 用Megatron-CNTRL為語言模型添加外部知識和可控性
用Megatron-CNTRL為語言模型添加外部知識和可控性
大型語言模型,如 Megatron 和 GPT-3 正在改變人工智能。我們對能夠利用這些模型來創建更好的對話式人工智能的應用程序感到興奮。生成語言模型在會話式人工智能應用中存在的一個主要問題是缺乏可控制性和與真實世界事實的一致性。在這項工作中,我們試圖通過使我們的大型語言模型既可控又與外部知識庫保持一致來解決這個問題。縮放語言模型提供了更高的流暢性、可控性和一致性。
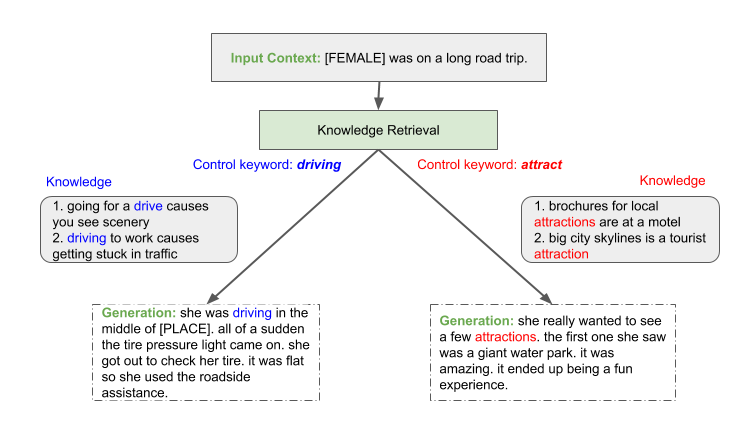
圖 1 。故事是由外部知識庫中的模型進行調節而產生的,并由不同的關鍵詞如“駕駛”和“吸引”控制。
為了緩解一致性和可控性問題,已經做了幾次嘗試。 Guan et al.( 2020 年) 通過微調引入常識知識來解決一致性問題。然而,這種天真的方法缺乏可解釋性和靈活性,無法決定何時以及從外部知識庫中合并什么。
控制文本生成 的許多功能都是可取的。最近,人們開發了不同的方法來控制生成,例如 使用預先添加到模型輸入的控制代碼 和 以目標演員之前的談話為條件 。然而,這些控制條件是預先定義好的,并且其能力有限。它們缺乏控制粒度,比如在句子或子文檔級別。
我們通過允許在預先訓練的語言模型中動態地結合外部知識以及控制文本生成來解決這些缺點。我們利用了我們的 Megatron 項目 ,它的目標是在 GPU 集群上以光效的速度訓練最大的 transformer 語言模型。我們提出了一個新的生成框架,威震天 CNTRL ,它使得我們的大型威震天語言模型既可以控制,又可以使用外部知識庫保持一致。
通過 土耳其機器人 使用人類求值器,我們展示了縮放語言模型提供了更高的流暢性、可控性和一致性,從而產生更真實的生成。結果,高達 91 . 5% 的生成故事被新關鍵字成功控制,并且高達 93 . 0% 的故事在 ROC 故事數據集 上被評估為一致。我們預計這一趨勢將繼續下去,從而激勵人們繼續投資于為對話型人工智能培訓更大的模型。圖 1 顯示了生成過程的一個示例。
Megatron 控制框架
在問題設置中,我們用第一句話作為輸入來完成一個故事。我們使用外部知識庫來擴充生成過程,并開發出一種能夠指導和控制故事生成的方法。圖 2 顯示了框架由以下連接步驟組成:
在給定故事背景的情況下,關鍵詞預測模型首先預測下一個句子的關鍵詞集合。
然后,知識檢索器獲取生成的關鍵字并查詢外部知識庫,其中每個知識三元組使用模板轉換為自然語言“知識句子”。
一個語境知識 ranker 然后根據外部知識句與故事上下文的關聯程度對它們進行排序。
最后,一個生成器將故事語境以及排名第一的知識句作為輸入,生成故事中的下一句。輸出句子附加到故事上下文中,重復步驟 1-4 。
這個公式自然地允許通過用手動外部關鍵字代替關鍵字生成過程來控制。
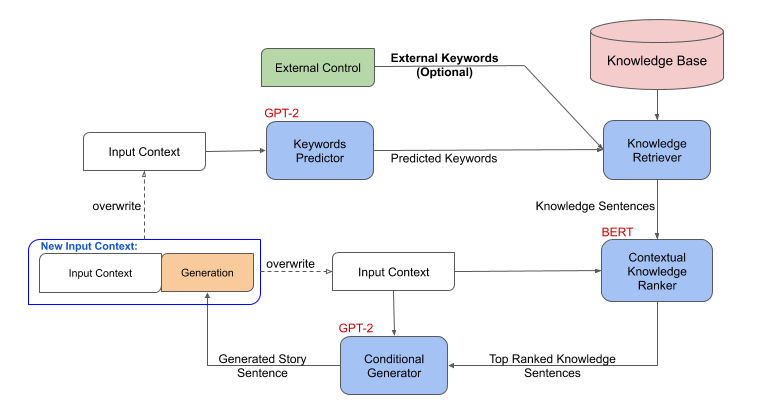
圖 2 。威震天控制:生成框架概述。
