 盤點幾種常見的數據結構
盤點幾種常見的數據結構
1.幾種常見的數據結構
這里主要總結下在工作中常碰到的幾種數據結構:Array,ArrayList,List,LinkedList,Queue,Stack,Dictionary。,t>
數組Array:
數組是最簡單的數據結構。其具有如下特點:
數組存儲在連續的內存上。
數組的內容都是相同類型。
數組可以直接通過下標訪問。
數組Array的創建:
1 int size = 5; 2 int[] test = new int[size];
創建一個新的數組時將在 CLR 托管堆中分配一塊連續的內存空間,來盛放數量為size,類型為所聲明類型的數組元素。如果類型為值類型,則將會有size個未裝箱的該類型的值被創建。如果類型為引用類型,則將會有size個相應類型的引用被創建。
由于是在連續內存上存儲的,所以它的索引速度非常快,訪問一個元素的時間是恒定的也就是說與數組的元素數量無關,而且賦值與修改元素也很簡單。
string[] test2 = new string[3];
//賦值
test2[0] = "chen";
test2[1] = "j";
test2[2] = "d";
//修改
test2[0] = "chenjd";
但是有優點,那么就一定會伴隨著缺點。由于是連續存儲,所以在兩個元素之間插入新的元素就變得不方便。而且就像上面的代碼所顯示的那樣,聲明一個新的數組時,必須指定其長度,這就會存在一個潛在的問題,那就是當我們聲明的長度過長時,顯然會浪費內存,當我們聲明長度過短的時候,則面臨這溢出的風險。這就使得寫代碼像是投機,很厭惡這樣的行為!針對這種缺點,下面隆重推出ArrayList。
ArrayList:
為了解決數組創建時必須指定長度以及只能存放相同類型的缺點而推出的數據結構。ArrayList是System.Collections命名空間下的一部分,所以若要使用則必須引入System.Collections。正如上文所說,ArrayList解決了數組的一些缺點。
不必在聲明ArrayList時指定它的長度,這是由于ArrayList對象的長度是按照其中存儲的數據來動態增長與縮減的。
ArrayList可以存儲不同類型的元素。這是由于ArrayList會把它的元素都當做Object來處理。因而,加入不同類型的元素是允許的。
ArrayList的操作:
ArrayList test3 = new ArrayList();
//新增數據
test3.Add("chen");
test3.Add("j");
test3.Add("d");
test3.Add("is");
test3.Add(25);
//修改數據
test3[4] = 26;
//刪除數據
test3.RemoveAt(4);
說了那么一堆”優點“,也該說說缺點了吧。為什么要給”優點”打上引號呢?那是因為ArrayList可以存儲不同類型數據的原因是由于把所有的類型都當做Object來做處理,也就是說ArrayList的元素其實都是Object類型的,辣么問題就來了。
ArrayList不是類型安全的。因為把不同的類型都當做Object來做處理,很有可能會在使用ArrayList時發生類型不匹配的情況。
如上文所訴,數組存儲值類型時并未發生裝箱,但是ArrayList由于把所有類型都當做了Object,所以不可避免的當插入值類型時會發生裝箱操作,在索引取值時會發生拆箱操作。這能忍嗎?
