 openGauss數據庫在可計算存儲CSD上探索
openGauss數據庫在可計算存儲CSD上探索
最近在可計算存儲 CSD 2000上使用 BenchmarkSQL 和 sysbench 測試了一下 openGauss 數據庫,主要觀察在大數據量下 openGauss 在 CSD 2000 上數據存儲空間和性能相比普通SSD 的變化。這里分享一些測試數據和原理的思考,供對openGauss 和可計算存儲 CSD 感興趣的朋友參考。
CSD 測試效果
測試場景簡介
測試場景選擇了數據庫廠商經常用的兩種標準場景。
§BenchmarkSQL TPC-C場景
TPC-C是衡量聯機事務處理(OLTP,OnlineTransaction Processing)系統的工業標準,是行業中公認的權威和最為復雜的在線事務處理基準測試。它通過模擬倉庫和訂單管理系統,測試廣泛的數據庫功能,包括查詢、更新和 mini-batch事務(隊列式小批量事務)。
TPC-C基準測試模擬訂單錄入與銷售環境,測量每分鐘商業事務(tpmC)吞吐量。TPC-C 測試數據集規模由倉庫數決定,本次測試指定10000倉。一共有9張業務表,最大的表數據量是倉庫數*300K ,這里有30億。
開源的 TPC-C 測試工具有 BenchmarkSQL 和 sysbench。這里選擇BenchmarkSQL,官方下載地址:https://sourceforge.net/projects/benchmarksql/ 。測試方法參考openGauss 官方文檔。
§sysbench OLTP 場景
sysbench 是一個開源的、模塊化的、跨平臺的多線程性能測試工具,可以用來進行CPU、內存、磁盤I/O、線程、數據庫的性能測試。目前支持的數據庫有 MySQL 、Oracle和Postgre SQL 。
sysbench oltp 基準測試指定場景腳本(lua文件),輸出相應的平均每秒事務數TPS、平均每秒請求數QPS、平均延時RT、99百分位延時等。sysbench 數據量是可以指定表的數量和每個表的數據量。本次測試指定100張表,每張表1億記錄。
sysbench 從開源網站github.com 下載,版本1.1.0 。
存儲空間壓縮效果
為了讓 SSD 讀寫能進入穩態,降低數據庫內存和操作系統內存對磁盤測試的影響,兩種測試場景的數據量都非常大。
§Benchmarksql TPC-C 場景:數據規模在 10000 倉庫,表的填充因子(FILLFACTOR)設置為 50,數據庫文件大小總計約 1882 GB,CSD 內部實際使用空間約 602 GB 。CSD 壓縮比為 3.12 (壓縮比=壓縮前物理空間 / 壓縮后物理空間)。
§sysbench 場景:100表,每表 1 億數據,表的填充因子設置為 100 ,數據庫文件大小總計為 2565 GB,CSD 內部實際使用空間約 810 GB 。CSD 壓縮比為 3.16 。
§sysbench 場景:100表,每表 1 億數據,表的填充因子設置為 75 ,數據庫文件大小總計為 3300 GB,CSD 內部實際使用空間約 874 GB 。CSD 壓縮比為 3.77 。
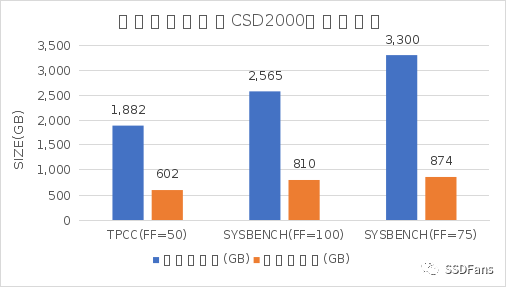
