") 如何通過(guò)在CI/CD中實(shí)現(xiàn)斷路器來(lái)防止內(nèi)部級(jí)聯(lián)故障的發(fā)生呢
如何通過(guò)在CI/CD中實(shí)現(xiàn)斷路器來(lái)防止內(nèi)部級(jí)聯(lián)故障的發(fā)生呢
譯者按:本文介紹了Slack公司如何通過(guò)在CI/CD中實(shí)現(xiàn)編排級(jí)的斷路器(orchestration-level circuit breakers)來(lái)提高開(kāi)發(fā)人員的生產(chǎn)力并防止內(nèi)部級(jí)聯(lián)故障的發(fā)生。斷路器:類似于電路的保險(xiǎn)絲,可以將需要保護(hù)的遠(yuǎn)程服務(wù)用“斷路器” 封裝起來(lái),在內(nèi)部監(jiān)聽(tīng)失敗次數(shù), 一旦失敗次數(shù)達(dá)到某閥值后,所有后續(xù)對(duì)該服務(wù)的調(diào)用被斷路器截獲,并直接返回錯(cuò)誤到調(diào)用方,而不會(huì)繼續(xù)調(diào)用已經(jīng)出問(wèn)題的服務(wù), 從而達(dá)到保護(hù)調(diào)用方的目的, 整個(gè)系統(tǒng)也就不會(huì)出現(xiàn)因?yàn)槌瑫r(shí)而產(chǎn)生的瀑布式連鎖反應(yīng)。
當(dāng)一個(gè)分布式的服務(wù)系統(tǒng)面對(duì)海量?jī)?nèi)部請(qǐng)求的挑戰(zhàn)時(shí),會(huì)發(fā)生什么情況?如何防止內(nèi)部服務(wù)之間的級(jí)聯(lián)故障?當(dāng)我們對(duì)系統(tǒng)進(jìn)行簡(jiǎn)單的水平擴(kuò)展或垂直擴(kuò)展并分別達(dá)到極限時(shí),應(yīng)該如何重新構(gòu)建開(kāi)發(fā)的工作流(workflow)? 回到2020年,以上這些都是Slack公司的工程師們?cè)陂_(kāi)發(fā)工作流中經(jīng)常面臨的挑戰(zhàn)。
工程師們使用的多個(gè)內(nèi)部服務(wù)被拉伸到了極限,導(dǎo)致服務(wù)之間出現(xiàn)級(jí)聯(lián)故障。級(jí)聯(lián)故障是正反饋回路,如果系統(tǒng)的某個(gè)部分規(guī)模化地出現(xiàn)故障,就會(huì)導(dǎo)致相鄰系統(tǒng)的請(qǐng)求排隊(duì),從而導(dǎo)致該系統(tǒng)規(guī)模化地出現(xiàn)故障。幾年以來(lái),由于兩個(gè)因素,我們的內(nèi)部工具和服務(wù)團(tuán)隊(duì)很難應(yīng)對(duì)每月10%的CI/CD請(qǐng)求增長(zhǎng):第一,內(nèi)部人員數(shù)量的增長(zhǎng);第二,服務(wù)和測(cè)試的復(fù)雜性。當(dāng)故障發(fā)生時(shí),整個(gè)開(kāi)發(fā)團(tuán)隊(duì)的開(kāi)發(fā)速度會(huì)變得緩慢,內(nèi)部工具開(kāi)發(fā)工程師和基礎(chǔ)設(shè)施工程師不得不想辦法盡快恢復(fù)服務(wù)。為了實(shí)現(xiàn)這個(gè)目標(biāo),這些工程師們一般采用以下方式:
將Github Enterprise等設(shè)備擴(kuò)展到AWS中可提供的最大硬件容量(限制了未來(lái)的垂直擴(kuò)展)。
使用更多的節(jié)點(diǎn)來(lái)擴(kuò)展一項(xiàng)服務(wù)以應(yīng)對(duì)新的峰值負(fù)載(但卻發(fā)現(xiàn)這會(huì)導(dǎo)致基礎(chǔ)設(shè)施中另一項(xiàng)服務(wù)的失敗)。
當(dāng)然,這些解決方案只能在我們的內(nèi)部服務(wù)達(dá)到一個(gè)新的峰值負(fù)載之前發(fā)揮作用。我們需要一種新的方式來(lái)思考這個(gè)問(wèn)題。
本文介紹了Slack的工程師如何通過(guò)在內(nèi)部工具中實(shí)施編排級(jí)的斷路器機(jī)制幫助開(kāi)發(fā)人員提高生產(chǎn)力。Checkpoint是一個(gè)CI/CD的編排服務(wù)。開(kāi)發(fā)者生產(chǎn)力團(tuán)隊(duì)中的工程師們采用了斷路器讓Checkpoint中的請(qǐng)求被推遲或放棄。
