") 基于異常檢測的模型表現(xiàn)對(duì)比
基于異常檢測的模型表現(xiàn)對(duì)比
本文將從以下6個(gè)方面介紹:
異常分類
異常檢測的挑戰(zhàn)
異常檢測的模型分類
異常檢測的數(shù)據(jù)集
異常檢測的模型表現(xiàn)對(duì)比
結(jié)論和未來方向
一、異常分類
以前傳統(tǒng)關(guān)于異常檢測的分類如圖1(a)所示,分為:
●點(diǎn)異常值:相對(duì)于全局其他數(shù)據(jù)的異常實(shí)例。
●上下文異常值:上下文異常值通常在它們自己的上下文中具有相對(duì)較大/較小的值,但不是全局的。
●集體異常值:被定義為相對(duì)于整個(gè)數(shù)據(jù)集異常的相關(guān)異常數(shù)據(jù)實(shí)例的集合。
但這種分類方式常因?yàn)樯舷挛亩x邊界模糊,導(dǎo)致集體異常值和上下文異常值的定義邊界也模糊。上下文異常值的上下文在不同文獻(xiàn)中通常非常不同。它們可以是一個(gè)小窗口,包含相鄰點(diǎn)或在季節(jié)性方面具有相似相對(duì)位置的點(diǎn)。比如圖2中的集體異常值,如果以季節(jié)性方面的上下文考慮,其實(shí)也能看做是上下文異常。
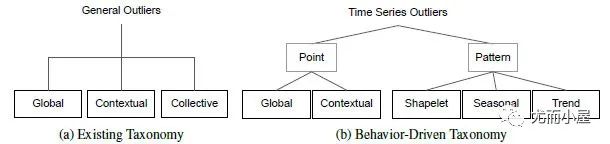 圖1:新舊異常分類對(duì)比
圖1:新舊異常分類對(duì)比
綜述[5]提出了新的異常分類法,如圖1(b)所示。具體的樣例如下:
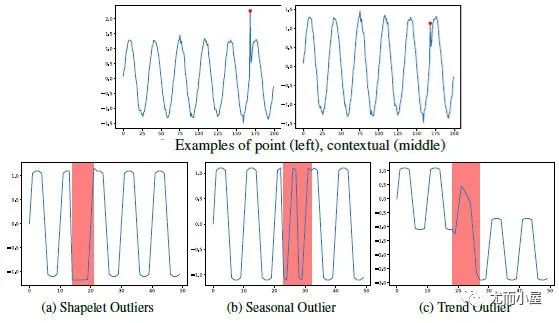 圖2:新異常分類下的數(shù)據(jù)樣例
圖2:新異常分類下的數(shù)據(jù)樣例
關(guān)于3類Pattern異常,可以基于shapelet函數(shù)來定義:其中, ,X是由多個(gè)不同
+頻率的波的值相加得到的。為趨勢項(xiàng),例如線性函數(shù) 。如果s為相似度度量函數(shù),那么以上3種異常類型可以分別定義為:
●shapelet outliers (異常的局部子序列): 。
●seasonal outliers (異常周期性的局部子序列): 。
●trend outliers (異常趨勢的局部子序列): 。
其中, 為異常判定的閾值。
二、異常檢測的挑戰(zhàn)
綜述[4]介紹了深度異常檢測解決的主要挑戰(zhàn):