普通的 SSD 沒有透明壓縮能力,內部實際存儲空間也就等于上面“壓縮前大小”。CSD 2000 的透明壓縮能力顯著降低數據在 SSD 內部的物理存儲空間,極大的降低了 存儲介質NAND 消耗速度,降低 SDD GC 頻率,所以在 SSD 進入穩態后高并發讀寫時,性能也有明顯提升。
性能對比
兩種測試場景,在固定數據量的前提下,分別使用不同的客戶端并發數進行測試,每次測試時間在10分鐘。
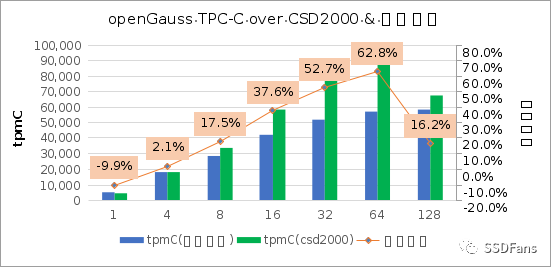
§TPC-C 性能,在 64 并發時提升幅度最大。
§SYSBENCH (FF=100)性能
注:FF,FILLFACTOR 的簡稱,填充因子,用于控制數據庫塊里 INSERT 的最大空間使用比例。
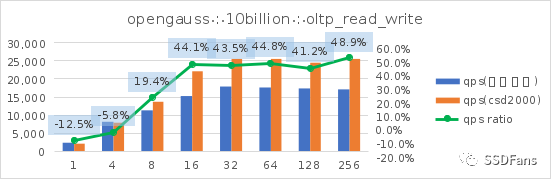
讀寫混合場景的每秒請求數QPS:
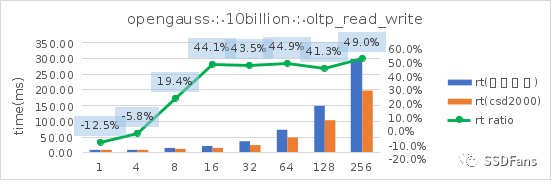
讀寫混合場景的平均延時 RT:
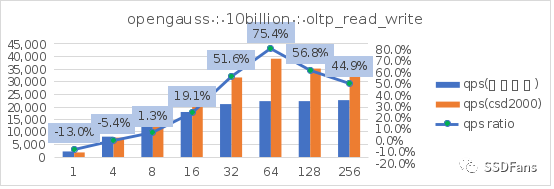
§SYSBENCH (FF=75)性能
讀寫混合場景的每秒請求數QPS:
讀寫混合場景的平均延時 RT:
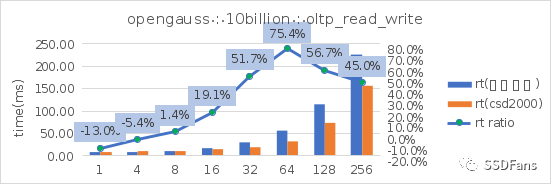
上面只是取了 TPCC 和 sysbench oltp 讀寫混合場景。更多場景的測試信息請查看文末鏈接。從上圖可以看出:
§sysbench 相同的數據量(100億),不同的填充因子(FILLFACTOR)從 100 降到 75 時,不管是在普通 SSD 還是 CSD 上,性能都會提升。在普通盤上的代價就是存儲空間的增長(從 2565G 漲到 3300G),但是在 CSD 上實際存儲空間的增長卻很小(從 810G 漲到 874G )。
§不管是 TPC-C 還是 sysbench 的讀寫混合場景,當并發超過 10 后,CSD 上的 QPS 或平均延時都會呈現優勢并且逐步擴大,直到到達一個拐點。
備注:這次性能測試場景數據量造的非常大(1.5T 以上),并且數據庫內存不是很大(80G),同時開啟了openGauss 的 full_page_writes ,沒有刻意對 openGauss 做深入優化。所以數據庫壓測的時候加在 SSD 上的讀寫壓力很大,整體呈現 IO Bound 特點。這是為了模擬這種情形,即客戶生產業務應用的數據庫并不一定總是很優化,在性能出現問題的時候可能存儲的讀寫壓力很大,SSD 往往成為性能瓶頸。所以這里測試的結果值跟數據庫單純的做性能測試取得的峰值會有一定差異。我們重點關注相同的數據量相同的數據庫軟硬件配置在不同的 SSD 上的性能差異。
openGauss存儲特性簡介
openGauss v2.1 的內核是 Postgres 9.2.4 。openGauss 的存儲引擎支持三種類型:
§行存儲引擎:面向 OLTP 場景設計。如訂單、物流、金融交易系統。
§列存儲引擎:面向 OLAP 場景設計。如數據統計分析報表。
§內存引擎:面向一些特殊場景對性能有極致要求。如銀行風控等。
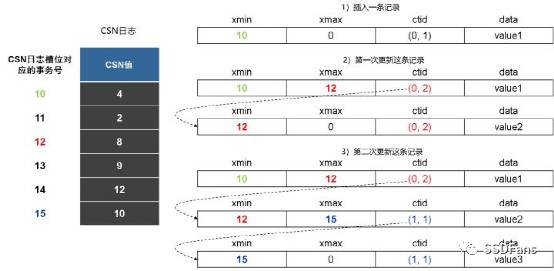
