") 計算機(jī)視覺中主要的五大技術(shù)
計算機(jī)視覺中主要的五大技術(shù)
摘要:本文主要介紹計算機(jī)視覺中主要的五大技術(shù),分別為圖像分類、目標(biāo)檢測、目標(biāo)跟蹤、語義分割以及實例分割。針對每項技術(shù)都給出了基本概念及相應(yīng)的典型方法,簡單通俗、適合閱讀。
計算機(jī)視覺是當(dāng)前最熱門的研究之一,是一門多學(xué)科交叉的研究,涵蓋計算機(jī)科學(xué)(圖形學(xué)、算法、理論研究等)、數(shù)學(xué)(信息檢索、機(jī)器學(xué)習(xí))、工程(機(jī)器人、NLP等)、生物學(xué)(神經(jīng)系統(tǒng)科學(xué))和心理學(xué)(認(rèn)知科學(xué))。由于計算機(jī)視覺表示對視覺環(huán)境及背景的相對理解,很多科學(xué)家相信,這一領(lǐng)域的研究將為人工智能行業(yè)的發(fā)展奠定基礎(chǔ)。
那么,什么是計算機(jī)視覺呢?下面是一些公認(rèn)的定義:
1.從圖像中清晰地、有意義地描述物理對象的結(jié)構(gòu)(Ballard & Brown,1982);
2.由一個或多個數(shù)字圖像計算立體世界的性質(zhì)(Trucco & Verri,1998);
3.基于遙感圖像對真實物體和場景做出有用的決定(Sockman & Shapiro,2001);
那么,為什么研究計算機(jī)視覺呢?答案很明顯,從該領(lǐng)域可以衍生出一系列的應(yīng)用程序,比如:
1.人臉識別:人臉檢測算法,能夠從照片中認(rèn)出某人的身份;
2.圖像檢索:類似于谷歌圖像使用基于內(nèi)容的查詢來搜索相關(guān)圖像,算法返回與3.查詢內(nèi)容最佳匹配的圖像。
4.游戲和控制:體感游戲;
5.監(jiān)控:公共場所隨處可見的監(jiān)控攝像機(jī),用來監(jiān)視可疑行為;
6.生物識別技術(shù):指紋、虹膜和人臉匹配是生物特征識別中常用的方法;
