 GAT模型如何來編碼依存關系
GAT模型如何來編碼依存關系
本文貢獻有如下兩點:
提出了一個面向方面的樹結構,通過重塑和修剪普通的依存樹來關注目標方面。
提出了一個新的GAT模型來編碼依存關系,建立方面和意見詞之間的聯系。
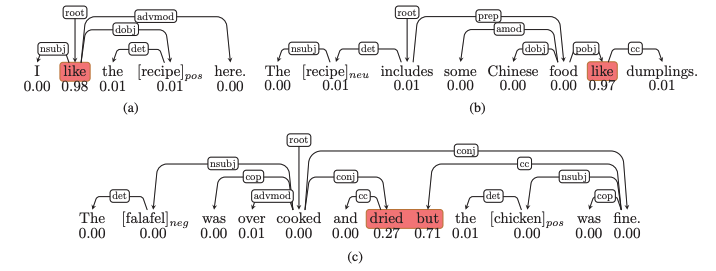
餐廳評論中的三個例子來說明 ABSA 中方面aspect、注意力和句法之間的關系。Labeled edges表示依存關系,每個單詞下的分數表示由LSTM分配注意力權重。具有高注意力權重的詞在「紅色框」中突出顯示,括號中的詞是目標方面target aspect,后面是它們的情感標簽。
面向方面的樹的構建
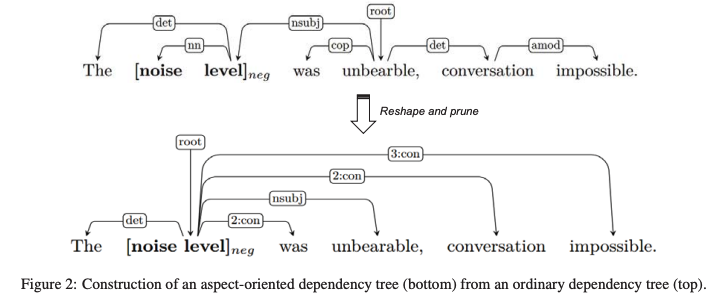
輸入:原來的解析結果以及句子和方面。(原文有偽代碼)
「第一步」 將目標方面放在根節點
「第二步」 我們將與方面有直接連接的節點設置為子節點,保留原始的依存關系
「第三步」 舍棄了其他的依存關系,取而代之的是一個從aspect到每個對應節點的虛擬關系n:con,其中n表示兩個節點之間的距離。
注意 如果句子包含多個方面,我們為每個方面構建一個唯一的樹。
根據是前人研究證明只關注在語法上接近目標方面的一小部分上下文詞就足夠了。好處是每個方面都有自己的依存樹,可以減少不相關節點和關系的影響,同時這種統一的樹結構不僅使模型專注于方面和情感詞之間的聯系,而且在訓練過程中便于批量操作和并行操作。
R-GAT
為了對上述樹進行編碼,在GAT的基礎上提出了一個新的R-GAT:relation graph attention network
GAT實現的是:
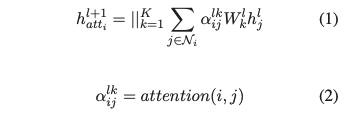
每個結點只對鄰居結點進行注意力計算權重。這個得到的是。注意 表明一共使用了個做轉換矩陣,最后將它們得到的結果拼接到一起。
作者認為沒有考慮到和相鄰接點的依存關系是存在不同的,不可以用同樣方法去計算。因此引入了考慮不同的依存關系的R-GAT來補充信息。大致的思想相同,只是對于(1)中的有考慮進新的信息,也就是不同的依存關系。
「R-GAT」:
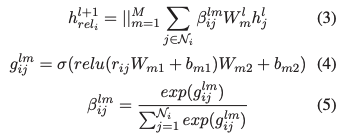 作者將各種依存關系映射到嵌入中,結點i和結點j之間的就是
作者將各種依存關系映射到嵌入中,結點i和結點j之間的就是
也就是先將依存關系經過兩層線性層,然后對一個結點的所有邊的結果歸一化,變成對應的系數。
整個網絡結構
結構很簡單如下:
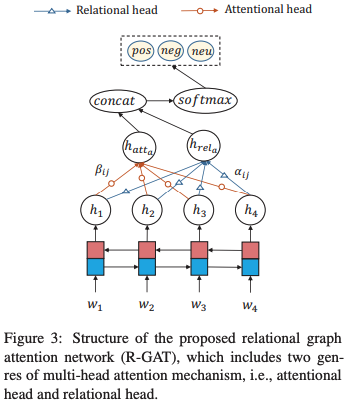
具體來說首先需要把句子的依存分析結果通過變換得到面向方面的數,這個結果將參與后續的圖編碼。
「第一步」,將句子的詞嵌入經過BiLSTM編碼得到,利用另一個BiLSTM編碼方面詞作為根節點嵌入的初始化。
「第二步」,利用GAT和R-GAT分別去處理h,得到和,注意相當于只用處理一個根節點。將得到的結果拼接到一起,再經過一個線性層就是該方面詞的表達。
「第三步」,softmax分類得到方面詞預測結果。
Loss Function
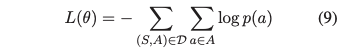
實驗和分析
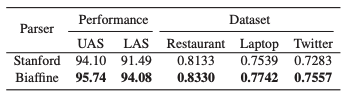
不同方法在三個數據集上的實驗: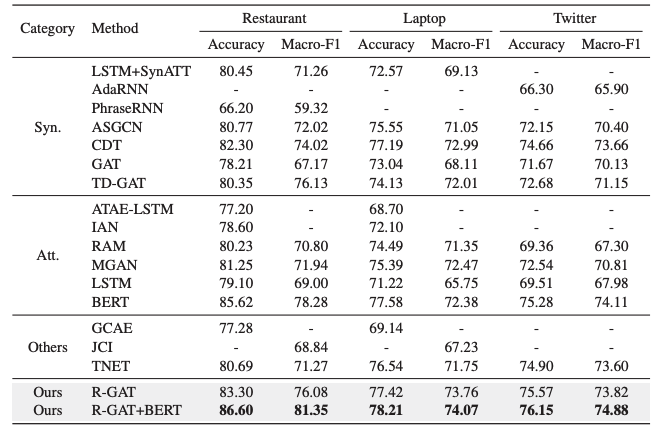
多方面分析結果,表明距離較近的方面往往導致準確度得分較低: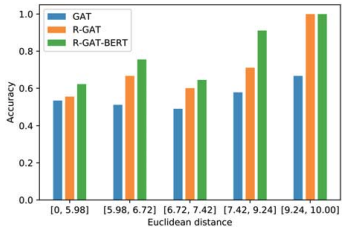
不用Parser的影響:
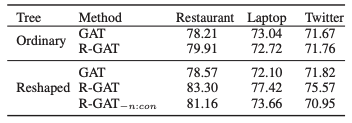
消融研究的結果,其中“Ordinary”表示使用普通依存樹,“Reshape”表示使用面向方面的樹,“*-n:con”表示不使用n:con的面向方面的樹:
R-GAT 和 R-GAT+BERT 對來自Restaurant數據集的 100 個錯誤分類示例的錯誤分析結果。原因分為四類,并給出了樣本。上表對應 R-GAT 的結果,下表對應 R-GAT+BERT:
-
編碼
+關注
關注
6文章
957瀏覽量
54954 -
模型
+關注
關注
1文章
3313瀏覽量
49231 -
GAT
+關注
關注
0文章
7瀏覽量
6360
原文標題:中山大學&阿里巴巴提出:用于基于Aspect的情感分析的關系圖注意網絡(GAT)
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
依存句法分析器的簡單實現
pyhanlp兩種依存句法分類器
基于CRF序列標注的中文依存句法分析器的Java實現
swi的功能號是如何來的?它和LR寄存器的值是何關系
swi的功能號是如何來的?它和LR寄存器的值是何關系?
聯柵晶體管(GAT)是什么意思?
儀表放大器(INA)偏移電壓與增益之間的關系
電力信息-物理相互依存網絡脆弱性評估

列表解釋關系模型
一種端到端的序列多任務法律判決預測模型






 工商網監
工商網監
評論