我們將關鍵詞生成建模為一個序列到序列的問題,它以故事上下文為輸入,輸出一系列關鍵字。我們使用 Megatron 模型(基于 GPT-2 )來生成關鍵字。知識檢索器是一個簡單的模型,它將關鍵字與知識庫相匹配。對于上下文知識 ranker ,我們首先構建偽標簽,通過嵌入一個名為 使用 的句子來找到與故事上下文最相關的知識。然后我們訓練一個來自 Megatron 模型的 ranker (基于 BERT ),對由知識檢索器過濾的知識進行排序。然后,排名靠前的知識被附加到故事上下文的末尾,作為來自 Megatron 模型的另一個條件生成器的輸入,以生成下一個故事句子。
實驗裝置
我們使用 ROC 故事數據集進行實驗。它由 98161 個故事組成,每個故事都包含五句話。按照 Guan et al.( 2020 年) ,對于每個句子,通過用特殊占位符替換故事中的所有名稱和實體來執行去毒性。在每個故事的第一句話中,我們的模型的任務是生成故事的其余部分,對于外部知識庫,我們使用了由 600k 知識三倍組成的 概念網 。我們分別用 Megatron 對預雨前的 BERT 和 GPT-2 模型進行上下文知識 ranker 和生成模型的初始化。關鍵字預測器和條件句生成器都遵循相同的設置。
質量評價
我們用自動的困惑、故事重復和 4 克的標準來評價生成的故事的質量,以及人類對連貫性、連貫性和流利性的評價。將 Megatron-CNTRL-124M 模型與表 1 和圖 3 中的 Yao et al.( 2018 年) 進行比較,我們獲得了更高的 4 克、一致性、流利性和一致性分數,這表明了大型預處理變壓器模型的好處。將 Megatron-CNTRL-124M 與 Guan et al.( 2020 年) (不可控)進行比較,該模型還使用了表 1 所示的基于 GPT-2 的模型,我們注意到,我們的模型具有明顯的更好的一致性(+ 7 . 0% )和一致性(+ 7 . 5% )。我們將這歸因于檢索到的知識的使用。通過明確提供與下一句相關的事實,條件生成模型可以集中于生成文本。
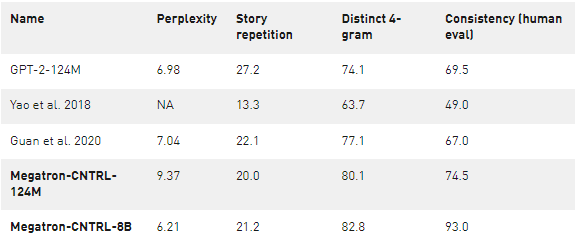
表 1 。評估了以前最先進的模型以及我們的算法在不同的大小。困惑,故事重復,和不同的 4-gram 被自動評估。
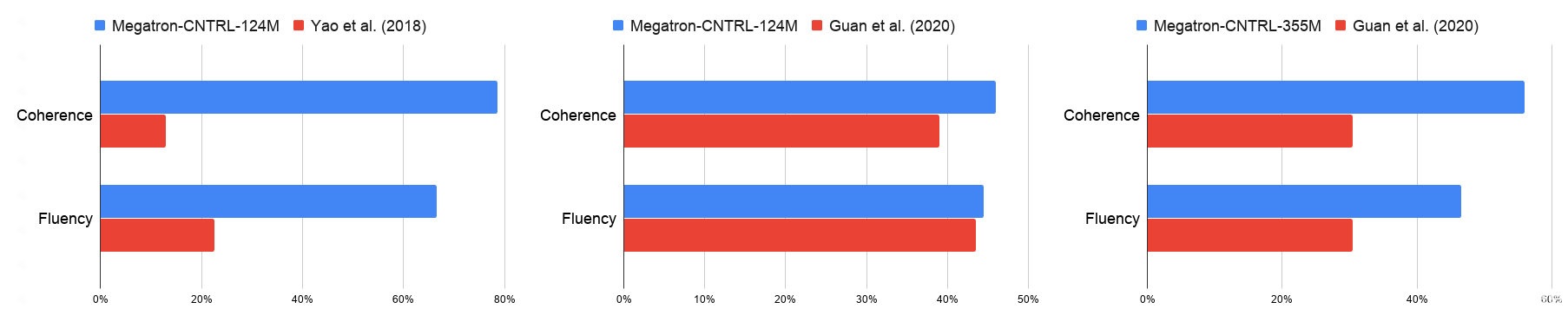
圖 3 。我們的模型和基線之間成對比較的人類評估。
當模型尺寸從 124M 增加到 355M 、 774M 、 2B 和 8B 時,我們觀察到在困惑、清晰、一致性、連貫性和流暢性方面的一致性改善,這表明進一步縮小模型尺寸幾乎總能提高生成質量。為了保持一致性,我們在 8B 參數下的最佳模型達到了 93% 的分數,這意味著 93% 的生成故事被注釋為邏輯一致。
可控性評價
我們首先將關鍵字改為反義詞,然后詢問注釋者生成的故事是否根據新的關鍵字而變化,以此來評估模型的可控性。表 2 中的結果表明,從Megatron-CNTRL-124M-ANT (它是通過將關鍵字改為反義詞的受控版本)生成的 77 . 5% 是由新關鍵字控制的。將發電模型從 124M 擴展到 8B ,我們觀察到可控性得分提高到 91 . 5% ,這表明大型模型對可控性有顯著的幫助。