這里我主要測試的是行存儲引擎。行存儲引擎的特性很多,這里這聊它的數據存儲模型。openGauss 跟 PostgreSQL 一樣都是使用 B-Tree 模型。openGauss行存儲表支持多版本元組機制,即為同一條記錄保留多個歷史版本的物理元組,以應對同一條記錄的讀、寫并發沖突(讀事務和寫事務工作在不同版本的物理元組上)。這種設計叫 astore 元組多版本機制。
astore存儲格式為追加寫優化設計,其多版本元組產生和存儲方式如下圖所示。當一個更新操作將v0版本元組更新為v1版本元組之后,如果v0版本元組所在頁面仍然有空閑空間,則直接在該頁面內插入更新后的v1版本元組,并將v0版本的元組指針指向v1版本的元組指針。在這個過程中,新版本元組以追加寫的方式和被更新的老版本元組混合存放,這樣可以減少更新操作的I/O開銷。然而,需要指出的是,由于新、老版本元組是混合存放的,因此在清理老版本元組時需要的清理開銷會比較大。因此,astore存儲格式比較適合頻繁插入、少量更新的業務場景。
引用來源:《openGauss數據庫源碼解析系列文章——存儲引擎源碼解析(二)》
openGauss 表有個存儲參數填充因子(FILLFACTOR)可以指定每個頁里在插入數據時使用的最大空間比例。表默認是 100% ,索引默認是 90%。大量的 insert 可能會導致頁基本寫滿從而后期更新操作時就需要另外找新的頁存放新元組。適當的預留一些空間能提升表的更新(update 和 delete)性能。PostgreSQL 或者 openGauss 用戶可能不會過多降低這個參數值,因為這會導致表和索引的存儲空間增加。但是如果數據庫存儲是帶透明壓縮的可計算型存儲 CSD 時,這個空間擔心就是多余的。
可計算型存儲 CSD 簡介
常用壓縮方案
常用的數據壓縮方案有好幾種,業務根據自己需求和方案特點選擇。這里簡單介紹一下各種方案特點:
§應用(指數據庫)自己開啟壓縮,占用一定主機 CPU 資源,損失一些性能。損失多少取決于壓縮算法和數據庫工程實現能力。隨著數據量增長,性能損耗會加大,不具備線性擴展能力。CPU 壓縮也會導致 CPU Cache Miss 事件增多。簡單來說是犧牲CPU性能換存儲空間。
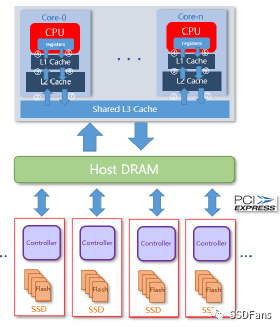
§使用 FPGA 加速卡壓縮。FPGA 卡自帶計算引擎,能減輕主機 CPU 負載,在不少場景里很適合。不過 FPGA 卡會占用一個 PCIe 插槽,且數據讀寫傳輸會占用內存資源。數據鏈路也變長。同樣受限于壓縮卡算力和帶寬,無法線性擴展。
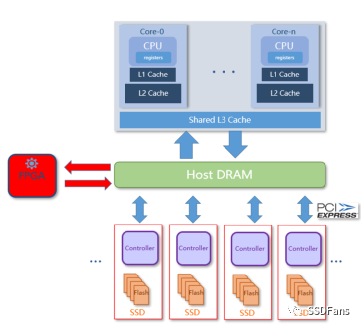
§CSD 透明壓縮。在 SSD 內部引入計算引擎,數據按常規方法寫入 SSD,然后盤內計算引擎對數據壓縮,寫入存儲物理介質(NAND)。透明壓縮,應用不需要修改。zero-copy技術,不需要額外數據傳輸。數據量增長時,可以增加多塊 CSD 盤實現壓縮能力線性擴展。
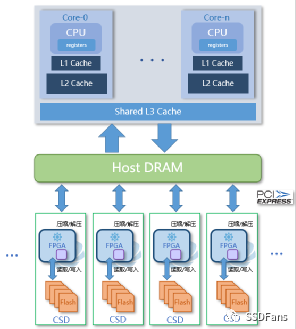
