") 基于可變形卷積的大規(guī)模視覺(jué)基礎(chǔ)模型
基于可變形卷積的大規(guī)模視覺(jué)基礎(chǔ)模型
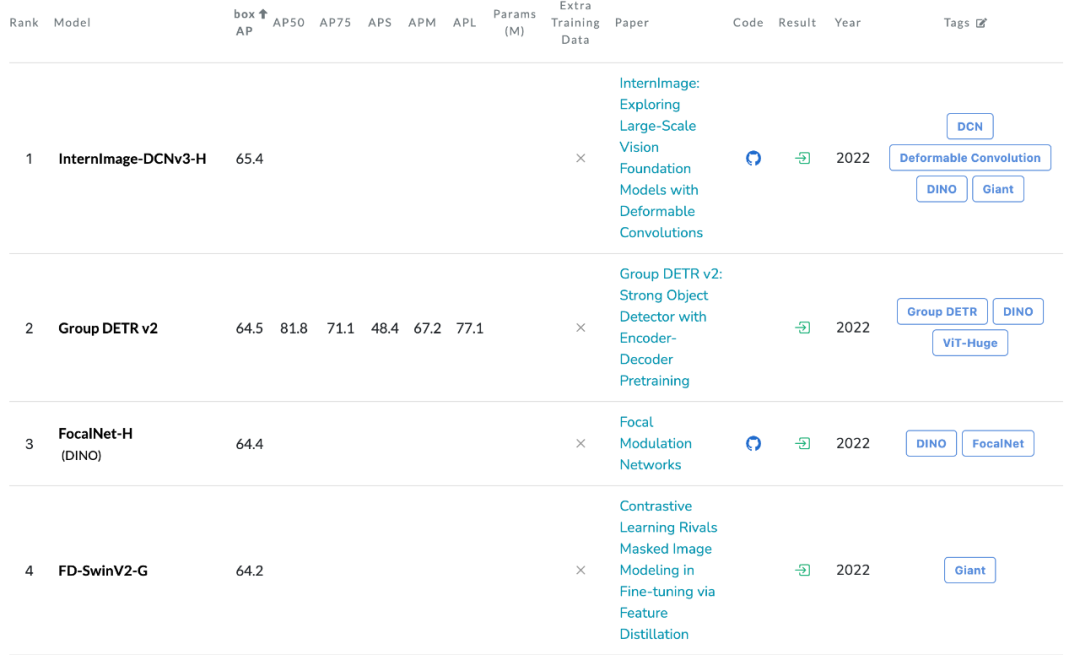
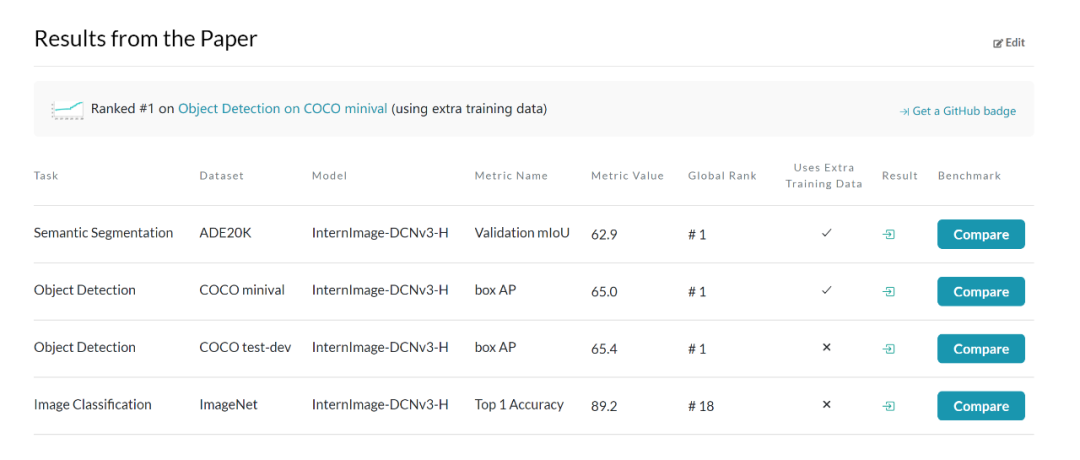
來(lái)自浦江實(shí)驗(yàn)室、清華等機(jī)構(gòu)的研究人員提出了一種新的基于卷積的基礎(chǔ)模型,稱為 InternImage,與基于 Transformer 的網(wǎng)絡(luò)不同,InternImage 以可變形卷積作為核心算子,使模型不僅具有檢測(cè)和分割等下游任務(wù)所需的動(dòng)態(tài)有效感受野,而且能夠進(jìn)行以輸入信息和任務(wù)為條件的自適應(yīng)空間聚合。InternImage-H 在 COCO 物體檢測(cè)上達(dá)到 65.4 mAP,ADE20K 達(dá)到 62.9,刷新檢測(cè)分割新紀(jì)錄。
近年來(lái)大規(guī)模視覺(jué) Transformer 的蓬勃發(fā)展推動(dòng)了計(jì)算機(jī)視覺(jué)領(lǐng)域的性能邊界。視覺(jué) Transformer 模型通過(guò)擴(kuò)大模型參數(shù)量和訓(xùn)練數(shù)據(jù)從而擊敗了卷積神經(jīng)網(wǎng)絡(luò)。來(lái)自上海人工智能實(shí)驗(yàn)室、清華、南大、商湯和港中文的研究人員總結(jié)了卷積神經(jīng)網(wǎng)絡(luò)和視覺(jué) Transformer 之間的差距。從算子層面看,傳統(tǒng)的 CNNs 算子缺乏長(zhǎng)距離依賴和自適應(yīng)空間聚合能力;從結(jié)構(gòu)層面看,傳統(tǒng) CNNs 結(jié)構(gòu)缺乏先進(jìn)組件。
針對(duì)上述技術(shù)問(wèn)題,來(lái)自浦江實(shí)驗(yàn)室、清華等機(jī)構(gòu)的研究人員創(chuàng)新地提出了一個(gè)基于卷積神經(jīng)網(wǎng)絡(luò)的大規(guī)模模型,稱為 InternImage,它將稀疏動(dòng)態(tài)卷積作為核心算子,通過(guò)輸入相關(guān)的信息為條件實(shí)現(xiàn)自適應(yīng)空間聚合。