CI/CD編排和Webapp中復(fù)雜性和規(guī)模化帶來(lái)的挑戰(zhàn)
回到2020年,我們看到兩類相互關(guān)聯(lián)的問(wèn)題:規(guī)模化和復(fù)雜性。工程師們建立并采用了持續(xù)集成流水線(CI)進(jìn)行開(kāi)發(fā),使用了持續(xù)交付流水線(CD)將Slack系統(tǒng)部署和發(fā)布到生產(chǎn)環(huán)境中。Checkpoint是我們的內(nèi)部平臺(tái),用于調(diào)度代碼的構(gòu)建、測(cè)試、部署和發(fā)布。隨著時(shí)間的推移,Slack的開(kāi)發(fā)人員和功能發(fā)布的數(shù)量都不斷增加,這也轉(zhuǎn)化為CI/CD的額外負(fù)載。隨著更多功能的發(fā)布,工程師們還編寫(xiě)了自動(dòng)化測(cè)試腳本以支持新功能的測(cè)試。
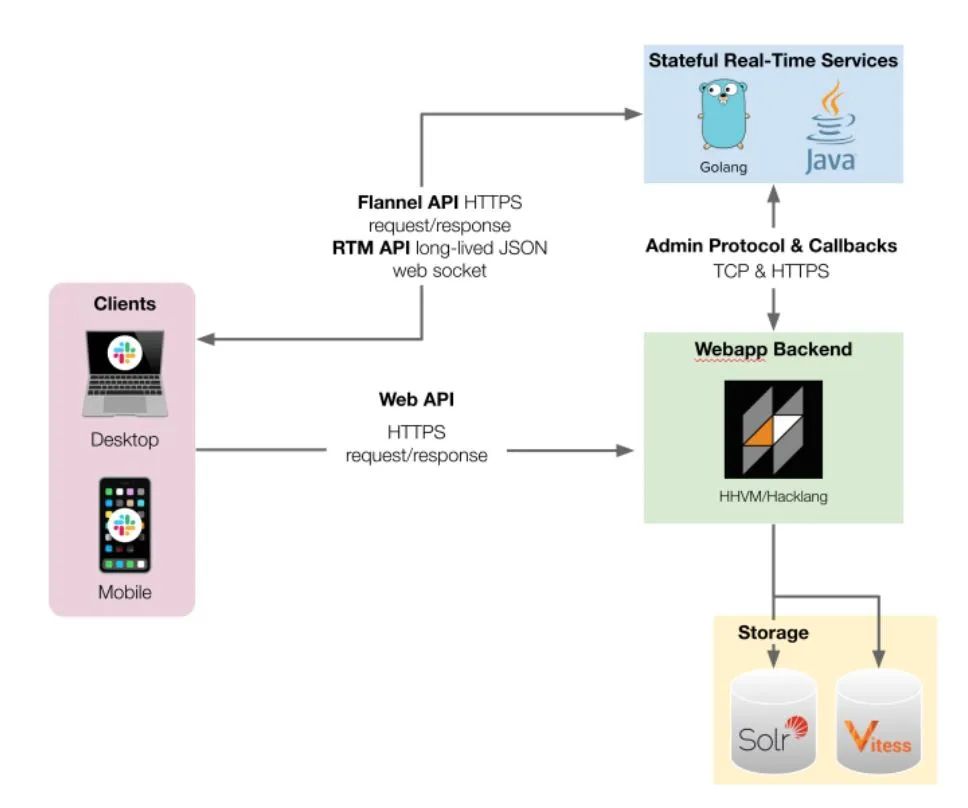
圖1 Slack Webapp架構(gòu)圖。客戶端連接到三個(gè)不同的API,以便實(shí)時(shí)有效地呈現(xiàn)用戶看到的內(nèi)容
開(kāi)發(fā)人員數(shù)量和功能發(fā)布數(shù)量這兩個(gè)增長(zhǎng)矢量導(dǎo)致了定期發(fā)生的新的負(fù)載高峰,也會(huì)導(dǎo)致個(gè)別服務(wù)出現(xiàn)新的故障模式,然后發(fā)生級(jí)聯(lián)故障(內(nèi)部服務(wù)之間)和事故。每個(gè)服務(wù)都以不同的速度在演進(jìn),不一定能通過(guò)水平或垂直擴(kuò)展輕松適應(yīng)新的峰值(下面的例子)。
當(dāng)故障發(fā)生時(shí),工程師們被召集起來(lái)處理大規(guī)模的內(nèi)部事故,解決這些級(jí)聯(lián)故障。盡管這些事故沒(méi)有影響到Slack的客戶,但仍然占用了工程師們的工作時(shí)間,而且往往涉及多個(gè)團(tuán)隊(duì)并持續(xù)多天。在事故發(fā)生時(shí),Slack的開(kāi)發(fā)人員需要忍受持續(xù)集成流水線中測(cè)試執(zhí)行的速度下降甚至是停止,以及持續(xù)交付流水線的可用性受到限制等問(wèn)題。
CI測(cè)試/CD工作流會(huì)出現(xiàn)Git錯(cuò)誤,當(dāng)每天的峰值測(cè)試數(shù)量超過(guò)了Git應(yīng)用程序可以提供的服務(wù),就導(dǎo)致Checkpoint(異步作業(yè)處理)中用于調(diào)度測(cè)試的任務(wù)增加,讓Checkpoint和Jenkins中執(zhí)行測(cè)試的隊(duì)列變長(zhǎng)。工程師們?cè)跍y(cè)試受限的情況下繼續(xù)進(jìn)行開(kāi)發(fā),讓任務(wù)隊(duì)列變得越來(lái)越長(zhǎng)。
Git是CI流水線和開(kāi)發(fā)者工具的基礎(chǔ)工具。Git的規(guī)模化問(wèn)題在建立抽象(如谷歌的Piper)或替代源控制(如Facebook的Mercurial)的大型組織中被充分的記錄下來(lái)。2019年,Slack內(nèi)部工具采用Git LFS來(lái)處理大文件。在這段時(shí)間里,Git設(shè)備一直在垂直方向上擴(kuò)展。Git中大型 repo的增長(zhǎng)對(duì)開(kāi)發(fā)人員一直是一個(gè)挑戰(zhàn),可以通過(guò)定制的源碼控制系統(tǒng)(如Piper或Github的monorepo維護(hù))來(lái)解決。
Checkpoint有一個(gè)內(nèi)部異步任務(wù)隊(duì)列(使用自我托管的main-main MySQL,現(xiàn)在使用的是AWS的RDS Aurora),以保持CI/CD編排的狀態(tài)。這個(gè)任務(wù)隊(duì)列和調(diào)度器會(huì)重試失敗的請(qǐng)求。調(diào)度器限制了并發(fā)任務(wù),以減少負(fù)載和數(shù)據(jù)庫(kù)上的失敗請(qǐng)求。當(dāng)一個(gè)隊(duì)列中有太多的任務(wù)(如測(cè)試請(qǐng)求任務(wù))時(shí),這種有限的并發(fā)性造成滯后,導(dǎo)致CI/CD的用戶重復(fù)請(qǐng)求同一個(gè)任務(wù),從而引發(fā)正反饋循環(huán)和更長(zhǎng)的隊(duì)列。