●CH1:異常檢測召回率低。由于異常非常罕見且異質(zhì),因此很難識(shí)別所有異常。
●CH2:異常通常在低維空間中表現(xiàn)出明顯的異常特征,而在高維空間中變得隱藏且不明顯。
●CH3:正常/異常的數(shù)據(jù)高效學(xué)習(xí)。利用標(biāo)記數(shù)據(jù)來學(xué)習(xí)正常/異常的表征,對(duì)于準(zhǔn)確的異常檢測至關(guān)重要。
●CH4:抗噪異常檢測。許多弱/半監(jiān)督異常檢測方法假設(shè)標(biāo)記的訓(xùn)練數(shù)據(jù)是干凈的,這可能容易受到被錯(cuò)誤標(biāo)記為相反類別標(biāo)簽的噪聲實(shí)例的影響。
●CH5:復(fù)雜異常的檢測。現(xiàn)有的大多數(shù)方法都是針對(duì)點(diǎn)異常的,不能用于條件異常和組異常,因?yàn)樗鼈儽憩F(xiàn)出與點(diǎn)異常完全不同的行為。
●CH6:異常解釋。在許多安全關(guān)鍵領(lǐng)域中,如果將異常檢測模型直接用作黑盒模型,則可能存在一些重大風(fēng)險(xiǎn)。
圖3展示了傳統(tǒng)方法和深度方法在不同能力上的區(qū)別,以及不同能力對(duì)解決哪些挑戰(zhàn)至關(guān)重要:
 圖3:傳統(tǒng)方法和深度方法的能力對(duì)比
圖3:傳統(tǒng)方法和深度方法的能力對(duì)比
具體到模型上的挑戰(zhàn),會(huì)在下面進(jìn)行詳細(xì)講解。
三、異常檢測的模型分類
不同綜述對(duì)時(shí)序異常檢測的模型分類方式也挺不同的,比如:
● 綜述[3]:分為統(tǒng)計(jì)方法,經(jīng)典機(jī)器學(xué)習(xí)方法和使用神經(jīng)網(wǎng)絡(luò)的異常檢測方法。
● 綜述[5]:分為基于預(yù)測偏差的方法,基于時(shí)序表征分類的方法,基于子序列不一致性分析的方法。
● 綜述[4]:針對(duì)神經(jīng)網(wǎng)絡(luò)算法,分為特征提取的方法,學(xué)習(xí)常態(tài)特征表征的方法,端對(duì)端學(xué)習(xí)異常分?jǐn)?shù)的方法。
我總結(jié)如下:
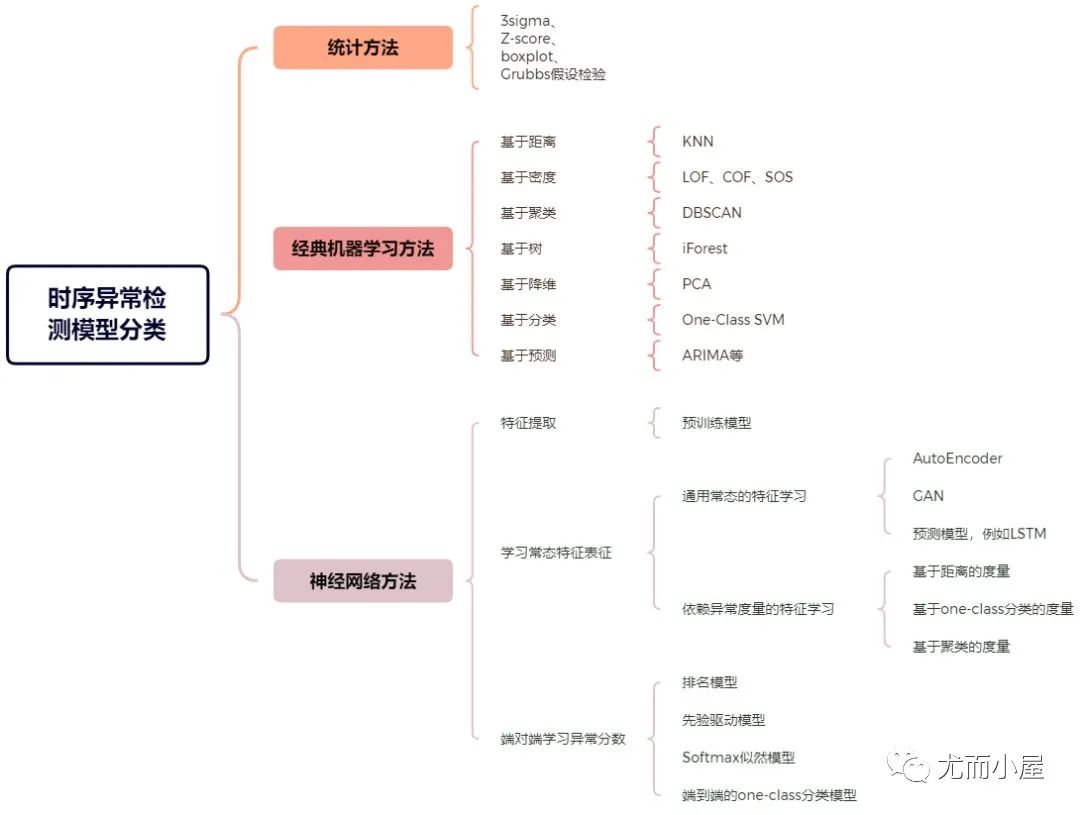 圖4:時(shí)序異常檢測的模型分類
圖4:時(shí)序異常檢測的模型分類