7.智能汽車:視覺仍然是觀察交通標(biāo)志、信號燈及其它視覺特征的主要信息來源;
正如斯坦福大學(xué)公開課CS231所言,計算機(jī)視覺任務(wù)大多是基于卷積神經(jīng)網(wǎng)絡(luò)完成。比如圖像分類、定位和檢測等。那么,對于計算機(jī)視覺而言,有哪些任務(wù)是占據(jù)主要地位并對世界有所影響的呢?本篇文章將分享給讀者5種重要的計算機(jī)視覺技術(shù),以及其相關(guān)的深度學(xué)習(xí)模型和應(yīng)用程序。相信這5種技術(shù)能夠改變你對世界的看法。
1.圖像分類
圖像分類這一任務(wù)在我們的日常生活中經(jīng)常發(fā)生,我們習(xí)慣了于此便不以為然。每天早上洗漱刷牙需要拿牙刷、毛巾等生活用品,如何準(zhǔn)確的拿到這些用品便是一個圖像分類任務(wù)。官方定義為:給定一組圖像集,其中每張圖像都被標(biāo)記了對應(yīng)的類別。之后為一組新的測試圖像集預(yù)測其標(biāo)簽類別,并測量預(yù)測準(zhǔn)確性。
如何編寫一個可以將圖像分類的算法呢?計算機(jī)視覺研究人員已經(jīng)提出了一種數(shù)據(jù)驅(qū)動的方法來解決這個問題。研究人員在代碼中不再關(guān)心圖像如何表達(dá),而是為計算機(jī)提供許多很多圖像(包含每個類別),之后開發(fā)學(xué)習(xí)算法,讓計算機(jī)自己學(xué)習(xí)這些圖像的特征,之后根據(jù)學(xué)到的特征對圖像進(jìn)行分類。
鑒于此,完整的圖像分類步驟一般形式如下:
1.首先,輸入一組訓(xùn)練圖像數(shù)據(jù)集;
2.然后,使用該訓(xùn)練集訓(xùn)練一個分類器,該分類器能夠?qū)W習(xí)每個類別的特征;
3.最后,使用測試集來評估分類器的性能,即將預(yù)測出的結(jié)果與真實類別標(biāo)記進(jìn)行比較;