在過(guò)去,為了應(yīng)對(duì)開(kāi)發(fā)人員數(shù)量的持續(xù)增長(zhǎng),Slack公司的內(nèi)部工具工程師需要定期增加測(cè)試執(zhí)行器(test executor)和測(cè)試環(huán)境的數(shù)量。如果沒(méi)有注意負(fù)載極限,來(lái)自測(cè)試(即測(cè)試執(zhí)行器)和Slack環(huán)境(即待測(cè)試代碼)的大規(guī)模請(qǐng)求,會(huì)導(dǎo)致更多的請(qǐng)求超過(guò)CI中的搜索集群可以處理的上限,從而引入錯(cuò)誤,當(dāng)然,更多的是增加了對(duì)CI/CD流水線的負(fù)載。
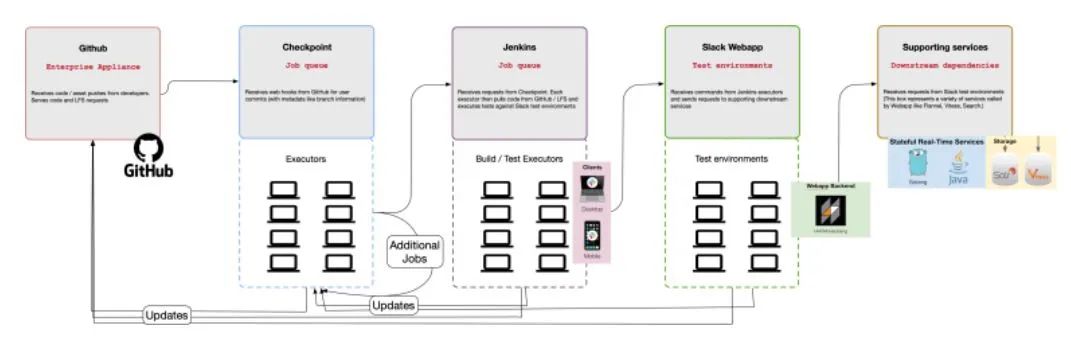
圖2CI服務(wù)和工具之間級(jí)聯(lián)故障的工作流程實(shí)例
為什么復(fù)雜性很重要
在Slack公司中,我們通過(guò)集成測(cè)試和端到端的測(cè)試來(lái)驗(yàn)證多個(gè)服務(wù)重疊的復(fù)雜工作流的正確性。雖然在開(kāi)始時(shí)公司只有一個(gè)服務(wù)(Webapp),但目前已經(jīng)發(fā)展成多個(gè)支持用戶體驗(yàn)的服務(wù)。Slack客戶端連接到三個(gè)不同的API,向用戶實(shí)時(shí)呈現(xiàn)內(nèi)容(見(jiàn)圖1中簡(jiǎn)化的架構(gòu)圖)。Slack公司的Webapp是一個(gè)復(fù)雜的應(yīng)用程序,包括許多配置(如團(tuán)隊(duì)、企業(yè)和跨企業(yè)信息)。為了測(cè)試復(fù)雜的代碼路徑,產(chǎn)品和測(cè)試工程師專注于編寫(xiě)自動(dòng)化測(cè)試,這依賴于大量的移動(dòng)部件(見(jiàn)圖2)。
斷路器
軟件斷路器是一個(gè)從系統(tǒng)工程中借用的概念,它用來(lái)檢測(cè)外部系統(tǒng)的故障并中斷對(duì)已知故障系統(tǒng)的調(diào)用。客戶端是采用斷路器的典型位置。由于我們的CI/CD編排層調(diào)節(jié)了請(qǐng)求在系統(tǒng)中的流動(dòng),因此,在將請(qǐng)求發(fā)送給下一個(gè)系統(tǒng)之前,我們?cè)诰幣牌飨M(fèi)者服務(wù)中實(shí)現(xiàn)了具有斷路器功能的客戶端,同時(shí)有多個(gè)并發(fā)的任務(wù)調(diào)用客戶端。
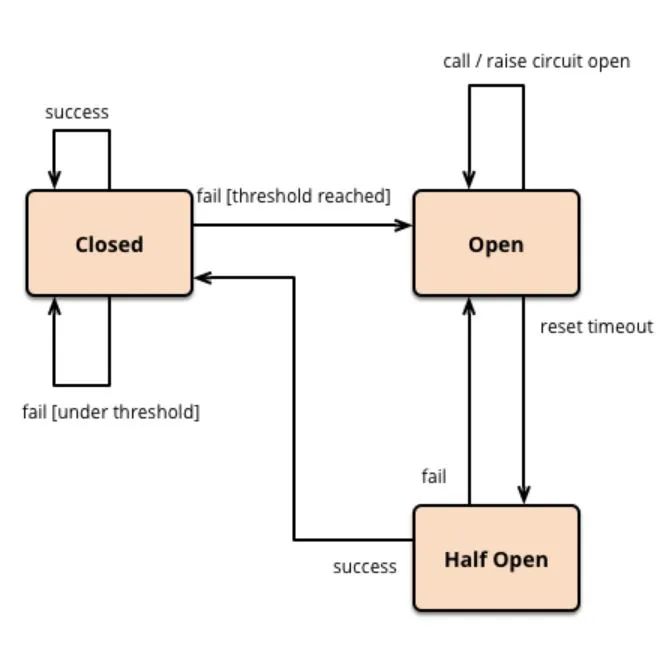
圖3斷路器控制流程圖
我們有一個(gè)假設(shè),即斷路器可以最大限度地減少級(jí)聯(lián)故障,并提高多個(gè)服務(wù)的程序化度量查詢的利用率,而不是基于單個(gè)客戶端或服務(wù)的方法。與單個(gè)服務(wù)中的傳統(tǒng)斷路器不同,編排級(jí)系統(tǒng)的斷路器可以調(diào)節(jié)系統(tǒng)間的請(qǐng)求接口。
當(dāng)系統(tǒng)所依賴的服務(wù)遇到負(fù)載增加的情況或由于負(fù)載增加而顯示錯(cuò)誤時(shí),斷路器就會(huì)打開(kāi)。Checkpoint以編程方式從多個(gè)依賴服務(wù)中檢索健康指標(biāo)。如果下游系統(tǒng)不能為這些請(qǐng)求提供服務(wù),那么請(qǐng)求將被推遲或放棄。當(dāng)依賴服務(wù)顯示恢復(fù)時(shí),斷路器將關(guān)閉,這些被推遲的請(qǐng)求將再次開(kāi)始執(zhí)行。這種對(duì)已知故障請(qǐng)求的管理減少了影響構(gòu)建、測(cè)試、部署和發(fā)布代碼能力的級(jí)聯(lián)故障事件,并減少了CI中的故障執(zhí)行。