在之前的文章里,統(tǒng)計(jì)方法和經(jīng)典機(jī)器學(xué)習(xí)的方法基本都已經(jīng)介紹過了,這邊就不重復(fù)介紹了。
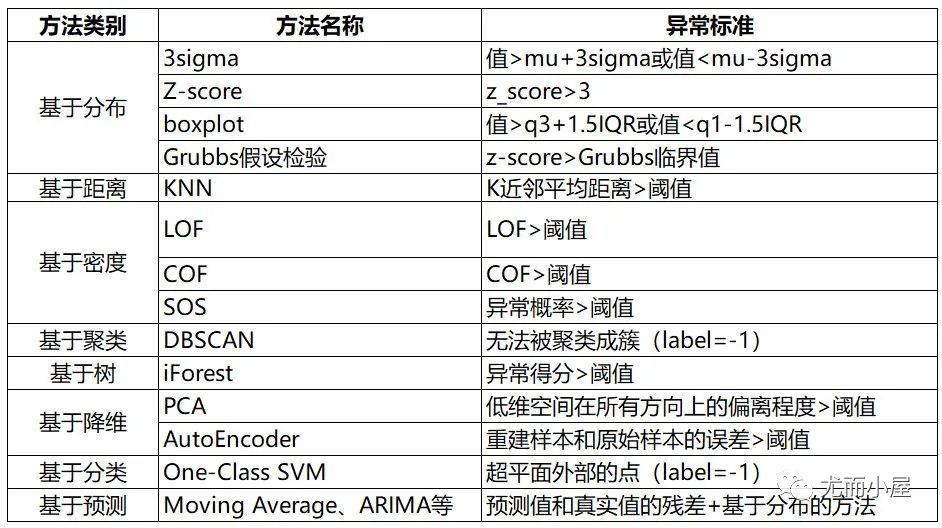 圖5:統(tǒng)計(jì)方法和經(jīng)典機(jī)器學(xué)習(xí)的方法總結(jié)
圖5:統(tǒng)計(jì)方法和經(jīng)典機(jī)器學(xué)習(xí)的方法總結(jié)
這里,主要基于綜述[4],介紹下神經(jīng)網(wǎng)絡(luò)下的模型分類,其實(shí)zero在知乎已經(jīng)整理了這篇綜述內(nèi)容,寫的很好,強(qiáng)烈建議閱讀文章[6]。
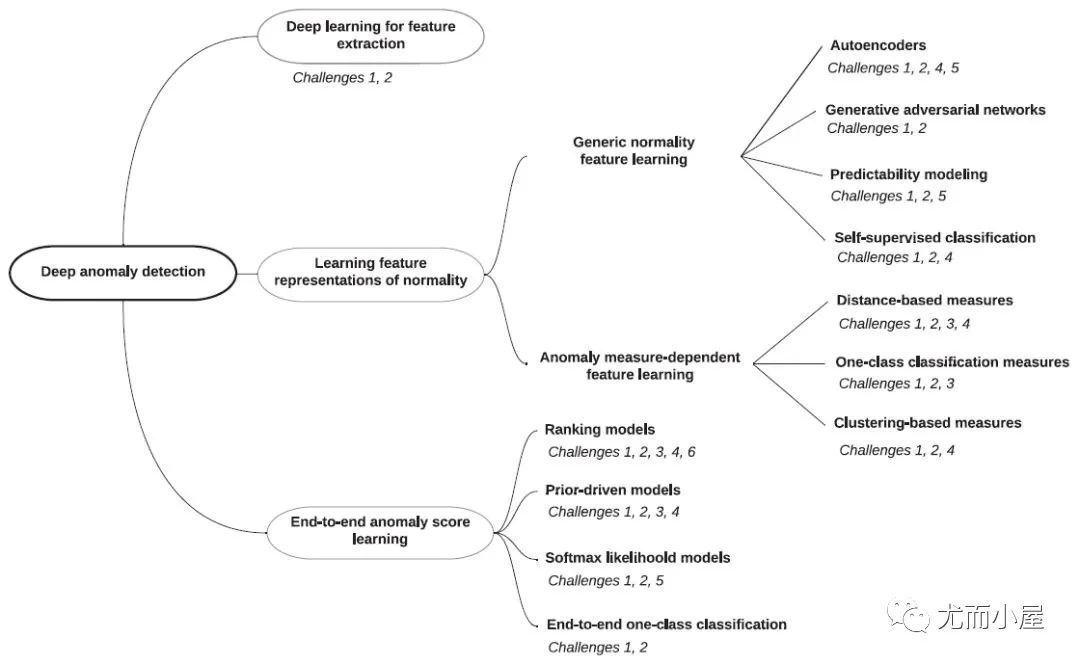 圖6:神經(jīng)網(wǎng)絡(luò)異常檢測方法分類
圖6:神經(jīng)網(wǎng)絡(luò)異常檢測方法分類
神經(jīng)網(wǎng)絡(luò)下的模型分類如下:
1. 特征提取:deep learning和anomaly detection是分開的,deep learning只負(fù)責(zé)特征提取。
2. 常態(tài)特征表征學(xué)習(xí):deep learning和anomaly detection是相互依賴的,一起學(xué)習(xí)正常樣本的有效表征。
●通用常態(tài)特征表征學(xué)習(xí):這類方法最優(yōu)化一個(gè)特征學(xué)習(xí)目標(biāo)函數(shù),該函數(shù)不是為異常檢測而設(shè)計(jì)的,但學(xué)習(xí)到的高級(jí)特征能夠用于異常檢測,因?yàn)檫@些高級(jí)特征包含了數(shù)據(jù)的隱藏規(guī)律。
●依賴異常度量的特征表征學(xué)習(xí):該類方法直接將現(xiàn)有的異常評(píng)價(jià)指標(biāo)嵌入表征學(xué)習(xí)的優(yōu)化目標(biāo)中。
3. 端對(duì)端異常分?jǐn)?shù)學(xué)習(xí):deep learning和anomaly detection是完全一體的,通過端到端的學(xué)習(xí),直接輸出異常分?jǐn)?shù)。
1. 特征提取
旨在利用深度學(xué)習(xí)從高維和/或非線性可分離數(shù)據(jù)中提取低維特征表征,用于下游異常檢測。特征提取和異常評(píng)分完全不相交且彼此獨(dú)立。因此,深度學(xué)習(xí)組件僅作為降維工作。
