 攝像頭傳統視覺算法與深度學習算法區別
攝像頭傳統視覺算法與深度學習算法區別
引言
攝像頭傳統視覺技術在算法上相對容易實現,因此已被現有大部分車廠用于輔助駕駛功能。但是隨著自動駕駛技術的發展,基于深度學習的算法開始興起,本期小編就來說說深度視覺算法相關技術方面的資料,讓我們一起來學習一下吧。
01深度學習概述
深度學習(DL,Deep Learning)是一類模式分析方法的統稱,屬于機器學習(ML,MachineLearning)領域中一個新的研究方向。深度學習通過學習樣本數據的內在規律和表示層次,能夠讓機器像人一樣具有分析、學習能力,可識別文字、圖像和聲音等數據,從而實現人工智能(AI,Artificial Intelligence)。
02深度學習意義
很多小伙伴們可能了解汽車想要實現自動駕駛,感知、決策與控制這三大系統是缺一不可的。其中,感知被我們放在了首位,因為車輛首先需要實時了解自車與現實世界三維變化的關系,即精準了解自車與周圍人、車、障礙物及道路要素等位置關系和變化。深度學習算法有效提升了攝像頭、激光雷達等傳感器的“智能”水平,這很大程度上也決定了自動駕駛汽車在復雜路況上的可靠度,因此深度學習的應用便成為了關鍵所在。另外汽車的感知傳感器雖然有多種,但是攝像頭是唯一一個通過圖像可以感知現實世界的傳感器,通過深度學習可以快速提升圖像的識別能力,讓我們的行駛更加安全。
03攝像頭傳統視覺算法與深度學習算法區別
有看過小編上期寫的關于攝像頭傳統視覺算法的小伙伴們就要問了,既然傳統攝像頭視覺算法已經可以使用,為什么還要研究深度學習算法呢?
因為傳統視覺算法有著自身的一些瓶頸,無論單目攝像頭還是多目攝像頭,傳統視覺算法都是基于人為特征提取得到樣本特征庫去識別計算。當自動駕駛車輛行駛過程中如發現特征庫沒有該樣本或特征庫樣本不準確,都會導致傳統視覺算法無法識別,另外傳統視覺算法還有在復雜場景下分割不佳等情況。因此,基于人為特征提取的傳統視覺算法具有性能瓶頸,無法完全滿足自動駕駛的目標檢測。
而攝像頭深度學習視覺算法的特征提取優勢是基于神經網絡算法,它模擬人的神經網絡,可將自動駕駛上攝像頭輸入的圖像(甚至激光雷達的點云)等信息進行語義分割,有效解決了傳統視覺算法對復雜的實際場景分割或樣本特征庫不佳的情況,讓圖像分類、語義分割、目標檢測和同步定位與地圖構建(SLAM)等任務上獲得更高的準確度。
接下來為了便于大家理解,小編先講講深度學習的神經網絡是什么?它是如何幫助攝像頭完成圖像識別等視覺計算的。它比傳統攝像頭的視覺算法又好在哪里?
04深度學習之神經網絡
深度學習大家看字面就很容易發現它是由“深度”+“學習”來完成的。“深度”就是模仿大腦的神經元之間傳遞處理信息的模式,其模型結構包括輸入層(inputlayer),隱藏層(Hiddenlayer)和輸出層(outputlayer),其中輸入層和輸出層一般只有1層,而隱藏層(或中間層)它往往有5層、6層,甚至更多層,多層隱層(中間層)節點被稱為深度學習里的“深度”;“學習”就是進行“特征學習”(featurelearning)或“表示學習”(representationlearning),也就是說,通過逐層特征變換,將樣本在原空間的特征表示變換到一個新特征空間,利用大數據來學習和調優,建立起適量的神經元計算節點和多層運算層次結構,盡可能的逼近現實的關聯關系,從而使特征分類或預測更容易。
上面的內容太抽象了,簡單來講神經網絡有三層:
輸入:輸入層每個神經元對應一個變量特征,輸入層的神經元相當于裝有數字的容器
輸出:輸出層,回歸問題為一個神經元,分類問題為多個神經元
參數:網絡中所有的參數,即中間層(或隱藏層)神經元的權重和偏置,每一個神經元代表該層神經網絡學習到的特征
這里大家只需要記住神經網絡不管規模的大小,都是由一個一個單神經元網絡堆疊起來的。
不好理解也沒有關系,下面小編舉個例子來說明一下吧。
假設我們要買房子,那么買房子我們所能承受的最終成交價格就是輸出層;
輸入層可能會有很多原始特征(即購房因素,如房屋面積,房間個數,附近學校個數,學校教育質量,公共交通,停車位);
中間層(或隱藏層)的神經元就是我們可以學習到的特征,如家庭人數,教育質量,出行
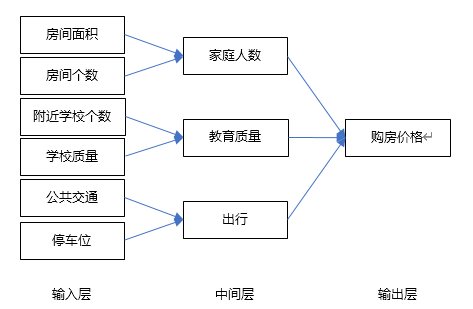
我們搜集的輸入特征數據越多,就能得到一個更為精細的神經網絡。而且隨著輸入層的原始特征神經元個數的增多,中間層就能從原始特征中學到足夠多的、更為細致的不同含義組合特征,比如房屋面積和房間數量能表示容納家庭人數,學校數量和學校質量表示教育質量。通過每個神經元對應的特征分類、統計和計算,最終得到我們想要輸出層“房價”。
那么對于攝像頭的深度學習來說,輸入層為攝像頭獲取的圖像,圖像對于攝像頭深度學習算法來說可以看成是一堆數據流,那么這些數據流還可以分成更多原始特征,如圖像各像素點的稀疏和密集、語義和幾何信息,還包括顏色、明暗、灰度等;中間層將這些輸入層的原始特征信息分類計算后,可識別出圖像中包含的物體有哪些(如車道線、障礙物、人、車、紅綠燈等),最終輸出與自動駕駛車有關的物體的實時距離、大小、形狀、紅綠燈顏色等要素,幫助自動駕駛車輛完成實時感知周圍環境識別、測距等功能。