實(shí)現(xiàn)方法
讓我們從一個(gè)用Hacklang實(shí)現(xiàn)的抽象類開(kāi)始,以此為基礎(chǔ)進(jìn)行討論,并為這個(gè)新的工作流創(chuàng)建原型。這里我們討論的重點(diǎn)不是構(gòu)建或測(cè)試客戶端,而是Checkpoint,即編排服務(wù),Checkpoint負(fù)責(zé)協(xié)調(diào)CI/CD工作流,其后臺(tái)工作系統(tǒng)代表了Slack的構(gòu)建、測(cè)試、部署和發(fā)布的命脈。
Checkpoint有一個(gè)API端點(diǎn),當(dāng)一個(gè)新的commit被創(chuàng)建時(shí),API端點(diǎn)可以接收GitHub的webhook。從這個(gè)commit中,Checkpoint會(huì)排入多個(gè)后臺(tái)任務(wù),觸發(fā)Jenkins構(gòu)建或測(cè)試,然后更新數(shù)據(jù)庫(kù)中的測(cè)試結(jié)果。
我們選擇在Checkpoint后臺(tái)任務(wù)中關(guān)注帶有延遲和減載的斷路。雖然斷路器可以存在于客戶端邏輯中(例如,等待恢復(fù)或阻止工作),但Checkpoint的后臺(tái)任務(wù)系統(tǒng)提供了一個(gè)獨(dú)特的機(jī)會(huì),因?yàn)樗嵌鄠€(gè)系統(tǒng)之間的調(diào)度程序的中介。
我們使用Trickster在幾個(gè)使用PromQL的Prometheus集群中對(duì)依賴性服務(wù)指標(biāo)進(jìn)行編程式查詢。這個(gè)服務(wù)是對(duì)多個(gè)Prometheus群進(jìn)行查詢的前端、代理和緩存。
由于內(nèi)部后臺(tái)任務(wù)重試和使用延遲的CI請(qǐng)求,Checkpoint不需要半開(kāi)放狀態(tài)(half-open state)。半開(kāi)放狀態(tài)對(duì)于單獨(dú)的客戶端請(qǐng)求和提示這些客戶端的恢復(fù)非常重要。但由于Checkpoint的后臺(tái)任務(wù)系統(tǒng)提供重試功能,而且這個(gè)斷路器包含了Prometheus查詢的TTL,一旦一個(gè)開(kāi)放的斷路器恢復(fù),Checkpoint就會(huì)隨時(shí)恢復(fù)工作。
namespace CheckpointCircuitBreaker; use type SlackCheckpointPromClient; /* * Generic interface for Circuit Breakers in Checkpoint. * Downstream actions include deferral mechanisms or load shedding. * @see https://martinfowler.com/bliki/CircuitBreaker.html */ enum CircuitBreakerState: string { CLOSED = 'closed'; OPEN = 'open'; } abstract class CircuitBreaker { /** * Get the state of this circuit breaker. Note the return value is intentionally * not a `Result圖4CircuitBreaker類的簡(jiǎn)化代碼`. In the case of internal errors, this must * decide if the breaker fails open/closed. */ abstract protected function getState(): CircuitBreakerState; /** * Allow for bypassing a circuit breaker. Used as a circuit breaker for circuit breakers. * In a subsequent class, add the following to always allow the request to pass through * <<__Override, __Memoize>> * public function bypass(): bool { return true; } */ public function bypass(): bool { return false; } public function allowRequest(): bool { $state = $this->getState(); PromClient::circuit_breaker_requests()->inc(1, darray[ 'breaker_type' => (string)static::class, 'breaker_state' => (string)$state, ]); if ($this->bypass()) return true; return $state === CircuitBreakerState::CLOSED; } }
在第一個(gè)代碼實(shí)現(xiàn)的sprint中,我們實(shí)現(xiàn)了編排服務(wù)健康的斷路器。
當(dāng)Checkpoint和Jenkins隊(duì)列達(dá)到一定閾值時(shí),推遲測(cè)試任務(wù)。
當(dāng)所有Slack測(cè)試環(huán)境都很忙時(shí),推遲端到端的測(cè)試任務(wù)。
為分支上的較早的commit消減測(cè)試執(zhí)行的負(fù)載。
對(duì)于任何有持續(xù)失敗的套件,消減測(cè)試重試的負(fù)載。
在第二個(gè)sprint中,我們實(shí)現(xiàn)了共享依賴服務(wù)的斷路器。
Flannel :在全球多個(gè)地區(qū)的邊緣緩存,返回經(jīng)常獲取的團(tuán)隊(duì)范圍的數(shù)據(jù)。
Vitess:所有客戶數(shù)據(jù)的真實(shí)來(lái)源(采用MySQL語(yǔ)法)。Vitess是一個(gè)數(shù)據(jù)庫(kù)解決方案,用于部署、擴(kuò)展和管理大型數(shù)據(jù)庫(kù)實(shí)例集群。
搜索:提供信息、文件和人的索引的服務(wù),計(jì)算實(shí)時(shí)集合(通過(guò)工作隊(duì)列實(shí)時(shí)提供)和每周集合(用從時(shí)間開(kāi)始的信息進(jìn)行離線計(jì)算)。
Flannel的簡(jiǎn)化實(shí)現(xiàn)代碼如圖5所示,包括:緩存中的查詢(連同TTL),Prometheus范圍查詢,用戶信息傳遞,以及使用Prometheus范圍查詢對(duì)Trickster的調(diào)用。安全性在這里很重要,如果Trickster/Prometheus集群返回一個(gè)錯(cuò)誤,我們讓斷路器保持關(guān)閉,允許請(qǐng)求流過(guò)。同樣地,我們?yōu)楫惒饺蝿?wù)之間一致的客戶請(qǐng)求緩存響應(yīng)。
namespace CheckpointCIBotCircuitBreaker;
use namespace Checkpoint{CIIssue, Trickster};
use type CheckpointCIBotDelta{DeltaAnomalyType, DeltaDimensionType};
use type CheckpointCIIssueServiceDepCircuitBreakerType;
use type CheckpointCircuitBreaker{Cacheable, CircuitBreaker, CircuitBreakerState};
use type SlackCheckpointPromClient;
type flannel_callback_error_rate_cache_t = shape(
'ts' => int,
'error_rate' => int,
);
final class FlannelServiceDepCircuitBreaker extends CircuitBreaker {
use Cacheable;
const int TTL = 60; // Time-to-Live for cached value
const int FLANNEL_CALLBACK_ERROR_RATE_THRESHOLD = 5;
