 使用YOLOX檢測PCB的缺陷
使用YOLOX檢測PCB的缺陷
PCB(印刷電路板)
我知道,你一定在問,什么是PCB?不是嗎?對于不知道PCB是什么的人,這里有一個來自維基百科的定義:
PCB(Printed Circuit Board),中文名稱為印制電路板,又稱印刷線路板,是重要的電子部件,是電子元器件的支撐體,是電子元器件電氣相互連接的載體。由于它是采用電子印刷術制作的,故被稱為“印刷”電路板。[1]
我打賭你一生中至少見過一次PCB,但可能不想知道它是什么。以下是維基百科DVD讀取器上的PCB圖像:

PCB無處不在。幾乎所有的電子設備都有一個隱藏在其中的印刷電路板。在很多情況下,這些PCB在設計時或使用后都可能存在缺陷。
以下是互聯網上列出的PCB中一些常見缺陷的列表,以及免費提供的數據集中的示例圖像?.
1.Opens
2.Excessive solder
3.Component shifting
4.Cold joints
5.Solder bridges
6.Webbing and splashes
我們不會深入探討它們的確切含義,因為這不是博客的內容。但是,從懂一點計算機視覺和深度學習的計算機工程師的角度來看,似乎檢測PCB數字圖像中的缺陷是一個可以解決的問題。
我們將使用mmdetection? 檢測PCB圖像中的缺陷。OpenMMLab? 是一個深度學習庫,擁有計算機視覺領域大多數最先進實現的預訓練模型。它實現了幾乎所有眾所周知的視覺問題,如分類、目標檢測與分割、姿態估計、圖像生成、目標跟蹤等等。
YOLOX:2021超越YOLO系列?
本文中,我們將使用YOLOX? ,我們將微調mmdetection?. YOLOX? 是2021發布的最先進模型,是YOLO系列的改進。作者做出了一些重大改進,如下所示。
2.移除錨箱
3.注意數據增強
4.用于檢測和分類的獨立頭
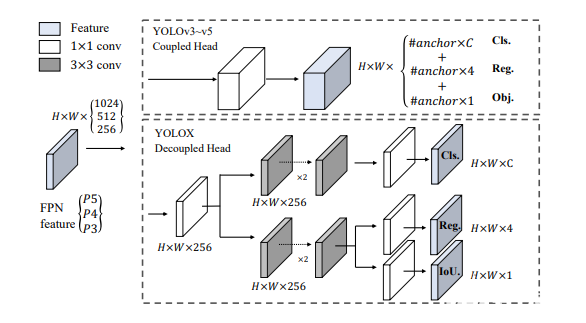
之前從v3到v5的YOLO系列都有一個單一的預測頭,其中包括邊界框預測、分類分數預測以及對象性分數預測,如上圖上半部分所示。
這在YOLOX中發生了變化? 作者選擇使用具有獨立頭的解耦頭進行所有預測的系列。
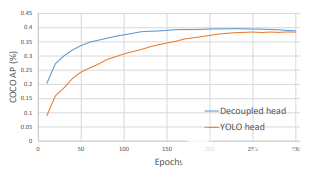
如圖所示,檢測頭和分類頭位于不同的頭中。這有助于改善訓練期間的收斂時間(如圖3所示),并略微提高模型精度。
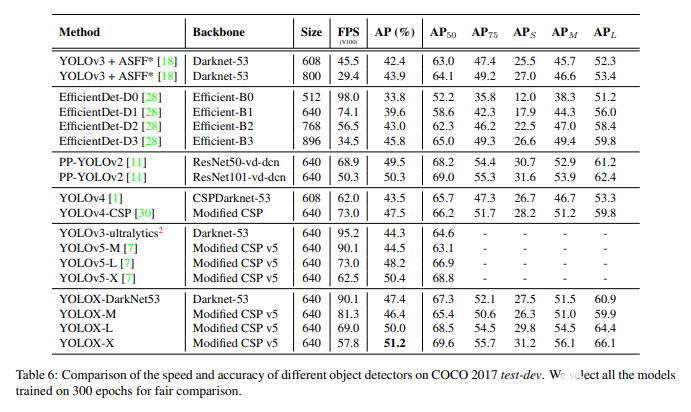
由于分離為兩個頭部,參數數量顯著增加,因此模型的速度確實受到了影響。正如我們在圖4中看到的,YOLOX-L比YOLOv5-L慢一點。它也有專門為參數低得多的邊緣設備構建的微型版本。
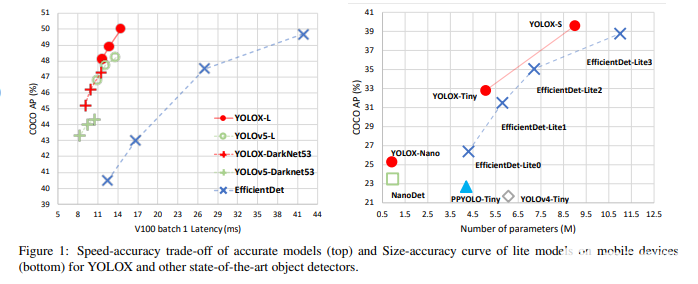
與以前最先進的對象檢測模型相比,它們在平均精度方面確實有所提高,但FPS略有下降。
最后,正如偉大的萊納斯·托瓦爾茲所說,
廢話少說。放碼過來。
讓我們直接跳到代碼里!
使用mmdetection微調YOLOX
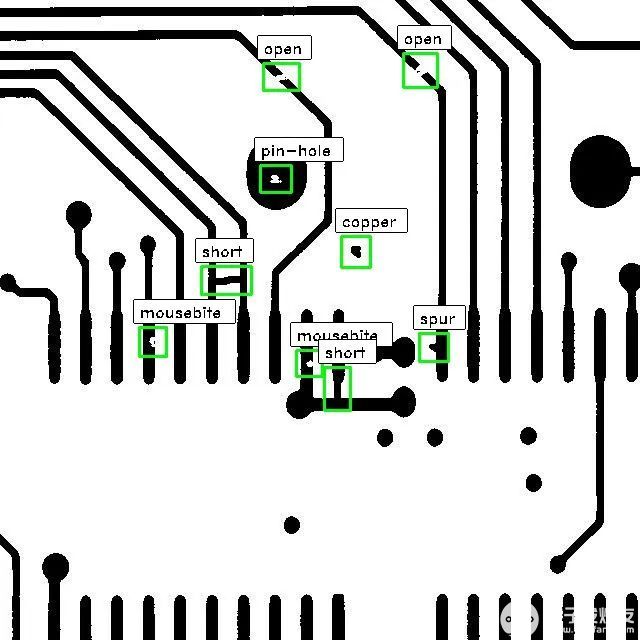
我們有一個名為DeepPCB的開源PCB缺陷數據集?. 該數據集由1500個圖像對組成,每個圖像對具有一個無缺陷模板圖像和一個具有缺陷的圖像,該圖像具有6種常見類型缺陷的邊界框注釋,即open, mouse-bite, short, spur, spurious copper, 和pin-hole。