CSD 的透明壓縮做到應用完全不用修改就可以用。傳統的關系型數據庫(使用B-Tree數據模型,如 ORACLE/MySQL/SQL Server/PostgreSQL)可以直接部署在 CSD 上使用,通常業務數據壓縮比能在 2.0 以上。雖然這些數據庫自身也有壓縮方案,但考慮到性能,客戶核心應用在生產上不會開啟壓縮。一些 NewSQL 數據庫使用 LSM Tree 模型的,也自帶壓縮能力。如果數據庫強行開啟壓縮,那么數據文件在 CSD 上壓縮比還要根據實際情況看。這涉及到 CSD 壓縮的原理。
CSD 原理特性
§定長塊 IO
當給 SSD 盤做文件系統格式化時,默認塊大小是 4KB(這個也可以改,具體要看操作系統是否支持)。應用寫入數據時,每個 IO 里實際有效數據大小可能小于或等于 4KB,不足 4KB 時會用空(0x0)補齊。文件系統上層的應用(數據庫),為了減少 I/O 次數,數據庫的塊(或叫頁Page)大小通常都比 4KB 大。如 ORACLE 和 PostgreSQL 默認是 8KB ,MySQL 是 16KB ,openGauss 是 8KB 。數據庫軟件在管理數據存儲的時候,會有按塊大小補齊邏輯。此外,使用 B-Tree 模型管理數據的數據庫的塊通常有預留空間設計,以提升記錄更新的性能,減少數據塊或者索引塊不必要的頁分裂帶來的性能下降。這是用存儲空間換性能的做法。比如說 ORACLE 建表的 storage 參數的 PCTFREE,PostgreSQL 、openGauss的 storage 參數 FILLFACTOR 。預留空間的比例需要在空間和性能之間權衡。這個在以前是個難題,不過數據放在 CSD 上后就不是問題了。因為所有用于補齊的空數據、數據庫塊里的預留空間(空數據),在 CSD2000 內部都會被壓縮掉,沒有實際存儲成本。
§壓縮算法
當然,壓縮收益還有一部分來自于業務數據和壓縮算法自身。以 TPC-C 產生的10000倉的數據為例,如果全部導出為 csv 文件,在 CSD2000 上大小有 729 GB,實際占用物理空間為 457 GB,壓縮比約 1.59 。當將數據導入到 openGauss并設置 openGauss 表的 fillfactor 為 50 時,這份數據在 openGauss 的數據文件總計 1882 GB,該數據文件在 CSD 2000 上實際占用物理空間 602 GB,壓縮比約 3.13 。CSD 2000 內部使用的壓縮算法是 zlib (gzip)。
除了 gzip/zlib 還有些常見的壓縮算法,如 lz4、snappy、zstd 。每個壓縮算法還有不同的壓縮 level。就默認 level 而言,實際經驗是 lz4、snappy壓縮比較快,對 CPU 占用低,自然壓縮比也是很低。zstd、gzip 壓縮比較慢,對 CPU 占用高,壓縮比很高。CSD 的透明壓縮是靠 SSD 內部的計算引擎實現的(在 CSD 2000 內部是有一個 FPGA;在 CSD 3000 內部是 ARM 芯片),不占用主機 CPU 。下面表格是 sysbench 表導出 csv 文件后的壓縮比測試。
| 原始大小 | 壓縮算法 | 壓縮后大小 | 應用壓縮比 | CSD壓縮后大小 | CSD壓縮比 |
| 1.1GB | none | 1.1GB | none | 533 MB | 2.11 |
| 1.1GB | lz4-1.8.3 | 919 MB | 1.26 | 598 MB | 1.54 |