const string PROM_FLANNEL_CLUSTER = 'flannel';
const string PROM_FLANNEL_QUERY_GLOBAL = 'sum(dcirate1m{error!~"org_login_required"})';
const string ISSUE_MESSAGE_OPEN = ' Flannel Circuit Breaker is open. Tests are deferred';
const string ISSUE_MESSAGE_CLOSE = 'This circuit breaker is closed. Tests are starting again';
const string ISSUE_KEY = ServiceDepCircuitBreakerType::FLANNEL;
public function __construct(private ?github_repos_t $repo = null, private ?TSlackjsonValidatorPropertiesCheckpointPropertiesTestsItems $test = null) {}
<<__Override, __Memoize>>
public function getState(): CircuitBreakerState {
$cached_key = $this->getCacheKey(self::class, 'flannel_callback_errors');
$cached_data = cache_get($cached_key);
$existing_error_rate = 0;
// If the cache exists, and is fresh enough, use it. Default to Closed
$result = type_assert_type($cached_data, flannel_callback_error_rate_cache_t::class);
if ($result->is_error()) { return CircuitBreakerState::CLOSED; }
$data = $result->get();
$existing_error_rate = $data['error_rate'];
if ($this->isValidCache($data['ts'], static::TTL)) {
if ($existing_error_rate < static::FLANNEL_CALLBACK_ERROR_RATE_THRESHOLD) {
return CircuitBreakerState::CLOSED;
} else {
return CircuitBreakerState::OPEN;
}
}
// Lets fetch the current error rate (and compare against the former one)
$result = $this->getFlannelCallbackErrorRate();
if ($result->is_error()) {
return CircuitBreakerState::CLOSED;
}
$error_rate = $result->get();
$cached_value = shape('ts' => time(), 'error_rate' => $error_rate);
cache_set($cached_key, $cached_value);
if ($error_rate >= static::FLANNEL_CALLBACK_ERROR_RATE_THRESHOLD) {
PromClient::cibot_service_dependency_error_rate_above_threshold()->inc(1, darray[
'breaker_type' => (string)static::class,
]);
if ($existing_error_rate < static::FLANNEL_CALLBACK_ERROR_RATE_THRESHOLD) {
CIIssuesend(static::ISSUE_MESSAGE_OPEN, DeltaDimensionType::CIRCUIT_BREAKER, DeltaAnomalyType::CIRCUIT_BREAKER_OPEN, static::ISSUE_KEY);