優(yōu)點(diǎn):
● 很容易獲得大量先進(jìn)的預(yù)訓(xùn)練深度模型和現(xiàn)成的異常檢測器做特征提取和異常檢測;
● 深度特征提取比傳統(tǒng)線性方法更有效。
缺點(diǎn):
● 特征提取和異常評(píng)分是獨(dú)立分開的,通常會(huì)導(dǎo)致次優(yōu)的異常評(píng)分;
● 預(yù)訓(xùn)練的深度模型通常僅限于特定類型的數(shù)據(jù)。(感覺更適用于圖像,因?yàn)閳D像可以做分類預(yù)訓(xùn)練,個(gè)人對(duì)時(shí)序預(yù)訓(xùn)練了解的不是很多)。
2. 通用常態(tài)特征表征學(xué)習(xí)
這類方法最優(yōu)化一個(gè)特征學(xué)習(xí)目標(biāo)函數(shù),該函數(shù)不是為異常檢測而設(shè)計(jì)的。
但學(xué)習(xí)到的高級(jí)特征能夠用于異常檢測,因?yàn)檫@些高級(jí)特征包含了數(shù)據(jù)的隱藏規(guī)律。例如:AutoEncoder、GAN、預(yù)測模型。
優(yōu)點(diǎn):
● AE:方法簡單,可用不同AE變種;
● GAN:產(chǎn)生正常樣本的能力很強(qiáng),而產(chǎn)生異常樣本的能力就很弱,因此有利于進(jìn)行異常檢測;
● 預(yù)測模型:存在大量序列預(yù)測模型,能學(xué)到時(shí)間和空間的依賴性。
缺點(diǎn):
● AE:學(xué)習(xí)到的特征表征可能會(huì)因?yàn)椤坝?xùn)練數(shù)據(jù)中不常見的規(guī)律、異常值或噪聲“而產(chǎn)生偏差;
● GAN:訓(xùn)練可能存在多種問題,比如難以收斂,模式坍塌。因此,基于異常檢測的 GANs 訓(xùn)練或難以進(jìn)行;
● 預(yù)測模型:序列預(yù)測的計(jì)算成本高。
另外,以上方法都有兩個(gè)共性問題:
●都假設(shè)訓(xùn)練集是正常樣本,但若訓(xùn)練集中混入噪聲或異常值,會(huì)給模型表征學(xué)習(xí)能力帶來偏差;
●沒有將異常評(píng)價(jià)納入到模型優(yōu)化的目標(biāo)當(dāng)中,最后檢測的結(jié)果可能是次優(yōu)的。
