 ZYNQ:使用PL將任務從PS加載到PL端
ZYNQ:使用PL將任務從PS加載到PL端
之前的幾篇文章主要集中在 Zynq SoC 的處理系統 (PS) 方面,包括:
然而,從設計角度來看,Zynq SoC 真正令人興奮的方面是創建一個使用 Zynq 可編程邏輯 (PL) 的應用程序。使用 PL 將任務從 PS 加載到 PL 端,為其他任務回收處理器帶寬從而加速任務。此外,PS 端可以控制 PL 端在經典的片上系統應用中執行的操作。使用 Zynq SoC 的 PL 端可以提高系統性能、降低功耗并為實時事件提供可預測的延遲。
簡介
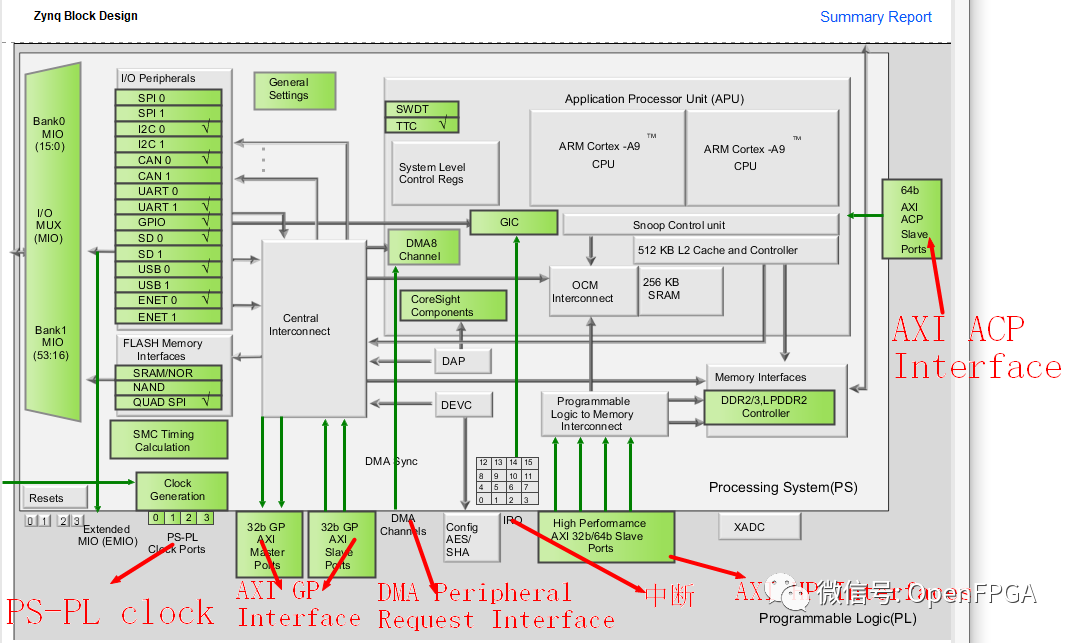
Zynq PS 和 PL 通過以下接口互連:
- 兩個 32 位主 AXI 端口(PS 主)
- 兩個 32 位從 AXI 端口(PL 主)
- 四個 32/64 位從機高性能端口(PL 主機)
- 1 個 64 位從加速器一致性端口 (ACP)(PL 主控)
- 從 PS 到 PL 的四個時鐘
- PS 到 PL 中斷
- PL 到 PS 中斷
- DMA 外設請求接口
以下是說明這些不同接口點的框圖:
ARM 的 AXI 是一種面向突發的協議,旨在提供高帶寬同時提供低延遲。每個 AXI 端口都包含獨立的讀寫通道。要求不高的接口使用的 AXI 協議的一個版本是 AXI4-Lite,它是一種更簡單的協議,可用于寄存器式控制/狀態接口。例如,Zynq XADC 使用 AXI4-Lite 接口連接到 Zynq PS。有關 AXI 協議的更多信息,請訪問:
http://www.arm.com/products/system-ip/amba/amba-open-specifications.php
Zynq SoC 支持三種不同的 AXI 傳輸類型,可以使用它們來連接PS到設備的PL端:
- AXI4 Burst transfers
- AXI4-Lite for simple control interfaces
- AXI4-Streaming for unidirectional data transfers
下表定義了每個接口的理論帶寬:

必須使用 Zynq SoC 的 DMA 控制器才能達到上表中列出的最大速度。作為一個額外的好處,當 PS 是主機時,DMA 控制器減少了 Zynq SoC 的 ARM Cortex-A9 MPCore 處理器的負載。在不使用 DMA 控制器的情況下,從 PS 到 PL 端的最大傳輸速率為 25Mbytes/sec。
總而言之,在 PS 和 PL 之間使用了驚人的 14.4Gbytes/sec(115.2Gbits/sec)的理論帶寬!