}
return CircuitBreakerState::OPEN;
}
// If our circuit breaker was previously open (and now closed), track this new state and mark it in our issues dataset
if ($existing_error_rate >= static::FLANNEL_CALLBACK_ERROR_RATE_THRESHOLD) {
CIIssueend(static::ISSUE_MESSAGE_CLOSE, DeltaDimensionType::CIRCUIT_BREAKER, DeltaAnomalyType::CIRCUIT_BREAKER_OPEN, static::ISSUE_KEY);
}
return CircuitBreakerState::CLOSED;
}
圖5 FlannelServiceDepCircuitBreaker類的簡(jiǎn)化代碼
用戶交互
每一個(gè)斷路器中都會(huì)獲取數(shù)據(jù),并在通道檢測(cè)到問(wèn)題時(shí)發(fā)出警報(bào)。斷路器打開(kāi)后將從不同的角度呈現(xiàn)故障。一個(gè)典型的工作流程是:我們團(tuán)隊(duì)的成員注意到斷路器打開(kāi),然后向?qū)?yīng)的團(tuán)隊(duì)通道匯報(bào)詳細(xì)信息。
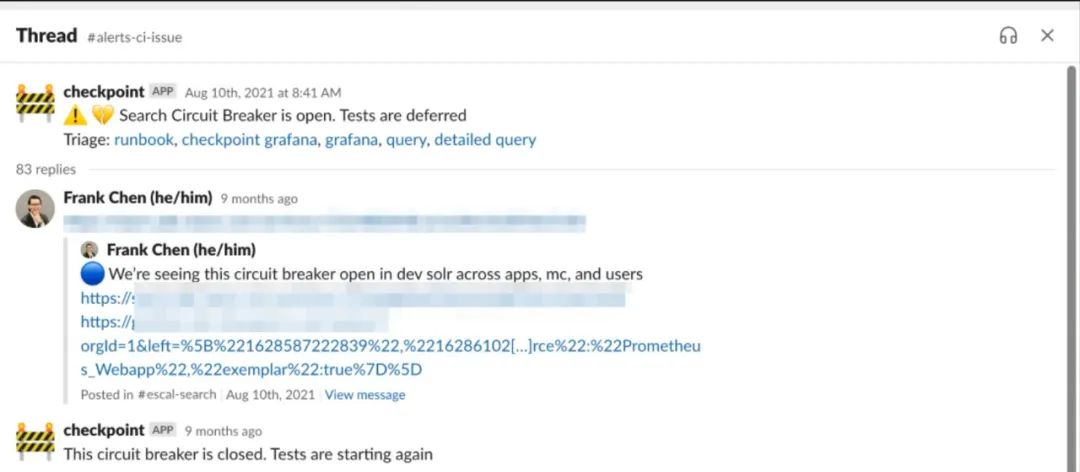
圖6. #alerts-ci-issue中的自動(dòng)斷路器信息的截圖,導(dǎo)致錯(cuò)誤率激增而將問(wèn)題報(bào)告給搜索團(tuán)隊(duì)
在自動(dòng)斷路信息中,每個(gè)環(huán)節(jié)都會(huì)顯示對(duì)同一問(wèn)題的不同看法。類似的遞延信息也會(huì)顯示在Checkpoint的客戶端,如圖7所示:

圖7自動(dòng)斷路器信息截圖:Checkpoint的PR/測(cè)試視圖中顯示服務(wù)問(wèn)題和測(cè)試狀態(tài)("Jenkins隊(duì)列目前很高,隊(duì)列下降后測(cè)試將繼續(xù)")
我們之前提到,Checkpoint對(duì)不同的服務(wù)錯(cuò)誤率進(jìn)行查詢,我們創(chuàng)建了一個(gè)小型的內(nèi)部問(wèn)題庫(kù)向Slack報(bào)告處于打開(kāi)狀態(tài)的斷路器。評(píng)估這些特定的問(wèn)題(而不是看到無(wú)差別的錯(cuò)誤峰值)逐步提高了我們對(duì)斷路器的推斷能力。此外,我們擴(kuò)展了這個(gè)問(wèn)題庫(kù),以便在測(cè)試執(zhí)行器、測(cè)試環(huán)境和測(cè)試集中進(jìn)行異常檢測(cè)(例如,高于預(yù)期的失敗、錯(cuò)誤率、持續(xù)時(shí)間或失誤率)。這些反過(guò)來(lái)又為開(kāi)發(fā)人員提供了更流暢的體驗(yàn)。
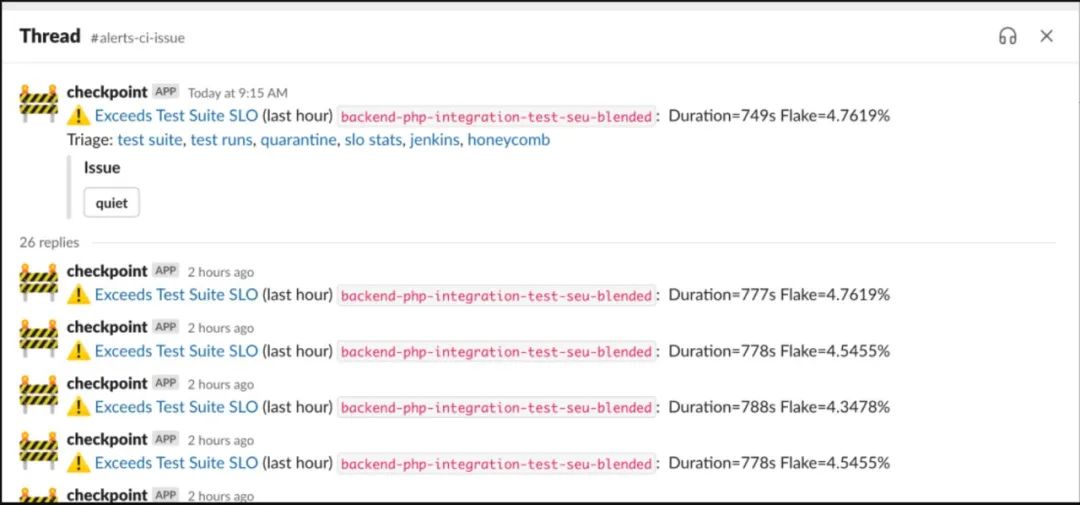
圖8 測(cè)試集執(zhí)行異常檢測(cè)的屏幕截圖
對(duì)開(kāi)發(fā)者的影響
自從引入兩套基礎(chǔ)設(shè)施和依賴性服務(wù)斷路器以來(lái),我們已經(jīng)通過(guò)延遲測(cè)試任務(wù)減少了級(jí)聯(lián)故障的面積,并通過(guò)負(fù)載消減讓測(cè)試執(zhí)行的吞吐量變得平滑。
帶來(lái)的結(jié)果是大大改善了開(kāi)發(fā)人員的體驗(yàn)。在過(guò)去的兩年里,內(nèi)部工具的級(jí)聯(lián)故障事件為零,并且,關(guān)鍵服務(wù)的負(fù)載大大降低,這有利于提升CI/CD的用戶體驗(yàn)。
而這些事故在2020年之前是很常見(jiàn)的。我們定期對(duì)CI編排中的依賴服務(wù)負(fù)載進(jìn)行編程式查詢來(lái)遇到新的峰值負(fù)載。在最近的Git LFS事件中,雖然癥狀與早期的事故相似,但情況會(huì)被定位到測(cè)試執(zhí)行器,團(tuán)隊(duì)能夠修復(fù)和隔離故障,而不會(huì)出現(xiàn)級(jí)聯(lián)故障。