InternImage 通過(guò)減少傳統(tǒng) CNN 的嚴(yán)格歸納偏置實(shí)現(xiàn)了從海量數(shù)據(jù)中學(xué)習(xí)到更強(qiáng)大、更穩(wěn)健的大規(guī)模參數(shù)模式。其有效性在包括圖像分類(lèi)、目標(biāo)檢測(cè)和語(yǔ)義分割等視覺(jué)任務(wù)上得到了驗(yàn)證。并在 ImageNet、COCO 和 ADE20K 在內(nèi)的挑戰(zhàn)性基準(zhǔn)數(shù)據(jù)集中取得了具有競(jìng)爭(zhēng)力的效果,在同參數(shù)量水平的情況下,超過(guò)了視覺(jué) Transformer 結(jié)構(gòu),為圖像大模型提供了新的方向。

InternImage: Exploring Large-Scale Vision Foundation Models with
Deformable Convolutions
論文鏈接:https://arxiv.org/abs/2211.05778
開(kāi)源代碼:https://github.com/OpenGVLab/InternImage
傳統(tǒng)卷積神經(jīng)網(wǎng)絡(luò)的局限
擴(kuò)大模型的規(guī)模是提高特征表示質(zhì)量的重要策略,在計(jì)算機(jī)視覺(jué)領(lǐng)域,模型參數(shù)量的擴(kuò)大不僅能夠有效加強(qiáng)深度模型的表征學(xué)習(xí)能力,而且能夠?qū)崿F(xiàn)從海量數(shù)據(jù)中進(jìn)行學(xué)習(xí)和知識(shí)獲取。ViT 和 Swin Transformer 首次將深度模型擴(kuò)大到 20 億和 30 億參數(shù)級(jí)別,其單模型在 ImageNet 數(shù)據(jù)集的分類(lèi)準(zhǔn)確率也都突破了 90%,遠(yuǎn)超傳統(tǒng) CNN 網(wǎng)絡(luò)和小規(guī)模模型,突破了技術(shù)瓶頸。但是,傳統(tǒng)的 CNN 模型由于缺乏長(zhǎng)距離依賴和空間關(guān)系建模能力,無(wú)法實(shí)現(xiàn)同 Transformer 結(jié)構(gòu)相似的模型規(guī)模擴(kuò)展能力。研究者總結(jié)了傳統(tǒng)卷積神經(jīng)網(wǎng)絡(luò)與視覺(jué) Transformer 的不同之處:
(1)從算子層面來(lái)看,視覺(jué) Transformer 的多頭注意力機(jī)制具有長(zhǎng)距離依賴和自適應(yīng)空間聚合能力,受益于此,視覺(jué) Transformer 可以從海量數(shù)據(jù)中學(xué)到比 CNN 網(wǎng)絡(luò)更加強(qiáng)大和魯棒的表征。
(2)從模型架構(gòu)層面來(lái)看,除了多頭注意力機(jī)制,視覺(jué) Transformer 擁有 CNN 網(wǎng)絡(luò)不具有的更加先進(jìn)的模塊,例如 Layer Normalization (LN), 前饋神經(jīng)網(wǎng)絡(luò) FFN, GELU 等。
盡管最近的一些工作嘗試使用大核卷積來(lái)獲取長(zhǎng)距離依賴,但是在模型尺度和精度方面都與最先進(jìn)的視覺(jué) Transformer 有著一定距離。
可變形卷積網(wǎng)絡(luò)的進(jìn)一步拓展
InternImage 通過(guò)重新設(shè)計(jì)算子和模型結(jié)構(gòu)提升了卷積模型的可擴(kuò)展性并且緩解了歸納偏置,包括(1)DCNv3 算子,基于 DCNv2 算子引入共享投射權(quán)重、多組機(jī)制和采樣點(diǎn)調(diào)制。(2)基礎(chǔ)模塊,融合先進(jìn)模塊作為模型構(gòu)建的基本模塊單元(3)模塊堆疊規(guī)則,擴(kuò)展模型時(shí)規(guī)范化模型的寬度、深度、組數(shù)等超參數(shù)。
該工作致力于構(gòu)建一個(gè)能夠有效地?cái)U(kuò)展到大規(guī)模參數(shù)的 CNN 模型。首先,重新設(shè)計(jì)的可變形卷積算子 DCNv2 以適應(yīng)長(zhǎng)距離依賴和弱化歸納偏置;然后,將調(diào)整后的卷積算子與先進(jìn)組件相結(jié)合,建立了基礎(chǔ)單元模塊;最后,探索并實(shí)現(xiàn)模塊的堆疊和縮放規(guī)則,以建立一個(gè)具有大規(guī)模參數(shù)的基礎(chǔ)模型,并且可以從海量數(shù)據(jù)中學(xué)習(xí)到強(qiáng)大的表征。
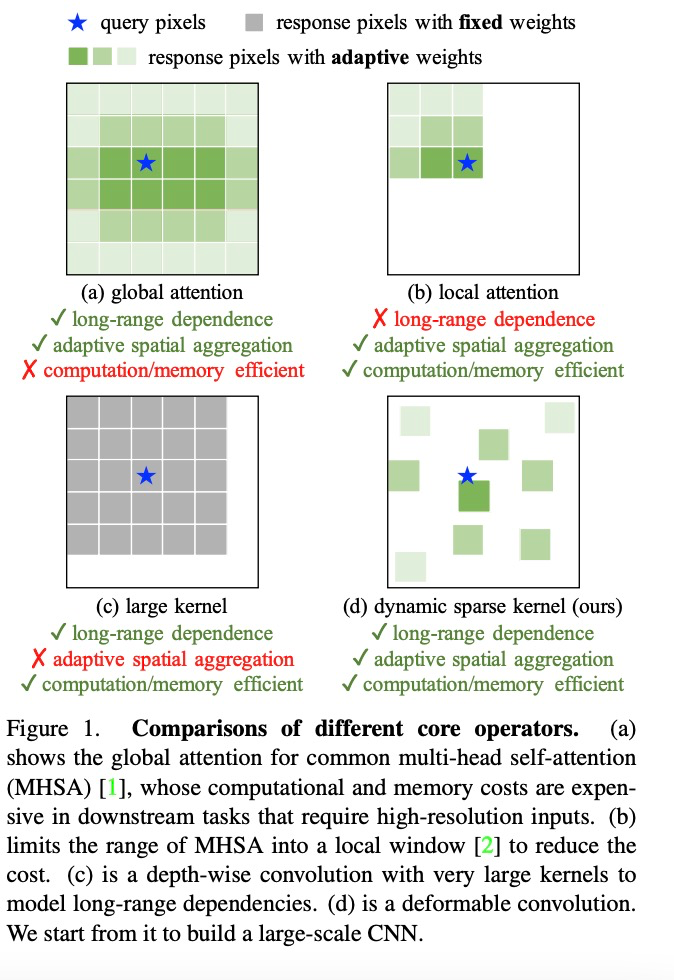