| 1.1GB | gzip-1.5 | 476 MB | 2.37 | ||
| 1.1GB | zstd-1.3.8 | 494 MB | 2.37 | 494 MB | 1.00 |
應用(指數據庫)如果開啟壓縮,除了要消耗一部分 CPU 資源外,還會帶來一個問題就是數據讀寫過程中的壓縮和解壓縮會降低 CPU cache 的命中率。此外,當一個 16K 的數據塊被壓縮后可能就不是 4KB 的整數了,在寫到文件系統里還是很可能有不少空數據,所以在數據庫壓縮后在 CSD 內部還可以繼續壓縮一部分(還有一個原因就是壓縮算法之間的差異)。
這次沒有對比測試 openGauss 數據庫的壓縮效果。根據其他數據庫的測試經驗。如果數據庫使用 lz4 壓縮,在 CSD2000 內部還會有 1.54 的壓縮比。有些數據庫使用 LSM Tree 模型,數據是分層壓縮的,不同層的壓縮算法還可以不一樣,這些數據在 CSD 內部的壓縮效果就取決于數據庫里使用用不同壓縮算法的數據占比了。
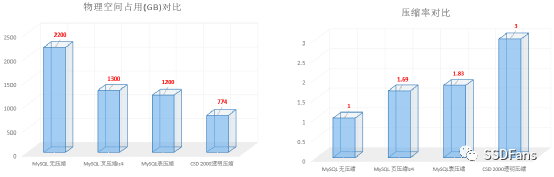
§壓縮比
CSD 2000 提供了命令可以直接看具體的文件的實際物理空間和壓縮比,以及整個 SSD 盤的實際物理空間和壓縮比。當業務數據是變化的時候,CSD 2000 上觀察到的壓縮比是浮動的,每個業務都不一樣。下圖是客戶的業務數據壓縮比經驗。
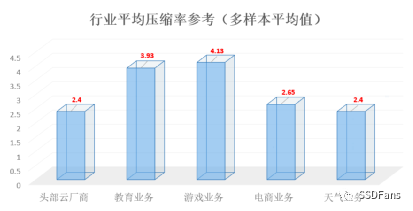
大部分數據庫的數據存儲是即時分配,這些數據庫的壓縮比觀察數據比較直接。少數數據庫有自己的空間管理策略。如 ORACLE數據庫有表空間概念,可以預分配(初始化)一定大小的數據文件。同時也可以后期文件自動擴展。以前在存儲資源很寶貴的時候, DBA 會習慣自己控制文件的增長。一點點用,像擠牙膏似的。預分配的空間里都是用空數據(0x0)初始化,對壓縮比的結果會有一定影響,影響的比例就取決于這部分數據占總大小的比例。然后表空間還有自己的空間管理(復用)策略,在表被刪除后,其對應的空間很有可能只是數據庫內部復用,并不會歸還給磁盤。盡管數據庫認為某一段空間是無效的,在 CSD 眼里,其原數據還是在的,壓縮比也是存在的。
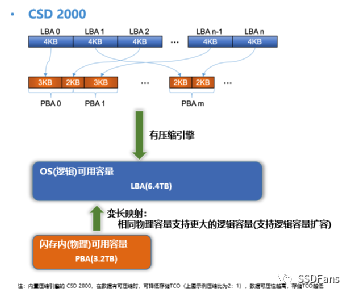
壓縮比浮動可能會讓人擔心。為了放心,運維可以監控 SSD 的可用物理空間。正如 ORACLE 數據庫管理員要監控磁盤可用空間,也要監控數據庫內部表空間的可用空間,使用 CSD 2000 還要監控 SSD 內部可用物理空間。CSD 2000 的透明壓縮沒有修改文件系統的接口,所以用戶在看數據文件大小看到的都是壓縮前的大小,也叫邏輯空間大小(其訪問地址對應為 LBA,Logical Block Address)。這點是CSD透明壓縮區別于文件系統(如zfs)壓縮方案。在 SSD 內部還有個物理空間地址 PBA (Physical Block Address)。
§OP 空間