3. 依賴異常度量的特征表征學(xué)習(xí)
該類方法直接將現(xiàn)有的異常評(píng)價(jià)指標(biāo)嵌入表征學(xué)習(xí)的優(yōu)化目標(biāo)中,解決了通用常態(tài)特征表征學(xué)習(xí)中第二個(gè)共性問題。例如Deep one-class SVM,Deep one-class Support Vector Data Description (Deep one-class SVDD)等。
優(yōu)化:
● 基于距離的度量:比起傳統(tǒng)方法,能處理高維空間數(shù)據(jù),有豐富的理論支持;
● 基于one-class分類的度量:表征學(xué)習(xí)和one-class模型能一起學(xué)習(xí)更好的特征表示,同時(shí)免于手動(dòng)選擇核函數(shù);
● 基于聚類的度量:對(duì)于復(fù)雜數(shù)據(jù),可以讓聚類方法在深度專門優(yōu)化后的表征空間內(nèi)檢測異常點(diǎn)。
缺點(diǎn):
● 基于距離的度量:計(jì)算量大;
● 基于one-class分類的度量:在正常類內(nèi)分布復(fù)雜的數(shù)據(jù)集上,該模型可能會(huì)無效;
● 基于聚類的度量:模型的表現(xiàn)嚴(yán)重依賴于聚類結(jié)果。也受污染數(shù)據(jù)的影響。
以上缺點(diǎn)在于:沒辦法直接輸出異常分?jǐn)?shù)。
3. 端對(duì)端異常分?jǐn)?shù)學(xué)習(xí)
通過端到端的學(xué)習(xí),直接輸出異常分?jǐn)?shù)。個(gè)人對(duì)這部分的了解是一片空白,只能初略轉(zhuǎn)述下綜述中的內(nèi)容,有興趣的朋友可以閱讀原文跟進(jìn)相關(guān)工作。
優(yōu)點(diǎn):
● 排名模型:利用了排序理論;
● 先驗(yàn)驅(qū)動(dòng)模型:將不同的先驗(yàn)分布嵌入到模型中,并提供更多解釋性;
● Softmax似然模型:可以捕捉異常的特征交互信息;
● 端到端的one-class分類模型:端到端式的對(duì)抗式優(yōu)化,GAN有豐富的理論和實(shí)踐支持。
缺點(diǎn):
● 排名模型:訓(xùn)練數(shù)據(jù)中必須要有異常樣本;
