 誰用NumPy手推了一大波ML模型?
誰用NumPy手推了一大波ML模型?
NumPy作為 Python 生態中最受歡迎的科學計算包,很多讀者已經非常熟悉它了。
它為 Python 提供高效率的多維數組計算,并提供了一系列高等數學函數,我們可以快速搭建模型的整個計算流程。毫不負責任地說,NumPy 就是現代深度學習框架的「爸爸」。
盡管目前使用 NumPy 寫模型已經不是主流,但這種方式依然不失為是理解底層架構和深度學習原理的好方法。最近,來自普林斯頓的一位博士后將 NumPy 實現的所有機器學習模型全部開源,超過 3 萬行代碼、30 多個模型,并提供了相應的論文和一些實現的測試效果。
項目地址:https://github.com/ddbourgin/numpy-ml
粗略估計,該項目大約有 30 個主要機器學習模型,此外還有 15 個用于預處理和計算的小工具,全部.py 文件數量有 62 個之多。平均每個模型的代碼行數在 500 行以上,在神經網絡模型的 layer.py 文件中,代碼行數接近 4000。
這,應該是目前用 NumPy 手寫機器學習模型的「最高境界」吧。
誰用 NumPy 手推了一大波 ML 模型?通過項目的代碼目錄,我們能發現,作者基本上把主流模型都實現了一遍,這個工作量簡直驚為天人。作者 David Bourgin 是一位大神,于 2018 年獲得加州大學伯克利分校計算認知科學博士學位,隨后在普林斯頓大學從事博士后研究。 盡管畢業不久,David 在頂級期刊與計算機會議上都發表了一些優秀論文。在 ICML 2019 中,其關于認知模型先驗的研究就被接收為少有的 Oral 論文。 David Bourgin 就是用 NumPy 手寫 ML 模型、手推反向傳播的大神。這么多的工作量,當然還是需要很多參考資源的,David 會理解這些資源或實現,并以一種更易讀的方式寫出來。 他表示,從 autograd repo 學到了很多,但二者的不同之處在于,他顯式地進行了所有梯度計算,以突出概念/數學的清晰性。當然,這么做的缺點也很明顯,在每次需要微分一個新函數時,你都要寫出它的公式…… 估計 David Bourgin 在寫完這個項目后,機器學習基礎已經極其牢固了。項目總體介紹這個項目最大的特點是作者把機器學習模型都用 NumPy 手寫了一遍,包括更顯式的梯度計算和反向傳播過程。可以說它就是一個機器學習框架了,只不過代碼可讀性會強很多。 David Bourgin 表示他一直在慢慢寫或收集不同模型與模塊的純 NumPy 實現,它們跑起來可能沒那么快,但是模型的具體過程一定足夠直觀。每當我們想了解模型 API 背后的實現,卻又不想看復雜的框架代碼,那么它可以作為快速的參考。 文章后面會具體介紹整個項目都有什么模型,這里先簡要介紹它的整體結構。如下所示為項目文件,不同的文件夾即不同種類的代碼集。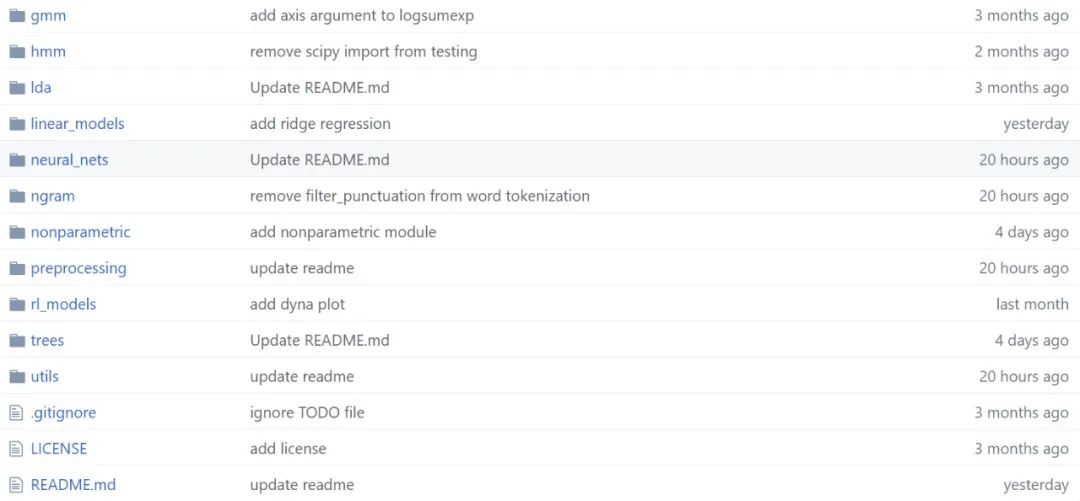 ?在每一個代碼集下,作者都會提供不同實現的參考資料,例如模型的效果示例圖、參考論文和參考鏈接等。如下所示,David 在實現神經網絡層級的過程中,還提供了參考論文。
?在每一個代碼集下,作者都會提供不同實現的參考資料,例如模型的效果示例圖、參考論文和參考鏈接等。如下所示,David 在實現神經網絡層級的過程中,還提供了參考論文。
 ?當然如此龐大的代碼總會存在一些 Bug,作者也非常希望我們能一起完善這些實現。如果我們以前用純 NumPy 實現過某些好玩的模型,那也可以直接提交 PR 請求。因為實現基本上都只依賴于 NumPy,那么環境配置就簡單很多了,大家差不多都能跑得動。手寫 NumPy 全家福作者在 GitHub 中提供了模型/模塊的實現列表,列表結構基本就是代碼文件的結構了。整體上,模型主要分為兩部分,即傳統機器學習模型與主流的深度學習模型。