創建AXI外設
這一節將使用 AXI 接口在 Zynq SoC 的可編程邏輯結構中創建外設。
第一步
第一步是打開 Vivado 設計并從工具選項下選擇“創建和封裝 IP”選項-create and package IP。
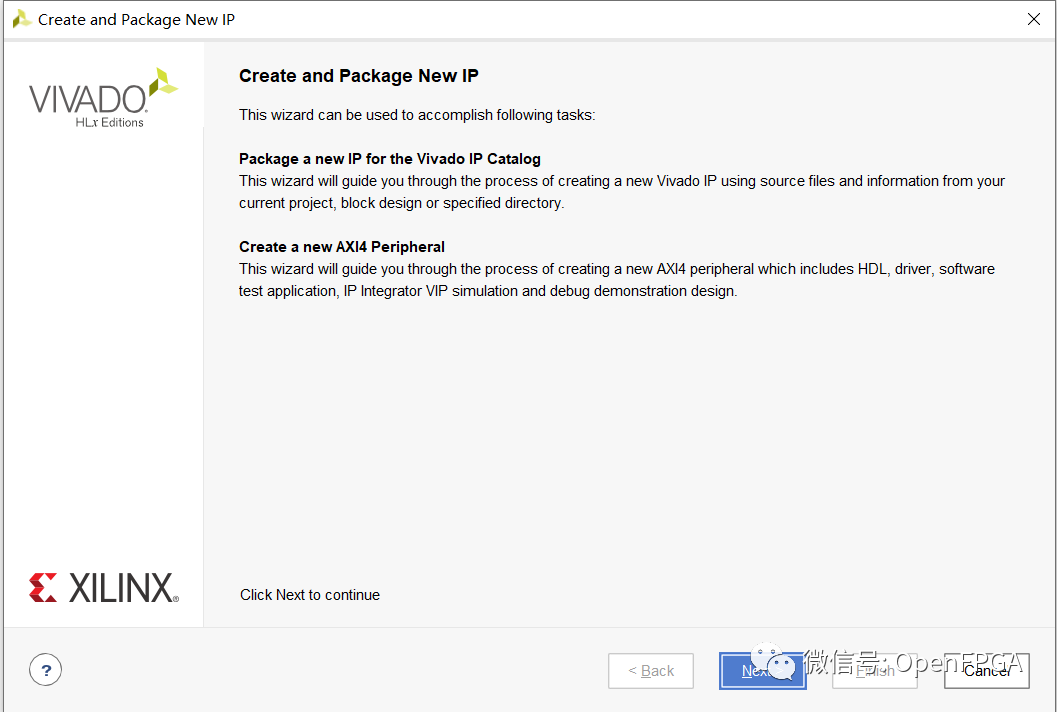
這將打開一個對話框,允許創建 AXI4 外設。對話框的第一個實際頁面提供了許多選項,用于創建新 IP 或將當前設計或目錄轉換為 IP 模塊。
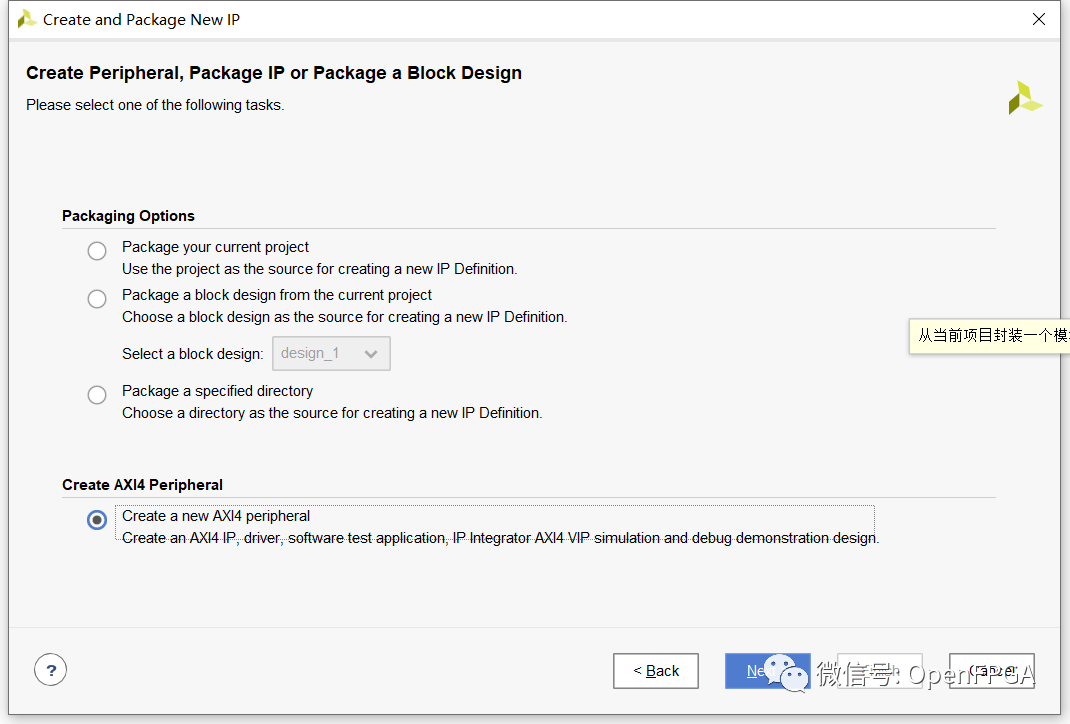
選擇“創建新的 AXI4 外設 - Create new AXI4 peripheral”選項并將其指向預定義的 IP 位置。可以使用 Vivado 主頁上的管理 IP 部分創建新的 IP 位置。

然后,該對話框允許輸入要用于新外圍設備的庫、名稱、描述和公司 URL。對于這個非常簡單的示例(稍后我將對其進行擴展)。
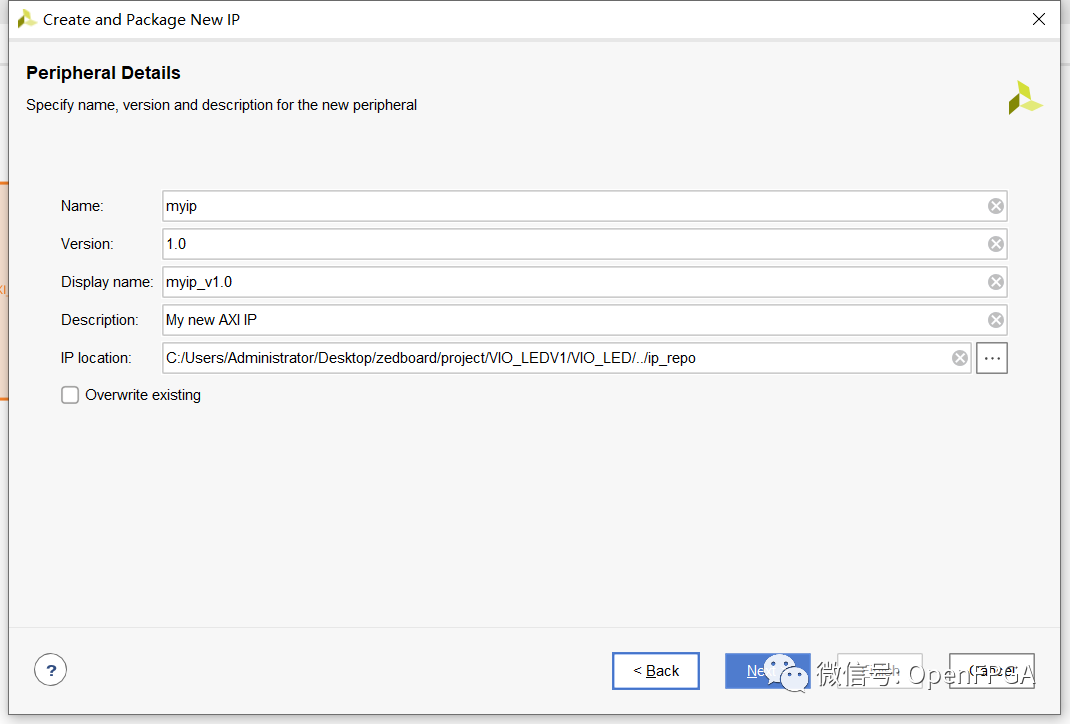
下面的對話框是一個功能強大的對話框,我們可以在其中定義我們希望指定的 AXI4 接口類型:
- 主或從
- 接口類型 – Lite、Streaming 或 Burst
- 總線寬度 32 或 64 位
- 內存大小
- 寄存器數量
這個初始示例非常簡單,以便我可以演示創建外設所需的流程,在 Vivado 中實現它,然后將其導出到 SDK。出于這個原因,我將只有四個寄存器的 AXI4-L ite 接口,然后我們可以使用軟件對其進行尋址。這些寄存器可用于控制設計的可編程邏輯方面的功能操作。
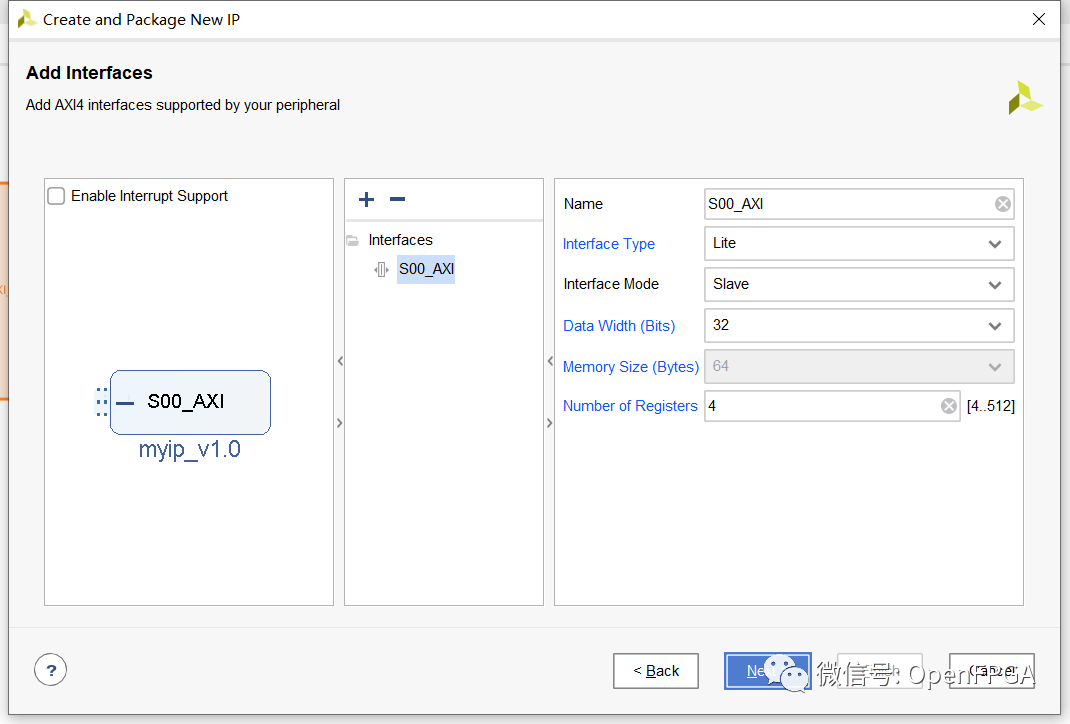
最后的“創建外圍設備-create peripheral”對話框允許選擇一個選項來為新外圍設備生成驅動程序文件。這是一個重要的步驟,因為它將使外設與 SDK 的使用更加簡單。
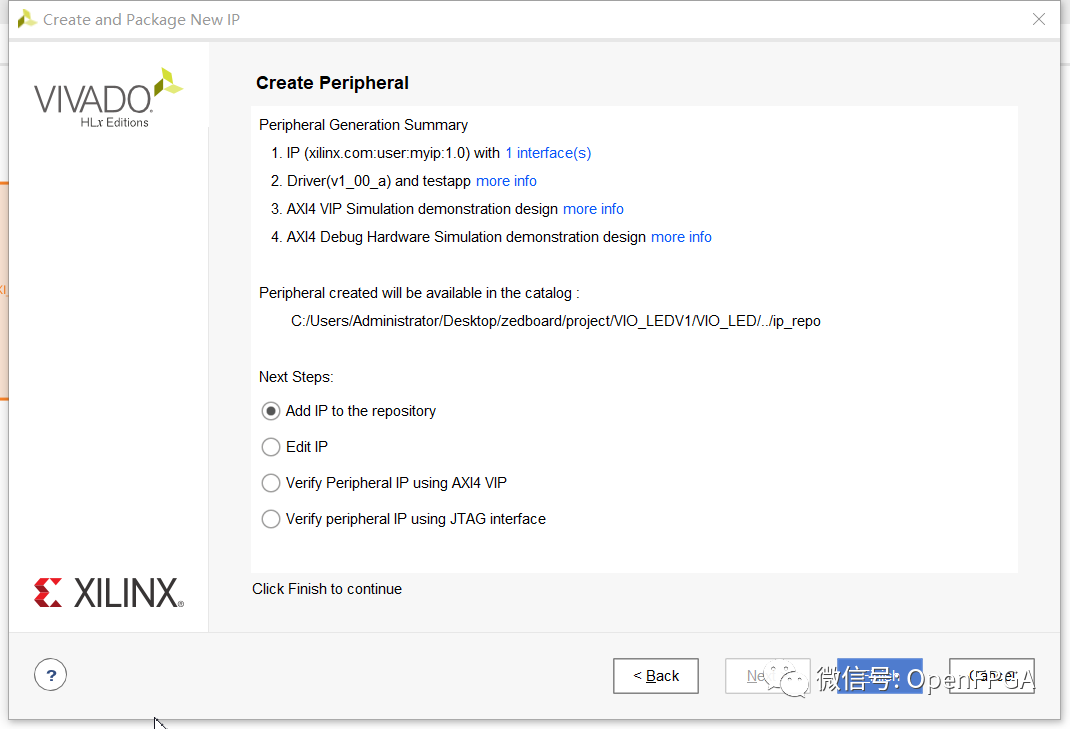