注:為何說頻繁的沒有必要的裝箱和拆箱不能忍呢?所謂裝箱 (boxing):就是值類型實例到對象的轉換(百度百科)。那么拆箱:就是將引用類型轉換為值類型咯(還是來自百度百科)。下面舉個栗子~
//裝箱,將String類型的值FanyoyChenjd賦值給對象。
int info = 1989;
object obj=(object)info;
//拆箱,從Obj中提取值給info
object obj = 1;
int info = (int)obj;
那么結論呢?顯然,從原理上可以看出,裝箱時,生成的是全新的引用對象,這會有時間損耗,也就是造成效率降低。
List泛型List
為了解決ArrayList不安全類型與裝箱拆箱的缺點,所以出現了泛型的概念,作為一種新的數組類型引入。也是工作中經常用到的數組類型。和ArrayList很相似,長度都可以靈活的改變,最大的不同在于在聲明List集合時,我們同時需要為其聲明List集合內數據的對象類型,這點又和Array很相似,其實List內部使用了Array來實現。
List test4 = new List();
//新增數據
test4.Add(“Fanyoy”);
test4.Add(“Chenjd”);
//修改數據
test4[1] = “murongxiaopifu”;
//移除數據
test4.RemoveAt(0);
這么做最大的好處就是
即確保了類型安全。
也取消了裝箱和拆箱的操作。
它融合了Array可以快速訪問的優點以及ArrayList長度可以靈活變化的優點。
LinkedList
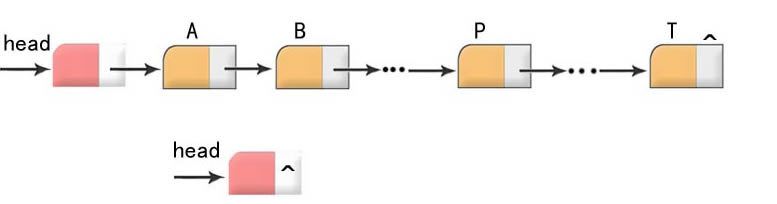
也就是鏈表了。和上述的數組最大的不同之處就是在于鏈表在內存存儲的排序上可能是不連續的。這是由于鏈表是通過上一個元素指向下一個元素來排列的,所以可能不能通過下標來訪問。如圖
?
既然鏈表最大的特點就是存儲在內存的空間不一定連續,那么鏈表相對于數組最大優勢和劣勢就顯而易見了。
向鏈表中插入或刪除節點無需調整結構的容量。因為本身不是連續存儲而是靠各對象的指針所決定,所以添加元素和刪除元素都要比數組要有優勢。
鏈表適合在需要有序的排序的情境下增加新的元素,這里還拿數組做對比,例如要在數組中間某個位置增加新的元素,則可能需要移動移動很多元素,而對于鏈表而言可能只是若干元素的指向發生變化而已。
有優點就有缺點,由于其在內存空間中不一定是連續排列,所以訪問時候無法利用下標,而是必須從頭結點開始,逐次遍歷下一個節點直到尋找到目標。所以當需要快速訪問對象時,數組無疑更有優勢。
綜上,鏈表適合元素數量不固定,需要經常增減節點的情況。
示例:
下面的代碼示例演示了類的許多功能LinkedList。
using System;
using System.Text;
using System.Collections.Generic;
public class Example
{
public static void Main()
{
// Create the link list.
string[] words =
{ "the", "fox", "jumps", "over", "the", "dog" };
LinkedList sentence = new LinkedList(words);
Display(sentence, "The linked list values:");
Console.WriteLine("sentence.Contains("jumps") = {0}",
sentence.Contains("jumps"));
// Add the word 'today' to the beginning of the linked list.
sentence.AddFirst("today");
Display(sentence, "Test 1: Add 'today' to beginning of the list:");
// Move the first node to be the last node.
LinkedListNode mark1 = sentence.First;
sentence.RemoveFirst();
sentence.AddLast(mark1);
Display(sentence, "Test 2: Move first node to be last node:");
// Change the last node to 'yesterday'.
sentence.RemoveLast();
sentence.AddLast("yesterday");
Display(sentence, "Test 3: Change the last node to 'yesterday':");
// Move the last node to be the first node.
mark1 = sentence.Last;
sentence.RemoveLast();
sentence.AddFirst(mark1);
Display(sentence, "Test 4: Move last node to be first node:");
// Indicate the last occurence of 'the'.
sentence.RemoveFirst();
LinkedListNode current = sentence.FindLast("the");
IndicateNode(current, "Test 5: Indicate last occurence of 'the':");
// Add 'lazy' and 'old' after 'the' (the LinkedListNode named current).
sentence.AddAfter(current, "old");
sentence.AddAfter(current, "lazy");
IndicateNode(current, "Test 6: Add 'lazy' and 'old' after 'the':");
// Indicate 'fox' node.
current = sentence.Find("fox");
IndicateNode(current, "Test 7: Indicate the 'fox' node:");
// Add 'quick' and 'brown' before 'fox':
sentence.AddBefore(current, "quick");
sentence.AddBefore(current, "brown");
IndicateNode(current, "Test 8: Add 'quick' and 'brown' before 'fox':");
// Keep a reference to the current node, 'fox',
// and to the previous node in the list. Indicate the 'dog' node.
mark1 = current;
LinkedListNode mark2 = current.Previous;
current = sentence.Find("dog");
IndicateNode(current, "Test 9: Indicate the 'dog' node:");
// The AddBefore method throws an InvalidOperationException
// if you try to add a node that already belongs to a list.