其中淺層模型既有隱馬爾可夫模型和提升方法這樣的復雜模型,也包含了線性回歸或最近鄰等經典方法。而深度模型則主要從各種模塊、層級、損失函數、最優化器等角度搭建代碼架構,從而能快速構建各種神經網絡。
除了模型外,整個項目還有一些輔助模塊,包括一堆預處理相關的組件和有用的小工具。
該 repo 的模型或代碼結構如下所示:
1. 高斯混合模型
?當然如此龐大的代碼總會存在一些 Bug,作者也非常希望我們能一起完善這些實現。如果我們以前用純 NumPy 實現過某些好玩的模型,那也可以直接提交 PR 請求。因為實現基本上都只依賴于 NumPy,那么環境配置就簡單很多了,大家差不多都能跑得動。手寫 NumPy 全家福作者在 GitHub 中提供了模型/模塊的實現列表,列表結構基本就是代碼文件的結構了。整體上,模型主要分為兩部分,即傳統機器學習模型與主流的深度學習模型。
其中淺層模型既有隱馬爾可夫模型和提升方法這樣的復雜模型,也包含了線性回歸或最近鄰等經典方法。而深度模型則主要從各種模塊、層級、損失函數、最優化器等角度搭建代碼架構,從而能快速構建各種神經網絡。
除了模型外,整個項目還有一些輔助模塊,包括一堆預處理相關的組件和有用的小工具。
該 repo 的模型或代碼結構如下所示:
1. 高斯混合模型- EM 訓練
- 用變分 EM 進行 MLE 參數估計的標準模型
- 用 MCMC 進行 MAP 參數估計的平滑模型
- Add
- Flatten
- Multiply
- Softmax
- 全連接/Dense
- 稀疏進化連接
- LSTM
- Elman 風格的 RNN
- 最大+平均池化
- 點積注意力
- 受限玻爾茲曼機 (w. CD-n training)
- 2D 轉置卷積 (w. padding 和 stride)
- 2D 卷積 (w. padding、dilation 和 stride)
- 1D 卷積 (w. padding、dilation、stride 和 causality)
- 雙向 LSTM
- ResNet 風格的殘差塊(恒等變換和卷積)
- WaveNet 風格的殘差塊(帶有擴張因果卷積)
- Transformer 風格的多頭縮放點積注意力
- Dropout
- 歸一化
- 批歸一化(時間上和空間上)
- 層歸一化(時間上和空間上)
- SGD w/ 動量
- AdaGrad
- RMSProp
- Adam
- 常數
- 指數
- Noam/Transformer
- Dlib 調度器
- Glorot/Xavier uniform 和 normal
- He/Kaiming uniform 和 normal
- 標準和截斷正態分布初始化
- 交叉熵
- 平方差
- Bernoulli VAE 損失
- 帶有梯度懲罰的 Wasserstein 損失
- ReLU
- Tanh
- Affine
- Sigmoid
- Leaky ReLU
- Bernoulli 變分自編碼器
- 帶有梯度懲罰的 Wasserstein GAN
- 決策樹 (CART)
- [Bagging] 隨機森林
- [Boosting] 梯度提升決策樹
- 嶺回歸
- Logistic 回歸
- 最小二乘法
- 貝葉斯線性回歸 w/共軛先驗
- 最大似然得分
- Additive/Lidstone 平滑
- 簡單 Good-Turing 平滑
- 使用交叉熵方法的智能體