算子層面,該研究首先總結(jié)了卷積算子與其他主流算子的主要區(qū)別。當(dāng)前主流的 Transformer 系列模型主要依靠多頭自注意力機(jī)制實(shí)現(xiàn)大模型構(gòu)建,其算子具有長(zhǎng)距離依賴性,足以構(gòu)建遠(yuǎn)距離特征間的連接關(guān)系,還具有空間的自適應(yīng)聚合能力以實(shí)現(xiàn)構(gòu)建像素級(jí)別的關(guān)系。但這種全局的注意力機(jī)制其計(jì)算和存儲(chǔ)需求量巨大,很難實(shí)現(xiàn)高效訓(xùn)練和快速收斂。同樣的,局部注意力機(jī)制缺乏遠(yuǎn)距離特征依賴。大核密集卷積由于沒(méi)有空間聚合能力,而難以克服卷積天然的歸納偏置,不利于擴(kuò)大模型。因此,InternImage 通過(guò)設(shè)計(jì)動(dòng)態(tài)稀疏卷積算子,達(dá)到實(shí)現(xiàn)全局注意力效果的同時(shí)不過(guò)多浪費(fèi)計(jì)算和存儲(chǔ)資源,實(shí)現(xiàn)高效訓(xùn)練。
研究者基于 DCNv2 算子,重新設(shè)計(jì)調(diào)整并提出 DCNv3 算子,具體改進(jìn)包括以下幾個(gè)部分。
(1)共享投射權(quán)重。與常規(guī)卷積類(lèi)似,DCNv2 中的不同采樣點(diǎn)具有獨(dú)立的投射權(quán)重,因此其參數(shù)大小與采樣點(diǎn)總數(shù)呈線性關(guān)系。為了降低參數(shù)和內(nèi)存復(fù)雜度,借鑒可分離卷積的思路,采用與位置無(wú)關(guān)的權(quán)重代替分組權(quán)重,在不同采樣點(diǎn)之間共享投影權(quán)重,所有采樣位置依賴性都得以保留。
(2)引入多組機(jī)制。多組設(shè)計(jì)最早是在分組卷積中引入的,并在 Transformer 的多頭自注意力中廣泛使用,它可以與自適應(yīng)空間聚合配合,有效地提高特征的多樣性。受此啟發(fā),研究者將空間聚合過(guò)程分成若干組,每個(gè)組都有獨(dú)立的采樣偏移量。自此,單個(gè) DCNv3 層的不同組擁有不同的空間聚合模式,從而產(chǎn)生豐富的特征多樣性。
(3)采樣點(diǎn)調(diào)制標(biāo)量歸一化。為了緩解模型容量擴(kuò)大時(shí)的不穩(wěn)定問(wèn)題,研究者將歸一化模式設(shè)定為逐采樣點(diǎn)的 Softmax 歸一化,這不僅使大規(guī)模模型的訓(xùn)練過(guò)程更加穩(wěn)定,而且還構(gòu)建了所有采樣點(diǎn)的連接關(guān)系。