Console.WriteLine("Test 10: Throw exception by adding node (fox) already in the list:");
try
{
sentence.AddBefore(current, mark1);
}
catch (InvalidOperationException ex)
{
Console.WriteLine("Exception message: {0}", ex.Message);
}
Console.WriteLine();
// Remove the node referred to by mark1, and then add it
// before the node referred to by current.
// Indicate the node referred to by current.
sentence.Remove(mark1);
sentence.AddBefore(current, mark1);
IndicateNode(current, "Test 11: Move a referenced node (fox) before the current node (dog):");
// Remove the node referred to by current.
sentence.Remove(current);
IndicateNode(current, "Test 12: Remove current node (dog) and attempt to indicate it:");
// Add the node after the node referred to by mark2.
sentence.AddAfter(mark2, current);
IndicateNode(current, "Test 13: Add node removed in test 11 after a referenced node (brown):");
// The Remove method finds and removes the
// first node that that has the specified value.
sentence.Remove("old");
Display(sentence, "Test 14: Remove node that has the value 'old':");
// When the linked list is cast to ICollection(Of String),
// the Add method adds a node to the end of the list.
sentence.RemoveLast();
ICollection icoll = sentence;
icoll.Add("rhinoceros");
Display(sentence, "Test 15: Remove last node, cast to ICollection, and add 'rhinoceros':");
Console.WriteLine("Test 16: Copy the list to an array:");
// Create an array with the same number of
// elements as the linked list.
string[] sArray = new string[sentence.Count];
sentence.CopyTo(sArray, 0);
foreach (string s in sArray)
{
Console.WriteLine(s);
}
// Release all the nodes.
sentence.Clear();
Console.WriteLine();
Console.WriteLine("Test 17: Clear linked list. Contains 'jumps' = {0}",
sentence.Contains("jumps"));
Console.ReadLine();
}
private static void Display(LinkedList words, string test)
{
Console.WriteLine(test);
foreach (string word in words)
{
Console.Write(word + " ");
}
Console.WriteLine();
Console.WriteLine();
}
private static void IndicateNode(LinkedListNode node, string test)
{
Console.WriteLine(test);
if (node.List == null)
{
Console.WriteLine("Node '{0}' is not in the list.\n",
node.Value);
return;
}
StringBuilder result = new StringBuilder("(" + node.Value + ")");
LinkedListNode nodeP = node.Previous;
while (nodeP != null)
{
result.Insert(0, nodeP.Value + " ");
nodeP = nodeP.Previous;
}
node = node.Next;
while (node != null)
{
result.Append(" " + node.Value);
node = node.Next;
}
Console.WriteLine(result);
Console.WriteLine();
}
}
//This code example produces the following output:
//
//The linked list values:
//the fox jumps over the dog
//Test 1: Add 'today' to beginning of the list:
//today the fox jumps over the dog
//Test 2: Move first node to be last node:
//the fox jumps over the dog today
//Test 3: Change the last node to 'yesterday':
//the fox jumps over the dog yesterday
//Test 4: Move last node to be first node:
//yesterday the fox jumps over the dog
//Test 5: Indicate last occurence of 'the':
//the fox jumps over (the) dog
//Test 6: Add 'lazy' and 'old' after 'the':
//the fox jumps over (the) lazy old dog
//Test 7: Indicate the 'fox' node:
//the (fox) jumps over the lazy old dog
//Test 8: Add 'quick' and 'brown' before 'fox':
//the quick brown (fox) jumps over the lazy old dog
//Test 9: Indicate the 'dog' node:
//the quick brown fox jumps over the lazy old (dog)
//Test 10: Throw exception by adding node (fox) already in the list:
//Exception message: The LinkedList node belongs a LinkedList.
