 借助機器翻譯來生成偽視覺-目標語言對進行跨語言遷移
借助機器翻譯來生成偽視覺-目標語言對進行跨語言遷移
雖然目前傳統的跨模態檢索工作已取得了巨大的進展,但由于缺少低資源語言的標注數據,這些工作通常關注于高資源語言(比如英語),因此極大地限制了低資源語言在該領域的發展。
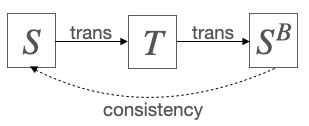
為了解決這一問題,作者針對跨語言跨模態檢索任務(CCR)展開了研究,該任務旨在僅使用人工標注的視覺-源語言(如英語)語料庫對模型進行訓練,使其可以適用于其他目標語言(非英語)進行評估【如下圖所示】。
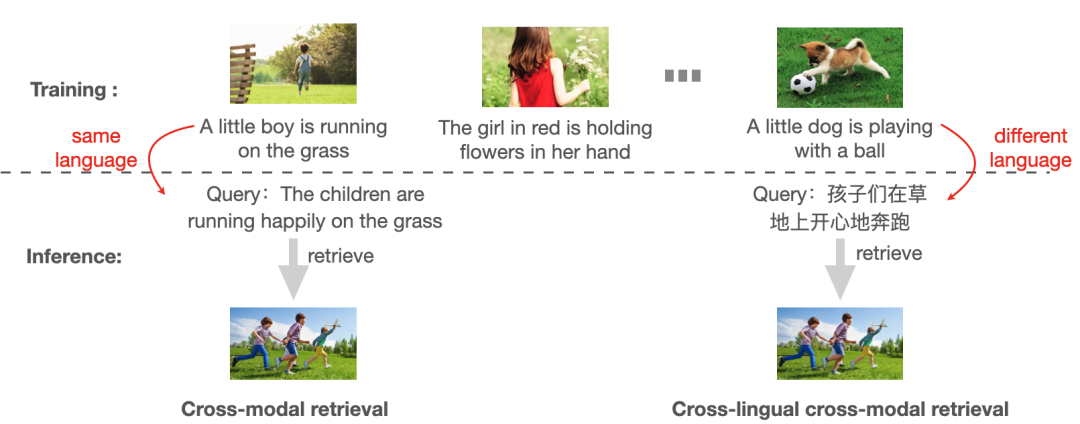
傳統跨模態檢索&跨語言跨模態檢索(CCR)
在這篇論文中,作者旨在借助機器翻譯來生成偽視覺-目標語言對進行跨語言遷移,來緩解人工標注多語言視覺-語言語料庫困難的問題。雖然機器翻譯可以快速的處理大量的文本語言轉換,但是其準確性并不能得到保證,因此在翻譯過程中將會引入大量的噪聲,導致翻譯的目標語言句子并不能準確的描述其對應的視覺內容【如下圖所示】。

