 新晉圖像生成王者擴散模型
新晉圖像生成王者擴散模型
新晉圖像生成王者擴散模型,剛剛誕生沒多久。
有關它的理論和實踐都還在“野蠻生長”。
來自英偉達StyleGAN的原班作者們站了出來,嘗試給出了一些設計擴散模型的竅門和準則,結果模型的質量和效率都有所改進,比如將現有ImageNet-64模型的FID分數從2.07提高到接近SOTA的1.55分。

他們這一工作成果迅速得到了業界大佬的認同。
DeepMind研究員就稱贊道:這篇論文簡直就是訓練擴散模型的人必看,妥妥的一座金礦。

三大貢獻顯著提高模型質量和效率
我們從以下幾個方面來看StyleGAN作者們對擴散模型所做的三大貢獻:
用通用框架表示擴散模型
在這部分,作者的貢獻主要為從實踐的角度觀察模型背后的理論,重點關注出現在訓練和采樣階段的“有形”對象和算法,更好地了解了組件是如何連接在一起的,以及它們在整個系統的設計中可以使用的自由度(degrees of freedom)。
精華就是下面這張表:

該表給出了在他們的框架中復現三種模型的確定變體的公式。
(這三種方法(VP、VE、iDDPM+ DDIM)不僅被廣泛使用且實現了SOTA性能,還來自不同的理論基礎。)
這些公式讓組件之間原則上沒有隱含的依賴關系,在合理范圍內選擇任意單個公示都可以得出一個功能模型。
隨機采樣和確定性采樣的改進
作者的第二組貢獻涉及擴散模型合成圖像的采樣過程。
他們確定了最佳的時間離散化(time discretization),對采樣過程應用了更高階的Runge–Kutta方法,并在三個預訓練模型上評估不同的方法,分析了隨機性在采樣過程中的有用性。
結果在合成過程中所需的采樣步驟數量顯著減少,改進的采樣器可以用作幾個廣泛使用的擴散模型的直接替代品。
先看確定性采樣。用到的三個測試模型還是上面的那三個,來自不同的理論框架和模型族。
作者首先使用原始的采樣器(sampler)實現測量這些模型的基線結果,然后使用表1中的公式將這些采樣方法引入他們的統一框架,再進行改進。
接著根據在50000張生成圖像和所有可用真實圖像之間計算的FID分數來評估質量。
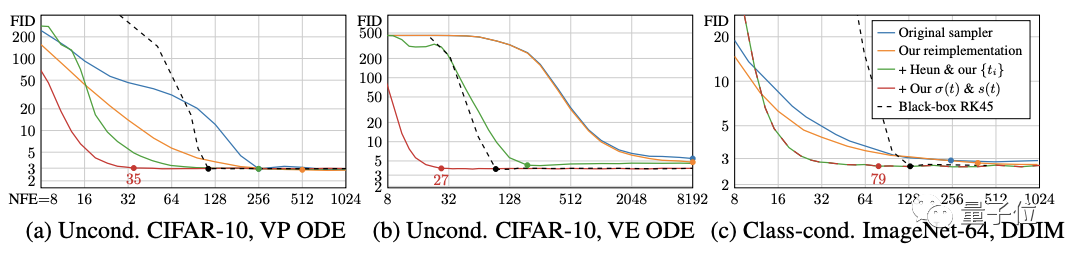
可以看到,原始的的確定性采樣器以藍色顯示,在他們的統一框架(橙色)中重新實現這些方法會產生類似或更好的結果。
作者解釋,這些差異是由于原始實現中的某些疏忽,加上作者對離散噪聲級的處理更仔細造成的。
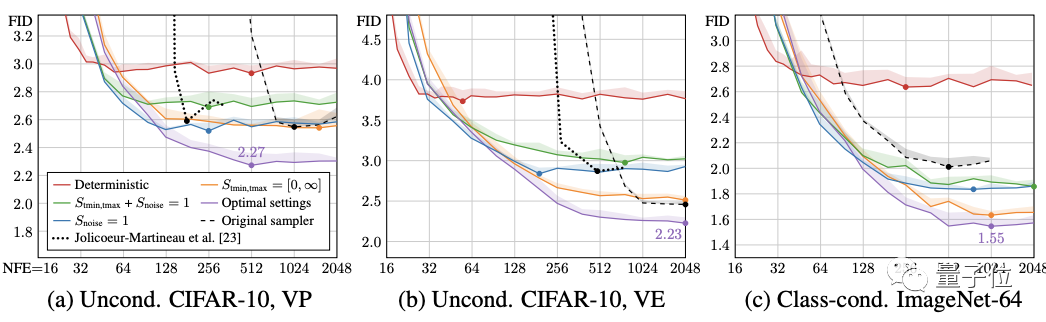
確定性采樣好處雖然多,但與每一步都向圖像中注入新噪聲的隨機采樣相比,它輸出的圖像質量確實更差。
不過作者很好奇,假設ODE(常微分方程)和SDE(隨機微分方程)在理論上恢復相同的分布,隨機性的作用到底是什么?
在此他們提出了一種新的隨機采樣器,它將現有的高階ODE積分器與添加和去除噪聲的顯式“Langevin-like ‘churn’”相結合。