//Test 11: Move a referenced node (fox) before the current node (dog):
//the quick brown jumps over the lazy old fox (dog)
//Test 12: Remove current node (dog) and attempt to indicate it:
//Node 'dog' is not in the list.
//Test 13: Add node removed in test 11 after a referenced node (brown):
//the quick brown (dog) jumps over the lazy old fox
//Test 14: Remove node that has the value 'old':
//the quick brown dog jumps over the lazy fox
//Test 15: Remove last node, cast to ICollection, and add 'rhinoceros':
//the quick brown dog jumps over the lazy rhinoceros
//Test 16: Copy the list to an array:
//the
//quick
//brown
//dog
//jumps
//over
//the
//lazy
//rhinoceros
//Test 17: Clear linked list. Contains 'jumps' = False
//
Queue
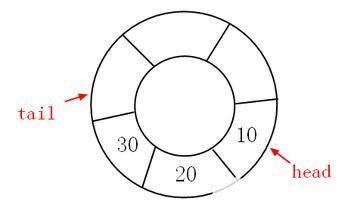
在Queue這種數據結構中,最先插入在元素將是最先被刪除;反之最后插入的元素將最后被刪除,因此隊列又稱為“先進先出”(FIFO—first in first out)的線性表。通過使用Enqueue和Dequeue這兩個方法來實現對 Queue 的存取。
一些需要注意的地方:
先進先出的情景。
默認情況下,Queue的初始容量為32, 增長因子為2.0。
當使用Enqueue時,會判斷隊列的長度是否足夠,若不足,則依據增長因子來增加容量,例如當為初始的2.0時,則隊列容量增長2倍。
乏善可陳。
示例:
下面的代碼示例演示了泛型類的幾個方法 Queue 。 此代碼示例創建具有默認容量的字符串隊列,并使用 Enqueue 方法將五個字符串進行排隊。 枚舉隊列的元素,而不會更改隊列的狀態。 Dequeue方法用于取消對第一個字符串的排隊。 Peek方法用于查看隊列中的下一項,然后 Dequeue 使用方法將其取消排隊。
ToArray方法用于創建數組,并將隊列元素復制到該數組,然后將數組傳遞給 Queue 采用的構造函數 IEnumerable ,創建隊列的副本。 將顯示副本的元素。
創建隊列大小兩倍的數組,并 CopyTo 使用方法從數組中間開始復制數組元素。 在 Queue 開始時,將再次使用構造函數來創建包含三個 null 元素的隊列的第二個副本。
Contains方法用于顯示字符串 "四" 位于隊列的第一個副本中,在此之后, Clear 方法會清除副本, Count 屬性顯示該隊列為空。
using System;
using System.Collections.Generic;
class Example
{
public static void Main()
{
Queue numbers = new Queue();
numbers.Enqueue("one");
numbers.Enqueue("two");
numbers.Enqueue("three");
numbers.Enqueue("four");
numbers.Enqueue("five");
// A queue can be enumerated without disturbing its contents.
foreach( string number in numbers )
{
Console.WriteLine(number);
}
Console.WriteLine("\nDequeuing '{0}'", numbers.Dequeue());
Console.WriteLine("Peek at next item to dequeue: {0}",
numbers.Peek());
Console.WriteLine("Dequeuing '{0}'", numbers.Dequeue());
// Create a copy of the queue, using the ToArray method and the
// constructor that accepts an IEnumerable.
Queue queueCopy = new Queue(numbers.ToArray());
Console.WriteLine("\nContents of the first copy:");
foreach( string number in queueCopy )
{
Console.WriteLine(number);
}
// Create an array twice the size of the queue and copy the
// elements of the queue, starting at the middle of the
// array.
string[] array2 = new string[numbers.Count * 2];
numbers.CopyTo(array2, numbers.Count);
// Create a second queue, using the constructor that accepts an
// IEnumerable(Of T).