● 先驗(yàn)驅(qū)動(dòng)模型:沒法設(shè)計(jì)一個(gè)普遍有效的先驗(yàn),若先驗(yàn)分布不能很好地?cái)M合真實(shí)分布,模型的效果可能會(huì)變差;
● Softmax似然模型:特征交互的計(jì)算成本很大,而且模型依賴負(fù)樣本的質(zhì)量;
● 端到端的one-class分類模型:GAN具有不穩(wěn)定性,且僅限于半監(jiān)督異常檢測場景。
深度相關(guān)的30個(gè)代表性模型:
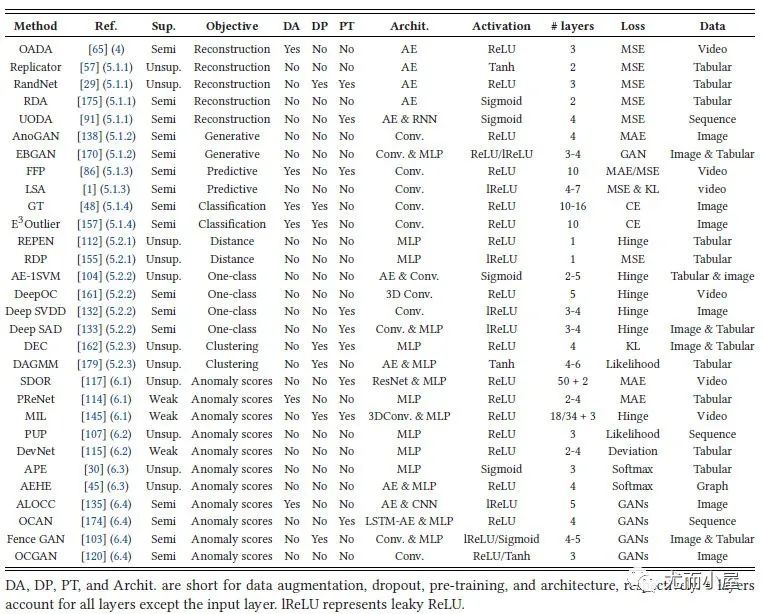 圖7:30個(gè)代表性的深度模型
圖7:30個(gè)代表性的深度模型
四、異常檢測的數(shù)據(jù)集
SEQ:[5]中提出基于shapelet函數(shù),我們可以獲取35個(gè)合成數(shù)據(jù)集(可稱NeurlIPS-TS synthestic datasets or SEQ),其中20個(gè)單變量,15個(gè)多變量數(shù)據(jù)集。該數(shù)據(jù)集覆蓋各類異常數(shù)據(jù)。
21個(gè)開源真實(shí)數(shù)據(jù)集:
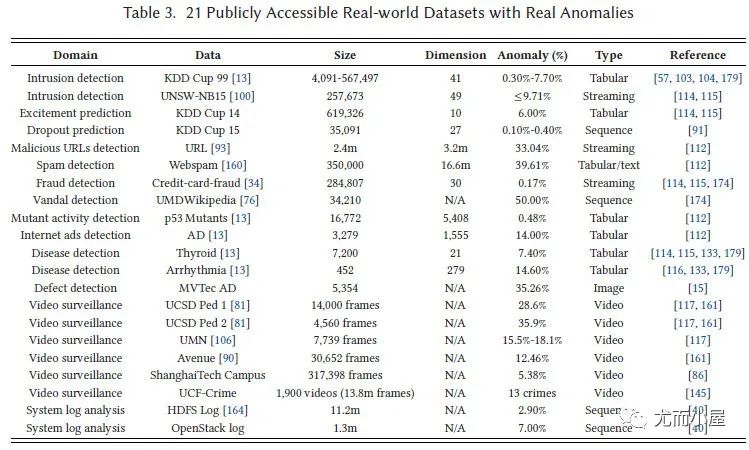 圖8:21個(gè)開源真實(shí)數(shù)據(jù)集[4]
圖8:21個(gè)開源真實(shí)數(shù)據(jù)集[4]
五、異常檢測的模型表現(xiàn)對(duì)比
各類綜述論文下的模型表現(xiàn),因?yàn)樗脭?shù)據(jù)集,參數(shù)或后處理不一致,導(dǎo)致表現(xiàn)對(duì)比可能存在差異,這里僅供參考。
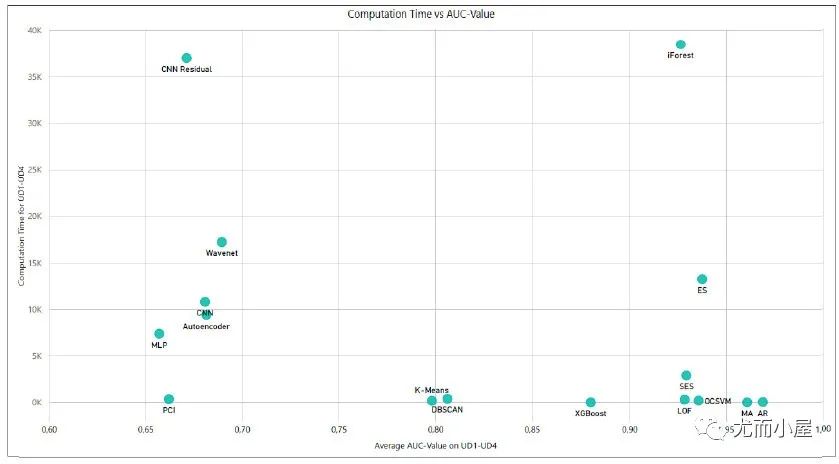 圖9:在UD1-UD4數(shù)據(jù)集上個(gè)模型AUC和計(jì)算時(shí)間的對(duì)比[3]
圖9:在UD1-UD4數(shù)據(jù)集上個(gè)模型AUC和計(jì)算時(shí)間的對(duì)比[3] 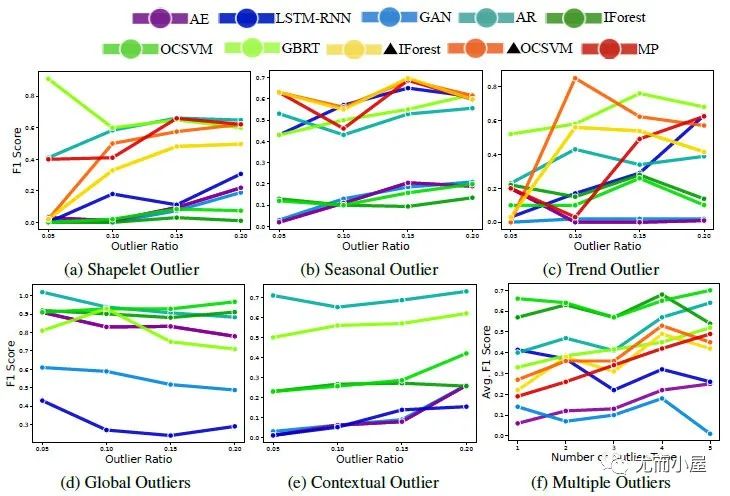 圖10:在合成數(shù)據(jù)SEQ上的模型表現(xiàn)[5]
圖10:在合成數(shù)據(jù)SEQ上的模型表現(xiàn)[5]
圖10很明顯打臉了一眾深度模型,我們不可否認(rèn)實(shí)際業(yè)務(wù)場景中,深度模型性能的不穩(wěn)定,傳統(tǒng)模型確實(shí)更好用,但在學(xué)術(shù)圈里,深度模型還是有它研究價(jià)值在;
