 NVIDIA Merlin分布式嵌入使快速、TB級推薦培訓變得簡單
NVIDIA Merlin分布式嵌入使快速、TB級推薦培訓變得簡單
嵌入在深度學習推薦模型中起著關鍵作用。它們用于將數據中的編碼分類輸入映射到可由數學層或多層感知器( MLP )處理的數值。
嵌入通常構成深度學習推薦模型中的大部分參數,并且可以相當大,甚至達到 TB 級。在訓練期間,很難將它們放入單個 GPU 的內存中。
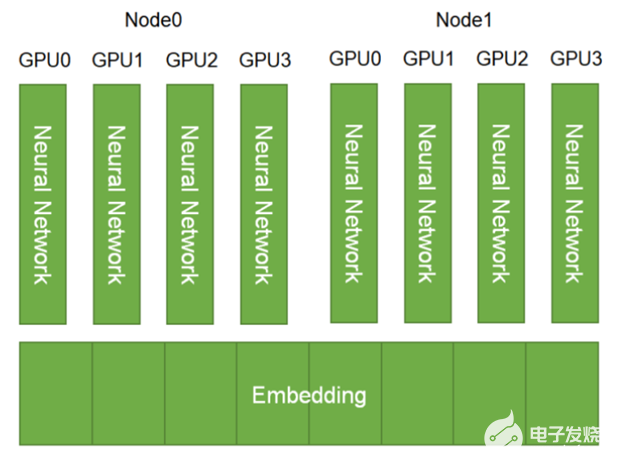
因此,現代推薦者可能需要模型并行和數據并行分布式訓練方法的組合,以實現合理的訓練時間和可用 GPU 計算的最佳利用。
NVIDIA Merlin 分布式嵌入 ,在 TensorFlow 2 中,一個用于訓練大型基于嵌入的(例如,推薦者)模型的庫使您只需幾行代碼即可輕松完成。
背景
通過 GPU 上的數據并行分布式訓練,在每個 GPU 工作人員上復制整個模型。在訓練過程中,一批數據在多個 GPU 中分割,每個設備獨立操作其自己的數據碎片。
這允許將計算擴展到更大批量的更高數據量。在反向傳播期間計算的梯度使用減少操作(例如, horovod.tensorflow.allreduce ) 用于同步參數更新。
通過模型并行分布式訓練,模型參數在不同工作人員之間進行分割。這是一種更適合分發大型嵌入表的方法。訓練需要使用全對全通信原語(例如, horovod.tensorflow.alltoall ) 使得工人可以訪問不在其分區中的參數。
在之前的相關文章中, 在 TensorFlow 2 中使用 100B +參數在 DGX A100 上訓練推薦系統 , Tomasz 討論了如何為 1130 億參數分配嵌入 DLRM 跨多個 NVIDIA GPU 的模型有助于在僅 CPU 的解決方案上實現 672 倍的加速。這一重大改進可能會將訓練時間從幾天縮短到幾分鐘!這是通過模型并行分布嵌入表和通過數據并行執行小得多的數學密集型 MLP 層計算來實現的。
與將嵌入存儲在 CPU 內存中相比,這種混合方法使您能夠使用 GPU 內存的高內存帶寬進行內存綁定嵌入查找。它還使用幾個 GPU 設備中的計算能力加速 MLP 層。作為參考 NVIDIA A100-80GB GPU 具有帶寬超過 2 TB / s 的 80 GB HBM2 存儲器)。
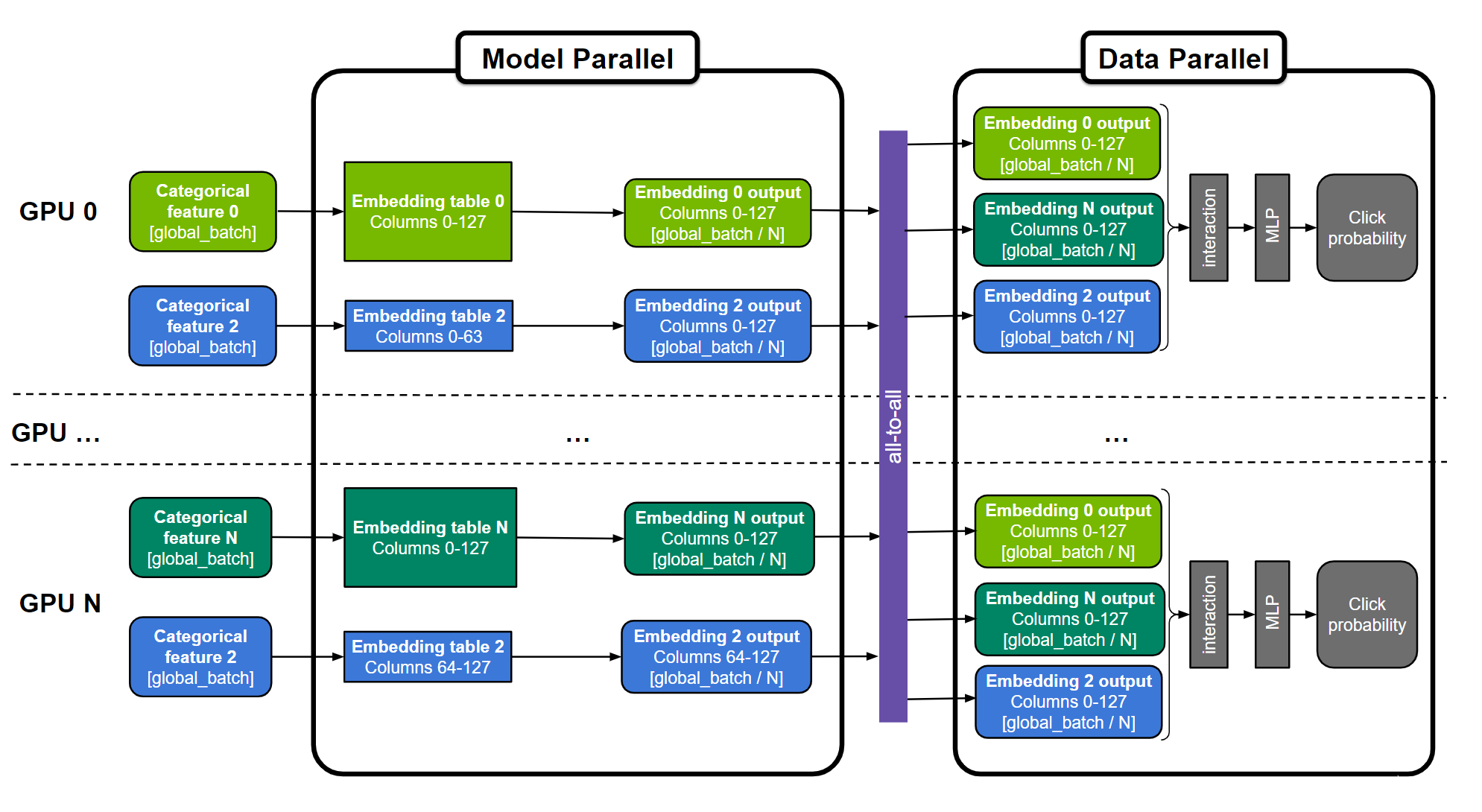
圖 1.用于訓練大型推薦系統的通用“混合并行”方法
嵌入表可以分為“表方式”(例如,嵌入表 0 和 N )、“列方式”(例如嵌入表 2 )或“行方式”。跨所有 GPU 復制 MLP 層。數字特征可以直接輸入 MLP 層,并且在圖中未示出。
然而,實現這種復雜的混合并行訓練方法并不簡單,需要領域專家設計幾百行低級代碼來開發和優化訓練。
為了使其更廣泛地使用 NVIDIA Merlin 分布式嵌入 該庫提供了一個易于使用的包裝器,只需三行 Python 代碼即可在 TensorFlow 2 中民主化模型并行性。它提供了一個可伸縮的模型并行包裝器 分發嵌入表 除了一些 高效嵌入操作 這涵蓋并擴展了 TensorFlow 的嵌入功能。下面是它如何實現混合并行。
分布式并行模型
NVIDIA Merlin 分布式嵌入提供了 distributed_embeddings.dist_model_parallel 單元。它有助于在多個 GPU 工作者之間分發嵌入,而無需任何復雜的代碼來處理與原語的跨工作者通信,如 all2all 下面的代碼示例顯示了此 API 的用法:
import dist_model_parallel as dmp class MyEmbeddingModel(tf.keras.Model): def __init__(self, table_sizes): ... self.embedding_layers = [tf.keras.layers.Embedding(input_dim, output_dim) for input_dim, output_dim in table_sizes] # 1. Add this line to wrap list of embedding layers used in the model self.embedding_layers = dmp.DistributedEmbedding(self.embedding_layers) def call(self, inputs): # embedding_outputs = [e(i) for e, i in zip(self.embedding_layers, inputs)] embedding_outputs = self.embedding_layers(inputs) ...
要使用 Horovod 以數據并行方式運行密集層,請替換Horovod’sDistributed GradientTape和broadcast方法及其在分布式嵌入中的等效。以下示例直接取自 Horovod 文檔,并進行了相應修改。
@tf.function def training_step(inputs, labels, first_batch): with tf.GradientTape() as tape: probs = model(inputs) loss_value = loss(labels, probs) # 2. Change Horovod Gradient Tape to dmp tape # tape = hvd.DistributedGradientTape(tape) tape = dmp.DistributedGradientTape(tape) grads = tape.gradient(loss_value, model.trainable_variables) opt.apply_gradients(zip(grads, model.trainable_variables)) if first_batch: # 3. Change Horovod broadcast_variables to dmp's # hvd.broadcast_variables(model.variables, root_rank=0) dmp.broadcast_variables(model.variables, root_rank=0) return loss_value
通過這些微小的改變,您就可以使用混合并行訓練步驟了!
我們還提供了以下完整示例: 使用 Criteo 1TB 點擊日志數據訓練 DLRM 模型 以及 合成數據 這將模型尺寸擴展到 22.8 TiB 。
性能
為了證明使用 NVIDIA Merlin 分布式嵌入的好處,我們展示了在 Criteo 1TB 數據集上訓練的 DLRM 模型的基準測試,以及各種具有多達 3 個 TiB 嵌入表大小的合成模型。
Criteo 數據集上的 DLRM 基準
基準測試表明,我們使用更簡單的 API 保持了類似于專家工程代碼的性能。這個 NVIDIA 深度學習示例 DLRM 使用 TensorFlow 2 的代碼現在也已更新,以利用 NVIDIA Merlin 分布式嵌入的混合并行訓練。更多信息,請參閱我們之前的文章, 在 TensorFlow 2 中使用 100B +參數在 DGX A100 上訓練推薦系統 。
這個 基準 自述部分提供了對性能數字的更多了解。
具有 1130 億個參數( 421 個 GiB 模型大小)的 DLRM 模型在 Criteo TB 點擊日志 數據集,三種不同的硬件設置:
僅 CPU 的解決方案。
單 – GPU 解決方案,其中 CPU 內存用于存儲最大的嵌入表。
使用 NVIDIA DGX A100-80GB 和 8 GPU 的混合并行解決方案。這利用了 NVIDIA Merlin 分布式嵌入提供的模型并行包裝器和嵌入 API 。