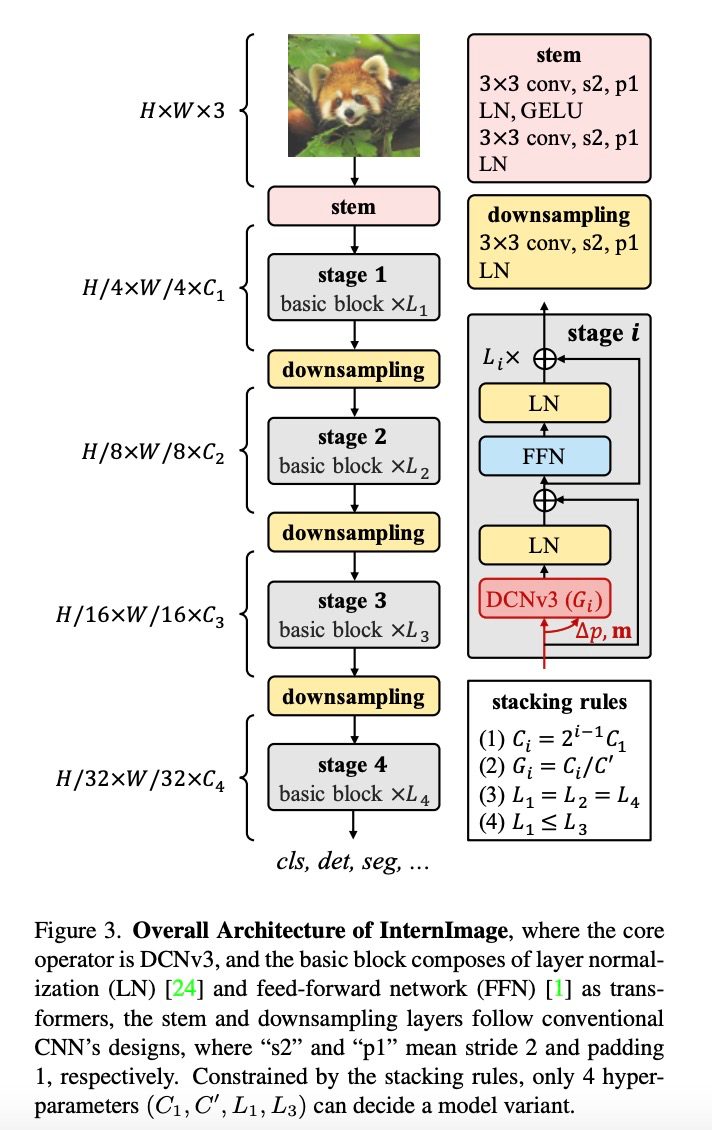
構(gòu)建 DCNv3 算子之后,接下來(lái)首先需要規(guī)范化模型的基礎(chǔ)模塊和其他層的整體細(xì)節(jié),然后通過(guò)探索這些基礎(chǔ)模塊的堆疊策略,構(gòu)建 InternImage。最后,根據(jù)所提出模型的擴(kuò)展規(guī)則,構(gòu)建不同參數(shù)量的模型。
基礎(chǔ)模塊。與傳統(tǒng) CNN 中廣泛使用的瓶頸結(jié)構(gòu)不同,該研究采用了更接近 ViTs 的基礎(chǔ)模塊,配備了更先進(jìn)的組件,包括 GELU、層歸一化(LN)和前饋網(wǎng)絡(luò)(FFN),這些都被證明在各種視覺(jué)任務(wù)中更有效率。基礎(chǔ)模塊的細(xì)節(jié)如上圖所示,其中核心算子是 DCNv3,通過(guò)將輸入特征通過(guò)一個(gè)輕量級(jí)的可分離卷積來(lái)預(yù)測(cè)采樣偏置和調(diào)制尺度。對(duì)于其他組件,遵循與普通 Transformer 相同的設(shè)計(jì)。
疊加規(guī)則。為了明確區(qū)塊堆疊過(guò)程,該研究提出兩條模塊堆疊規(guī)則,其中第一條規(guī)則是后三個(gè)階段的通道數(shù)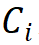 ,由第一階段的通道數(shù)
,由第一階段的通道數(shù)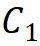 決定,即
決定,即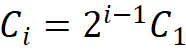 ;第二條規(guī)則是各模塊組號(hào)與各階段的通道數(shù)對(duì)應(yīng),即
;第二條規(guī)則是各模塊組號(hào)與各階段的通道數(shù)對(duì)應(yīng),即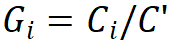 ;第三,堆疊模式固定為 “AABA”,即第 1、2 和 4 階段的模塊堆疊數(shù)是相同的
;第三,堆疊模式固定為 “AABA”,即第 1、2 和 4 階段的模塊堆疊數(shù)是相同的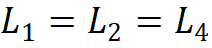 ,并且不大于第 3 階段