而有些深度異常檢測論文的F1分?jǐn)?shù)比圖10高,除了參數(shù)和數(shù)據(jù)問題,也可能是像Anomaly Transformer代碼Issue中很多人提到的類似“detection adjustment”后處理優(yōu)化的結(jié)果。所以這塊仁者見仁智者見智吧。
六、結(jié)論和未來方向
綜述[4]給出了未來異常檢測的結(jié)論和發(fā)展方向:
●把異常度量目標(biāo)加入到表征學(xué)習(xí)中:表征學(xué)習(xí)時(shí),一個(gè)關(guān)鍵問題是它們的目標(biāo)函數(shù)是通用的,但沒有專門針對(duì)異常檢測進(jìn)行優(yōu)化。在前面有提到依賴于異常度量的特征學(xué)習(xí),它便是通過施加來自傳統(tǒng)異常度量的約束,來幫助解決這個(gè)問題;
●探索少標(biāo)記樣本的利用:探索利用這些小標(biāo)記數(shù)據(jù)來學(xué)習(xí)更強(qiáng)大的檢測模型和更深層次架構(gòu);
●大規(guī)模無監(jiān)督/自監(jiān)督表示學(xué)習(xí):首先在無監(jiān)督/自監(jiān)督模式下從大規(guī)模未標(biāo)記數(shù)據(jù)中學(xué)習(xí)可遷移的預(yù)訓(xùn)練表示模型,然后在半監(jiān)督模式下微調(diào)異常檢測模型;
●復(fù)雜異常的深度檢測:對(duì)條件/組異常的深度模型的探索明顯較少。另外多模態(tài)異常檢測是一個(gè)很大程度上尚未探索的研究領(lǐng)域;
●可解釋和可操作的深度異常檢測:具有提供異常解釋的內(nèi)在能力的深度模型很重要,能減輕對(duì)人類用戶的任何潛在偏見/風(fēng)險(xiǎn)以及實(shí)現(xiàn)決策行動(dòng);
●新穎的應(yīng)用和設(shè)置:例如分布外 (OOD) 檢測、curiosity learning等。
個(gè)人來看,在【三、異常檢測的模型分類】里談?wù)摰哪P椭校覀兛梢韵嗷ソ梃b,比如Anomaly Transformer便采取了依賴異常度量的特征表征學(xué)習(xí),同時(shí)還借鑒了端對(duì)端異常分?jǐn)?shù)學(xué)習(xí)中的先驗(yàn)驅(qū)動(dòng)模型,引入了先驗(yàn)關(guān)聯(lián)。
