") 一種新穎的標(biāo)簽驅(qū)動(dòng)去噪框架(LDF)
一種新穎的標(biāo)簽驅(qū)動(dòng)去噪框架(LDF)
01
研究動(dòng)機(jī)
方面類別檢測(簡稱ACD)是細(xì)粒度情感分析的一個(gè)重要子任務(wù),旨在從一組預(yù)定義的方面類別中檢測出評(píng)論句子中提到的方面類別。例如,給定句子”雖然房間很貴,但是服務(wù)很好.”,ACD 的任務(wù)是從句子中識(shí)別出兩個(gè)方面類別,即”服務(wù)”和”價(jià)格”。顯然,ACD 屬于多標(biāo)簽分類問題。
最近,隨著深度學(xué)習(xí)的發(fā)展,研究者們提出了大量用于 ACD 任務(wù)的神經(jīng)網(wǎng)絡(luò)模型[1, 2, 3]。所有這些模型的性能在很大程度上依賴于足夠的標(biāo)記數(shù)據(jù)。但是,ACD 任務(wù)中方面類別的注釋非常昂貴。有限的標(biāo)記數(shù)據(jù)嚴(yán)重限制了神經(jīng)網(wǎng)絡(luò)模型的有效性。為了緩解這個(gè)問題,Hu等人[4]參考了小樣本學(xué)習(xí) (FSL) 的思路[5, 6,7 ,8],將 ACD任務(wù)形式化為小樣本學(xué)習(xí)問題 (FS-ACD),即使用少量的監(jiān)督數(shù)據(jù)來判評(píng)論句子所屬的方面類別。
表1: 3-way 2-shot 元任務(wù)的示例
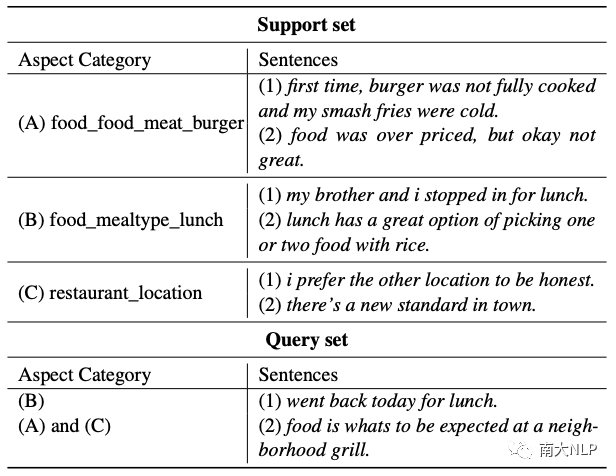
FS-ACD 遵循元學(xué)習(xí)范式[9],構(gòu)建了一個(gè) N-way K-shot 的元任務(wù)集合。表1顯示了一個(gè) 3-way 2-shot 的元任務(wù),它由一個(gè)支持集和一個(gè)查詢集組成。支持集隨機(jī)采樣三個(gè)類(即方面類別),每個(gè)類隨機(jī)選擇兩個(gè)句子(即實(shí)例)。元任務(wù)旨在借助少量標(biāo)記的支持集來推斷查詢集中句子所屬的方面類別。
通過在訓(xùn)練階段對不同的元任務(wù)進(jìn)行采樣,F(xiàn)S-ACD 可以在少樣本場景中學(xué)習(xí)到很好的泛化能力,并且在測試階段表現(xiàn)良好。為了執(zhí)行 FS-ACD 任務(wù),Hu等人[4]提出了一個(gè)基于注意力的原型網(wǎng)絡(luò)Proto-AWATT。它首先利用注意力機(jī)制從支持集中的方面類別對應(yīng)的句子中提取關(guān)鍵字,然后將它們聚合為證據(jù)為每個(gè)方面類別生成一個(gè)原型。
然后,查詢集利用原型生成相應(yīng)的查詢表示。最后,通過測量每個(gè)原型表示與相應(yīng)查詢表示之間的距離來進(jìn)行類別預(yù)測。