一旦“Create Peripheral”向導關閉,可以打開創建的 VHDL 文件并添加自定義硬件設計以在 PL 中執行想要的功能。我將只使用我們創建的四個寄存器,因此可以不編輯文件。創建了外圍設備后,我們希望在 Vivado 設計中連接和使用它。這樣做非常簡單。我們打開系統框圖并從左側菜單中選擇添加 IP 選項。應該能夠找到在此菜單中創建的外圍設備。可用外圍設備按字母順序列出。
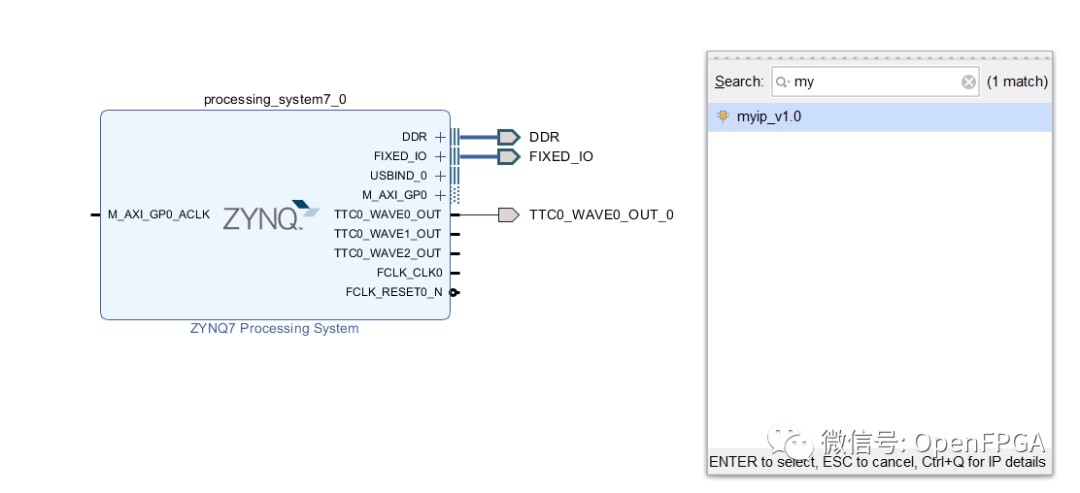
第二步
將此 IP 模塊拖入設計中,然后將其連接到 AXI GP 總線,其中 Vivado 提供運行連接自動化工具。
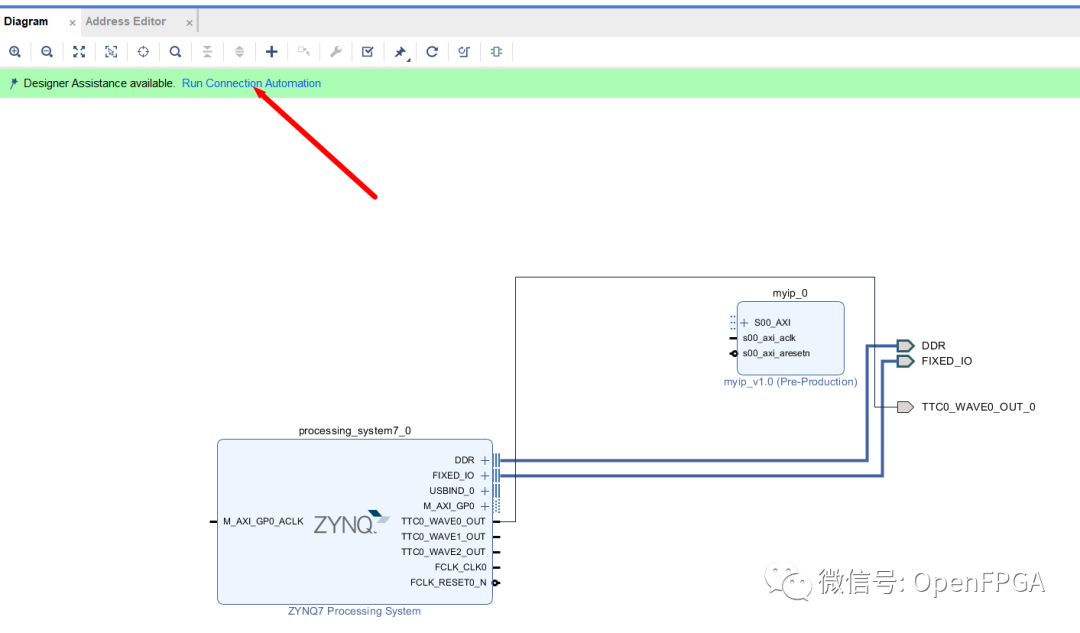
運行該工具會產生我們可以實施的設計。
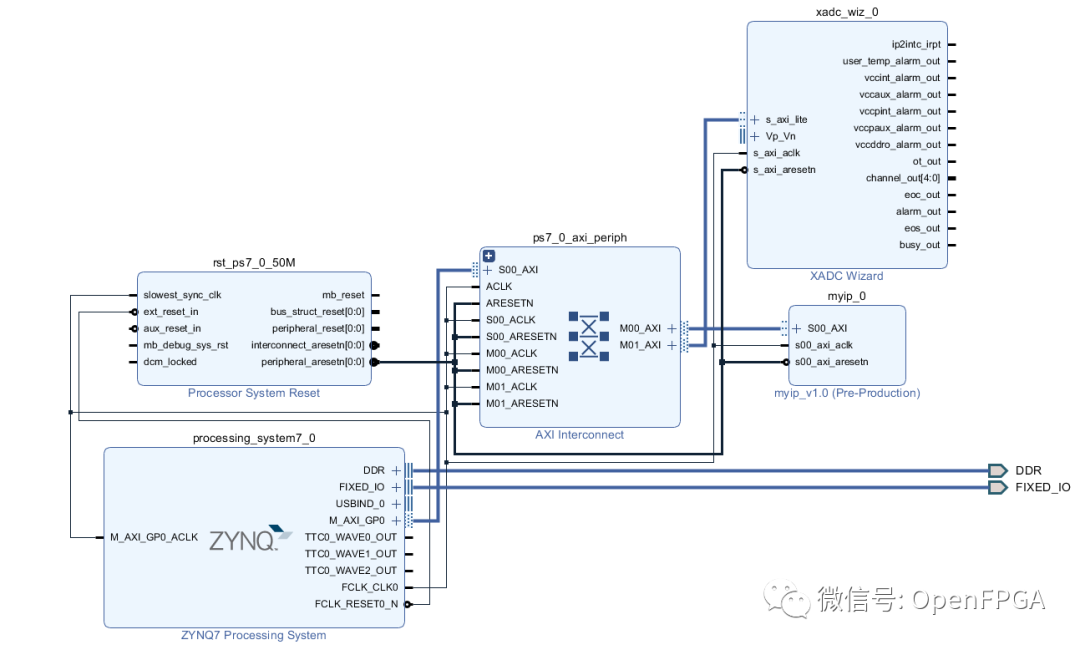
可以通過單擊地址編輯器選項卡來修改外設的地址范圍。請注意,4k 地址空間是允許的最小地址空間,這對于我們的 4 寄存器示例來說過于慷慨了。幸運的是,Zynq SoC 中的 ARM Cortex-A9 MPCore 處理器擁有大量的地址空間。
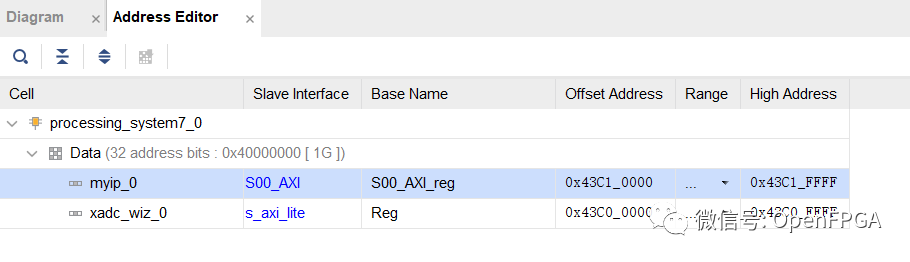
一旦 Vivado 自動完成連接及地址空間分配完畢,如下圖所示,我們就可以實現設計并將其導出到 SDK。然后我們就可以開始使用我們的外圍設備了。
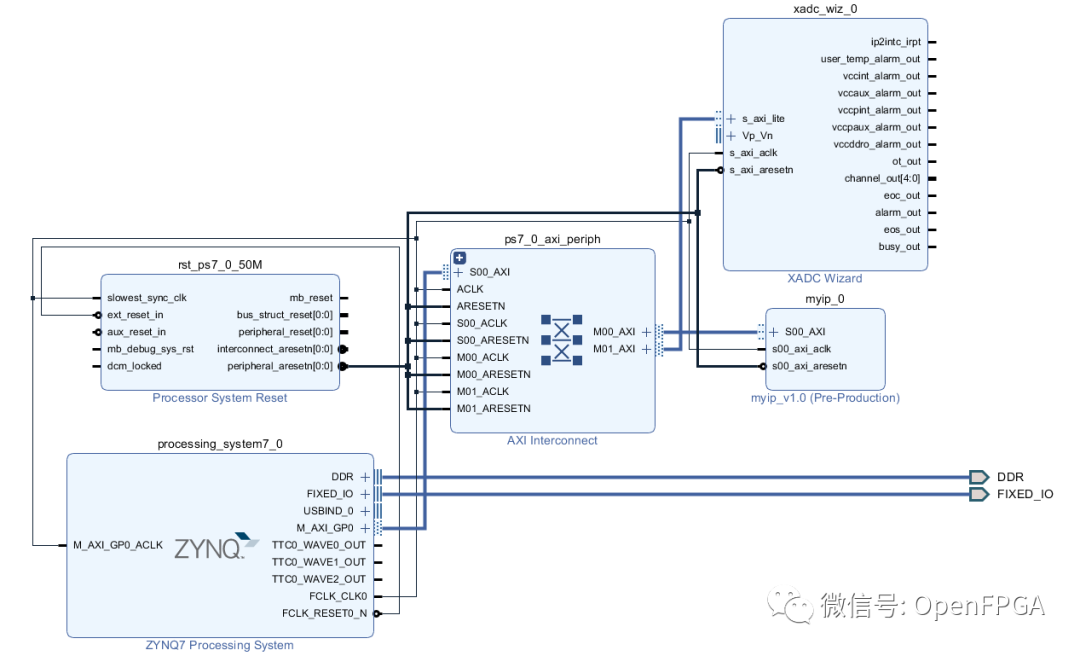
注意,可以檢查實施報告以確保包含已創建的外圍設備。
驗證
上面我們已經產生了一個AXI外設,接下來就是在SDK中驗證這個外設的正確性。
使用 Vivado 創建 AXI4 外設并生成BIN文件。