,并且不大于第 3 階段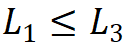 。由此選擇將參數(shù)量為 30M 級(jí)別的模型作為基礎(chǔ),其具體參數(shù)為:Steam 輸出通道數(shù)
。由此選擇將參數(shù)量為 30M 級(jí)別的模型作為基礎(chǔ),其具體參數(shù)為:Steam 輸出通道數(shù)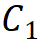 為 64;分組數(shù)為每個(gè)階段輸入通道數(shù)的 1/16,第 1、2、4 階段的模塊堆疊數(shù)
為 64;分組數(shù)為每個(gè)階段輸入通道數(shù)的 1/16,第 1、2、4 階段的模塊堆疊數(shù)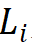 為 4,第 3 階段的模塊堆疊數(shù)
為 4,第 3 階段的模塊堆疊數(shù)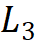 為 18,模型參數(shù)為 30M。
為 18,模型參數(shù)為 30M。
模型縮放規(guī)則。基于上述約束條件下的最優(yōu)模型,該研究規(guī)范化了網(wǎng)絡(luò)模型的兩個(gè)縮放維度:即深度 D(模塊堆疊數(shù))和寬度 C(通道數(shù)),利用限制因子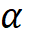 和
和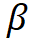 沿著復(fù)合系數(shù)
沿著復(fù)合系數(shù)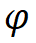 對(duì)深度和寬度進(jìn)行縮放,即,
對(duì)深度和寬度進(jìn)行縮放,即,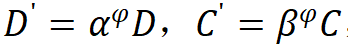 ,其中
,其中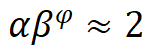 ,根據(jù)實(shí)驗(yàn)其最佳設(shè)置為
,根據(jù)實(shí)驗(yàn)其最佳設(shè)置為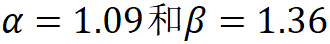 。
。