我們觀察到, DGX-A100 上的分布式嵌入解決方案比僅使用 CPU 的解決方案提供了驚人的 683 倍的加速!我們還注意到,與單一 GPU 解決方案相比,性能有了顯著改善。這是因為在 GPU 內存中保留所有嵌入消除了通過 CPU-GPU 接口嵌入查找的開銷。
綜合模型基準
為了進一步演示解決方案的可伸縮性,我們創建了不同大小的合成 DLRM 模型(表 2 )。

每個合成模型使用一個或多個 DGX-A100-80GB 節點進行訓練,全局批量大小為 65536 ,并使用 Adagrad 優化器。從表 3 中可以看出, NVIDIA Merlin 分布式嵌入可以在數百 GPU 上輕松訓練 TB 級模型。

另一方面,與傳統的數據并行相比,即使對于可以容納在單個 GPU 中的模型,分布式嵌入的模型并行仍然提供了多 GPU 的顯著加速。這如表 4 所示,其中一個微型模型在 DGX A100-80GB 上運行。

本實驗使用了 65536 的全局批量和 Adagrad 優化器。
結論
在這篇文章中,我們介紹了 NVIDIA Merlin 分布式嵌入庫,僅需幾行代碼即可在 NVIDIA GPU 上實現基于嵌入的深度學習模型的可擴展和高效模型并行訓練。
關于作者
Shashank Verma 是 NVIDIA 的一名深入學習的技術營銷工程師。他負責開發和展示各種深度學習框架中以開發人員為中心的內容。他從威斯康星大學麥迪遜分校獲得電氣工程碩士學位,在那里他專注于計算機視覺、數據科學的安全方面和 HPC 。
Wenwen Gao 是 NVIDIA Merlin 的高級產品經理,擁有 Amazon 和其他技術公司的產品管理經驗,專注于個性化和推薦。她擁有多倫多大學計算機科學學士學位和麻省理工學院斯隆管理學院工商管理碩士學位。
Hao Wu 是 NVIDIA 的高級 GPU 計算架構師。他在完成博士學位后于 2011 年加入 NVIDIA 計算架構組。在中國科學院。近年來, Hao 的技術重點是將低精度應用于深度神經網絡訓練和推理。
Deyu Fu 是 NVIDIA 深度學習框架團隊的高級開發技術工程師,負責加速軟件堆棧 CUDA 內核、數學、通信、框架和模型的 DL 培訓工作。他最近專注于 NVIDIA Merlin 分布式嵌入和推薦系統。
Tomasz Grel 是一名深度學習工程師。在NVIDIA ,他專注于確保眾多推薦系統的質量和執行速度,包括 NCF 、 VAE-CF 和 DLRM 。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5076瀏覽量
103728 -
gpu
+關注
關注
28文章
4777瀏覽量
129360 -
深度學習
+關注
關注
73文章
5515瀏覽量
121553
發布評論請先 登錄
相關推薦
分布式軟件系統
LED分布式恒流原理
使用分布式I/O進行實時部署系統的設計
基于分布式調用鏈監控技術的全息排查功能
如何設計分布式干擾系統?
分布式系統的優勢是什么?
HarmonyOS分布式數據庫,為啥這么牛?
在分布式嵌入式系統的過程中利用Jini技術有什么優勢?
【木棉花】:簡單的分布式任務調度
如何高效完成HarmonyOS分布式應用測試?
分布式電源分布式電源裝置是指什么?有何特點
快速在線分布式對偶平均優化算法
基于Jini互聯技術實現分布式嵌入式系統的設計

如何使用NVIDIA Merlin推薦系統框架實現嵌入優化





 工商網監
工商網監
評論