Queue queueCopy2 = new Queue(array2);
Console.WriteLine("\nContents of the second copy, with duplicates and nulls:");
foreach( string number in queueCopy2 )
{
Console.WriteLine(number);
}
Console.WriteLine("\nqueueCopy.Contains("four") = {0}",
queueCopy.Contains("four"));
Console.WriteLine("\nqueueCopy.Clear()");
queueCopy.Clear();
Console.WriteLine("\nqueueCopy.Count = {0}", queueCopy.Count);
}
}
/* This code example produces the following output:
one
two
three
four
five
Dequeuing 'one'
Peek at next item to dequeue: two
Dequeuing 'two'
Contents of the copy:
three
four
five
Contents of the second copy, with duplicates and nulls:
three
four
five
queueCopy.Contains("four") = True
queueCopy.Clear()
queueCopy.Count = 0
*/
Stack
與Queue相對,當需要使用后進先出順序(LIFO)的數據結構時,我們就需要用到Stack了。
一些需要注意的地方:
后進先出的情景。
默認容量為10。
使用pop和push來操作。
乏善可陳。
示例:
下面的代碼示例演示了泛型類的幾個方法 Stack 。 此代碼示例創建一個具有默認容量的字符串堆棧,并使用 Push 方法將五個字符串推送到堆棧上。 枚舉堆棧的元素,這不會更改堆棧的狀態。 Pop方法用于彈出堆棧中的第一個字符串。 Peek方法用于查看堆棧上的下一項,然后 Pop 使用方法將它彈出。
ToArray方法用于創建數組,并將堆棧元素復制到該數組,然后將該數組傳遞給 Stack 采用的構造函數,并 IEnumerable 使用反轉元素的順序創建堆棧副本。 將顯示副本的元素。
創建堆棧大小兩倍的數組,并 CopyTo 使用方法從數組中間開始復制數組元素。 Stack再次使用構造函數來創建具有反轉的元素順序的堆棧副本; 因此,這三個 null 元素位于末尾。
Contains方法用于顯示字符串 "四" 位于堆棧的第一個副本中,在此之后, Clear 方法會清除副本, Count 屬性會顯示堆棧為空。
using System;
using System.Collections.Generic;
class Example
{
public static void Main()
{
Stack numbers = new Stack();
numbers.Push("one");
numbers.Push("two");
numbers.Push("three");
numbers.Push("four");
numbers.Push("five");
// A stack can be enumerated without disturbing its contents.
foreach( string number in numbers )
{
Console.WriteLine(number);
}
Console.WriteLine("\nPopping '{0}'", numbers.Pop());
Console.WriteLine("Peek at next item to destack: {0}",
numbers.Peek());
Console.WriteLine("Popping '{0}'", numbers.Pop());
// Create a copy of the stack, using the ToArray method and the
// constructor that accepts an IEnumerable.
Stack stack2 = new Stack(numbers.ToArray());
Console.WriteLine("\nContents of the first copy:");
foreach( string number in stack2 )
{
Console.WriteLine(number);
}
// Create an array twice the size of the stack and copy the
// elements of the stack, starting at the middle of the
// array.
string[] array2 = new string[numbers.Count * 2];
numbers.CopyTo(array2, numbers.Count);
// Create a second stack, using the constructor that accepts an
// IEnumerable(Of T).