盡管取得了很好的效果,但是我們發(fā)現(xiàn)噪聲仍然是 FS-ACD 任務(wù)的關(guān)鍵問題。原因來自兩個(gè)方面:一方面,由于缺乏足夠的監(jiān)督數(shù)據(jù),以前的模型很容易捕捉到與當(dāng)前方面類別無關(guān)的噪聲詞,這在很大程度上影響了生成原型的質(zhì)量。如圖1所示,以方面類別 food_food_meat_burger的原型為例。
我們根據(jù)Proto-AWATT 的注意力權(quán)重突出顯示其前 10 個(gè)單詞。由于缺乏足夠的監(jiān)督數(shù)據(jù),我們觀察到模型傾向于關(guān)注那些常見但嘈雜的單詞,例如“a”、“the”、“my”。這些嘈雜的詞無法為每個(gè)方面生成具有代表性的原型,從而導(dǎo)致性能打折。另一方面,語義上接近的方面類別通常會(huì)產(chǎn)生相似的原型,這些語義接近的原型互為噪音,極大地混淆了分類器。
據(jù)統(tǒng)計(jì),數(shù)據(jù)集中近 25% 的方面類別對具有相似的語義,例如表 1 中的 food_food_meat_burger 和 food_mealtype_lunch。顯然,這些語義相近的方面類別生成的原型會(huì)相互干擾并嚴(yán)重混淆 FS-ACD的檢測結(jié)果。
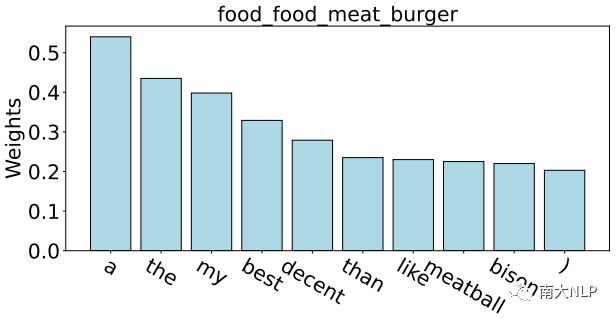
圖1:根據(jù) Proto-AWATT 的注意力權(quán)重可視化方面類別 food_food_meat_burger 原型的前 10 個(gè)單詞
為了解決上述問題,我們?yōu)?FS-ACD 任務(wù)提出了一種新穎的標(biāo)簽驅(qū)動(dòng)去噪框架(LDF)。具體來說,對于第一個(gè)問題,方面類別的標(biāo)簽文本包含豐富的語義描述方面的概念和范圍,例如方面類別restaurant_location的標(biāo)簽文本“restaurant“和”location”,它們可以幫助注意力機(jī)制更好地捕捉與標(biāo)簽相關(guān)的單詞。
因此,我們提出了一種標(biāo)簽引導(dǎo)的注意力策略來過濾噪聲詞并引導(dǎo) LDF 產(chǎn)生更好的方面原型。鑒于第二個(gè)問題,我們提出了一種有效的標(biāo)簽加權(quán)對比損失,它將支持集的類間關(guān)系合并到對比學(xué)習(xí)函數(shù)中,從而擴(kuò)大了相似原型之間的距離。
02
貢獻(xiàn)
1、據(jù)我們所知,我們是第一個(gè)利用方面類別的標(biāo)簽信息來解決FS-ACD任務(wù)中噪聲問題的工作;
2、我們提出了一種新穎的標(biāo)簽驅(qū)動(dòng)去噪框架(LDF),它包含一個(gè)標(biāo)簽引導(dǎo)的注意力策略來過濾嘈雜的單詞并為每個(gè)方面生成一個(gè)有代表性的原型,以及一個(gè)標(biāo)簽加權(quán)的對比損失來避免為語義接近的方面類別生成相似的原型;
