") 擴(kuò)散模型再下一城! 故事配圖這個(gè)活可以交給AI了
擴(kuò)散模型再下一城! 故事配圖這個(gè)活可以交給AI了
以后,故事配圖這個(gè)活可以交給 AI 了。
你有沒(méi)有發(fā)現(xiàn),最近大火的擴(kuò)散模型如 DALL·E 2、Imagen 和 Stable Diffusion,雖然在文本到圖像生成方面可圈可點(diǎn),但它們只是側(cè)重于單幅圖像生成,假如要求它們生成一系列連貫的圖像如漫畫(huà),可能表現(xiàn)就差點(diǎn)意思了。
生成具有故事性的漫畫(huà)可不是那么簡(jiǎn)單,不光要保證圖像質(zhì)量,畫(huà)面的連貫性也占有非常重要的地位,如果生成的圖像前后連貫性較差,故事中的人物像素成渣,給人一種看都不想看的感覺(jué),就像下圖展示的,生成的故事圖就像加了馬賽克,完全看不出圖像里有啥。

img
本文中,來(lái)自滑鐵盧大學(xué)、阿里巴巴集團(tuán)等機(jī)構(gòu)的研究者向這一領(lǐng)域發(fā)起了挑戰(zhàn):他們提出了自回歸潛在擴(kuò)散模型(auto-regressive latent diffusion model, AR-LDM),從故事可視化和故事延續(xù)入手。故事的可視化旨在合成一系列圖像,用來(lái)描述用句子組成的故事;故事延續(xù)是故事可視化的一種變體,與故事可視化的目標(biāo)相同,但基于源框架(即第一幀)完成。這一設(shè)置解決了故事可視化中的一些問(wèn)題(泛化問(wèn)題和信息限制問(wèn)題),允許模型生成更有意義和連貫的圖像。

img
論文地址:https://arxiv.org/pdf/2211.10950.pdf
具體來(lái)說(shuō), AR-LDM 采用了歷史感知編碼模塊,其包含一個(gè) CLIP 文本編碼器和 BLIP 多模態(tài)編碼器。對(duì)于每一幀,AR-LDM 不僅受當(dāng)前字幕的指導(dǎo),而且還以先前生成的圖像字幕歷史為條件。這允許 AR-LDM 生成相關(guān)且連貫的圖像。
據(jù)了解,這是第一項(xiàng)成功利用擴(kuò)散模型進(jìn)行連貫視覺(jué)故事合成的工作。
該研究的效果如何呢?例如,下圖是本文方法和 StoryDALL·E 的比較,其中 #1、2、3、4、5 分別代表第幾幀,在第 3 和第 4 幀的字幕中沒(méi)有描述汽車(chē)或背景的細(xì)節(jié),只是兩句話(huà)「#3:Fred 、 Wilma 正在開(kāi)車(chē) 」、「#4:Fred 一邊開(kāi)車(chē),一邊聽(tīng)乘客 Wilma 說(shuō)話(huà)。Wilma 抱著雙臂和 Fred 說(shuō)話(huà)時(shí)看起來(lái)很生氣。」相比較而言,AR-LDM 生成的圖像質(zhì)量明顯更高,人物臉部表情等細(xì)節(jié)清晰可見(jiàn),且生成的系列圖像更具連貫性,例如 StoryDALL·E 生成的圖像,很明顯的看到背景都不一樣,人物細(xì)節(jié)也很模糊,其生成只根據(jù)上下文文本條件,而沒(méi)有利用之前生成的圖像。相反,AR-LDM 前后給人的感覺(jué)就是一個(gè)完整的漫畫(huà)故事。
總結(jié)來(lái)說(shuō)就是,AR-LDM 表現(xiàn)出很強(qiáng)的多模態(tài)理解和圖像生成能力。它能夠精確地生成字幕描述的高質(zhì)量場(chǎng)景,并在幀間保持很強(qiáng)的一致性。此外,該研究還探索了采用 AR-LDM 來(lái)保持故事中未見(jiàn)過(guò)的角色(即代詞所指的角色,例如圖 1 最后一幀中的男人)的一致性。這種適配可以在很大程度上緩解由于對(duì)未見(jiàn)角色的不確定描述而導(dǎo)致的生成結(jié)果不一致。