- 首次訪問 on-policy 蒙特卡羅智能體
- 加權增量重要采樣蒙特卡羅智能體
- Expected SARSA 智能體
- TD-0 Q-learning 智能體
- Dyna-Q / Dyna-Q+ 優先掃描
- Nadaraya-Watson 核回歸
- k 最近鄰分類與回歸
- 離散傅立葉變換 (1D 信號)
- 雙線性插值 (2D 信號)
- 最近鄰插值 (1D 和 2D 信號)
- 自相關 (1D 信號)
- 信號窗口
- 文本分詞
- 特征哈希
- 特征標準化
- One-hot 編碼/解碼
- Huffman 編碼/解碼
- 詞頻逆文檔頻率編碼
- 相似度核
- 距離度量
- 優先級隊列
- Ball tree 數據結構
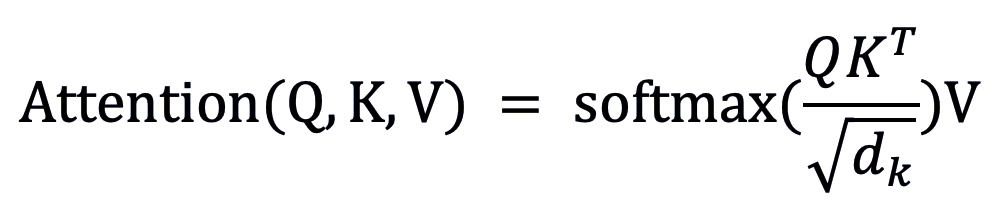
classDotProductAttention(LayerBase): def__init__(self,scale=True,dropout_p=0,init="glorot_uniform",optimizer=None): super().__init__(optimizer) self.init=init self.scale=scale self.dropout_p=dropout_p self.optimizer=self.optimizer self._init_params() def_fwd(self,Q,K,V): scale=1/np.sqrt(Q.shape[-1])ifself.scaleelse1 scores=Q@K.swapaxes(-2,-1)*scale#attentionscores weights=self.softmax.forward(scores)#attentionweights Y=weights@V returnY,weights def_bwd(self,dy,q,k,v,weights): d_k=k.shape[-1] scale=1/np.sqrt(d_k)ifself.scaleelse1 dV=weights.swapaxes(-2,-1)@dy dWeights=dy@v.swapaxes(-2,-1) dScores=self.softmax.backward(dWeights) dQ=dScores@k*scale dK=dScores.swapaxes(-2,-1)@q*scale returndQ,dK,dV 在以上代碼中,Q、K、V 三個向量輸入到「_fwd」函數中,用于計算每個向量的注意力分數,并通過 softmax 的方式得到權重。而「_bwd」函數則計算 V、注意力權重、注意力分數、Q 和 K 的梯度,用于更新網絡權重。 在一些實現中,作者也進行了測試,并給出了測試結果。如圖為隱狄利克雷(Latent Dirichlet allocation,LDA)實現進行文本聚類的結果。左圖為詞語在特定主題中的分布熱力圖。右圖則為文檔在特定主題中的分布熱力圖。
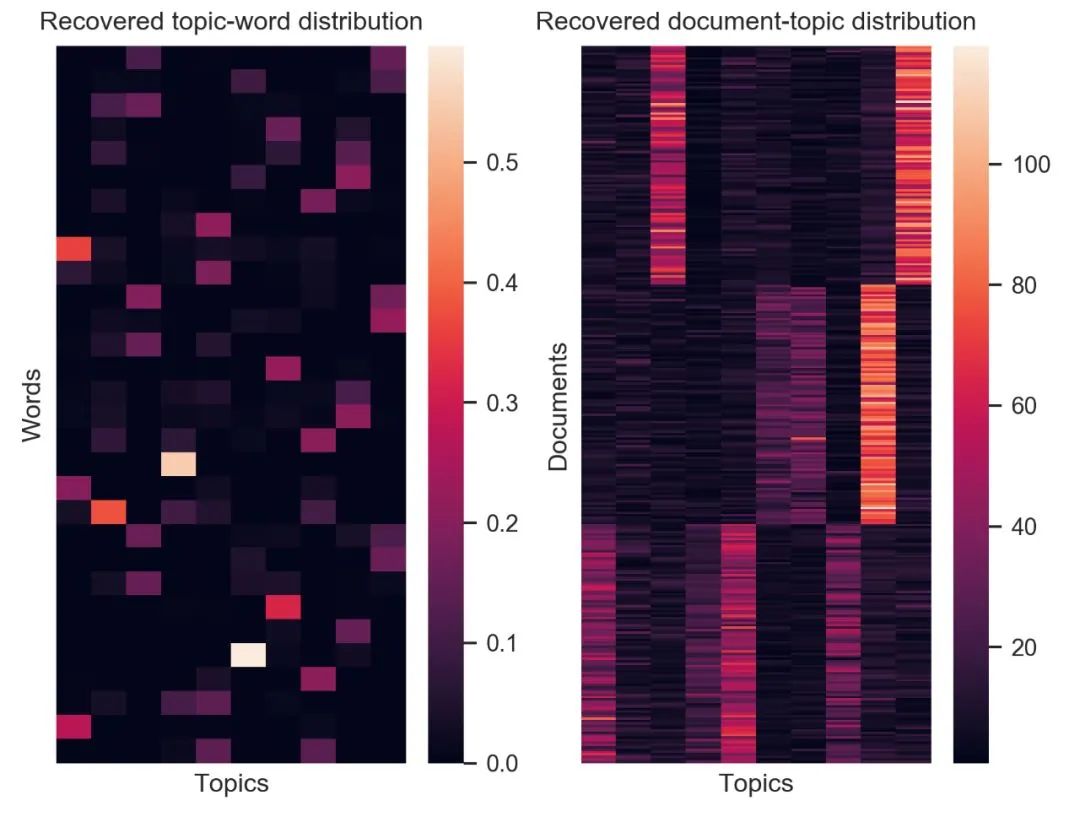 圖注:隱狄利克雷分布實現的效果。
圖注:隱狄利克雷分布實現的效果。審核編輯 :李倩
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
函數
+關注
關注
3文章
4346瀏覽量
62974 -
機器學習
+關注
關注
66文章
8439瀏覽量
133087 -
python
+關注
關注
56文章
4807瀏覽量
85040
原文標題:?Numpy手寫機器學習算法,3萬行代碼!