表 2 。通過將關鍵字改為反義詞,人類對可控性的評價。
可控世代樣本
在下面的例子中,我們展示了Megatron-CNTRL 的能力。我們展示了在不同的發電粒度水平下的可控性。給出一個句子,Megatron-CNTRL 提出控制關鍵字。用戶可以使用它們,也可以提供他們選擇的外部控件關鍵字。這個過程一直持續到整個故事生成的結尾。
例 1:我們提供句子“[FEMALE]在一次公路旅行中”和一開始的控制關鍵字“ driving ”。根據這個輸入 Megatron 控制產生“她在路上開車”的條件是“開車”。然后,該模型預測下兩步的新關鍵詞“突然”和“拉動,檢查”,并生成相應的故事句。在生成最后一個句子之前,我們再次提供外部控制關鍵字“ help ”。我們觀察到,生成的句子“它吸煙嚴重,需要幫助”跟在控制關鍵字后面。
視頻 1 。使用“ driving ”關鍵字生成的故事。
例 2:我們給出與示例 1 相同的輸入語句:“[FEMALE]在一次公路旅行中”,但是在開始時使用了不同的控制關鍵字“ excited ”。因此,Megatron-CNTRL 基于“激動”產生了一個新的故事句子:“她興奮是因為她終于見到了(女性)”。在生成完整的故事之后,我們看到這個新的例子展示了一個關于一只巨大黑熊的可怕故事。由于外部情緒控制關鍵字引入的情感體驗,它比示例 1 中的更具吸引力。
視頻 2 。用“激動”關鍵字生成的故事。
結論
我們的工作證明了將大型的、經過訓練的模型與外部知識庫相結合的好處以及生成過程的可控性。我們未來的工作將是使知識檢索器可學習,并為更長的世代引入結構級控制。
例 2 :我們給出與示例 1 相同的輸入語句:“[FEMALE]在一次公路旅行中”,但是在開始時使用了不同的控制關鍵字“ excited ”。因此,Megatron-CNTRL 基于“激動”產生了一個新的故事句子:“她興奮是因為她終于見到了(女性)”。在生成完整的故事之后,我們看到這個新的例子展示了一個關于一只巨大黑熊的可怕故事。由于外部情緒控制關鍵字引入的情感體驗,它比示例 1 中的更具吸引力。
結論
我們的工作證明了將大型的、經過訓練的模型與外部知識庫相結合的好處以及生成過程的可控性。我們未來的工作將是使知識檢索器可學習,并為更長的世代引入結構級控制。
關于作者
Peng Xu是香港科技大學的候選人。他的研究重點是情感計算和自然語言生成。通過構建能夠理解人類情感的系統,他旨在實現更好的人機交互,并將更多自然世代的界限從機器上推出來。他在中國科學技術大學獲得電子工程和信息科學學士學位。
Mostofa Patwary 是 NVIDIA 應用深度學習研究團隊的高級深度學習研究科學家。 Mostofa 的研究興趣遍及自然語言處理、可擴展深度學習、高性能計算和算法工程等領域。在加入 NVIDIA 之前, Mostofa 在百度硅谷人工智能實驗室( Silicon Valley AI Lab )致力于擴展大型語言模型和擴展深度學習應用程序的可預測性。 Mostofa 還為能夠在超級計算機上運行的機器學習中的幾個核心內核開發大規模代碼做出了重大貢獻。