img
最后,該研究在兩個(gè)數(shù)據(jù)集 FlintstonesSV 和 PororoSV 上進(jìn)行了實(shí)驗(yàn),雖然使用的數(shù)據(jù)集都是卡通圖像,但該研究還引入了一個(gè)新的數(shù)據(jù)集 VIST,來(lái)更好地評(píng)估 AR-LDM 對(duì)真實(shí)世界的故事合成能力。
定量評(píng)估結(jié)果表明 AR-LDM 在故事可視化和連續(xù)任務(wù)中都實(shí)現(xiàn)了 SOTA 性能。特別是,AR-LDM 在 PororoSV 上取得了 16.59 的 FID 分?jǐn)?shù),相對(duì)于之前的故事可視化方法提高了 70%。AR-LDM 還提高了故事連續(xù)性能,在所有評(píng)估數(shù)據(jù)集上相對(duì)提高了大約 20%。此外,該研究還進(jìn)行了大規(guī)模的人類(lèi)評(píng)估,以測(cè)試 AR-LDM 在視覺(jué)質(zhì)量、相關(guān)性和一致性的表現(xiàn),這表明人類(lèi)更喜歡本文合成的故事而不是以前的方法。
方法概述
與單字幕文本到圖像任務(wù)不同,合成連貫的故事需要模型了解歷史描述和場(chǎng)景。例如下面這個(gè)故事「紅色金屬圓柱立方體位于中心,然后在右側(cè)添加一個(gè)綠色橡膠立方體」,僅第二句話(huà)無(wú)法為模型提供足夠的指導(dǎo)來(lái)生成連貫的圖像。因此對(duì)于模型來(lái)說(shuō),了解第一張生成圖像中「紅色金屬圓柱立方體」的歷史字幕、場(chǎng)景和外觀至關(guān)重要。
設(shè)計(jì)強(qiáng)大的故事合成模型的關(guān)鍵是使其能夠?qū)?dāng)前圖像生成與歷史字幕和場(chǎng)景結(jié)合起來(lái)。在這項(xiàng)工作中,研究者提出了 AR-LDM,以實(shí)現(xiàn)更好的跨幀一致性。如下圖 2a 所示,AR-LDM 利用歷史字幕和圖像來(lái)生成未來(lái)幀。圖 2b 顯示了 AR-LDM 的詳細(xì)架構(gòu)。
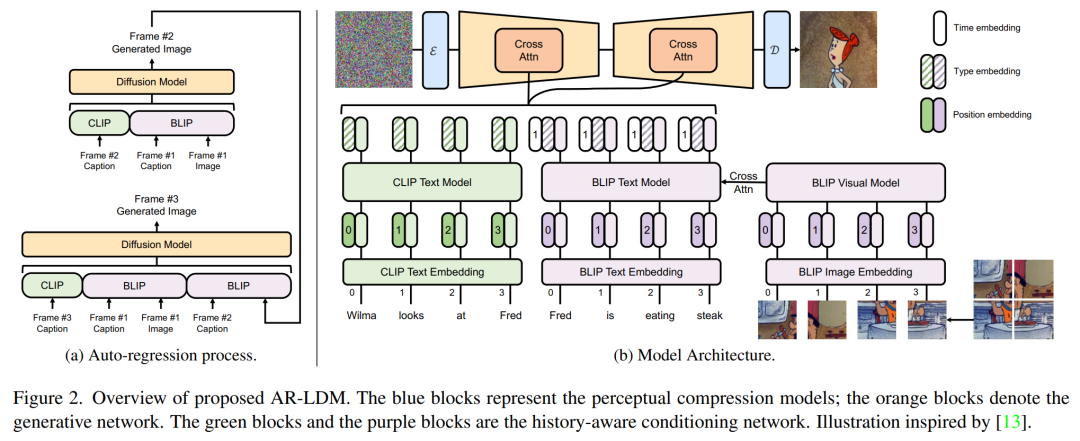
img
現(xiàn)有工作假設(shè)每一幀之間的條件獨(dú)立,并根據(jù)字幕生成整個(gè)視覺(jué)故事。而 AR-LDM 額外地以歷史圖像