當(dāng)我們帶著各類模型優(yōu)缺點(diǎn)的基礎(chǔ)知識(shí)去閱讀新論文時(shí),也能引發(fā)思考,比如Anomaly Transformer的先驗(yàn)關(guān)聯(lián)采用高斯分布是否普遍有效?若窗口內(nèi)存在離散異常尖峰(即多峰異常),那單峰先驗(yàn)關(guān)聯(lián)和多峰序列關(guān)聯(lián)是否便存在一定關(guān)聯(lián)差異,那么檢測效果是不是會(huì)有負(fù)面影響?多頭Anomaly Attention是否可以緩解這個(gè)問題?
這有些跑題了,但希望本篇文章大家能帶來些反思和啟發(fā),鼓勵(lì)閱讀綜述原文,深入了解其中的思想。
-
函數(shù)
+關(guān)注
關(guān)注
3文章
4346瀏覽量
62968 -
模型
+關(guān)注
關(guān)注
1文章
3305瀏覽量
49217 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1209瀏覽量
24830
原文標(biāo)題:時(shí)序異常檢測綜述整理!
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于變分自編碼器的異常小區(qū)檢測
基于特征模式的馬爾可夫鏈異常檢測模型
基于危險(xiǎn)模式的異常檢測模型
基于Q-學(xué)習(xí)算法的異常檢測模型
基于隱馬爾可夫模型的視頻異常檢測模型
基于稀疏隨機(jī)森林模型的用電側(cè)異常行為檢測
基于概率圖模型的時(shí)空異常事件檢測算法
基于健壯多元概率校準(zhǔn)模型的全網(wǎng)絡(luò)異常檢測
云模型的網(wǎng)絡(luò)異常流量檢測
基于Greenshield模型的異常節(jié)點(diǎn)檢測機(jī)制
一種多維時(shí)間序列汽車駕駛異常點(diǎn)檢測模型
如何選擇異常檢測算法
FreeWheel基于機(jī)器學(xué)習(xí)的業(yè)務(wù)異常檢測實(shí)踐
哈工大提出Myriad:利用視覺專家進(jìn)行工業(yè)異常檢測的大型多模態(tài)模型

基于DiAD擴(kuò)散模型的多類異常檢測工作






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論