創建了設計的硬件組件后,我們現在需要將其導出到我們的 SDK 設計中,以便我們可以編寫軟件來驅動它。第一步是在 Vivado 中打開當前工程,編譯生成BIN文件,然后將硬件導出到 SDK。(如果嘗試導出硬件時,SDK 已在使用中,則會收到警告。)如果不將硬件導出到 SDK,則下次打開 SDK 時,需要將硬件定義和板級支持包更新,否則將無法使用它們。還需要更新設計中定義的存儲庫,以包括包含外圍設備的 IP 存儲庫。
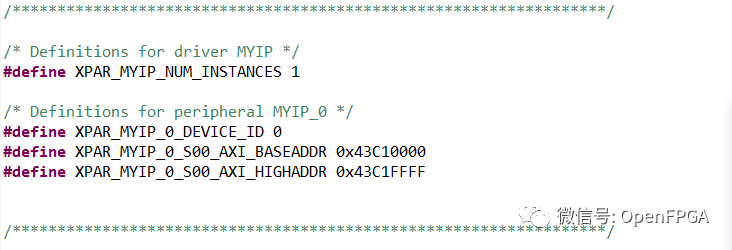
打開 xparameters.h 文件(在 BSP 包含文件中)以查看專用于新 AXI4 外設的地址空間:
下一步是打開 System.MSS 文件并自定義要使用的 BSP在外設創建過程中生成的驅動程序而不是通用驅動程序。
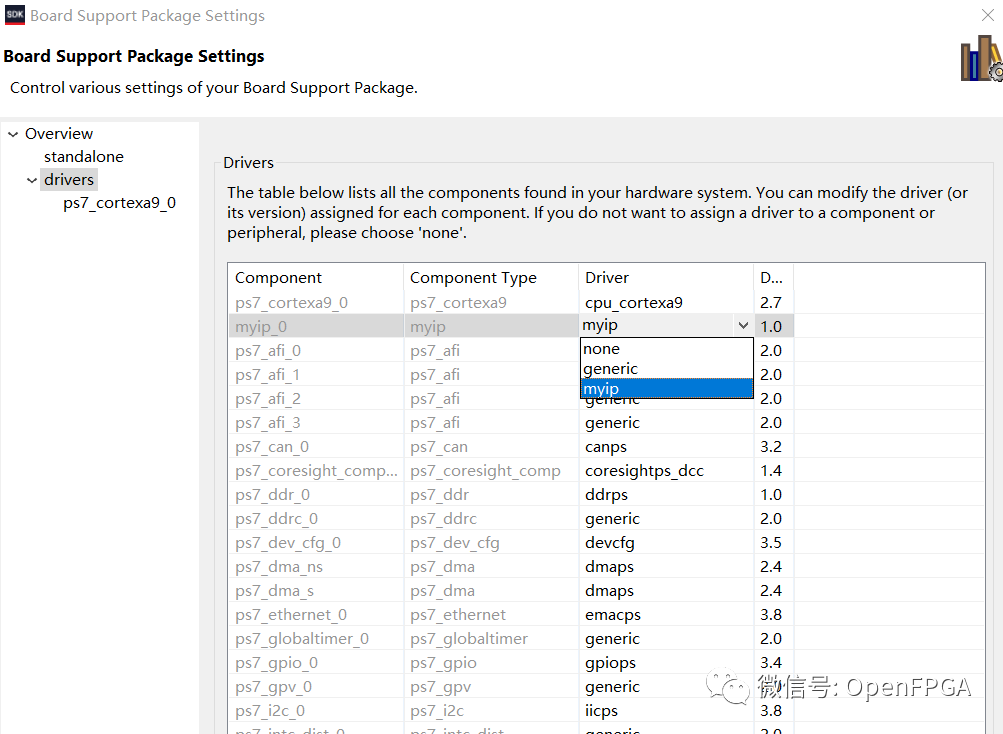
重新構建項目可確保將驅動程序文件加載到 BSP 中。這是一個非常有用的步驟,因為這些文件還包含一個簡單的自檢程序,可以使用該程序來測試外設的軟件接口是否正確,然后再開始使用它進行更高級的操作。使用此測試程序還表明我們已在 Vivado 中正確實例化了硬件。
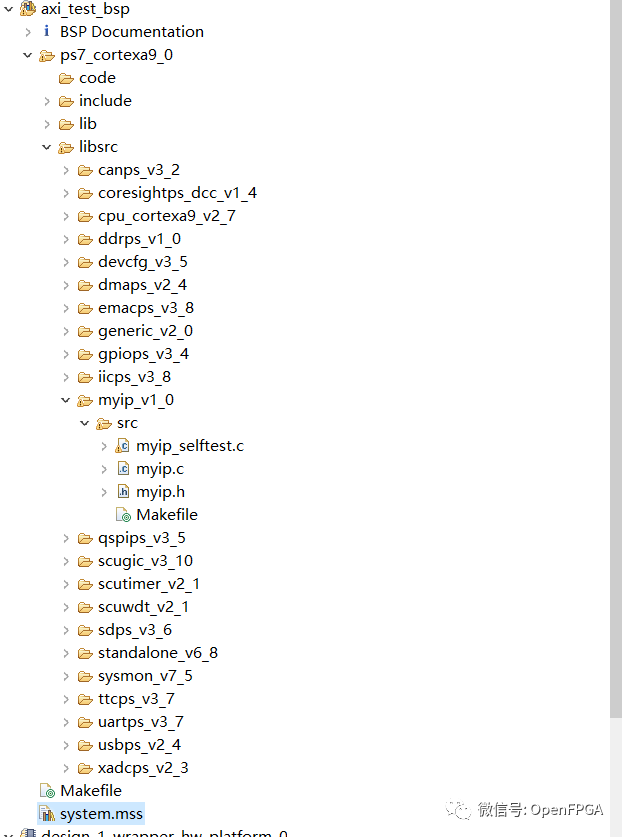
在 BSP 下 libsrc 中,將看到許多新 AXI4 外設的文件。這些文件允許像使用原生外圍設備(例如 XADC 和 GPIO)一樣讀取和寫入外圍設備,我們之前在其他文章中一直在使用它們。
對于這個簡單的示例,文件 myip.h 包含我們可以用來驅動新外設的三個函數。
-
MYIP_mReadReg(BaseAddress, RegOffset)
-
MYIP_mWriteReg(BaseAddress, RegOffset, Data)
-
XStatus MYIP_Reg_SelfTest( void * baseaddr_p);
除自檢功能外,讀取和寫入功能都映射到通用函數 Xil_In32 和 Xil_Out32,它們在 Xil_io.h 中定義。然而,使用創建的函數可以使代碼更具可讀性,因為被尋址的外設非常清晰。