圖像的尺寸為640×640,在我們的YOLOX案例中非常完美? 在相同的維度上進行訓練。
OpenMMLab?
OpenMMLab可以非常輕松地微調最先進的模型,只需很少的代碼更改。它具有針對特定用例的全面API。我們將使用mmdetection? 用于微調YOLOX? 在DeepPCB上? 數據集。
數據集格式
注:PCB缺陷數據集是一個開源數據集,取自具有MIT許可證的DeepPCB Github repo
我們需要將數據集修改為COCO格式或Pascal VOC格式來重新訓練模型。這是MMD檢測所必需的? 加載自定義數據集進行訓練。
出于訓練目的,我們將采用COCO格式。你無需費盡心思將數據集轉換為COCO格式,因為它已經為你完成了。你可以從這里直接下載轉換后的數據集。整個數據集與DeepPCB中的數據集相同? 只需添加帶有COCO格式注釋的訓練和測試JSON文件即可進行訓練。
我將不進行COCO格式的轉換,因為你可以找到許多文檔,就像mmdetection文檔中提到的那樣。
將此數據集轉換為COCO格式的腳本:
import json
import os
TRAIN_PATH = 'PCBData/PCBData/trainval.txt'
TEST_PATH = 'PCBData/PCBData/test.txt'
def create_data(data_path, output_path):
images = []
anns = []
with open(data_path, 'r') as f:
data = f.read().splitlines()
dataset = []
counter = 0
for idx, example in enumerate(data):
image_path, annotations_path = example.split()
image_path = os.path.join('PCBData', 'PCBData', image_path.replace('.jpg', '_test.jpg'))
annotations_path = os.path.join('PCBData', 'PCBData', annotations_path)
with open(annotations_path, 'r') as f:
annotations = f.read().splitlines()
for ann in annotations:
x, y, x2, y2 = ann.split()[:-1]
anns.append({
'image_id': idx,
'iscrowd': 0,
'area': (int(x2)-int(x)) * (int(y2)-int(y)),
'category_id': int(ann.split()[-1])-1,
'bbox': [int(x), int(y), int(x2)-int(x), int(y2)-int(y)],
'id': counter
})
counter += 1
images.append({
'file_name': image_path,
'width': 640,
'height': 640,
'id': idx
})
dataset = {
'images': images,
'annotations': anns,
'categories': [
{'id': 0, 'name': 'open'},