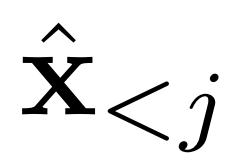
為條件來(lái)擺脫這個(gè)假設(shè),并根據(jù)鏈?zhǔn)椒▌t直接估計(jì)后驗(yàn),其形式如下
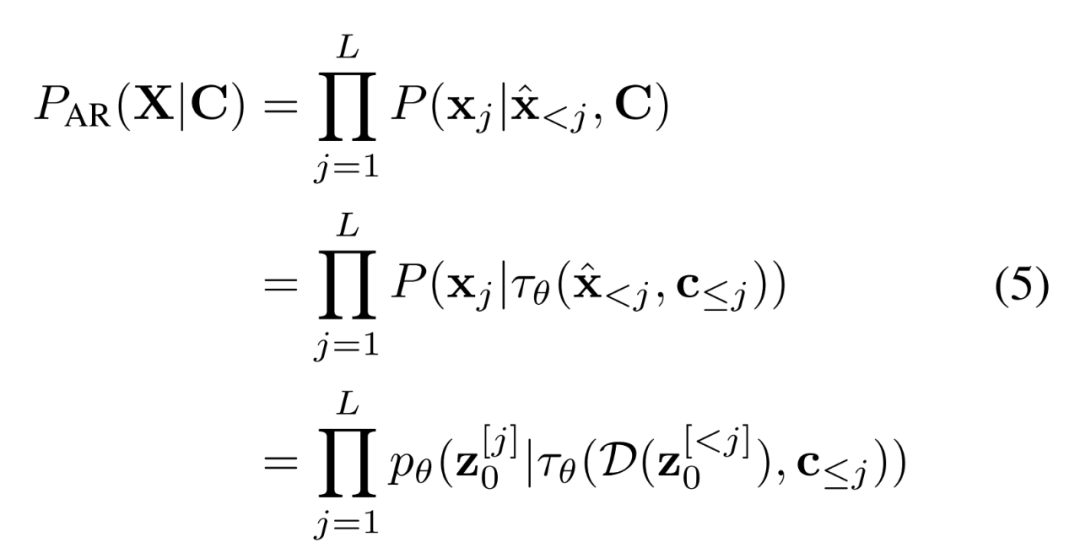
img
AR-LDM 還能在高效、低維潛在空間中執(zhí)行正向和反向擴(kuò)散過(guò)程。潛在空間在感知上近似等同于高維 RGB 空間,而像素中冗余的語(yǔ)義無(wú)意義信息被消除。具體地,AR-LDM 在擴(kuò)散過(guò)程中使用潛在表示
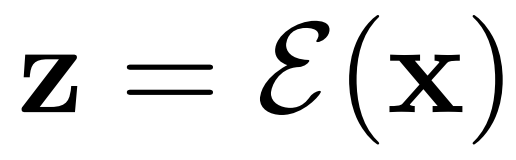
代替像素,最終輸出可以用 D(z) 解碼回像素空間。單獨(dú)的輕度感知壓縮階段僅消除難以察覺(jué)的細(xì)節(jié),使模型能夠以更低的訓(xùn)練和推理成本獲得具有競(jìng)爭(zhēng)力的生成結(jié)果。
研究者使用歷史感知條件網(wǎng)絡(luò)將歷史字幕 - 圖像對(duì)編碼為多模態(tài)條件
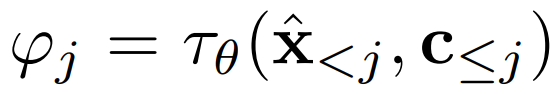
,以指導(dǎo)去噪過(guò)程
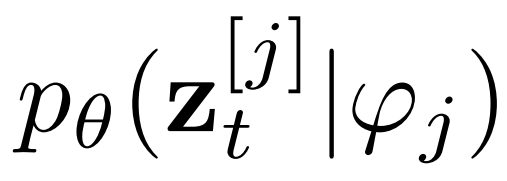
。條件網(wǎng)絡(luò)由 CLIP 和 BLIP 組成,分別負(fù)責(zé)當(dāng)前字幕編碼和先前字幕圖像編碼。BLIP 使用視覺(jué)語(yǔ)言理解和生成任務(wù)與大規(guī)模過(guò)濾干凈的 Web 數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練。總之,AR-LDM可以通過(guò)以下公式生成圖像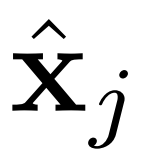 。
。
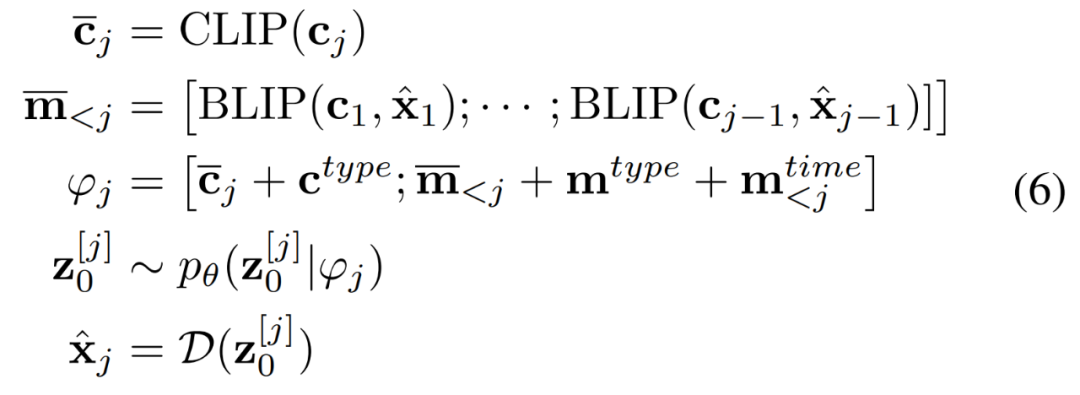
img
自適應(yīng) AR-LDM
對(duì)于漫畫(huà)等現(xiàn)實(shí)世界的應(yīng)用,有必要為新的(未見(jiàn)過(guò)的)角色保持一致性。受 Textual Inversion 和 DreamBooth 的啟發(fā),研究者添加了一個(gè)新的 token 來(lái)表示未見(jiàn)過(guò)的角色,并調(diào)整經(jīng)過(guò)訓(xùn)練的 AR-LDM 以泛化到特定的未見(jiàn)過(guò)的角色。