對于這個例子,我們在外設中只有四個寄存器,所以我們將只使用自檢,它將寫入和讀取所有寄存器并報告通過或失敗。這個測試讓我們相信我們已經獲得了正確的硬件和軟件環境,一旦我們在外圍模塊中定義了它們,我們就可以繼續使用更高級的功能。在下一篇文章中,我們將研究如何使用 HDL 代碼向外設添加一些功能,以從處理系統中卸載功能并提高系統性能。
利用XADC進行復雜運算
假設我們想在 Zynq 中執行更復雜的計算,例如針對工業控制系統。通常,這些系統將具有多個模擬輸入(通過 ADC),由熱敏電阻、熱電偶、壓力傳感器、鉑電阻溫度計 (PRT) 等傳感器驅動。
很多時候,來自這些傳感器的數據需要傳遞函數來將來自 ADC 的原始數據值轉換為可用于進一步處理的數據。一個很好的例子是 Zynq XADC,它在 XADCPS.h 中包含許多函數/宏,用于將原始 XADC 值轉換為電壓或溫度。但是,這些轉換非常簡單。假如這些計算變得越復雜,則需要 Zynq 處理時間就越多。如果使用 Zynq SoC 的可編程邏輯 (PL) 端來執行這些計算,則可以大大加快計算速度。附帶的好處是,處理器還可以騰出時間來執行其他軟件任務,因此可以通過使用 PL 進行計算來提高處理帶寬。
傳遞函數越復雜,計算結果所需的處理器時間就越多。我們可以使用以millibars為單位的大氣壓力轉換為以米(meters)為單位的高度的示例來演示這種轉換。下面的傳遞函數給出了壓力在 0 到 10 millibars之間的海拔高度:

使用 Zynq SoC 的處理系統 (PS) Zynq 實現這個傳遞函數非常簡單,使用下面的代碼行,其中“結果-result”是一個浮點數;a、b 和 c 是上述傳遞函數中定義的常數;i 是輸入值
result=((float)a*(i*i))+((float)b*(i))+(float)c;
對于這個例子,我將使用嵌套在“for”循環中的代碼來模擬上面輸入值中的步驟。代碼通過 STDOUT 輸出結果。因為我要計算執行這個計算所需的時間,我將使用私有計時器來確定這個時間,如下:
for(i=0.0;i<10.0;?i?=?i?+0.1?){
???????XScuTimer_LoadTimer(&Timer,?TIMER_LOAD_VALUE);
???????timer_start?=?XScuTimer_GetCounterValue(&Timer);
???????XScuTimer_Start(&Timer);
???????result?=?((float)a*(i*i))+((float)b*(i))+(float)c;
XScuTimer_Stop(&Timer);
timer_value=XScuTimer_GetCounterValue(&Timer);
printf("%f,%f,%lu,%lu,
",i,result,timer_start,timer_value);
}
雖然此代碼可能無法提供最準確的時序參考,但足以證明我們研究的原理。在Zynq板上運行上述代碼,在終端窗口中獲得了以下結果。注意:
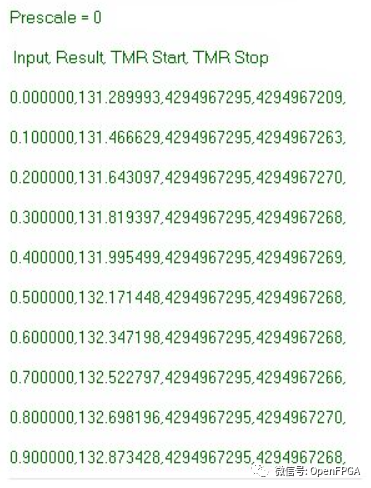
對此輸出進行一些簡單的分析表明,計算結果平均需要 25 個 CPU_3x2x 時鐘周期。。使用 666MHz 處理器時鐘,此計算需要 76 ns。我相信很多人會看到ADC輸出不是浮點數而是一個定點數。使用整數數學重寫函數代碼導致時鐘周期的平均數非常相似。但是我認為對于這個例子,浮點數會更容易使用,并且不需要解釋定點數系統背后的原理。
在確定了 Zynq 的 PS 端執行中等復雜度傳遞函數需要多長時間的基準之后,我們下一次可以看看當我們將相同的函數轉移到設備的 PL 端時,我們能以多快的速度計算這個函數。
定點數工作原理
上一節我們使用PS計算了一個公式,接下來我們將使用PL端加速這一公式計算,但是PL端的特點是只能進行定點計算,所以這一小節我們將說明一下定點數工作原理。
在數字系統中有兩種表示數字的方法:定點或浮點。定點表示將小數點保持在固定位置,這就大大簡化了算術運算。如圖所示,定點數由稱為整數和小數部分的兩部分組成:數字的整數部分在隱含小數點的左側,小數部分在右側。