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
LM98640是給一個過滿度的正弦波采集大量全碼數據進行概率分布計算DNL還是給個斜坡波進行靜態測試?
是給一個過滿度的正弦波采集大量全碼數據進行概率分布計算DNL還是給個斜坡波進行靜態測試?
我用的正弦波測試結果怎么使兩頭各有
發表于 12-25 07:11
如何使用Python構建LSTM神經網絡模型
: NumPy:用于數學運算。 TensorFlow:一個開源機器學習庫,Keras是其高級API。 Keras:用于構建和訓練深度學習模型。 你可以使用pip來安裝這些庫: pip install
手搓黨分享:用Air700E開發板+毫米波雷達,搓一個睡眠監測儀!
?只能說,看到這個大佬分享的睡眠監測儀,手上的手環瞬間不香了。。。 用Air700E開發板+毫米波雷達,手搓一個開箱即用的睡眠監測儀,不花冤枉錢!


為AI、ML和數字孿生模型建立可信數據
在當今數據驅動的世界中,人工智能(AI)、機器學習(ML)和數字孿生技術正在深刻改變行業、流程和企業運營環境。每天產生的超過3.28億TB數據已成為新“石油”——為下一代數字系統提供所需的能源。
用二只OPA548組成功率輸出電路,二只管子的電流工作時一大一小,為什么?
我有一電路,用二只OPA548組成功率輸出電路,電流限在2.5A,電壓峰峰值50V,現的問題是電路輸出正弦波正常,可二只管子的電流工作時一大一小(判斷方法:從散片上摸
發表于 08-30 06:38
用TINA如何搭建仿真模型?
使用TINA仿真單極運放的環路,仿真模型知道怎么搭建,現在要仿真由兩級TL082搭建的兩級運放的環路穩定性,請教,用TINA如何搭建仿真模型,謝謝!
發表于 08-15 08:10
功率放大器在Lamb波信號波包模型驗證研究中的應用
?實驗名稱:窄帶激勵條件下的蘭姆波時域信號參數估計研究研究方向:Lamb波測試目的:基于Lamb波的二階頻散理論,提出了時域信號的波包模型,為全文奠定理論基礎。
OPA454沒有放大波形輸出是怎么回事?
你好,我用3.3V單片機輸出PWM波形(也用信號發生器模擬輸入波形),接線圖如上圖,OPA454采用單電源供電,OPA454沒有放大波形輸出,用示波器測量的信號比輸入的信號還小,麻
發表于 08-05 06:26
如何訓練一個有效的eIQ基本分類模型
在 MCX CPU和eIQ Neutron NPU上。 eIQPortal它是一個直觀的圖形用戶界面(GUI),簡化了ML開發。開發人員可以創建、優化、調試和導出ML模型,以及導入數據

Achronix新推出一款用于AI/ML計算或者大模型的B200芯片
近日舉辦的GTC大會把人工智能/機器學習(AI/ML)領域中的算力比拼又帶到了一個新的高度,這不只是說明了通用圖形處理器(GPGPU)時代的來臨

谷歌模型怎么用PS打開文件和圖片
谷歌模型本身并不是用Adobe Photoshop(簡稱PS)打開的文件和圖片格式。谷歌模型通常是用于機器學習和深度學習的模型文件,如TensorFlow






 工商網監
工商網監
評論