{'id': 1, 'name': 'short'},
{'id': 2, 'name': 'mousebite'},
{'id': 3, 'name': 'spur'},
{'id': 4, 'name': 'copper'},
{'id': 5, 'name': 'pin-hole'},
]
}
with open(output_path, 'w') as f:
json.dump(dataset, f)
create_data(TRAIN_PATH, 'train.json')
create_data(TEST_PATH, 'test.json')
數據集配置
下一步是修改數據集配置以使用自定義數據集。我們需要添加/修改特定的內容,如類的數量、注釋路徑、數據集路徑、epoch數量、基本配置路徑和一些數據加載器參數。
我們將復制一個預先編寫的YOLOX-s配置,并為我們的數據集修改它。其余的配置,如增強、優化器和其他超參數將是相同的。
我們不會改變太多,因為這個博客的主要目的是熟悉手頭的問題,嘗試最先進的YOLOX架構,并實驗mmdetection庫。我們將把這個文件命名為yolox_s_config。py并將其用于訓練。
我們將添加類名并更改預測頭的類數。由于將從根目錄而不是configs目錄加載配置,因此需要更改基本路徑。
_base_ = ['configs/_base_/schedules/schedule_1x.py', 'configs/_base_/default_runtime.py']
classes = ('open', 'short', 'mousebite', 'spur', 'copper', 'pin-hole')
bbox_head = dict(type='YOLOXHead', num_classes=6, in_channels=128, feat_channels=128)
我們需要稍微修改train dataset loader以使用我們的類和注釋路徑。
train_dataset = dict(
type='MultiImageMixDataset',
dataset=dict(
type=dataset_type,
classes=classes,
ann_file='train.json',
img_prefix='',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True)
],
filter_empty_gt=False,
),
pipeline=train_pipeline)
我們需要在這里對驗證和測試集執行相同的操作。這里我們不打算使用單獨的測試集,相反,我們將使用相同的測試集進行驗證和測試。
data = dict(
samples_per_gpu=8,
workers_per_gpu=4,
persistent_workers=True,
train=train_dataset,
val=dict(
type=dataset_type,
classes=classes,
ann_file='test.json',
img_prefix='',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
classes=classes,
ann_file='test.json',
img_prefix='',
pipeline=test_pipeline))