上述定點數能夠使用二進制補碼表示表示介于 0.0 和 255.9906375 之間的無符號數或介于 –128.9906375 和 127.9906375 之間的有符號數。
浮點數分為指數和尾數兩部分。浮點表示允許小數點根據值的大小在數字內浮動。定點表示的主要缺點是要表示更大的數字或使用小數獲得更準確的結果,需要更多的位。雖然 FPGA 可以同時支持定點數和浮點數,但大多數應用程序都采用定點數系統,因為它們比浮點數系統更易于實現。
在設計中,我們可以選擇使用無符號或有符號數字。通常,選擇受到正在實施的算法的限制。無符號數可以表示 0 到 2n – 1 的范圍,并且始終表示正數。有符號數使用補碼數系統來表示正數和負數。二進制補碼系統允許通過簡單地將兩個數字相加來從另一個數字中減去一個數字。補碼數可以表示的范圍是:- (2n-1) ~ + (2n-1 – 1)
表示定點數內整數位和小數位之間分割的正常方式是 x,y,其中 x 表示整數位的數量,y 表示小數位的數量。例如 8,8 代表 8 個整數位和 8 個小數位,而 16,0 代表 16 個整數和 0 個小數位。
在許多情況下,整數和小數位數將在設計時確定,這個時間通常在算法從浮點轉換之后。由于 FPGA 的靈活性,我們可以表示任意位長的定點數;我們不僅限于 32、64 甚至 128 位寄存器。FPGA 對 15 位、37 位或 1024 位寄存器同樣適用。
所需整數位的數量取決于該數字需要存儲的最大整數值。小數位數取決于最終結果的所需精度。要確定所需的整數位數,我們可以使用以下等式:
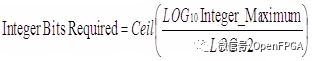
例如,表示 0.0 到 423.0 之間的值所需的整數位數是:
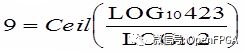
我們需要 9 個整數位,允許表示 0 到 511 的范圍.