具體來(lái)說(shuō),新 token 的嵌入由類(lèi)似的現(xiàn)有單詞初始化,如「man」或「woman」。研究者只需要角色的 4-5 張圖像組成一個(gè)故事作為訓(xùn)練數(shù)據(jù)集,并使用 1e-5 的相同學(xué)習(xí)率對(duì)經(jīng)過(guò) 100 個(gè) epoch 的 AR-LDM 進(jìn)行微調(diào)。他們發(fā)現(xiàn)微調(diào) AR-LDM 的整個(gè)參數(shù)(僅編碼器 和解碼器 D 除外)獲得了更好的性能。
和解碼器 D 除外)獲得了更好的性能。
實(shí)驗(yàn)結(jié)果
研究者使用三個(gè)數(shù)據(jù)集作為測(cè)試平臺(tái),分別是 PororoSV、FlintstonesSV 和 VIST。這三個(gè)數(shù)據(jù)集中的每個(gè)故事都包含 5 個(gè)連續(xù)的幀。對(duì)于故事可視化,研究者從字幕中預(yù)測(cè)全部的 5 幀。對(duì)于故事連貫性,第一幀被指定為源幀,并參考源幀生成其余 4 幀。他們?cè)?8 塊 NVIDIA A100-80GB GPU 上對(duì) AR-LDM 訓(xùn)練了 50 個(gè) epoch,用時(shí)兩天。
研究者使用兩種設(shè)置評(píng)估 AR-LDM,其一是使用自動(dòng)度量 FID 分?jǐn)?shù)進(jìn)行定量評(píng)估,其二是關(guān)于視覺(jué)質(zhì)量、相關(guān)性和一致性的大規(guī)模人工評(píng)估。
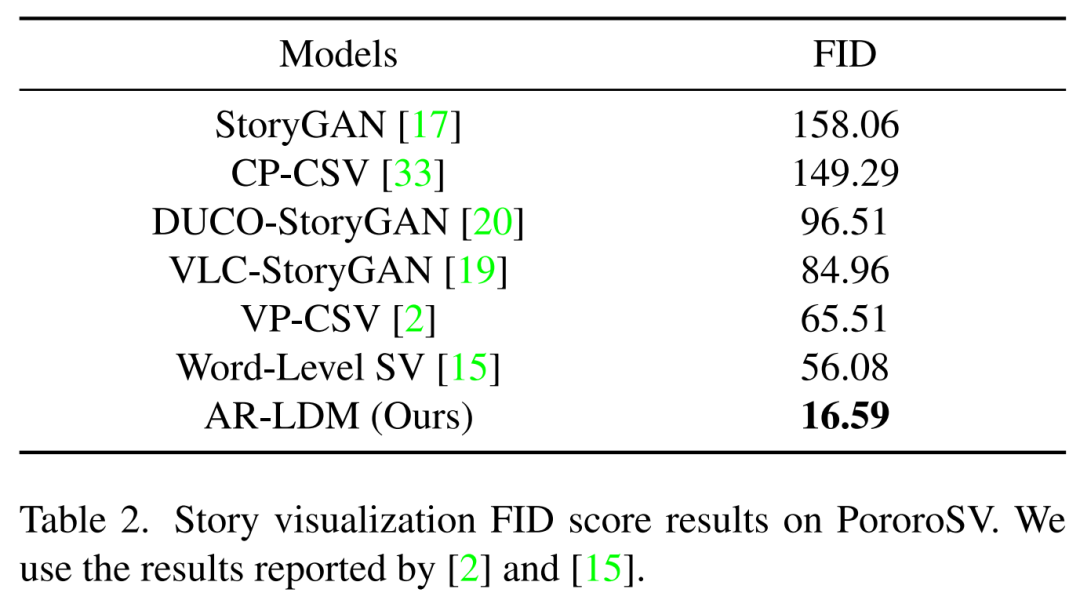
下表 2 展示了在 PororoSV 上的故事可視化結(jié)果,其中 AR-LDM 取得了重大進(jìn)步,SOTA FID 分?jǐn)?shù)得分為 16.59,大大低于以前的方法。
img
下圖 4a 中,AR-LDM 能夠生成高質(zhì)量、連貫的視覺(jué)故事,同時(shí)忠實(shí)地再現(xiàn)角色細(xì)節(jié)和背景。圖 4b 中,AR-LDM 可以通過(guò)自回歸生成保留場(chǎng)景,例如左側(cè)示例中最后兩幀的背景,以及右側(cè)示例中第三和第四幀中的塊。