然而之前的基于機器翻譯的CCR工作大多忽略了這個問題,它們通常使用大規模的預訓練模型在通過機器翻譯得到的大規模多語言視覺-語言語料庫上進行大規模預訓練,并且只關注于視覺-目標語言數據對之間的對齊。然而直接在這種噪聲數據對上應用跨模態匹配將會嚴重影響檢索性能,神經網絡模型有很強的能力來擬合這種給定的(噪聲)數據。
為了解決這個問題,作者提出了一個噪聲魯棒學習方法來緩解機器翻譯中所引入的噪聲問題,該論文是首個關注于CCR任務中由機器翻譯所引入噪聲問題的工作。
方法
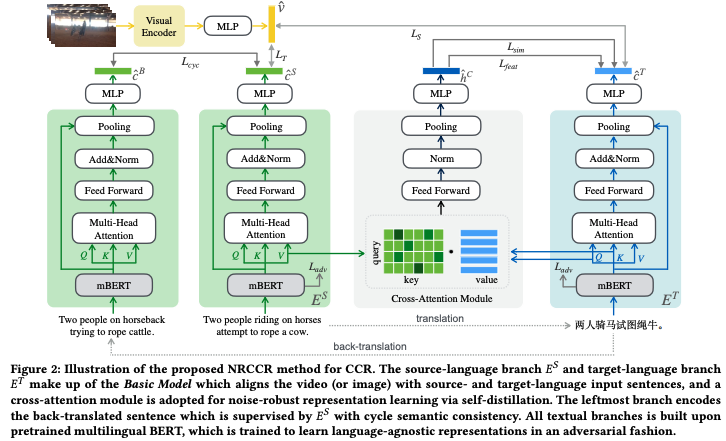
模型框架圖
作者首先先引入了其「基線模型」
基線模型
視覺編碼器:給定一個視頻,使用預訓練的2D CNN來提取視頻特征序列,然后輸入到Transformer塊中,來增強幀間交互,最終得到一個視頻特征向量
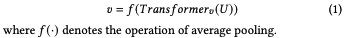
文本編碼器:作者設計了一個雙分支編碼器,分別又一個源語言分支和一個目標語言分支組成。每個語言分支都包含一個Transformer block 和一個預訓練的mBERT backbone,將源語言和目標語言分別輸入到對應的分支中,得到對應的源語言句子特征和目標語言句子特征
將以上三個特征分別映射到多語言多模態空間中
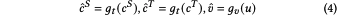
作者使用了傳統的跨模態檢索任務中常用的triplet ranking loss進行約束:
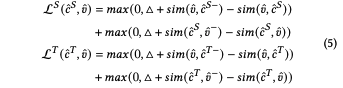
噪聲魯棒的特征學習
基線模型只是簡單的進行了跨語言跨模態對齊,并沒有對噪聲進行處理,接下來作者提出了多視圖自蒸餾來生成pseudo-tagets以監督目標語言分支的學習
作者首先借助于cross-attention來生成一個相對干凈的中間目標語言句子特征,通過將源語言token序列作為query,利用cross-attenion固有的性質,對目標語言token序列進行過濾。
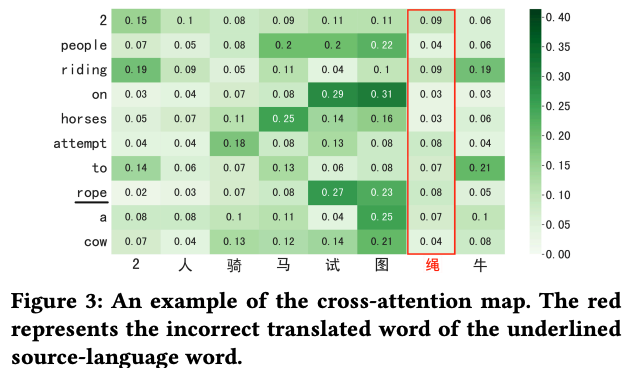
cross-attention權重示例圖
如圖3所示,錯誤的單詞(用紅色標記)和源語言單詞之間的注意權重被分配了低值。其過程表示如下:
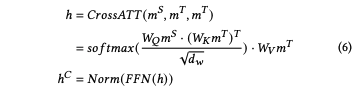
多視角自蒸餾
作者引入了基于相似度視角和基于特征視角的自蒸餾損失
基于相似度視角的自蒸餾(Similarity-based view):
給定(V, S, T),默認其兩兩之間互為匹配對,忽視翻譯得到的目標語言句子T中所包含噪聲的事實。對此,作者將cross-attention所生成的特征作為teacher,使用特征和視覺特征計算計算得到一個soft pseudo-targets作為目標語言分支的監督
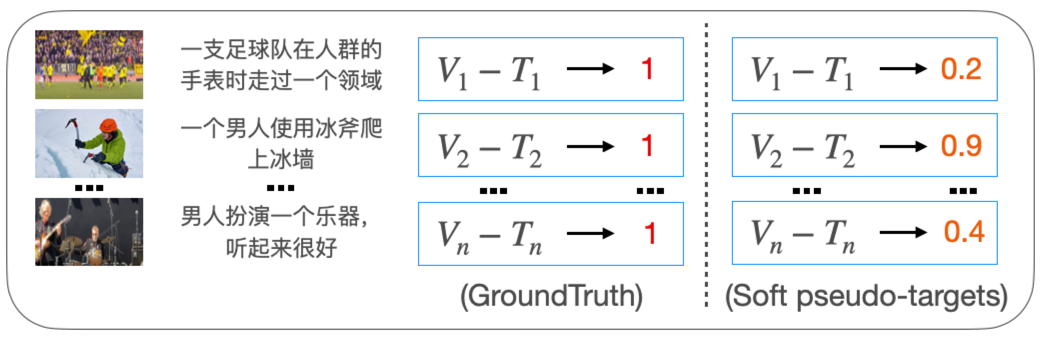
soft pseudo-targets示例圖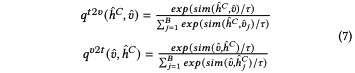
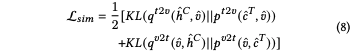
基于特征視角的自蒸餾(Feature-based view):
通過l1范式實現特征蒸餾
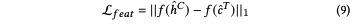
循環語義一致性
受無監督機器翻譯的啟發,作者引入了循環語義一致性模塊,提高源語言分支從噪聲中提高原始語義信息的能力。增加源語言分支的魯棒性。
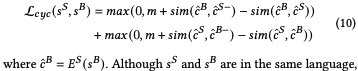
語言無關特征學習
考慮到特定語言特征缺少跨語言遷移能力,作者通過對抗學習的方式來訓練模型學習語言無關特征。構建一個分類器F作為判別器來分辨輸入特征是源語言還是目標語言,判別器和特征編碼器相互博弈:
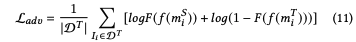
訓練和測試
最終的目標函數為:
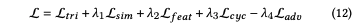
測試時作者采用了目標語言和翻譯的源語言(由于測試時只使用目標語言)加權和的方式:
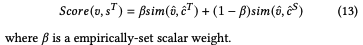
實驗
作者在三個跨語言跨模態數據集上進行了實驗對比,其中為兩個多語言視頻文本檢索數據集(VATEX和MSRVTT-CN),一個多語言圖像文本檢索(Multi30K);其中MSRVTT-CN是作者對MSRVTT進行中文擴展得到的多語言數據集
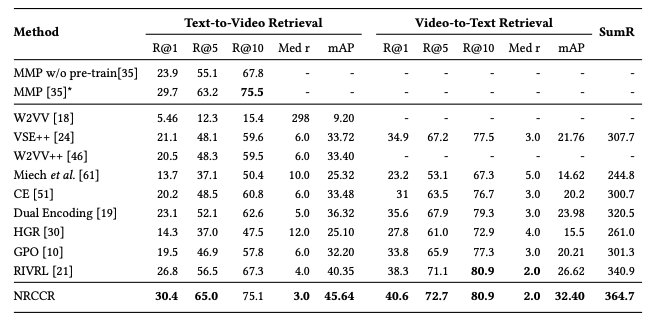
在VATEX數據集上進行SOTA對比實驗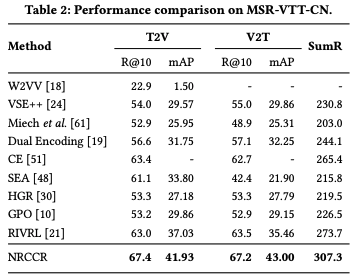
MSRVTT-CN上性能對比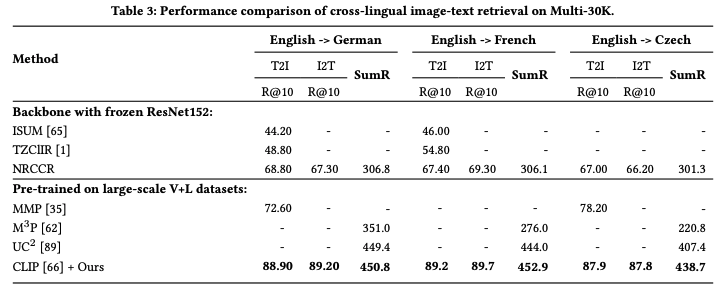
Multi30K上進行性能對比實驗
魯棒分析實驗
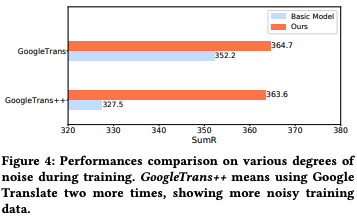
為了進一步證明模型對抗翻譯噪聲的魯棒能力,作者通過增加翻譯次數以進一步增加訓練數據的噪聲程度,如圖所示,在經過多次翻譯后,基線模型的性能明顯下降,而本文所提出的模型性能更加的穩定,驗證了噪聲魯棒特征學習的有效性
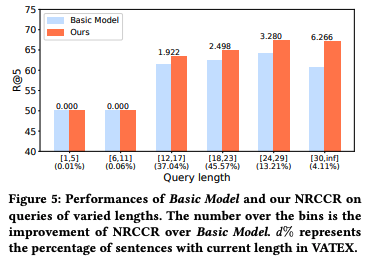
將目標語言句子根據句子長度進行分組,作者假設越長的句子,翻譯越困難,因此包含的噪聲可能更多。結果表明,本文所提出的模型和基線模型的性能差距隨著句子長度的增加而增加。
t-SNE可視化實驗
作者隨機從VATEX的中文測試集中隨機選擇20個樣本,其中每個樣本包含10個對應的英語翻譯句子和一個對應的視頻。如圖所示,NRCCR的類內特征更加的緊湊,表明了模型更好的學習到了跨語言跨模態對齊。