Mohammad Shoeybi 是一位高級研究科學家,在 NVIDIA 管理應用深度學習研究小組的 NLP 團隊。他的團隊專注于語言建模, NLP 應用,如問答和對話系統,以及大規模培訓。他獲得了博士學位。 2010 年從斯坦福大學畢業。在 NVIDIA 之前,他曾在 DeepMind 和美國百度工作,致力于將深度學習和強化學習應用到應用程序中。
Raul Puri 是 OpenAI 的研究科學家。勞爾在加州大學伯克利分校獲得電子工程和計算機科學學士學位,重點研究生物醫學工程。
Pascale Fung 是香港香港科技大學計算機科學與工程系的 ELE 〔 ZDK0 〕電子與計算機工程系教授。馮教授獲哥倫比亞大學計算機科學博士學位。她曾在 at & T 貝爾實驗室、 BBN 系統與技術公司、 LIMSI 、 CNRS 、日本京都大學信息科學系和法國巴黎中央經濟學院工作和學習。馮教授能流利地講七種歐洲和亞洲語言,他對多語種演講和自然語言問題特別感興趣。
Anima Anandkumar 在學術界和工業界擁有雙重地位。她是加州理工學院 CMS 系的布倫教授和 NVIDIA 的機器學習研究主任。在 NVIDIA ,她領導著開發下一代人工智能算法的研究小組。在加州理工學院,她是 Dolcit 的聯合主任,與 Yisong Yue 共同領導 AI4science initiative 。
Bryan Catanzaro 是 NVIDIA 應用深度學習研究的副總裁,他領導一個團隊尋找使用人工智能的新方法來改善項目,從語言理解到計算機圖形和芯片設計。布萊恩在 NVIDIA 的研究導致了 cuDNN 的誕生,最近,他幫助領導了發明 dlss2 。 0 的團隊。在 NVIDIA 之前,他曾在百度創建下一代系統,用于培訓和部署端到端、基于深度學習的語音識別。布萊恩在加州大學伯克利分校獲得了電子工程和計算機科學博士學位
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5076瀏覽量
103720 -
深度學習
+關注
關注
73文章
5513瀏覽量
121550
發布評論請先 登錄
相關推薦
【實操文檔】在智能硬件的大模型語音交互流程中接入RAG知識庫
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
【《大語言模型應用指南》閱讀體驗】+ 基礎篇
如何向Buildroot內添加外部APP

【《大語言模型應用指南》閱讀體驗】+ 俯瞰全書
大語言模型的預訓練
大語言模型:原理與工程時間+小白初識大語言模型
【大語言模型:原理與工程實踐】大語言模型的評測
【大語言模型:原理與工程實踐】大語言模型的預訓練
【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》2.0
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
基于NVIDIA Megatron Core的MOE LLM實現和訓練優化






 工商網監
工商網監
評論