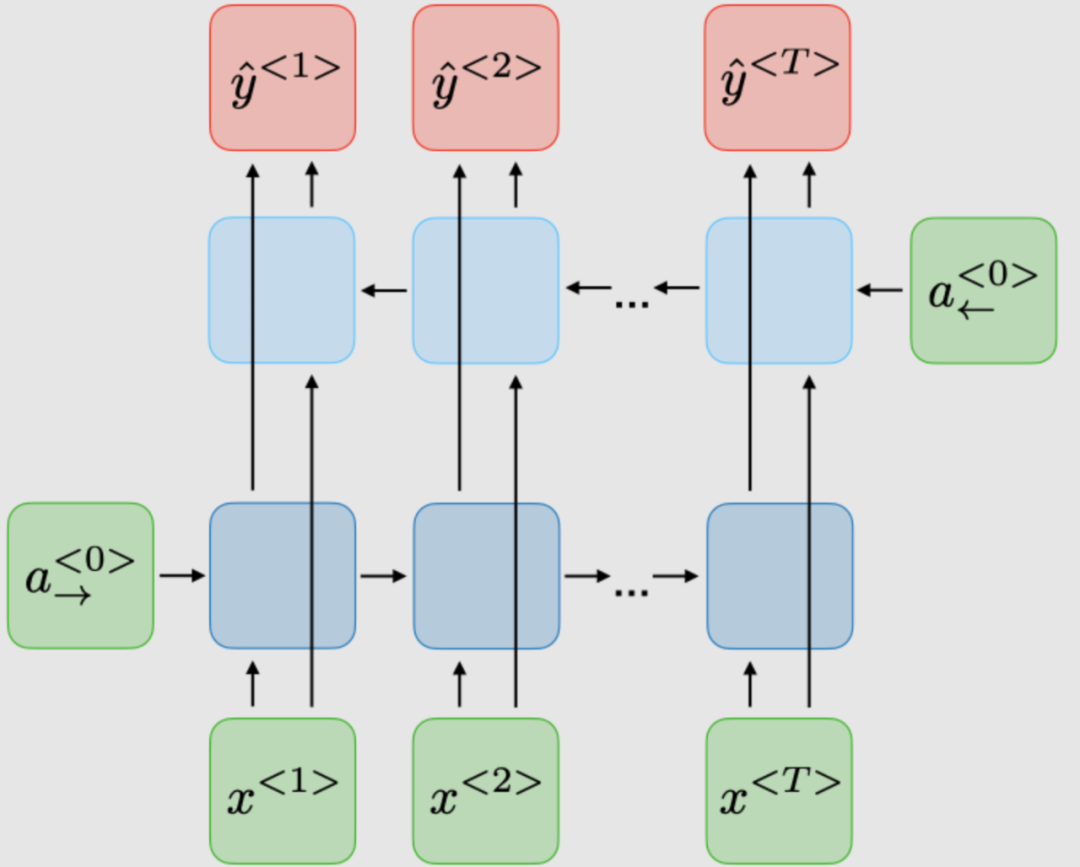
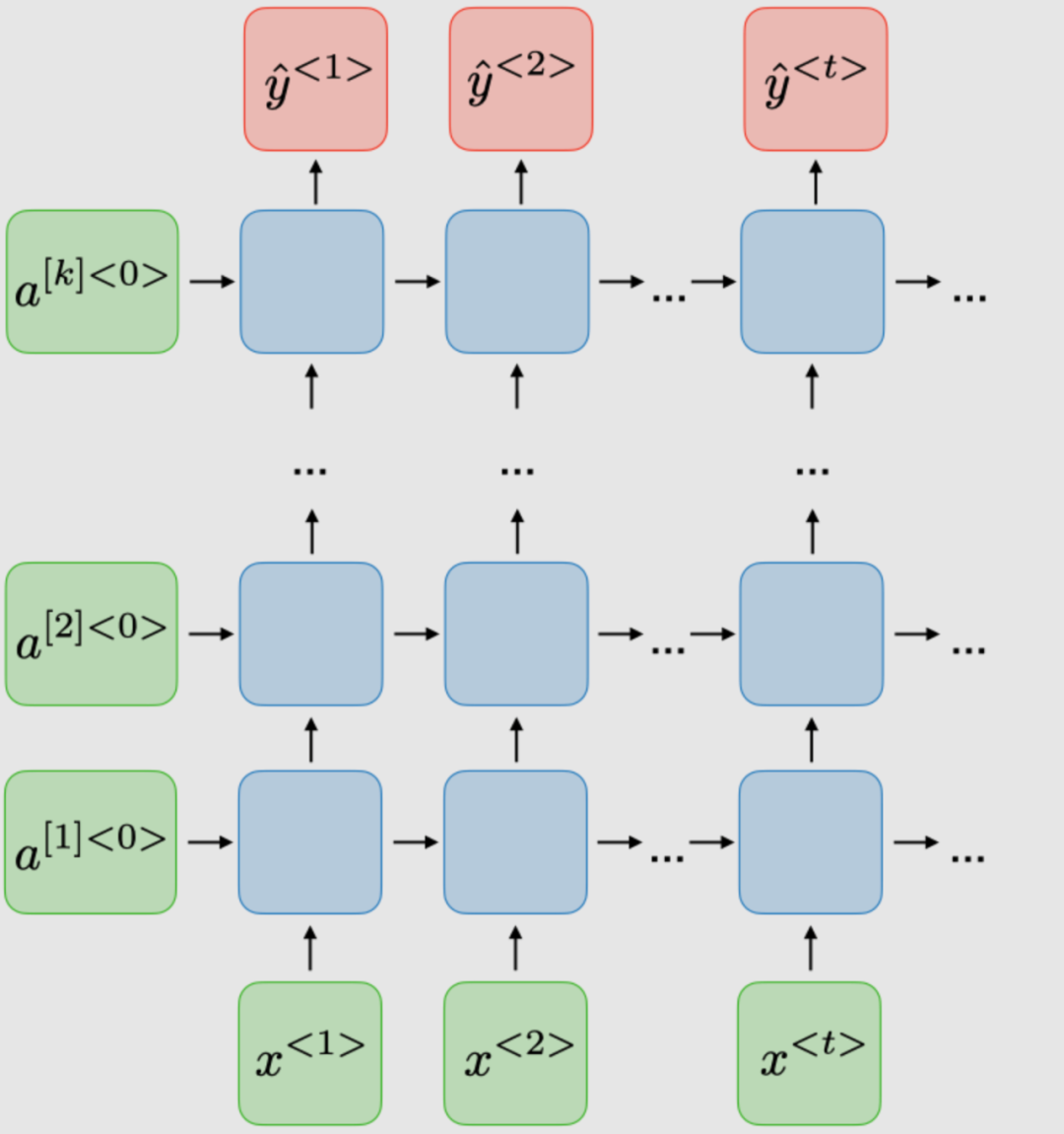
RNN的變體
下表總結了其他常用的RNN模型:
原文標題:神經網絡RNN圖解
文章出處:【微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101165 -
深度學習
+關注
關注
73文章
5513瀏覽量
121544
原文標題:神經網絡RNN圖解
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
RNN模型與傳統神經網絡的區別
LSTM神經網絡與傳統RNN的區別
rnn是遞歸神經網絡還是循環神經網絡
rnn是什么神經網絡模型
rnn是什么神經網絡
rnn神經網絡模型原理
RNN神經網絡適用于什么
rnn神經網絡基本原理
遞歸神經網絡是循環神經網絡嗎
循環神經網絡有哪些基本模型
循環神經網絡的基本原理是什么
什么是RNN(循環神經網絡)?RNN的基本原理和優缺點
GRU是什么?GRU模型如何讓你的神經網絡更聰明 掌握時間 掌握未來
助聽器降噪神經網絡模型
什么是RNN (循環神經網絡)?





 工商網監
工商網監
評論