對于圖像分類而言,最受歡迎的方法是卷積神經(jīng)網(wǎng)絡(luò)(CNN)。CNN是深度學(xué)習(xí)中的一種常用方法,其性能遠(yuǎn)超一般的機(jī)器學(xué)習(xí)算法。CNN網(wǎng)絡(luò)結(jié)構(gòu)基本是由卷積層、池化層以及全連接層組成,其中,卷積層被認(rèn)為是提取圖像特征的主要部件,它類似于一個“掃描儀”,通過卷積核與圖像像素矩陣進(jìn)行卷積運算,每次只“掃描”卷積核大小的尺寸,之后滑動到下一個區(qū)域進(jìn)行相關(guān)的運算,這種計算叫作滑動窗口。
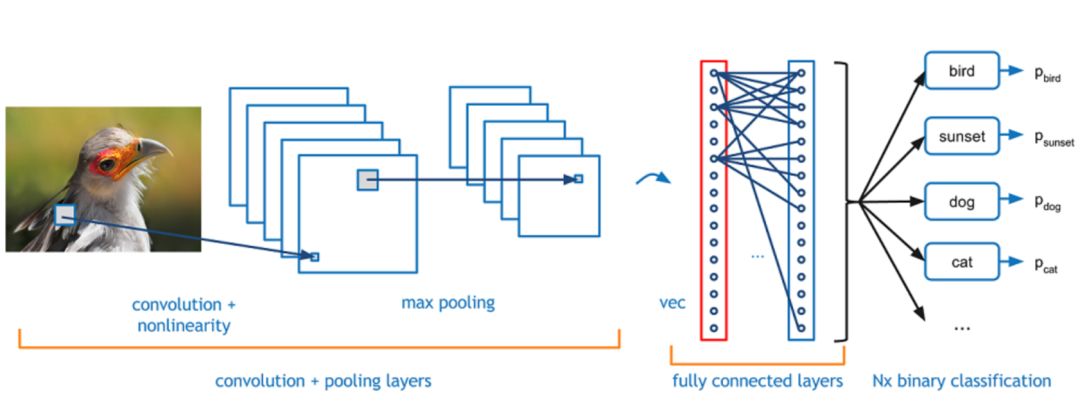
從圖中可以看到,輸入圖像送入卷積神經(jīng)網(wǎng)絡(luò)中,通過卷積層進(jìn)行特征提取,之后通過池化層過濾細(xì)節(jié)(一般采用最大值池化、平均池化),最后在全連接層進(jìn)行特征展開,送入相應(yīng)的分類器得到其分類結(jié)果。
大多數(shù)圖像分類算法都是在ImageNet數(shù)據(jù)集上訓(xùn)練的,該數(shù)據(jù)集由120萬張的圖像組成,涵蓋1000個類別,該數(shù)據(jù)集也可以稱作改變?nèi)斯ぶ悄芎褪澜绲臄?shù)據(jù)集。ImagNet 數(shù)據(jù)集讓人們意識到,構(gòu)建優(yōu)良數(shù)據(jù)集的工作是 AI 研究的核心,數(shù)據(jù)和算法一樣至關(guān)重要。為此,世界組織也舉辦了針對該數(shù)據(jù)集的挑戰(zhàn)賽——ImageNet挑戰(zhàn)賽。
第一屆ImageNet挑戰(zhàn)賽的第一名是由Alex Krizhevsky(NIPS 2012)獲得,采用的方法是深層卷積神經(jīng)網(wǎng)絡(luò),網(wǎng)絡(luò)結(jié)構(gòu)如下圖所示。在該模型中,采用了一些技巧,比如最大值池化、線性修正單元激活函數(shù)ReLU以及使用GPU仿真計算等,AlexNet模型拉開了深度學(xué)習(xí)研究的序幕。
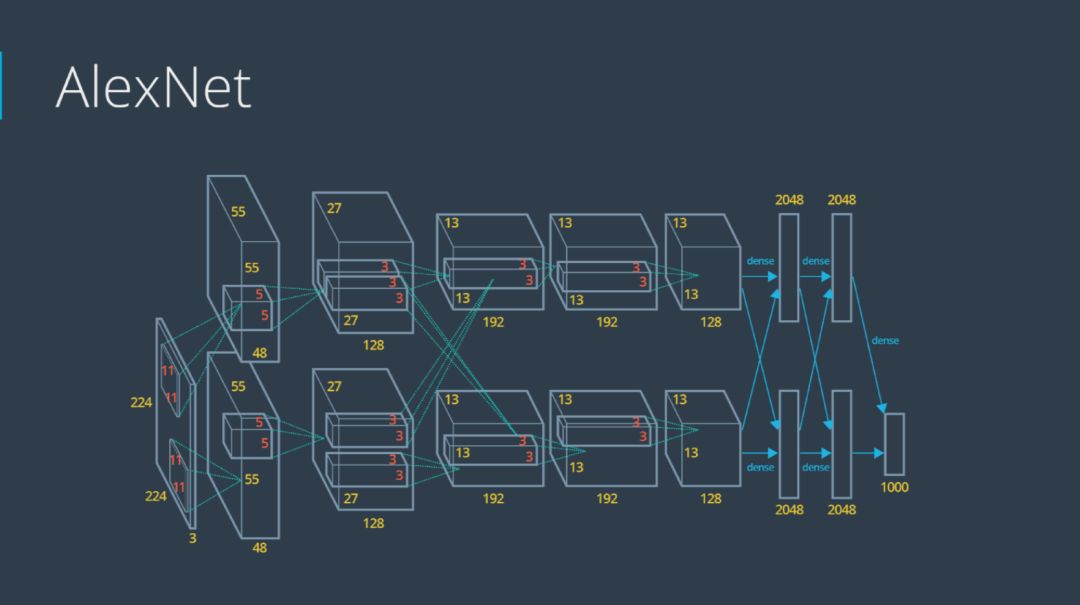