按照此規(guī)則,該研究構(gòu)建了不同尺度的模型,即 InternImage-T、S、B、L、XL。具體參數(shù)為:

實(shí)驗(yàn)結(jié)果
圖像分類(lèi)實(shí)驗(yàn):通過(guò)使用 427M 的公共數(shù)據(jù)集合:Laion-400M,YFCC15M,CC12M,InternImage-H 在 ImageNet-1K 的精度達(dá)到了 89.2%。
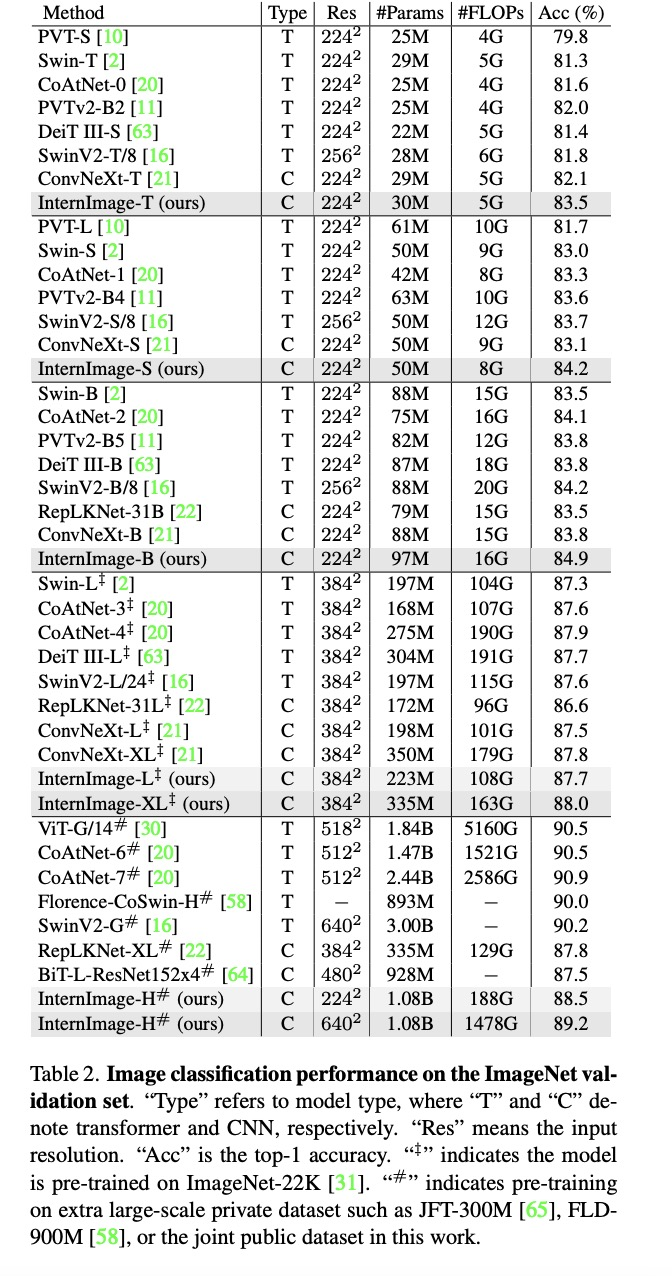
目標(biāo)檢測(cè):以最大規(guī)模的 InternImage-H 為骨干網(wǎng)絡(luò),并使用 DINO 作為基礎(chǔ)檢測(cè)框架,在 Objects365 數(shù)據(jù)集上預(yù)訓(xùn)練 DINO 檢測(cè)器,然后在 COCO 上進(jìn)行微調(diào)。該模型在目標(biāo)檢測(cè)任務(wù)中達(dá)到了 65.4% 的最優(yōu)結(jié)果,突破了 COCO 目標(biāo)檢測(cè)的性能邊界。
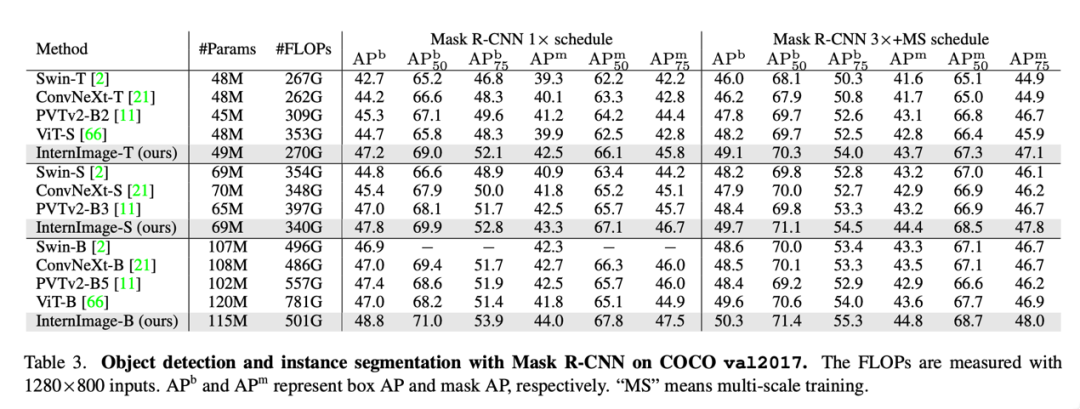
語(yǔ)義分割:在語(yǔ)義分割上,InternImage-H 同樣取得了很好的性能,結(jié)合 Mask2Former 在 ADE20K 上取得了當(dāng)前最高的 62.9%。
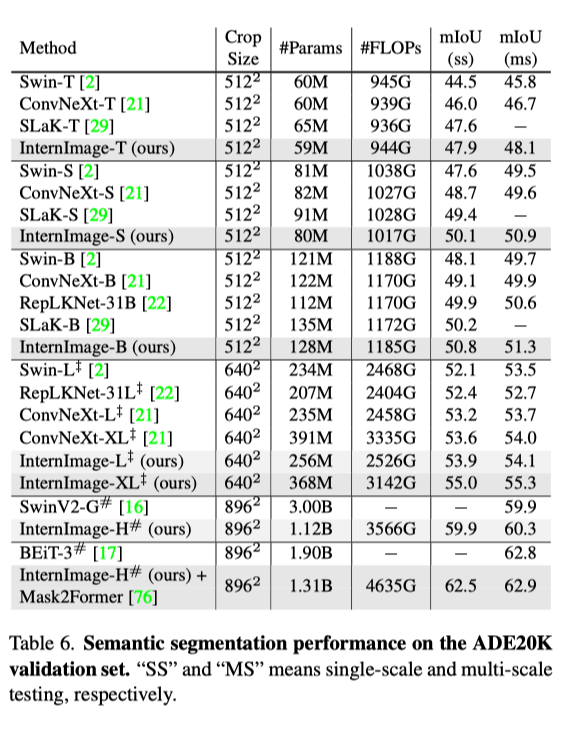
結(jié)論
該研究提出了 InternImage,這是一種新的基于 CNN 的大規(guī)模基礎(chǔ)模型,可以為圖像分類(lèi)、對(duì)象檢測(cè)和語(yǔ)義分割等多功能視覺(jué)任務(wù)提供強(qiáng)大的表示。研究者調(diào)整靈活的 DCNv2 算子以滿足基礎(chǔ)模型的需求,并以核心算子為核心開(kāi)發(fā)了一系列的 block、stacking 和 scaling 規(guī)則。目標(biāo)檢測(cè)和語(yǔ)義分割基準(zhǔn)的大量實(shí)驗(yàn)驗(yàn)證了 InternImage 可以獲得與經(jīng)過(guò)大量數(shù)據(jù)訓(xùn)練、且精心設(shè)計(jì)的大規(guī)模視覺(jué) Transformer 相當(dāng)或更好的性能,這表明 CNN 也是大規(guī)模視覺(jué)基礎(chǔ)模型研究的一個(gè)相當(dāng)大的選擇。盡管如此,大規(guī)模的 CNN 仍處于早期發(fā)展階段,研究人員希望 InternImage 可以作為一個(gè)很好的起點(diǎn)。