最終模型性能提升顯著,而且僅通過對采樣器的改進,就能夠讓ImageNet-64模型原來的FID分數從2.07提高到1.55,接近SOTA水平。
預處理和訓練
作者的第三組貢獻主要為分數建模(score-modeling)神經網絡的訓練。
這部分繼續依賴常用的網絡體系結構(DDPM、NCSN),作者通過對擴散模型設置中網絡的輸入、輸出和損失函數的預處理進行了原則性分析,得出了改進訓練動態的最佳實踐。
比如使用依賴于σ(noise level)的跳躍連接對神經網絡進行預處理,使其能夠估計y(signal)或n(noise),或介于兩者之間的東西。
下表具體展示了模型彩英不同訓練配置得到的FID分數。
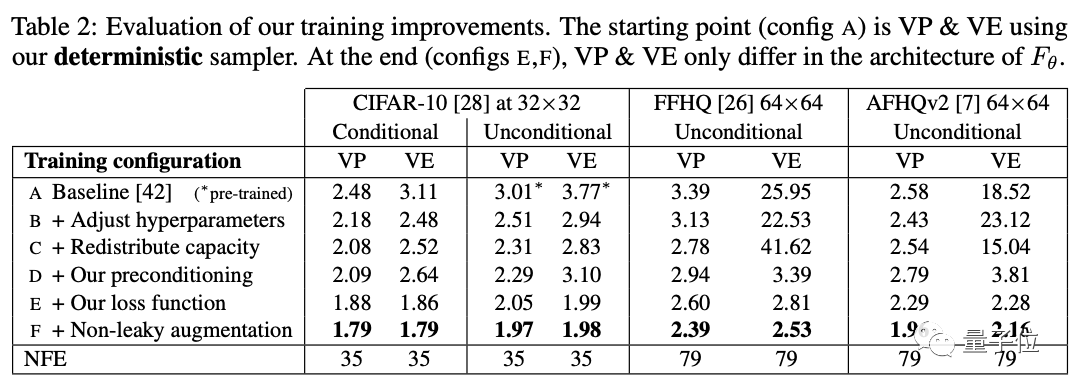
作者從基線訓練配置開始,使用確定性采樣器(稱為配置A),重新調整了基本超參數(配置B),并通過移除最低分辨率層,并將最高分辨率層的容量加倍來提高模型的表達能力(配置C)。
然后用預處理(配置D)替換原來的{cin,cout,cnoise,cskip}選項。這使結果基本保持不變,但VE在64×64分辨率下有很大改善。該預處理方法的主要好處不是改善FID本身,而是使訓練更加穩健,從而將重點轉向重新設計損失函數又不會產生不利影響。
VP和VE只在Fθ的架構上有所不同(配置E和F)。
除此之外,作者還建議改進訓練期間的噪聲級分布,并發現通常與GANs一起使用的無泄漏風險增強(non-leaking augmentation)操作也有利于擴散模型。
比如從上表中,我們可以看到:有條件和無條件CIFAR-10的最新FID分別達到了1.79和1.97,打破了之前的記錄(1.85和2.1046)。
審核編輯 :李倩
-
算法
+關注
關注
23文章
4630瀏覽量
93360 -
模型
+關注
關注
1文章
3313瀏覽量
49231
原文標題:DeepMind谷歌研究員力薦:擴散模型效率&生成質量提升竅門,來自StyleGAN原作者
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AN-715::走近IBIS模型:什么是IBIS模型?它們是如何生成的?

基于移動自回歸的時序擴散預測模型
借助谷歌Gemini和Imagen模型生成高質量圖像

Google兩款先進生成式AI模型登陸Vertex AI平臺
浙大、微信提出精確反演采樣器新范式,徹底解決擴散模型反演問題


Meta發布Imagine Yourself AI模型,重塑個性化圖像生成未來
如何用C++創建簡單的生成式AI模型
Runway發布Gen-3 Alpha視頻生成模型
南開大學和字節跳動聯合開發一款StoryDiffusion模型
KOALA人工智能圖像生成模型問世
韓國科研團隊發布新型AI圖像生成模型KOALA,大幅優化硬件需求
谷歌Gemini AI模型因人物圖像生成問題暫停運行
openai發布首個視頻生成模型sora
Stability AI試圖通過新的圖像生成人工智能模型保持領先地位






 工商網監
工商網監
評論