對于普通的 HDD 而言,LBA 和 PBA 地址映射是 1:1 的。SSD 比 HDD 不一樣的地方是 SSD 內部有一定比例的保留空間對用戶是不可見的,又稱為 Over Provision 空間(簡稱 OP)。OP 空間的存在原因是 SSD 的寫是對閃存空的Page 進行編程(Program),每個 Page 只能編程一次(除非后期擦除再次變為空 Page了)。所以 SSD 可以寫入新的空 Page 但是不能修改老的 Page 。如果要改寫只能將老的 Page 數據復制到新的 Page,期間經過 SSD Cache 的時候在 Cache 里修改數據,然后寫入到新的 Page。這就需要 OP 空間來容納數據。所以 SSD 內 LBA 和 PBA 的映射不是 1:1 , PBA 的地址容量大于 LBA 的地址容量。當改寫數據時,原 LBA 會映射到新的 PBA,那么老的 PBA 在 SSD 內部就屬于“無主數據”或者“臟數據”。當 SSD 內沒有剩余的空 Page 用于寫時,SSD 就會回收“臟數據” 所在的 Page,這個操作叫 GC, “臟數據”所在 Page 變為空 Page 操作叫擦除(Erase)。由于 SSD 電路設計特點,擦除的單位是 BLOCK ,并且每個 BLOCK 被擦除的次數還有限。一個 BLOCK 大小現在可能有幾MB 或者幾十 MB(跟產品型號、容量有關)。所以為了擦除某幾個“臟數據” 所在的 BLOCK,需要先把該 BLOCK 上有效數據所在的 Page 遷移到空的 BLOCK 上。當剩余空 PAGE 比例很低觸發GC時,就是SSD進入穩態了。GC 操作并不會等空 Page全部寫完了才做,可能是定時做或者空閑期自動做,或者空余 Page比例不足某個值時做。當 GC 發生時,很多數據搬遷,會占用 SSD 內部 CPU 和 NAND 通道帶寬,所以對性能會有一定影響。這也就是普通 SSD 使用一段時間后寫性能會變慢的主要原因。當把數據搬遷的量也算作 SSD 存儲介質(NAND)的消耗時,相比業務寫入 SSD 的數據量,前者可能遠遠大于后者,這就是 SSD 的寫放大特點。
但在 CSD 產品,GC 的概率會非常低。由于內置透明壓縮能力,業務寫入 CSD 的數據量跟 CSD 內部 NAND 實際寫入量的比例是 N:1 的關系(N 就是數據壓縮比,N>1),也就是 CSD 產品的寫放大是小于 1 的。這是跟普通 SSD 最大的區別。這樣導致 CSD 內部實際有效 OP 空間遠大于產品標稱的能力(一般 SSD 的 OP 比例是 7% 或者 28%)。OP 空間越大,GC 自然越少。對于 QLC CSD 而言,這個特性能極大提升 SSD 壽命。
§CSD 容量擴容
不過有部分客戶業務數據壓縮比很高(大于3),業務數據量很大的時候(幾十甚至幾百TB 以上)這部分多出的 OP 空間就非常可觀,客戶希望能使用這部分 OP 空間。所以 CSD 2000 還有一個用法就是“擴容”。默認一個 4TB 的 CSD 2000 可以提供 3.2T 的空間。根據實際業務數據特點,可以對盤做一個初始化設置,允許提供 6.4 T 的空間(這是舉例)。具體來說就是提供 6.4 TB 的 LBA 地址容量。對業務來說,使用方法還是不變。將 CSD 2000 格式化文件系統后,就能看到盤有 6.4 T 的剩余空間。只要后期業務寫入的數據平均壓縮比高于 2:1, 那么這塊盤的容量和性能還是可能比普通的盤要好。
§原子寫