以上我們可以看出,基于神經網絡的攝像頭視覺深度學習算法比基于人為特征提取的傳統攝像頭視覺算法要好用的多。因此目前主流的攝像頭視覺算法,都會使用深度學習去解決自動駕駛車對于圖像分類、圖像分割,對象檢測、多目標跟蹤、語義分割、可行駛區域、目標檢測和同步定位與地圖構建(SLAM)、場景分析等任務的準確率、識別率及圖像處理速度等,深度學習視覺算法也讓自動駕駛車快速量產落地成為可能。
05攝像頭深度學習算法
自動駕駛攝像頭傳感器所使用的深度學習視覺算法常用的有以下三種:
(1)基于卷積運算的神經網絡系統,即卷積神經網絡(CNN,ConvolutionalNeural Network)。在圖像識別中應用廣泛。
(2)基于多層神經元的自編碼神經網絡,包括自編碼(Autoencoder)以及近年來受到廣泛關注的稀疏編碼(SparseCoding)。
(3)以多層自編碼神經網絡的方式進行預訓練,進而結合鑒別信息進一步優化神經網絡權值的深度置信網絡(DBN,DeepBelief Networks)。
06深度學習是一個黑箱
雖然講了這么多,究竟基于神經網絡的深度學習算法是如何獲得輸入輸出的,其實上面的案例和算法分類也只是幫助我們去簡單理解深度學習的神經網絡,事實上深度學習是一個“黑箱”。“黑箱”意味著深度學習的中間過程不可知,深度學習產生的結果不可控。實際上程序員們編程后的神經網絡到底是如何學習,程序員們也不知道,只知道最終輸出結果是利用“萬能近似定理”(Universal approximation theorem)盡可能準確的擬合出輸入數據和輸出結果間的關系。所以,很多時候深度學習能很好的完成學習識別等任務,可是我們并不知道它學習到了什么,也不知道它為什么做出了特定的選擇。知其然而不知其所以然,這可以看作是深度學習的常態,也是深度學習工作中的一大挑戰。盡管如此,深度學習還是很好用滴!
當然,深度學習算法不僅僅可以用于自動駕駛攝像頭方面的視覺感知,還可以用于語音識別、交通、醫療、生物信息等領域。
這里順帶說一句,作為四維圖新而言,攝像頭不僅是四維圖新自動駕駛解決方案里的重要傳感器,也是四維圖新高精度地圖采集的主要工具。而且在高精度地圖采集和制圖標注過程中,不僅為四維圖新自動駕駛深度學習提供了海量的標注數據,還建立了四維圖新自動駕駛各類場景仿真庫,讓四維圖新基于深度學習的自動駕駛算法獲得的結果更為準確、高效。
四維圖新通過高精度地圖采集車上搭載的高清攝像頭、激光雷達等傳感器,將采集到的數據加以處理,并通過高度的自動化平臺進行繪制,從而為自動駕駛車感知、定位、規劃、決策等模塊提供重要支持。
目前四維圖新高精度地圖已經覆蓋國內32萬+公里高速公路以及10000+公里城市道路。
在自動駕駛仿真方面,依托大規模數據資源,形成參數化的場景模板,并具備靜態場景生成與動態場景制作的場景庫構建能力,為自動駕駛提供完備的仿真云平臺能力和商用分析平臺能力。
結語:
相信通過這幾期的車載攝像頭以及相應視覺算法的介紹,讓大家對攝像頭視覺傳感器有了一定的了解。眾所周知,攝像頭雖然可以實現很多功能,但是在逆光、光線昏暗和攝像頭遮擋等某些特定環境下,攝像頭的使用效果也會大打折扣,因此我們需要汽車其他傳感器的冗余及各傳感器數據融合計算來保障我們的自動駕駛車更加安全。而我們四維圖新一直在致力于成為更值得客戶信賴的智能出行科技公司,也希望我們的自動駕駛相關產品為小伙伴們帶來更加安全、放心、舒心的自動駕駛體驗。
那么下期,小編繼續為大家整理其他傳感器相關方面的資料,讓大家對自動駕駛更為了解,敬請期待吧!
原文標題:新·知丨自動駕駛傳感器那點事 之 攝像頭深度學習視覺技術
文章出處:【微信公眾號:四維圖新NavInfo】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
攝像頭
+關注
關注
60文章
4862瀏覽量
96299 -
自動駕駛
+關注
關注
785文章
13930瀏覽量
167002 -
深度學習
+關注
關注
73文章
5513瀏覽量
121544
原文標題:新·知丨自動駕駛傳感器那點事 之 攝像頭深度學習視覺技術
文章出處:【微信號:realnavinfo,微信公眾號:四維圖新NavInfo】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

多光譜火焰檢測攝像頭

攝像頭及紅外成像的基本工作原理


利用Matlab函數實現深度學習算法
深度學習的基本原理與核心算法
神經網絡芯片與傳統芯片的區別和聯系
基于FPGA的攝像頭心率檢測裝置設計
智能攝像頭抄表器是什么?

深度解析深度學習下的語義SLAM

機器視覺網卡:連接攝像頭和計算設備之間的橋梁







 工商網監
工商網監
評論