img
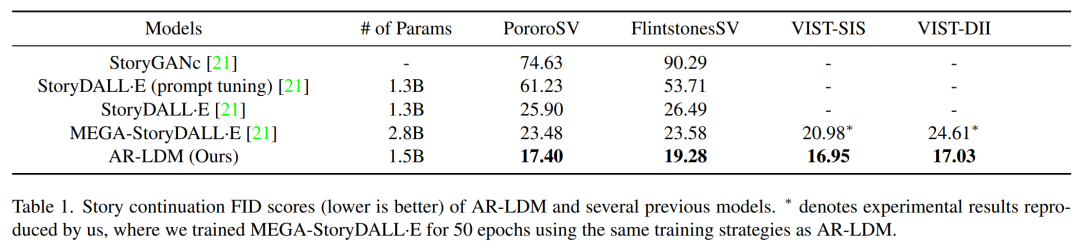
研究者測(cè)試了 AR-LDM 的故事連貫性,結(jié)果如下表 1 所示。AR-LDM 在所有四個(gè)數(shù)據(jù)集上都獲得新的 SOTA FID 分?jǐn)?shù)。值得一提的是,AR-LDM 憑借大約一半的參數(shù)優(yōu)于 MEGA-StoryDALL·E。
img
下圖 5 顯示了 FlintstonesSV 和 VIST-SIS 數(shù)據(jù)集上的更多示例,可以觀察到跨幀的場(chǎng)景一致性,例如左上角示例中第三幀和第四幀的窗戶(hù),左下角示例中的海岸場(chǎng)景。