3、LDF框架具有良好的兼容性,可以很容易地?cái)U(kuò)展到現(xiàn)有模型。在這項(xiàng)工作中,我們將其應(yīng)用于兩個(gè)最新的FS-ACD模型,Proto-HATT[8]和Proto-AWATT[4]。三個(gè)基準(zhǔn)數(shù)據(jù)集的實(shí)驗(yàn)結(jié)果證明了我們框架的優(yōu)越性。
03
背景
在這項(xiàng)工作中,我們基于 Proto-AWATT[4]和 Proto-HATT[8]模型抽象了一個(gè)通用的架構(gòu),它們都實(shí)現(xiàn)了令人滿意的性能,因此被選為我們工作的基礎(chǔ)。
給定一個(gè)包含l個(gè)單詞的實(shí)例,我們首先通過查找嵌入表將其映射到單詞序列中。然后,我們使用卷積神經(jīng)網(wǎng)絡(luò)(CNN)將單詞序列編碼為上下文表示。接下來,注意力層為實(shí)例中的每個(gè)單詞分配一個(gè)權(quán)重。最終實(shí)例表示由下式給出:
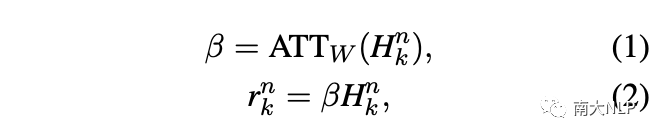
之后,我們聚合類n的所有實(shí)例表示來生成原型表示:
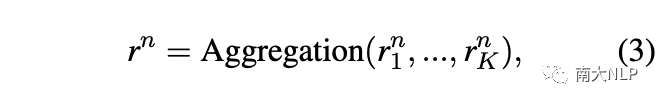
在處理了支持集中的所有類之后,我們得到了N個(gè)原型表示。類似地,對于查詢實(shí)例,我們首先利用注意力機(jī)制生成N個(gè)原型特定的查詢表示。之后,我們計(jì)算每個(gè)原型與對應(yīng)的原型特定查詢表示之間的歐幾里得距離(ED)。最后,我們對負(fù)歐幾里得距離進(jìn)行歸一化以獲得原型的排名,并使用閾值來選擇方面類別:
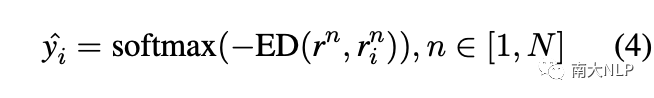
最終的訓(xùn)練目標(biāo)是均方誤差(MSE)損失:
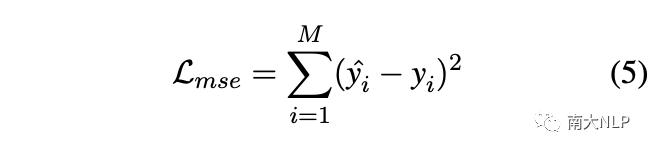
04
解決方案
圖 2 展示了 LDF 的整體架構(gòu),其中包含兩個(gè)組件:標(biāo)簽引導(dǎo)的注意力策略和標(biāo)簽加權(quán)的對比損失。在標(biāo)簽信息的幫助下,前者可以更好地關(guān)注與方面類別相關(guān)的單詞,從而為每個(gè)方面生成更準(zhǔn)確的原型,后者利用支持集的類間關(guān)系避免生成相似的原型。
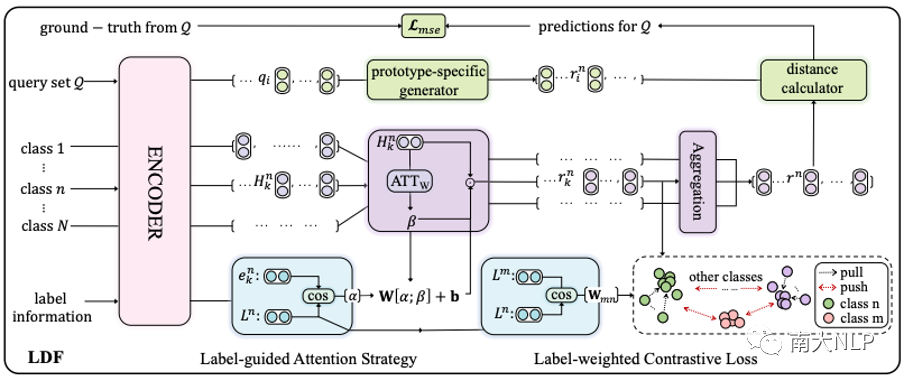
圖2:標(biāo)簽驅(qū)動(dòng)去噪框架(LDF)的整體架構(gòu)
3.1 標(biāo)簽引導(dǎo)的注意力策略
由于缺乏足夠的監(jiān)督數(shù)據(jù),公式1中的注意力權(quán)重通常會(huì)關(guān)注一些與當(dāng)前類別無關(guān)的噪聲詞,導(dǎo)致原型變得不具有代表性。直覺上來說,每個(gè)類的標(biāo)簽文本都包含豐富的語義,可以為捕獲方面類別相關(guān)的單詞提供指導(dǎo)。因此,我們利用標(biāo)簽信息來解決上述問題并提出標(biāo)簽引導(dǎo)的注意力策略。