Stack stack3 = new Stack(array2);
Console.WriteLine("\nContents of the second copy, with duplicates and nulls:");
foreach( string number in stack3 )
{
Console.WriteLine(number);
}
Console.WriteLine("\nstack2.Contains("four") = {0}",
stack2.Contains("four"));
Console.WriteLine("\nstack2.Clear()");
stack2.Clear();
Console.WriteLine("\nstack2.Count = {0}", stack2.Count);
}
}
/* This code example produces the following output:
five
four
three
two
one
Popping 'five'
Peek at next item to destack: four
Popping 'four'
Contents of the first copy:
one
two
three
Contents of the second copy, with duplicates and nulls:
one
two
three
stack2.Contains("four") = False
stack2.Clear()
stack2.Count = 0
*/
Dictionary,t>
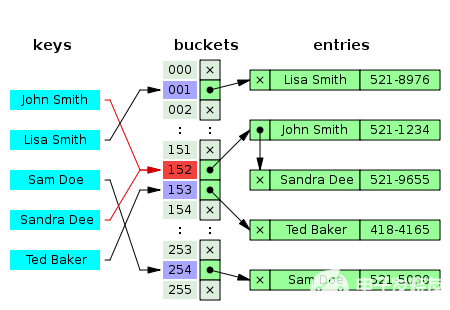
提到字典就不得不說Hashtable哈希表以及Hashing(哈希,也有叫散列的),因為字典的實現方式就是哈希表的實現方式,只不過字典是類型安全的,也就是說當創建字典時,必須聲明key和item的類型,這是第一條字典與哈希表的區別。關于哈希,簡單的說就是一種將任意長度的消息壓縮到某一固定長度,比如某學校的學生學號范圍從00000~99999,總共5位數字,若每個數字都對應一個索引的話,那么就是100000個索引,但是如果我們使用后3位作為索引,那么索引的范圍就變成了000~999了,當然會沖突的情況,這種情況就是哈希沖突(Hash Collisions)了。
回到Dictionary,我們在對字典的操作中各種時間上的優勢都享受到了,那么它的劣勢到底在哪呢?對嘞,就是空間。以空間換時間,通過更多的內存開銷來滿足我們對速度的追求。在創建字典時,我們可以傳入一個容量值,但實際使用的容量并非該值。而是使用“不小于該值的最小質數來作為它使用的實際容量,最小是3。”(老趙),當有了實際容量之后,并非直接實現索引,而是通過創建額外的2個數組來實現間接的索引,即int[] buckets和Entry[] entries兩個數組(即buckets中保存的其實是entries數組的下標),這里就是第二條字典與哈希表的區別,還記得哈希沖突嗎?對,第二個區別就是處理哈希沖突的策略是不同的!字典會采用額外的數據結構來處理哈希沖突,這就是剛才提到的數組之一buckets桶了,buckets的長度就是字典的真實長度,因為buckets就是字典每個位置的映射,然后buckets中的每個元素都是一個鏈表,用來存儲相同哈希的元素,然后再分配存儲空間。,t>
?
因此,我們面臨的情況就是,即便我們新建了一個空的字典,那么伴隨而來的是2個長度為3的數組。所以當處理的數據不多時,還是慎重使用字典為好,很多情況下使用數組也是可以接受的。
幾種常見數據結構的使用情景
| Array | 需要處理的元素數量確定并且需要使用下標時可以考慮,不過建議使用List |
|---|---|
| ArrayList | 不推薦使用,建議用List |
| List泛型List | 需要處理的元素數量不確定時 通常建議使用 |
| LinkedList | 鏈表適合元素數量不固定,需要經常增減節點的情況,2端都可以增減 |
| Queue | 先進先出的情況 |
| Stack | 后進先出的情況 |
| Dictionary | 需要鍵值對,快速操作 |
?
-
數據結構
+關注
關注
3文章
573瀏覽量
40230 -
Queue
+關注
關注
0文章
16瀏覽量
7284 -
Array
+關注
關注
99文章
18瀏覽量
18053
發布評論請先 登錄
相關推薦
數據結構是什么_數據結構有什么用
java中幾種常用數據結構
為什么要學習數據結構?數據結構的應用詳細資料概述免費下載
什么是數據結構?為什么要學習數據結構?數據結構的應用實例分析
算法和數據結構基礎知識分享(上)
算法和數據結構基礎知識分享(中)
算法和數據結構基礎知識分享(下)
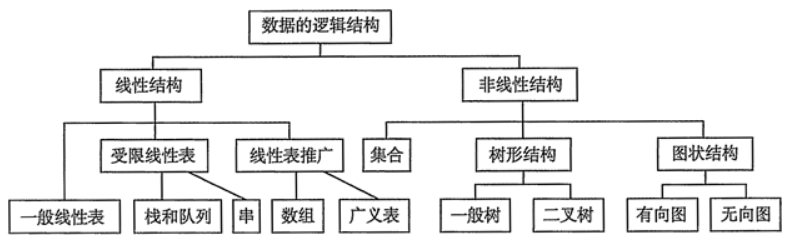
嵌入式技術數據結構中常見的樹有哪些?
NetApp的數據結構是如何演變的






 工商網監
工商網監
評論