現(xiàn)在,當(dāng)工程師的測(cè)試被推遲到系統(tǒng)恢復(fù)時(shí),他們會(huì)從Checkpoint的客戶端得到反饋。在使用斷路器之前,這些測(cè)試會(huì)因?yàn)橄掠蜗到y(tǒng)的過(guò)載而出現(xiàn)故障。推遲測(cè)試總體上降低了自動(dòng)化測(cè)試的不穩(wěn)定性,同時(shí)也降低了多個(gè)測(cè)試執(zhí)行任務(wù)之間的相關(guān)性。
圖9顯示了測(cè)試請(qǐng)求的巨大變化,這些測(cè)試請(qǐng)求與最初commit測(cè)試請(qǐng)求的工程師不再相關(guān)(例如,更新的提交),這些測(cè)試請(qǐng)求需要多次重復(fù)測(cè)試來(lái)解決不穩(wěn)定性。注意每個(gè)斷路器實(shí)現(xiàn)期(2020年3月和2020年8月)后的兩條曲線變化。
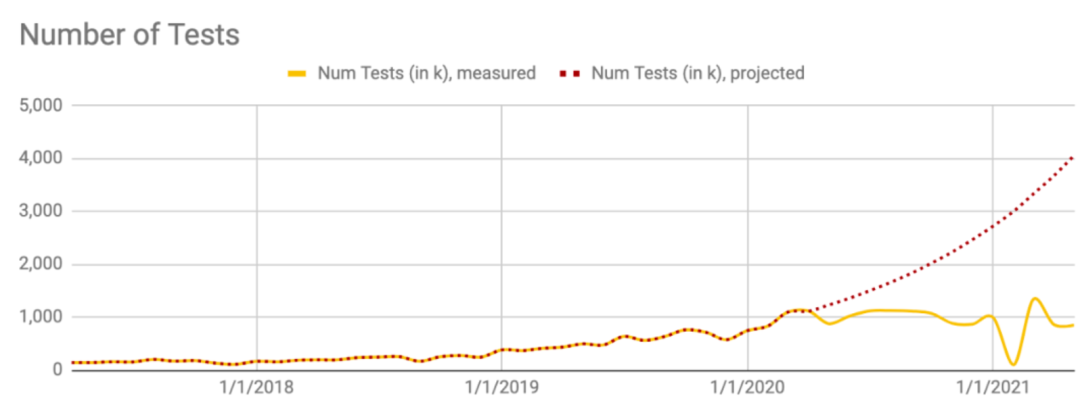
圖9基于10%增長(zhǎng)的已執(zhí)行測(cè)試集的預(yù)測(cè)(紅色),以及消減負(fù)載并延遲任務(wù)后的曲線變化(黃色)
最后,為了了解測(cè)試的反饋回路,使用CI流水線的團(tuán)隊(duì)已經(jīng)統(tǒng)一了一個(gè)業(yè)務(wù)指標(biāo) "測(cè)試結(jié)果獲取時(shí)間"(time to test results)。這個(gè)指標(biāo)考察的是開(kāi)發(fā)人員從CI中執(zhí)行的構(gòu)建和測(cè)試任務(wù)中獲得結(jié)果所需要的實(shí)際。團(tuán)隊(duì)成員擔(dān)心的是,添加斷路器以推遲或減輕負(fù)載與快速獲得持續(xù)集成結(jié)果是背道而馳的。在過(guò)去的幾年里,這個(gè)指標(biāo)并沒(méi)有向錯(cuò)誤的方向發(fā)展(更慢),而是一直很穩(wěn)定,因?yàn)樵S多相同的測(cè)試都會(huì)失敗,然后向用戶顯示的是測(cè)試不穩(wěn)定的結(jié)果。
結(jié)語(yǔ)
本文分享了Slack公司的內(nèi)部CI/CD編排系統(tǒng)Checkpoint的編排級(jí)斷路器的決策要點(diǎn)和結(jié)果。
在這個(gè)項(xiàng)目之前,Slack的工程師們看到了挑戰(zhàn),因?yàn)閮?nèi)部工具的請(qǐng)求達(dá)到了新的峰值,當(dāng)一個(gè)系統(tǒng)出現(xiàn)故障,就可能將故障級(jí)聯(lián)到其他系統(tǒng)。斷路器位于CI流水線中的各系統(tǒng)之間的接口,可以最大限度地減少級(jí)聯(lián)故障。
自從該項(xiàng)目在2020年完成后,工程師們?cè)谑褂脙?nèi)部工具鏈時(shí)不再遇到系統(tǒng)間的級(jí)聯(lián)故障。工程師們還看到了服務(wù)可用性的提高,Checkpoint的整體吞吐量的提升,以及更少的不良開(kāi)發(fā)者體驗(yàn),如失敗的服務(wù)帶來(lái)的測(cè)試不穩(wěn)定。斷路器的實(shí)現(xiàn)對(duì)整個(gè)Slack的工程師的生產(chǎn)力產(chǎn)生了實(shí)質(zhì)性影響。
現(xiàn)在,多個(gè)團(tuán)隊(duì)正在嘗試使用這個(gè)程序化指標(biāo)查詢框架,通過(guò)自動(dòng)構(gòu)建、測(cè)試、部署、發(fā)布和回滾,幫助Slack實(shí)現(xiàn)持續(xù)部署。
審核編輯:劉清
-
斷路器
+關(guān)注
關(guān)注
23文章
1957瀏覽量
52063 -
MYSQL數(shù)據(jù)庫(kù)
+關(guān)注
關(guān)注
0文章
96瀏覽量
9453 -
API串口
+關(guān)注
關(guān)注
0文章
13瀏覽量
4862
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論