具體來說,我們首先計(jì)算標(biāo)簽文本與實(shí)例中每個(gè)單詞的語義相似度來定位每個(gè)類的關(guān)鍵詞:
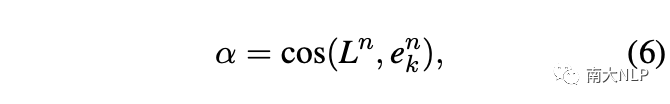
在標(biāo)簽信息的約束下,相似度權(quán)重傾向于關(guān)注與標(biāo)簽文本高度相關(guān)的少量單詞,這樣可能會(huì)忽略其它有信息量的詞。因此,我們將其作為注意力權(quán)重的補(bǔ)充,以生成更全面、更準(zhǔn)確的注意力權(quán)重:
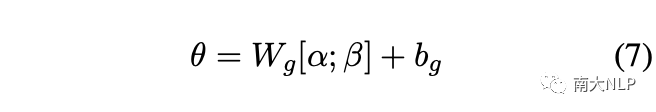
然后,為了重新獲得注意力分布,注意力權(quán)重被重新歸一化為:
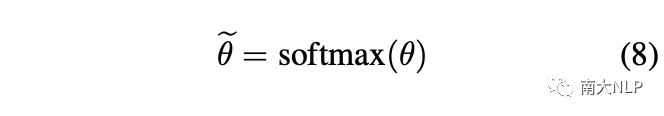
最后,我們將方程1中的注意力權(quán)重替換為方程8中新的注意力權(quán)重,從而獲得支持集中每個(gè)類的代表性原型。
3.2 標(biāo)簽加權(quán)的對比損失
如前所述,語義上接近的方面類別通常會(huì)在支持集中生成相似的原型,它們互為噪聲并嚴(yán)重混淆分類器。
直觀地說,一種可行且自然的方法是利用有監(jiān)督對比學(xué)習(xí),它可以將不同類別的原型推開如下:
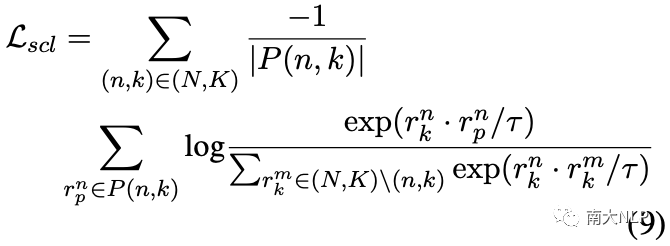
然而,有監(jiān)督對比學(xué)習(xí)并不能很好地解決我們的問題,因?yàn)樗谪?fù)集中平等地對待不同的原型,而我們的目標(biāo)是鼓勵(lì)越相似的原型相距越遠(yuǎn)。
例如,“food_food_meat_burger”在語義上比“room_bed”更接近“food_mealtype_lunch”。因此,“food_food_meat_burger”在負(fù)集中應(yīng)該比“room_bed”更遠(yuǎn)離“food_mealtype_lunch”。
為了實(shí)現(xiàn)這一目標(biāo),我們再次利用標(biāo)簽信息并提出將類間關(guān)系合并到有監(jiān)督的對比學(xué)習(xí)中,以自適應(yīng)地區(qū)分負(fù)集中的相似原型:
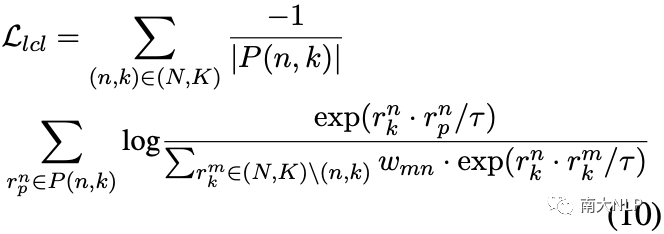
其中 wmn表示負(fù)集中不同方面類別之間的 cos 相似度,計(jì)算如下:
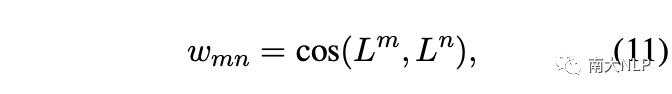
在標(biāo)簽加權(quán)的對比損失模塊中,最終的損失函數(shù)為:
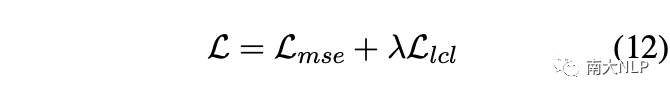
05
實(shí)驗(yàn)
5.1 實(shí)驗(yàn)設(shè)置