審核編輯 :李倩
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4781瀏覽量
101178 -
計(jì)算機(jī)視覺(jué)
+關(guān)注
關(guān)注
8文章
1700瀏覽量
46131
原文標(biāo)題:65.4 AP!刷新COCO目標(biāo)檢測(cè)新記錄!InternImage:基于可變形卷積的大規(guī)模視覺(jué)基礎(chǔ)模型
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
AI模型部署邊緣設(shè)備的奇妙之旅:目標(biāo)檢測(cè)模型
深度學(xué)習(xí)中的卷積神經(jīng)網(wǎng)絡(luò)模型
使用EMBark進(jìn)行大規(guī)模推薦系統(tǒng)訓(xùn)練Embedding加速

電壓放大器在可變形機(jī)翼縮比模型主動(dòng)變形實(shí)驗(yàn)中的應(yīng)用
計(jì)算機(jī)視覺(jué)技術(shù)的AI算法模型
經(jīng)典卷積網(wǎng)絡(luò)模型介紹
卷積神經(jīng)網(wǎng)絡(luò)分類(lèi)方法有哪些
卷積神經(jīng)網(wǎng)絡(luò)的基本結(jié)構(gòu)和工作原理
卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練的是什么
卷積神經(jīng)網(wǎng)絡(luò)cnn模型有哪些
【大規(guī)模語(yǔ)言模型:從理論到實(shí)踐】- 閱讀體驗(yàn)
【大規(guī)模語(yǔ)言模型:從理論到實(shí)踐】- 每日進(jìn)步一點(diǎn)點(diǎn)
【大語(yǔ)言模型:原理與工程實(shí)踐】大語(yǔ)言模型的基礎(chǔ)技術(shù)
利用卷積神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)SAR目標(biāo)分類(lèi)的研究






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論