自從AlexNet網(wǎng)絡(luò)模型贏得比賽之后,有很多基于CNN的算法也在ImageNet上取得了特別好的成績,比如ZFNet(2013)、GoogleNet(2014)、VGGNet(2014)、ResNet(2015)以及DenseNet(2016)等。
2.目標(biāo)檢測
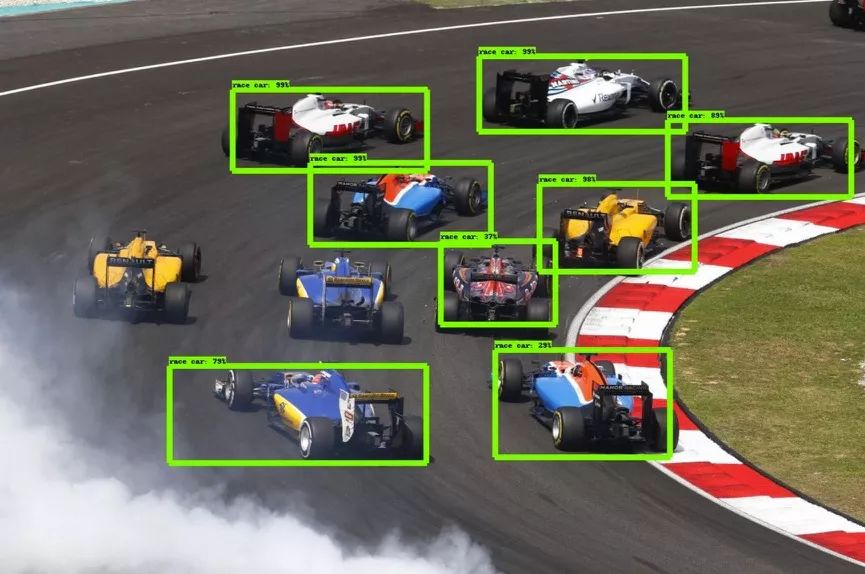
目標(biāo)檢測通常是從圖像中輸出單個目標(biāo)的Bounding Box(邊框)以及標(biāo)簽。比如,在汽車檢測中,必須使用邊框檢測出給定圖像中的所有車輛。
之前在圖像分類任務(wù)中大放光彩的CNN同樣也可以應(yīng)用于此。第一個高效模型是R-CNN(基于區(qū)域的卷積神經(jīng)網(wǎng)絡(luò)),如下圖所示。在該網(wǎng)絡(luò)中,首先掃描圖像并使用搜索算法生成可能區(qū)域,之后對每個可能區(qū)域運行CNN,最后將每個CNN網(wǎng)絡(luò)的輸出送入SVM分類器中來對區(qū)域進(jìn)行分類和線性回歸,并用邊框標(biāo)注目標(biāo)。
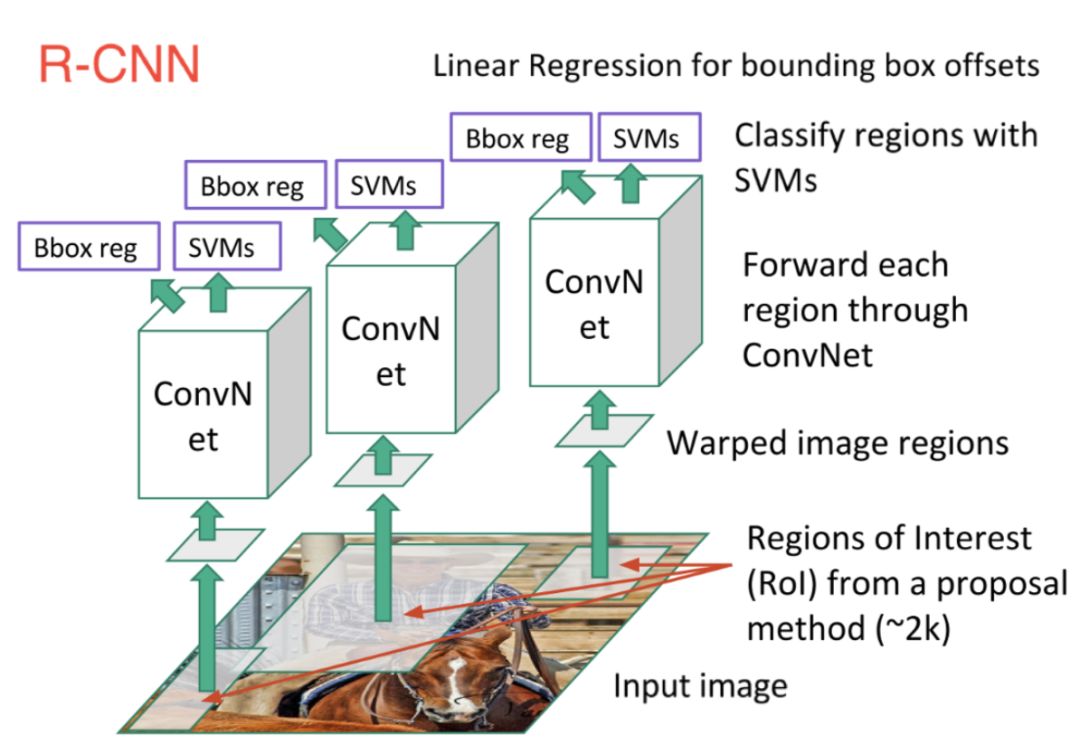
本質(zhì)上,是將物體檢測轉(zhuǎn)換成圖像分類問題。但該方法存在一些問題,比如訓(xùn)練速度慢,耗費內(nèi)存、預(yù)測時間長等。
為了解決上述這些問題,Ross Girshickyou提出Fast R-CNN算法,從兩個方面提升了檢測速度:
1)在給出建議區(qū)域之前執(zhí)行特征提取,從而只需在整幅圖像上運行一次CNN;2)使用Softmax分類器代替SVM分類器;
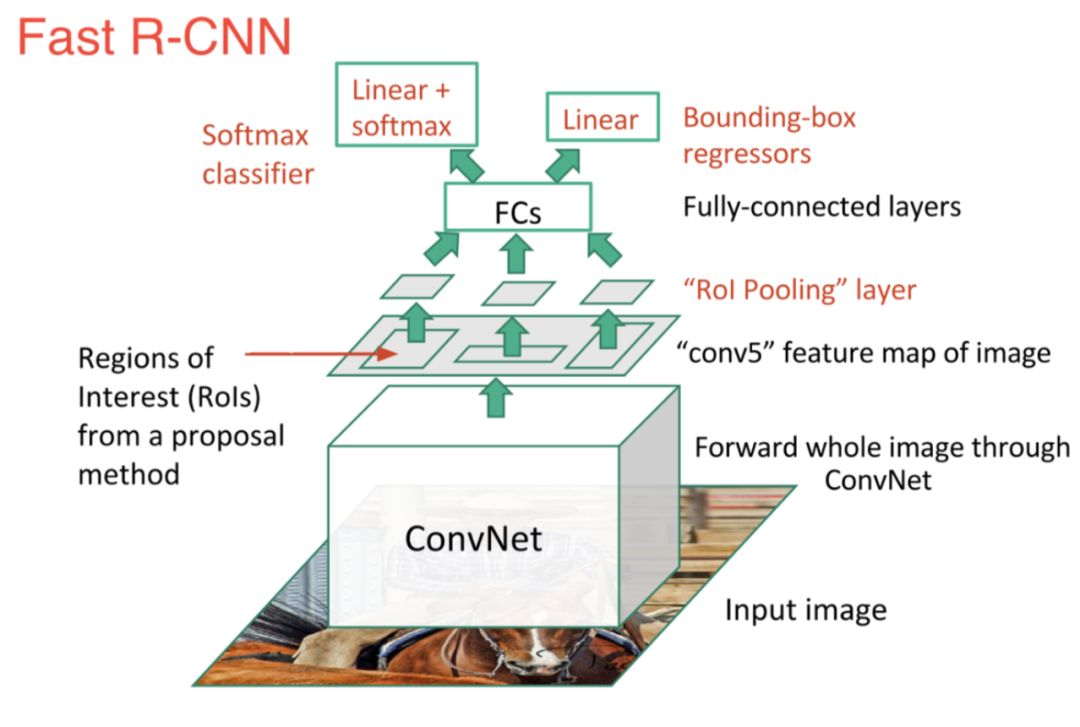
雖然Fast R-CNN在速度方面有所提升,然而,選擇搜索算法仍然需要大量的時間來生成建議區(qū)域。為此又提出了Faster R-CNN算法,該模型提出了候選區(qū)域生成網(wǎng)絡(luò)(RPN),用來代替選擇搜索算法,將所有內(nèi)容整合在一個網(wǎng)絡(luò)中,大大提高了檢測速度和精度。