我們將只對模型進行20個epoch的訓練,并每5個階段獲得一次驗證結果。我們不需要再訓練了,因為我們只在20個epoch里取得了不錯的成績。
max_epochs = 20
interval = 5
訓練
我們很樂意使用數據集部分。接下來我們需要做的是訓練模型。mmdetection最棒的部分? 是,所有關于訓練的事情都已經為你們做了。你所需要做的就是從tools目錄運行訓練腳本,并將路徑傳遞給我們在上面創建的數據集配置。
python3 tools/train.py yolox_s_config.py
你已經成功訓練了!
推理
讓我們看看我們的模型在一些示例上的表現。你一定想知道,訓練模型有多容易,必須有一個命令來對圖像進行推理?
有!但是,不要讓訓練模型的簡單程序拖累了你。讓我們編寫一些用于推理的代碼,但讓你感到高興的是,它不到10行代碼。
from mmdet.apis import init_detector, inference_detector, show_result_pyplot
config_file = 'yolox_s_config.py'
checkpoint_file = 'best_bbox_mAP_epoch_20.pth'
device = 'cuda:0'
# init a detector
model = init_detector(config_file, checkpoint_file, device=device)
# inference the demo image
image_path = 'demo.jpg'
op = inference_detector(model, image_path)
show_result_pyplot(model, image_path, op, score_thr=0.6)
這將顯示一個帶有邊界框的圖像,邊界框上繪制有預測的類名。下面是一個來自數據集的示例圖像,其中包含模型預測。
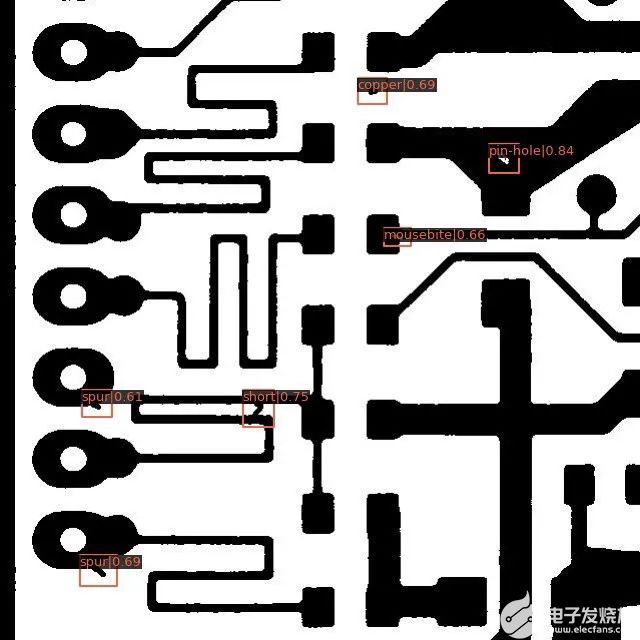
我們做到了!
你也可以嘗試我們預先訓練的模型,并使用它進行推理。
結論
今天,我們了解了現實世界中普遍存在的一個新問題,并嘗試使用像YOLOX這樣的最先進模型來解決這個問題?.
我們還使用了mmdetection? ,它是深度學習社區中用于訓練對象檢測模型的領先開源庫之一。如果我不提如何檢測,那將是不公平的? 。
在幾乎沒有任何自定義腳本的情況下,讓我們如此快速、輕松地解決問題。
磐創AI
審核編輯 :李倩
-
計算機視覺
+關注
關注
8文章
1700瀏覽量
46127 -
深度學習
+關注
關注
73文章
5513瀏覽量
121549 -
PCB
+關注
關注
1文章
1824瀏覽量
13204
發布評論請先 登錄
相關推薦
X-RAY檢測設備用于檢測集成電路缺陷瑕疵

PCB線路板常見缺陷原因分析:解鎖電路板制造的隱秘挑戰
X射線工業CT檢測設備用于復合新材料內部缺陷檢測

基于AI深度學習的缺陷檢測系統
yolox_bytetrack_osd_encode示例自帶的yolox模型效果不好是怎么回事?
外觀缺陷檢測原理

產品標簽OCR識別缺陷檢測系統方案

基于深度學習的缺陷檢測方案
蔡司工業ct內部瑕疵缺陷檢測機

賽默斐視X射線薄膜測厚儀與薄膜表面缺陷檢測
友思特應用 | 高精度呈現:PCB多類型缺陷檢測系統

如何應對工業缺陷檢測數據短缺問題?

洞察缺陷:精準檢測的關鍵

基于深度學習的芯片缺陷檢測梳理分析
2023年工業視覺缺陷檢測經驗分享






 工商網監
工商網監
評論