") python多線程和多進(jìn)程的對(duì)比
python多線程和多進(jìn)程的對(duì)比
1. 基本概念
在開(kāi)始講解理論知識(shí)之前,先過(guò)一下幾個(gè)基本概念。雖然咱是進(jìn)階教程,但我也希望寫得更小白,更通俗易懂。
串行:一個(gè)人在同一時(shí)間段只能干一件事,譬如吃完飯才能看電視;
并行:一個(gè)人在同一時(shí)間段可以干多件事,譬如可以邊吃飯邊看電視;
在Python中,多線程 和 協(xié)程 雖然是嚴(yán)格上來(lái)說(shuō)是串行,但卻比一般的串行程序執(zhí)行效率高得很。 一般的串行程序,在程序阻塞的時(shí)候,只能干等著,不能去做其他事。就好像,電視上播完正劇,進(jìn)入廣告時(shí)間,我們卻不能去趁廣告時(shí)間是吃個(gè)飯。對(duì)于程序來(lái)說(shuō),這樣做顯然是效率極低的,是不合理的。
雖然 多線程 和 協(xié)程 已經(jīng)相當(dāng)智能了。但還是不夠高效,最高效的應(yīng)該是一心多用,邊看電視邊吃飯邊聊天。這就是我們的 多進(jìn)程 才能做的事了。
2. 單線程VS多線程VS多進(jìn)程
文字總是蒼白無(wú)力的,不如用代碼直接來(lái)測(cè)試一下。
開(kāi)始對(duì)比之前,首先定義四種類型的場(chǎng)景
- CPU計(jì)算密集型
- 磁盤IO密集型
- 網(wǎng)絡(luò)IO密集型
- 【模擬】IO密集型
為什么是這幾種場(chǎng)景,這和多線程 多進(jìn)程的適用場(chǎng)景有關(guān)。結(jié)論里,我再說(shuō)明。
# CPU計(jì)算密集型
def count(x=1, y=1):
# 使程序完成150萬(wàn)計(jì)算
c = 0
while c < 500000:
c += 1
x += x
y += y
# 磁盤讀寫IO密集型
def io_disk():
with open("file.txt", "w") as f:
for x in range(5000000):
f.write("python-learning\n")
# 網(wǎng)絡(luò)IO密集型
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'}
url = "https://www.tieba.com/"
def io_request():
try:
webPage = requests.get(url, headers=header)
html = webPage.text
return
except Exception as e:
return {"error": e}
# 【模擬】IO密集型
def io_simulation():
time.sleep(2)
比拼的指標(biāo),我們用時(shí)間來(lái)考量。時(shí)間耗費(fèi)得越少,說(shuō)明效率越高。
為了方便,使得代碼看起來(lái),更加簡(jiǎn)潔,我這里先定義是一個(gè)簡(jiǎn)單的 時(shí)間計(jì)時(shí)器 的裝飾器。 如果你對(duì)裝飾器還不是很了解,也沒(méi)關(guān)系,你只要知道它是用于 計(jì)算函數(shù)運(yùn)行時(shí)間的東西就可以了。
def timer(mode):
def wrapper(func):
def deco(*args, **kw):
type = kw.setdefault('type', None)
t1=time.time()
func(*args, **kw)
t2=time.time()
cost_time = t2-t1
print("{}-{}花費(fèi)時(shí)間:{}秒".format(mode, type,cost_time))
return deco
return wrapper
第一步,先來(lái)看看單線程的
@timer("【單線程】")
def single_thread(func, type=""):
for i in range(10):
func()
# 單線程
single_thread(count, type="CPU計(jì)算密集型")
single_thread(io_disk, type="磁盤IO密集型")
single_thread(io_request,type="網(wǎng)絡(luò)IO密集型")
single_thread(io_simulation,type="模擬IO密集型")
看看結(jié)果
【單線程】-CPU計(jì)算密集型花費(fèi)時(shí)間:83.42633867263794秒
【單線程】-磁盤IO密集型花費(fèi)時(shí)間:15.641993284225464秒
【單線程】-網(wǎng)絡(luò)IO密集型花費(fèi)時(shí)間:1.1397218704223633秒