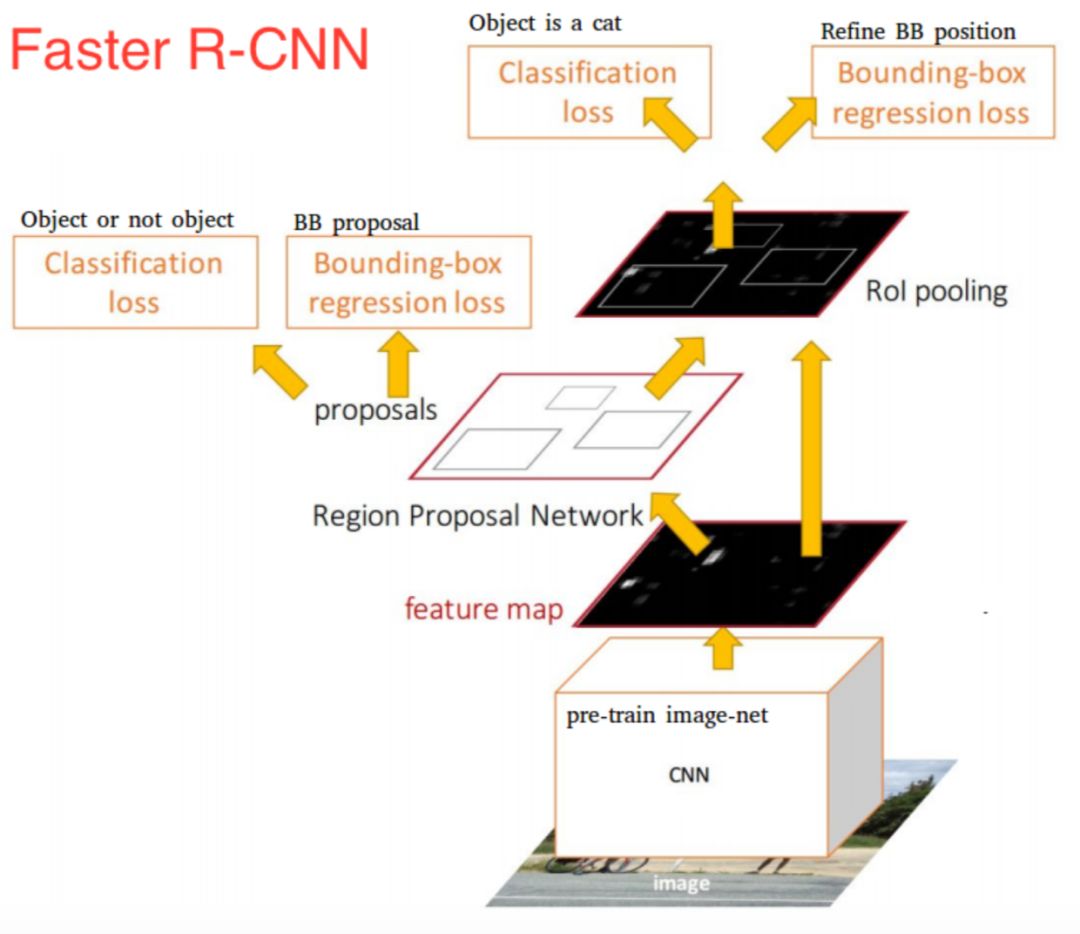
近年來,目標(biāo)檢測研究趨勢主要向更快、更有效的檢測系統(tǒng)發(fā)展。目前已經(jīng)有一些其它的方法可供使用,比如YOLO、SSD以及R-FCN等。
3.目標(biāo)跟蹤
目標(biāo)跟蹤是指在給定場景中跟蹤感興趣的具體對象或多個對象的過程。簡單來說,給出目標(biāo)在跟蹤視頻第一幀中的初始狀態(tài)(如位置、尺寸),自動估計目標(biāo)物體在后續(xù)幀中的狀態(tài)。該技術(shù)對自動駕駛汽車等領(lǐng)域顯得至關(guān)重要。
根據(jù)觀察模型,目標(biāo)跟蹤可以分為兩類:產(chǎn)生式(generative method)和判別式(discriminative method)。其中,產(chǎn)生式方法主要運用生成模型描述目標(biāo)的表觀特征,之后通過搜索候選目標(biāo)來最小化重構(gòu)誤差。常用的算法有稀疏編碼(sparse coding)、主成分分析(PCA)等。與之相對的,判別式方法通過訓(xùn)練分類器來區(qū)分目標(biāo)和背景,其性能更為穩(wěn)定,逐漸成為目標(biāo)跟蹤這一領(lǐng)域的主要研究方法。常用的算法有堆棧自動編碼器(SAE)、卷積神經(jīng)網(wǎng)絡(luò)(CNN)等。
使用SAE方法進(jìn)行目標(biāo)跟蹤的最經(jīng)典深層網(wǎng)絡(luò)是Deep Learning Tracker(DLT),提出了離線預(yù)訓(xùn)練和在線微調(diào)。該方法的主要步驟如下:
1.先使用棧式自動編碼器(SDAE)在大規(guī)模自然圖像數(shù)據(jù)集上進(jìn)行無監(jiān)督離線預(yù)訓(xùn)練來獲得通用的物體表征能力。