CSD 2000還有個特殊的能力,能在硬件層面提供 8K~256K 的 IO 原子寫能力。只要上層應用(數據庫)需要 4K 整數倍 IO的原子寫,可以完全交給 CSD 2000 來實現。前提是數據庫寫是 direct IO。
前面提到很多關系數據庫數據塊大小都是 4K 的倍數,在發生機器故障時,有可能出現數據塊寫到文件里部分成功部分失敗的情形下。即使數據庫開啟了 WAL(Write Ahead Logging)機制,也不一定能保證數據庫恢復后該數據塊也能正確恢復。在 MySQL 里,通過先同步順序寫一個共享表空間文件,然后再寫數據文件的方式來規避問題。在故障發生后如果發現數據塊校驗有問題,就直接用該共享表空間的內容覆蓋數據文件上的數據塊進行恢復。這個機制叫雙寫。在 PostgreSQL里使用的是在 Redo 日志里記錄數據塊完整的內容(通過參數 full_page_writes 控制)(傳統 WAL 日志記錄的是數據塊的變化內容)。openGauss 2.1版本兩種方案都支持(參數 enable_double_write 和 full_page_writes),默認使用的是雙寫方案。雙寫方案跟開啟增量檢查點一起使用(參數 enable_incremental_checkpoint )。
不管選哪個,這兩個原子寫方案都有一個特點,就是數據庫層面的寫放大,對性能的影響也是很明顯。openGauss 可以關閉這個機制,代價就是數據安全。由于 openGauss 不支持 direct IO,所以沒有辦法使用 CSD 2000 的原子寫能力。在 MySQL 數據庫上,我們成功驗證了關閉 MySQL 雙寫機制和使用 CSD 2000 的原子寫能力,sysbench 寫性能得到極大的提升(200%~350%)。
其他
openGauss 2. 1版本也提供了 IN-Place 更新機制,名為 Ustore 存儲引擎。應該還在試用狀態,具體使用效果還待官方客戶案例分享。這里沒有測試,Ustore 跟 ORACLE、MySQL的更新模型一致了,對使用CSD后壓縮和性能提升影響應該不會太大。
審核編輯 :李倩
-
操作系統
+關注
關注
37文章
6896瀏覽量
123755 -
數據庫
+關注
關注
7文章
3848瀏覽量
64689 -
CSD
+關注
關注
0文章
56瀏覽量
12720
原文標題:openGauss數據庫在可計算存儲 CSD上探索
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
分布式云化數據庫有哪些類型
矚目!海量數據再獲2024年度openGauss社區突出貢獻單位

軟通動力榮膺“openGauss社區突出貢獻單位”
企業上云后還需要數據庫運維嗎?真實答案看過來!
數據庫數據恢復—通過拼接數據庫碎片恢復SQLserver數據庫

云數據庫可以租用嗎?完整租用流程來了
數據庫數據恢復—SQL Server數據庫出現823錯誤的數據恢復案例

一文詳解企業上云數據庫是干嘛的

數據庫數據恢復—SQL Server數據庫所在分區空間不足報錯的數據恢復案例
中軟國際亮相openGauss Developer Day 2024
數據庫數據恢復—raid5陣列上層Sql Server數據庫數據恢復案例






 工商網監
工商網監
評論