兩個定點操作數的小數點必須對齊才能加、減或除這兩個數字。也就是說,一個 x,8 數字只能添加到、減去或除以同樣在 x,8 表示形式中的數字。要對不同 x,y 格式的數字執行算術運算,我們必須首先對齊小數點。請注意,對齊除法的小數點并不是絕對必要的。但是,實現定點除法需要仔細考慮,以確保在這種情況下得到正確的結果。
同樣,兩個定點數相乘時,小數點也不需要對齊。例如,將兩個定點數相乘,格式為 14,2 和 10,6,結果為 24,8(格式為 24 個整數位和 8 個小數位)。對于除以固定常數,我們當然可以通過計算常數的倒數然后將該常數結果用作乘數來簡化設計。
PL加速PS端計算
上一節簡單說了PL端實現定點計算的一些基礎知識,接下來就是專注于在系統中實現PL端加速的工作。
在我們開始切割代碼之前,我們需要確定我們將在這個特定實現中使用的比例因子(小數點的位置)。在此示例中,輸入信號的范圍在 0 到 10 之間,因此我們可以將 4 個十進制位和 12 個小數位打包成一個 16 位輸入向量。

上面的公式就是我們要實現的,它具有三個常數 A、B 和 C:A = -0.0088 B = 1.7673 C =131.29。我們需要在實現中處理(縮放)這些常數。在 FPGA 中這樣做的好處在于,我們可以對每個常數進行不同的縮放以優化性能,如下表所示:
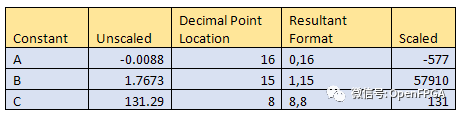
當我們實現上述等式時,我們需要考慮合成向量的擴展,對于術語 Ax^2和 Bx 定義如下:
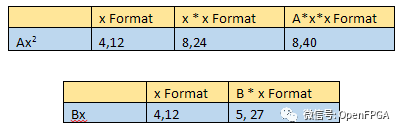
要使用常數 C 執行最終加法,我們需要對齊小數點。因此,我們需要將結果和 Ax^2和 Bx 除以 2 的冪,以將小數點與 C 對齊。result也將被格式化為這個值,即 8,8。
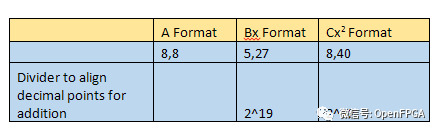
計算完上述內容后,我們就準備好在前幾節創建的 Vivado 外設工程中實施設計。
第一個實現步驟是在 Vivado 中打開框圖視圖,右鍵單擊IP,然后選擇“Edit in IP Packager”。一旦 IP Packager 在頂層文件中打開,我們就可以輕松實現一個簡單的過程,在多個時鐘周期內執行計算。(本示例中為五個時鐘,盡管可以進一步優化。)

現在我們可以在將更新的硬件導出到 SDK 之前,在 Vivado 中重新打包和重建項目(記得更新版本號)。
在 SDK 中,我們可以使用與以前相同的方法,除了現在使用定點數字系統而不是前面示例中使用的浮點系統:
for(i=0;i<2560;?i?=?i+25?){
???????XScuTimer_LoadTimer(&Timer,?TIMER_LOAD_VALUE);
???????timer_start?=?XScuTimer_GetCounterValue(&Timer);
???????XScuTimer_Start(&Timer);
???????ADAMS_PERIHPERAL_mWriteReg(Adam_Low,?4,?i);
???????result?=?ADAMS_PERIHPERAL_mReadReg(Adam_Low,?12);
???????XScuTimer_Stop(&Timer);
???????timer_value?=?XScuTimer_GetCounterValue(&Timer);
??????printf("%d,%lu,%lu,%lu,
",i,result,timer_start,timer_value);
}
當上面的代碼在ZYNQ板上運行時,我們在串行鏈路上看到以下結果輸出:

33610 的結果等于 131.289 除以 2^8 時,這是正確的并且符合浮點計算。盡管數值結果相同,但最大的區別在于執行計算所需的時間。雖然外圍設計的實際計算只需要 5 個時鐘,但生成結果需要 140 個時鐘或 420ns,而在 Zynq SoC 的 PS 側使用 ARM Cortex-A9 處理器則需要 25 個 CPU 時鐘。
為什么會出現差異?PL端不應該更快嗎?主要原因時外圍 I/O 時間開銷。在使用 PL 端時,我們必須考慮 AXI 總線上的總線延遲和 AXI 總線頻率,在此應用中為 142.8MHz(請求為 150MHz)。AXI 總線開銷導致計算時間長于預期。然而,一切都沒有錯。錯的是我做錯了方向:因為這種 I/O 開銷時間,將任務轉移到 Zynq SoC 的 PL 并不是以這種方式使用的。
那么如果我們要采取更合理的方法,需要怎么做?DMA
下一篇文章我們將使用DMA來搬運數據,看下結果是不是我們要的~~
本文部分源文件:
https://gitee.com/openfpga/zynq-chronicles/blob/master/VHDL_part24.vhd

審核編輯 :李倩
-
可編程邏輯
+關注
關注
7文章
517瀏覽量
44181 -
Zynq SoC
+關注
關注
0文章
6瀏覽量
3655
原文標題:ZYNQ從放棄到入門(八)-PS和PL交互
文章出處:【微信號:Open_FPGA,微信公眾號:OpenFPGA】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
使用BQ76PL102系列電量計進行BQ78PL114的快速入門指南

PICO-IMX8PL和SRG-IMX8PL:共創您的物聯網集成網關

復旦微PS+PL異構多核開發案例分享,基于FMQL20SM國產處理器平臺
PL7518v1
FM20S用戶手冊-PS + PL異構多核案例開發手冊
FM20S用戶手冊-PL端案例開發手冊
有關PL端利用AXI總線控制PS端DDR進行讀寫(從機wready信號一直不拉高)
簡談Xilinx Zynq-7000嵌入式系統設計與實現
AMD Versal AI Edge自適應計算加速平臺之體驗ARM,裸機輸出(7)
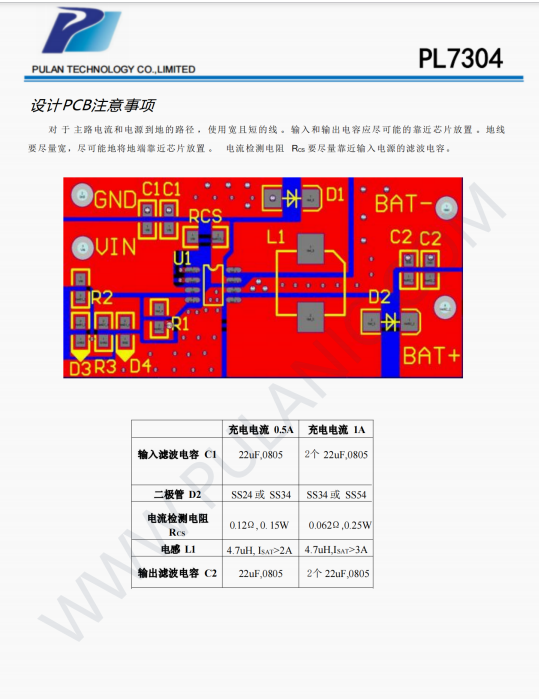
PL7304鋰電池充電集成電路





 工商網監
工商網監
評論