2.將預(yù)訓(xùn)練網(wǎng)絡(luò)的編碼部分與分類器相結(jié)合組成分類網(wǎng)絡(luò),然后利用從初始幀獲得的正、負(fù)樣本對網(wǎng)絡(luò)進(jìn)行微調(diào),使其可以區(qū)分當(dāng)前對象和背景。在跟蹤過程中,選擇分類網(wǎng)絡(luò)輸出得分最大的patch作為最終預(yù)測目標(biāo)。
3.模型更新策略采用限定閾值的方法。
基于CNN完成目標(biāo)跟蹤的典型算法是FCNT和MD Net。
FCNT的亮點之一在于對ImageNet上預(yù)訓(xùn)練得到的CNN特征在目標(biāo)跟蹤任務(wù)上的性能做了深入的分析:
1.CNN的特征圖可以用來做跟蹤目標(biāo)的定位;
2.CNN的許多特征圖存在噪聲或者和物體跟蹤區(qū)分目標(biāo)和背景的任務(wù)關(guān)聯(lián)較小;
3.CNN不同層提取的特征不一樣。高層特征更加抽象,擅長區(qū)分不同類別的物體,而低層特征更加關(guān)注目標(biāo)的局部細(xì)節(jié)。
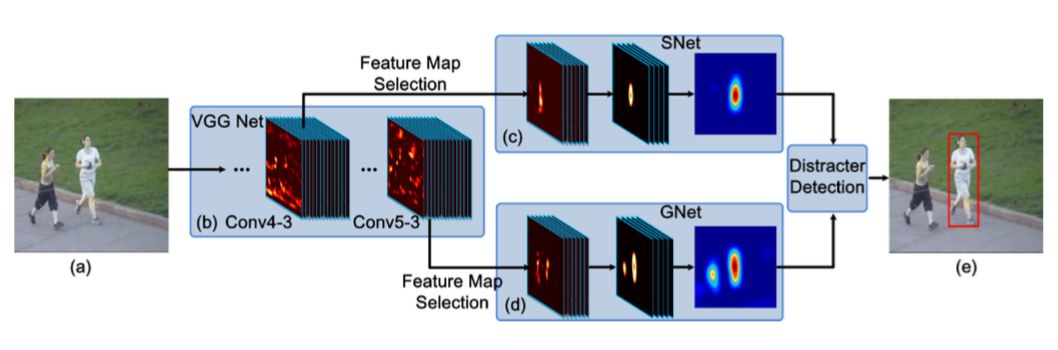
基于以上觀察,F(xiàn)CNT最終提出了如下圖所示的模型結(jié)構(gòu):
1.對于Conv4-3和Con5-3采用VGG網(wǎng)絡(luò)的結(jié)構(gòu),選出和當(dāng)前跟蹤目標(biāo)最相關(guān)的特征圖通道;
2.為了避免過擬合,對篩選出的Conv5-3和Conv4-3特征分別構(gòu)建捕捉類別信息GNet和SNet;
3.在第一幀中使用給出的邊框生成熱度圖(heap map)回歸訓(xùn)練SNet和GNet;
4.對于每一幀,其預(yù)測結(jié)果為中心裁剪區(qū)域,將其分別輸入GNet和SNet中,得到兩個預(yù)測的熱圖,并根據(jù)是否有干擾來決定使用哪個熱圖。
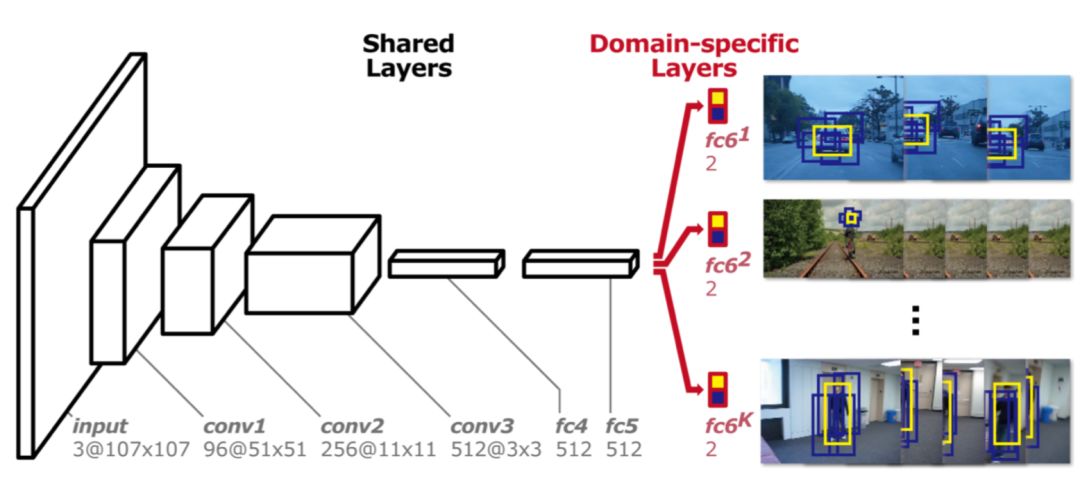