我們在三個(gè)公開的數(shù)據(jù)集FewAsp(single)、FewAsp(multi)和FewAsp上進(jìn)行了實(shí)驗(yàn),它們共享相同的100個(gè)方面類別,其中64個(gè)方面用于訓(xùn)練,16個(gè)方面用于驗(yàn)證,20個(gè)方面用于測試。我們使用 Macro-F1 和 AUC 分?jǐn)?shù)作為評(píng)估指標(biāo),并且 5-way 設(shè)置和 10-way 設(shè)置中的閾值分別設(shè)置為0.3和0.2。
為了驗(yàn)證LDF框架的優(yōu)越性,我們選擇了兩個(gè)性能最好的主流模型作為我們工作的基礎(chǔ),即Proto-HATT[8]和Proto-AWATT[4]。換句話說,我們將LDF集成到Proto-HATT和Proto-AWATT中,得到最終模型LDF-HATT和LDF-AWATT。
5.2 主實(shí)驗(yàn)
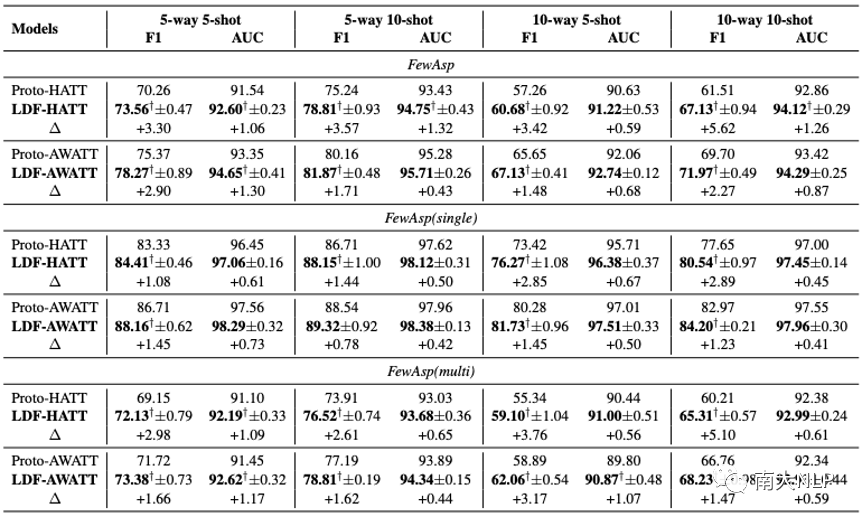
從表2可以看出,LDF-HATT和LDF-AWATT在三個(gè)數(shù)據(jù)集上的性能始終優(yōu)于其基礎(chǔ)模型。值得一提的是LDF-HATT在Macro-F1和AUC分?jǐn)?shù)上最多獲得了5.62%和1.32%的提升。相比之下,LDF-AWATT最多比Proto-AWATT高3.17%和1.30%。這些結(jié)果表明我們的框架具有良好的兼容性。
事實(shí)上,LDF-AWATT的Macro-F1在大多數(shù)情況下提高了大約2%,而LDF-HATT的Macro-F1平均提高了大約3%。這與我們的預(yù)期一致,因?yàn)樵糚roto-AWATT具有更強(qiáng)大的性能。LDF-HATT和LDF-AWATT在FewAsp(multi)數(shù)據(jù)集上比在FewAsp(single)數(shù)據(jù)集上表現(xiàn)更好。
一個(gè)可能的原因是FewAsp(multi)數(shù)據(jù)集中的每個(gè)類包含更多的實(shí)例,這使得LDF-HATT和LDF-AWATT在多標(biāo)簽分類中可以生成更準(zhǔn)確的原型。
表2:主實(shí)驗(yàn)結(jié)果
5.3 消融實(shí)驗(yàn)
在不失一般性的情況下,我們選擇 LDF-AWATT模型進(jìn)行消融實(shí)驗(yàn),以研究LDF中單個(gè)模塊對模型整體效果的影響。標(biāo)簽引導(dǎo)的注意力策略簡稱LAS,-標(biāo)簽加權(quán)的對比損失簡稱LCL,有監(jiān)督的對比學(xué)習(xí)簡稱SCL。根據(jù)表3報(bào)告的結(jié)果,我們可以觀察到以下幾點(diǎn):
表3:消融實(shí)驗(yàn)結(jié)果

1、與基礎(chǔ)模型Proto-AWATT相比, Proto-AWATT+LAS在三個(gè)數(shù)據(jù)集上取得了具有競爭力的性能,這驗(yàn)證了利用標(biāo)簽信息為每個(gè)類生成具有代表性原型的合理性;
2、將 LCL 集成到 Proto-AWATT+LAS后,LDF-AWATT 實(shí)現(xiàn)了 state-of-the-art 的性能,這表明 LCL 有利于區(qū)分相似的原型;