【單線程】-模擬IO密集型花費(fèi)時(shí)間:20.020972728729248秒
第二步,再來(lái)看看多線程的
@timer("【多線程】")
def multi_thread(func, type=""):
thread_list = []
for i in range(10):
t=Thread(target=func, args=())
thread_list.append(t)
t.start()
e = len(thread_list)
while True:
for th in thread_list:
if not th.is_alive():
e -= 1
if e <= 0:
break
# 多線程
multi_thread(count, type="CPU計(jì)算密集型")
multi_thread(io_disk, type="磁盤IO密集型")
multi_thread(io_request, type="網(wǎng)絡(luò)IO密集型")
multi_thread(io_simulation, type="模擬IO密集型")
看看結(jié)果
【多線程】-CPU計(jì)算密集型花費(fèi)時(shí)間:93.82986998558044秒
【多線程】-磁盤IO密集型花費(fèi)時(shí)間:13.270896911621094秒
【多線程】-網(wǎng)絡(luò)IO密集型花費(fèi)時(shí)間:0.1828296184539795秒
【多線程】-模擬IO密集型花費(fèi)時(shí)間:2.0288875102996826秒
第三步,最后來(lái)看看多進(jìn)程
@timer("【多進(jìn)程】")
def multi_process(func, type=""):
process_list = []
for x in range(10):
p = Process(target=func, args=())
process_list.append(p)
p.start()
e = process_list.__len__()
while True:
for pr in process_list:
if not pr.is_alive():
e -= 1
if e <= 0:
break
# 多進(jìn)程
multi_process(count, type="CPU計(jì)算密集型")
multi_process(io_disk, type="磁盤IO密集型")
multi_process(io_request, type="網(wǎng)絡(luò)IO密集型")
multi_process(io_simulation, type="模擬IO密集型")
看看結(jié)果
【多進(jìn)程】-CPU計(jì)算密集型花費(fèi)時(shí)間:9.082211017608643秒
【多進(jìn)程】-磁盤IO密集型花費(fèi)時(shí)間:1.287339448928833秒
【多進(jìn)程】-網(wǎng)絡(luò)IO密集型花費(fèi)時(shí)間:0.13074755668640137秒
【多進(jìn)程】-模擬IO密集型花費(fèi)時(shí)間:2.0076842308044434秒
3. 性能對(duì)比成果總結(jié)
將結(jié)果匯總一下,制成表格。
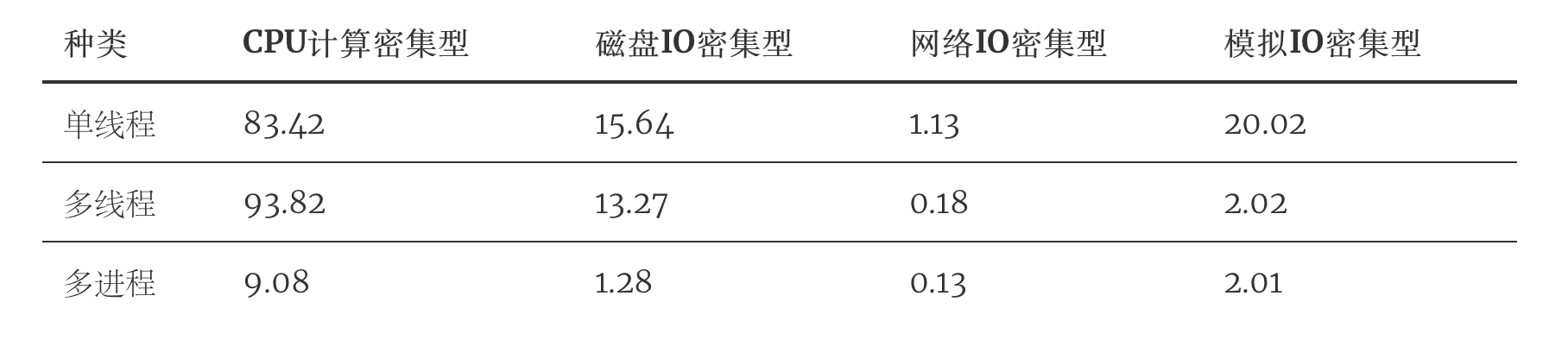
我們來(lái)分析下這個(gè)表格。
首先是CPU密集型,多線程以對(duì)比單線程,不僅沒(méi)有優(yōu)勢(shì),顯然還由于要不斷的加鎖釋放GIL全局鎖,切換線程而耗費(fèi)大量時(shí)間,效率低下,而多進(jìn)程,由于是多個(gè)CPU同時(shí)進(jìn)行計(jì)算工作,相當(dāng)于十個(gè)人做一個(gè)人的作業(yè),顯然效率是成倍增長(zhǎng)的。
然后是IO密集型,IO密集型可以是磁盤IO,網(wǎng)絡(luò)IO,數(shù)據(jù)庫(kù)IO等,都屬于同一類,計(jì)算量很小,主要是IO等待時(shí)間的浪費(fèi)。通過(guò)觀察,可以發(fā)現(xiàn),我們磁盤IO,網(wǎng)絡(luò)IO的數(shù)據(jù),多線程對(duì)比單線程也沒(méi)體現(xiàn)出很大的優(yōu)勢(shì)來(lái)。這是由于我們程序的的IO任務(wù)不夠繁重,所以優(yōu)勢(shì)不夠明顯。
所以我還加了一個(gè)「模擬IO密集型」,用sleep來(lái)模擬IO等待時(shí)間,就是為了體現(xiàn)出多線程的優(yōu)勢(shì),也能讓大家更加直觀的理解多線程的工作過(guò)程。單線程需要每個(gè)線程都要sleep(2),10個(gè)線程就是20s,而多線程,在sleep(2)的時(shí)候,會(huì)切換到其他線程,使得10個(gè)線程同時(shí)sleep(2),最終10個(gè)線程也就只有2s.