區(qū)別與FCNT,MD Net使用視頻中所有序列來跟蹤它們的運動。但序列訓(xùn)練也存在問題,即不同跟蹤序列與跟蹤目標(biāo)完全不一樣。最終MD Net提出多域的訓(xùn)練思想,網(wǎng)絡(luò)結(jié)構(gòu)如下圖所示,該網(wǎng)絡(luò)分為兩個部分:共享層和分類層。網(wǎng)絡(luò)結(jié)構(gòu)部分用于提取特征,最后分類層區(qū)分不同的類別。
4.語義分割

計算機(jī)視覺的核心是分割過程,它將整個圖像分成像素組,然后對其進(jìn)行標(biāo)記和分類。語言分割試圖在語義上理解圖像中每個像素的角色(例如,汽車、摩托車等)。
CNN同樣在此項任務(wù)中展現(xiàn)了其優(yōu)異的性能。典型的方法是FCN,結(jié)構(gòu)如下圖所示。FCN模型輸入一幅圖像后直接在輸出端得到密度預(yù)測,即每個像素所屬的類別,從而得到一個端到端的方法來實現(xiàn)圖像語義分割。
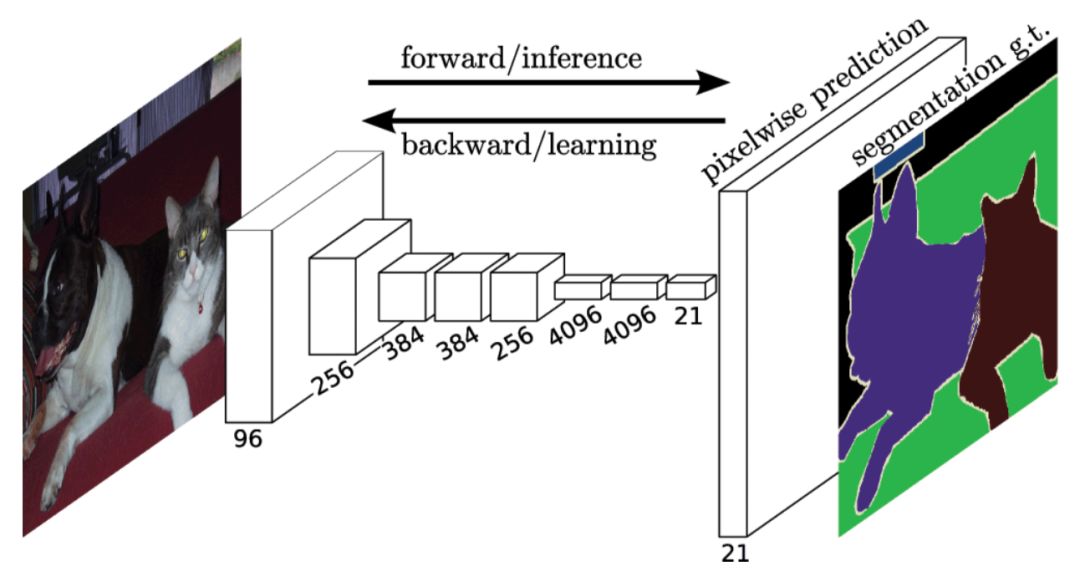
與FCN上采樣不同,SegNet將最大池化轉(zhuǎn)移至解碼器中,改善了分割分辨率。提升了內(nèi)存的使用效率。
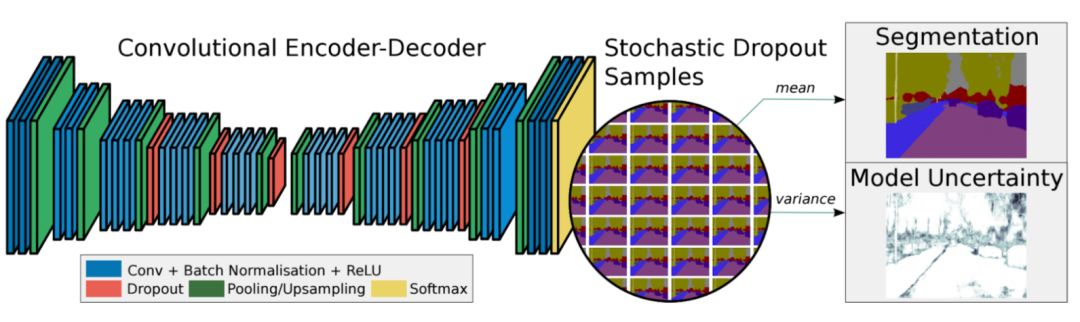
還有一些其他的方法,比如全卷積網(wǎng)絡(luò)、擴(kuò)展卷積,DeepLab以及RefineNet等。
5.實例分割

除了語義分割之外,實例分割還分割了不同的類實例,例如用5種不同顏色標(biāo)記5輛汽車。在分類中,通常有一個以一個物體為焦點的圖像,任務(wù)是說出這個圖像是什么。但是為了分割實例,我們需要執(zhí)行更復(fù)雜的任務(wù)。我們看到復(fù)雜的景象,有多個重疊的物體和日常背景,我們不僅對這些日常物體進(jìn)行分類,而且還確定它們的邊界、差異和彼此之間的關(guān)系。
到目前為止,我們已經(jīng)看到了如何以許多有趣的方式使用CNN功能來在帶有邊界框的圖像中有效地定位日常用品。我們可以擴(kuò)展這些技術(shù)來定位每個對象的精確像素,而不僅僅是邊界框嗎?