img
下圖 6 中,與其他方法相比,具有自回歸生成方式的 AR-LDM 可以更好地跨幀保留背景和場(chǎng)景視圖。

img
下圖 7 中,所有帶下劃線(xiàn)的文本都指的是同一個(gè)角色(即源幀中戴粉色帽子的男人),而描述不一致。因此,AR-LDM 根據(jù)每一個(gè)描述生成三個(gè)不同的角色。在對(duì) 3-5 幅圖像進(jìn)行微調(diào)后,自適應(yīng) AR-LDM 可以生成一致的角色,并如字幕所描述的那樣忠實(shí)地合成場(chǎng)景和角色。

img
審核編輯 :李倩
-
AI
+關(guān)注
關(guān)注
87文章
31536瀏覽量
270348 -
模型
+關(guān)注
關(guān)注
1文章
3313瀏覽量
49232 -
可視化
+關(guān)注
關(guān)注
1文章
1200瀏覽量
21036
原文標(biāo)題:擴(kuò)散模型再下一城! 故事配圖這個(gè)活可以交給 AI 了
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
科技云報(bào)到:從大模型到云端,“AI+云計(jì)算”還能講出什么新故事
基于移動(dòng)自回歸的時(shí)序擴(kuò)散預(yù)測(cè)模型
AI模型部署邊緣設(shè)備的奇妙之旅:目標(biāo)檢測(cè)模型
浙大、微信提出精確反演采樣器新范式,徹底解決擴(kuò)散模型反演問(wèn)題

擴(kuò)散模型的理論基礎(chǔ)


助力榮耀MagicBook Pro 16,芯海科技EC芯片再下一城

聆思CSK6視覺(jué)語(yǔ)音大模型AI開(kāi)發(fā)板入門(mén)資源合集(硬件資料、大模型語(yǔ)音/多模態(tài)交互/英語(yǔ)評(píng)測(cè)SDK合集)
為什么Cubeai導(dǎo)入模型的時(shí)候報(bào)錯(cuò)[AI:persondetection] ModuleNotFoundError: No module named \'_socket\'?
搭載星火認(rèn)知大模型的AI鼠標(biāo):一鍵呼出AI助手,辦公更高效

芯海科技PC生態(tài)再下一城 EC產(chǎn)品助力榮耀首款AI PC火熱上市!

芯海科技PC生態(tài)再下一城 EC產(chǎn)品助力榮耀首款AI PC火熱上市!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論