3、LAS 比 LCL 更有效。一個(gè)可能的原因是注意力機(jī)制是生成原型的核心因素。因此,它對我們的框架貢獻(xiàn)更大;
4、Proto-AWATT+SCL 在FewAsp 數(shù)據(jù)集上的性能略好于Proto-AWATT,但它們的結(jié)果遠(yuǎn)低于 Proto-AWATT+LCL,這些結(jié)果進(jìn)一步凸顯了LCL的有效性;
5、將類間關(guān)系集成到Proto-AWATT+SCL后,Proto-AWATT+LCL取得了更好的性能,這表明類間關(guān)系在區(qū)分相似原型方面起著至關(guān)重要的作用;
06
案例分析
為了更好地理解我們框架的優(yōu)勢,我們從FewAsp 數(shù)據(jù)集中選擇一些樣本進(jìn)行案例研究。具體來說,我們隨機(jī)抽取 5 個(gè)類,然后為這5個(gè)類抽取 50 次 5-way 5-shot 元任務(wù)。最后對于每個(gè)類,我們得到 50 個(gè)原型向量。
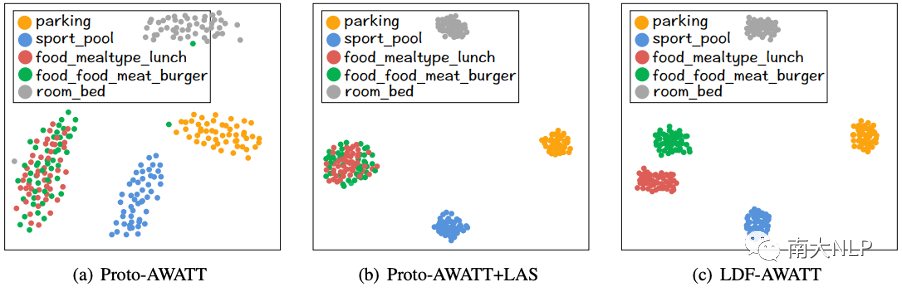
圖4:可視化Proto-AWATT、Proto-AWATT+LAS 和 LDF-AWATT 原型表示
6.1 Proto-AWATT vs. Proto-AWATT+LAS
如圖4(a) 和圖4(b) 所示,我們可以看到Proto-AWATT+LAS 學(xué)習(xí)到的每個(gè)類的原型表示顯然比Proto-AWATT 更集中。這些觀察表明Proto-AWATT+LAS確實(shí)可以為每個(gè)類生成更準(zhǔn)確的原型。
6.2 Proto-AWATT+LAS vs. LDF-AWATT
如圖4(b)和圖4(c)所示,將LCL集成到Proto-AWATT+LAS后,LDF-AWATT學(xué)習(xí)到的food_mealtype_lunch和food_food_meat_burger的原型表示比Proto-AWATT+LAS更分離。這表明LCL確實(shí)可以區(qū)分相似的原型。
07
錯(cuò)誤分析
為了分析我們框架的局限性,我們通過LDF-AWATT 從FewAsp 數(shù)據(jù)集中隨機(jī)抽取 100 個(gè)錯(cuò)誤案例,并將它們大致分為兩類。表4顯示了每個(gè)類別的比例和一些代表性示例。主要類別是”Complex”,主要包括需要深入理解的示例。
如示例(1)所示,與 restaurant_location 相關(guān)的單詞片段“Chandler Downtown Serrano”在訓(xùn)練集中出現(xiàn)的次數(shù)不超過 5 次,這些表達(dá)的低頻率使得我們的模型難以捕捉到它們的模式,因此給出正確的預(yù)測確實(shí)具有挑戰(zhàn)性。
第二類是”No obvious clues”,主要包括信息不足的例子。如示例(2)所示,句子很短,無法提供足夠的信息來預(yù)測真實(shí)標(biāo)簽。