CNN在此項任務(wù)中同樣表現(xiàn)優(yōu)異,典型算法是Mask R-CNN。Mask R-CNN在Faster R-CNN的基礎(chǔ)上添加了一個分支以輸出二元掩膜。該分支與現(xiàn)有的分類和邊框回歸并行,如下圖所示:
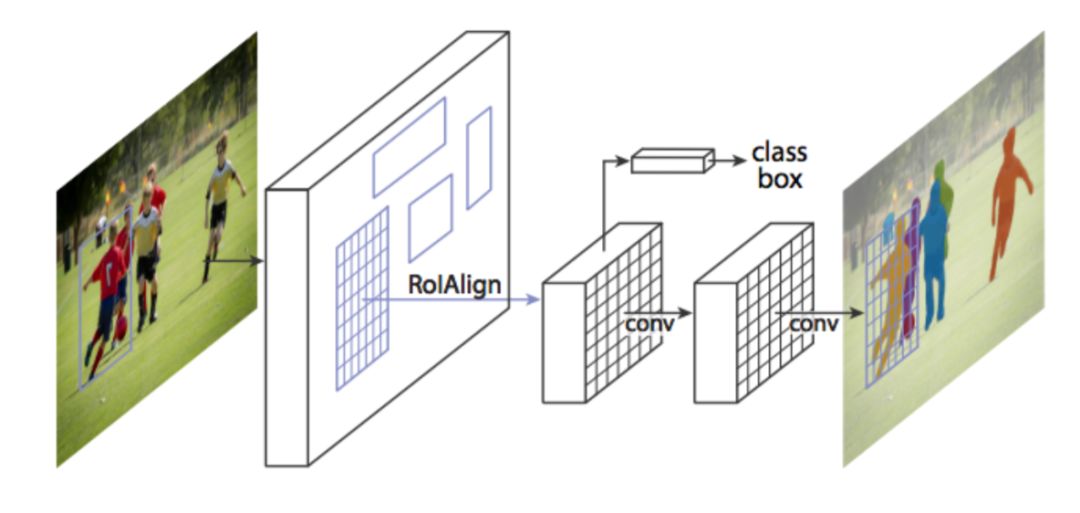
Faster-RCNN在實例分割任務(wù)中表現(xiàn)不好,為了修正其缺點,Mask R-CNN提出了RolAlign層,通過調(diào)整Rolpool來提升精度。從本質(zhì)上講,RolAlign使用雙線性插值避免了取整誤差,該誤差導(dǎo)致檢測和分割不準(zhǔn)確。
一旦掩膜被生成,Mask R-CNN結(jié)合分類器和邊框就能產(chǎn)生非常精準(zhǔn)的分割:

結(jié)論
以上五種計算機(jī)視覺技術(shù)可以幫助計算機(jī)從單個或一系列圖像中提取、分析和理解有用信息。此外,還有很多其它的先進(jìn)技術(shù)等待我們的探索,比如風(fēng)格轉(zhuǎn)換、動作識別等。希望本文能夠引導(dǎo)你改變看待這個世界的方式。
責(zé)任編輯:lq
-
圖像分類
+關(guān)注
關(guān)注
0文章
93瀏覽量
11956 -
計算機(jī)視覺
+關(guān)注
關(guān)注
8文章
1700瀏覽量
46127 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5514瀏覽量
121551
原文標(biāo)題:一文讀懂深度學(xué)習(xí)在計算機(jī)視覺領(lǐng)域中的應(yīng)用
文章出處:【微信號:vision263com,微信公眾號:新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
計算機(jī)視覺有哪些優(yōu)缺點
計算機(jī)視覺技術(shù)的AI算法模型
機(jī)器視覺和計算機(jī)視覺有什么區(qū)別
計算機(jī)視覺的五大技術(shù)
計算機(jī)視覺的工作原理和應(yīng)用
機(jī)器人視覺與計算機(jī)視覺的區(qū)別與聯(lián)系
計算機(jī)視覺與人工智能的關(guān)系是什么
計算機(jī)視覺與智能感知是干嘛的
計算機(jī)視覺和機(jī)器視覺區(qū)別在哪
計算機(jī)視覺在人工智能領(lǐng)域有哪些主要應(yīng)用?
計算機(jī)視覺屬于人工智能嗎
深度學(xué)習(xí)在計算機(jī)視覺領(lǐng)域的應(yīng)用
機(jī)器視覺與計算機(jī)視覺的區(qū)別
計算機(jī)視覺的主要研究方向
計算機(jī)視覺的十大算法

- 設(shè)計技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測量儀表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動
- 處理器/DSP
- EDA/IC設(shè)計
- 存儲技術(shù)
- 光電顯示
- EMC/EMI設(shè)計
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計資源
- 設(shè)計技術(shù)
- 電子百科
- 電子視頻
- 元器件知識
- 工具箱
- VIP會員
- 最新技術(shù)文章
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會
- 活動策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測驗
- 設(shè)計大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟(jì)技術(shù)開發(fā)區(qū)航空路6號手機(jī)智能終端產(chǎn)業(yè)園2號廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
評論