可以得出以下幾點(diǎn)結(jié)論
單線程總是最慢的,多進(jìn)程總是最快的。
多線程適合在IO密集場(chǎng)景下使用,譬如爬蟲(chóng),網(wǎng)站開(kāi)發(fā)等
多進(jìn)程適合在對(duì)CPU計(jì)算運(yùn)算要求較高的場(chǎng)景下使用,譬如大數(shù)據(jù)分析,機(jī)器學(xué)習(xí)等
多進(jìn)程雖然總是最快的,但是不一定是最優(yōu)的選擇,因?yàn)樗枰狢PU資源支持下才能體現(xiàn)優(yōu)勢(shì)
審核編輯:符乾江
-
多線程
+關(guān)注
關(guān)注
0文章
278瀏覽量
20075 -
python
+關(guān)注
關(guān)注
56文章
4807瀏覽量
85039
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
socket 多線程編程實(shí)現(xiàn)方法
一文搞懂Linux進(jìn)程的睡眠和喚醒
Python中多線程和多進(jìn)程的區(qū)別
從多線程設(shè)計(jì)模式到對(duì) CompletableFuture 的應(yīng)用
一句話讓你理解線程和進(jìn)程

bootloader開(kāi)多線程做引導(dǎo)程序,跳app初始化后直接進(jìn)hardfualt,為什么?
鴻蒙APP開(kāi)發(fā):【ArkTS類庫(kù)多線程】TaskPool和Worker的對(duì)比(2)
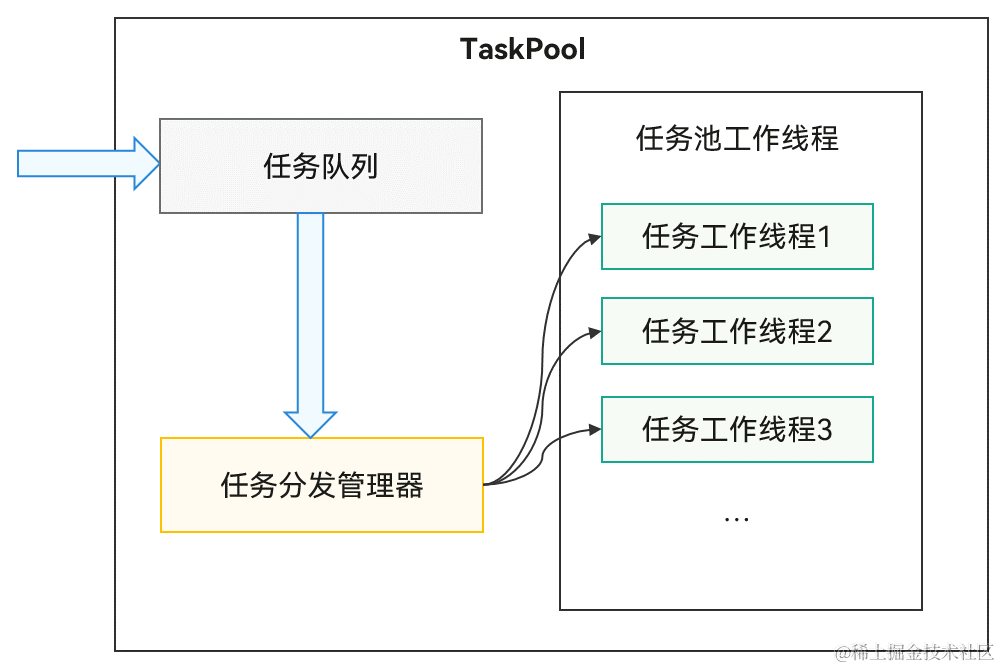
鴻蒙APP開(kāi)發(fā):【ArkTS類庫(kù)多線程】TaskPool和Worker的對(duì)比
鴻蒙原生應(yīng)用開(kāi)發(fā)-ArkTS語(yǔ)言基礎(chǔ)類庫(kù)多線程TaskPool和Worker的對(duì)比(一)
java實(shí)現(xiàn)多線程的幾種方式
python中5種線程鎖盤點(diǎn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論