表4:LDF-AWATT模型的錯(cuò)誤樣例

08
總結(jié)
在本文中,我們提出了一種新穎的標(biāo)簽驅(qū)動(dòng)去噪框架(LDF)來緩解 FS-ACD 任務(wù)的噪聲問題。具體來說,我們設(shè)計(jì)了兩個(gè)合理的方法:標(biāo)簽引導(dǎo)的注意力策略和標(biāo)簽加權(quán)的對比損失,旨在為每個(gè)類生成更好的原型并區(qū)分相似的原型。大量實(shí)驗(yàn)的結(jié)果表明,我們的框架 LDF 與其他最先進(jìn)的方法相比實(shí)現(xiàn)了更好的性能。
論文鏈接:
https://arxiv.org/pdf/2210.04220.pdf
代碼鏈接:
https://github.com/1429904852/LDF
審核編輯:劉清
-
ACD
+關(guān)注
關(guān)注
0文章
13瀏覽量
11359 -
分類器
+關(guān)注
關(guān)注
0文章
152瀏覽量
13225 -
卷積神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
4文章
367瀏覽量
11917
原文標(biāo)題:EMNLP'22 Findings | 用于多標(biāo)簽少樣本方面類別檢測的標(biāo)簽驅(qū)動(dòng)去噪框架
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評(píng)論請先 登錄
相關(guān)推薦
為電機(jī)一體化應(yīng)用提供一種大電流單通道集成電機(jī)驅(qū)動(dòng)芯片

YD7123高速低噪D類音頻放大驅(qū)動(dòng)電路中文手冊
一文看懂RFID電子標(biāo)簽的特點(diǎn)及應(yīng)用
一種面向飛行試驗(yàn)的數(shù)據(jù)融合框架

tlv320aic3106底噪過大要如何解決?
為電機(jī)一體化應(yīng)用提供一種雙通道集成電機(jī)驅(qū)動(dòng)方案的電機(jī)驅(qū)動(dòng)芯片-SS6811H

運(yùn)放的反饋電阻習(xí)慣性并聯(lián)上一個(gè)反饋電容,主要目的就是去噪,為什么會(huì)起到這種作用?
芯科科技完整的藍(lán)牙解決方案助推電子貨架標(biāo)簽應(yīng)用
rup是一種什么模型
頻譜儀測載噪比怎么測
IU8200差分輸入,超低底噪300mW單聲道高性能音頻驅(qū)動(dòng)芯片

一種高效的KV緩存壓縮框架--GEAR

融智興科普|淺析RFID洗滌標(biāo)簽管理應(yīng)用

介紹一種OpenAtom OpenHarmony輕量系統(tǒng)適配方案

一種高效1.5V/4.2V的LED驅(qū)動(dòng)器電路





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論