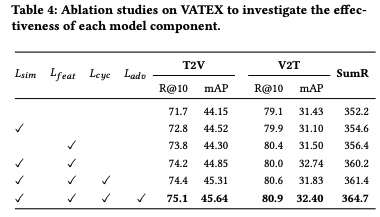
消融實驗
結果表明,使用兩個視角,性能得到了提升,表明基于相似度視角和基于特征視角彼此互補。引入循環語義一致性后,實現了額外的性能收益。此外,還表明了語言無關特征學習的重要性
審核編輯:劉清
-
編碼器
+關注
關注
45文章
3667瀏覽量
135237 -
C語言
+關注
關注
180文章
7614瀏覽量
137703
原文標題:ACMMM 2022 | 首個針對跨語言跨模態檢索的噪聲魯棒研究工作
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于機器翻譯增加的跨語言機器閱讀理解算法
機器翻譯三大核心技術原理 | AI知識科普 2
神經機器翻譯的方法有哪些?
基于淺層句法信息的翻譯實例獲取方法研究
淺談人工智能中語言和機器翻譯的重要性
機器翻譯系統實現了自然語言處理的又一里程碑突破

RNN基本原理和RNN種類與實例
Facebook的AI翻譯系統能翻譯100種語言!
人工智能翻譯mRASP:可翻譯32種語言
多語言翻譯新范式的工作:機器翻譯界的BERT
大語言模型的多語言機器翻譯能力分析

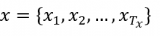





 工商網監
工商網監
評論