 使用MAX78000進行人臉識別
使用MAX78000進行人臉識別
MAX78000為超低功耗卷積神經網絡(CNN)推理引擎,用于在物聯網的微小邊緣運行人工智能(AI)計算。然而,該設備可以執行許多復雜的網絡,以實現關鍵和流行的應用。本文介紹一種在MAX78000上運行人臉識別(FaceID)的方法,該方法使用Maxim在PyTorch上的開發流程構建模型,使用不同的開放數據集進行訓練,并部署在MAX78000評估板上。
介紹
40多年來,人臉識別系統一直是研究的主題。機器學習的最新進展導致了研究的急劇增加和許多成功方法的出現。面部識別或識別技術今天比過去任何時候都更加重要,因為它非常普遍,并且引入了有關如何捕獲和共享面部信息的隱私問題。除了隱私問題外,這些應用程序的延遲和功耗對于許多移動或物聯網設備也很重要。
本應用筆記研究了使用MAX78000 CNN推理引擎在邊緣運行人臉識別(FaceID)以最小的延遲和優化的功耗。該應用面臨的挑戰是設計具有高性能的CNN架構,同時保持網絡中的系數數量比許多尖端的深人臉識別網絡(即DeepFace)少300倍。[1].
卷積神經網絡(CNN)非常有用,因為它們允許從輸入數據中學習位置和尺度無關的特征。卷積內核的長度一般較小,即 3 × 3、7 × 7 等,提供了極大的內存效率。隨著許多不同的研究表明所提供的性能提升以及模型大小的減小,對這些網絡的興趣有所增加。這種架構的缺點是計算負載較高,可能會產生高能耗和延遲。本研究通過MAX78000的獨特設計克服了這些問題。
本文簡要介紹MAX78000 CNN推理引擎,并介紹開發模型以識別適合芯片的人臉的方法。然后描述所開發模型的綜合,并解釋MAX78000評估板的應用軟件。
CNN 推理引擎 – MAX78000
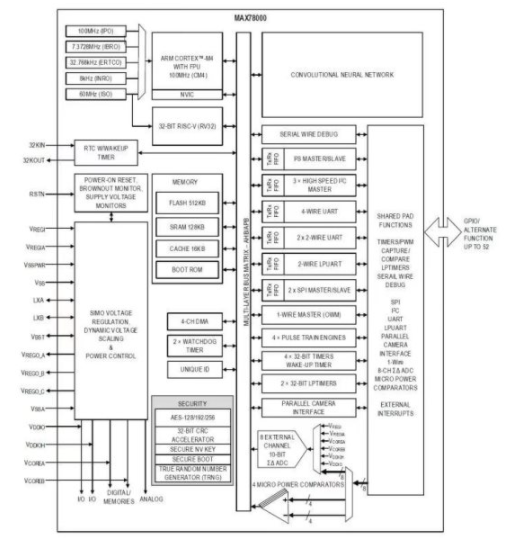
The MAX78000[2]是一種新型人工智能 (AI) 微控制器,旨在使神經網絡能夠以超低功耗執行并生活在物聯網邊緣。該產品將最節能的AI處理與Maxim經過驗證的超低功耗微控制器相結合。基于硬件的 CNN 加速器使電池供電的應用程序能夠執行 AI 推理,同時僅消耗微焦耳的能量。這使其成為能源關鍵型應用的理想架構。MAX78000具有帶浮點單元(FPU)CPU的Arm Cortex-M4,通過超低功耗深度神經網絡加速器實現高效的系統控制。圖1.MAX78000的結構顯示了MAX78000的頂層架構。??
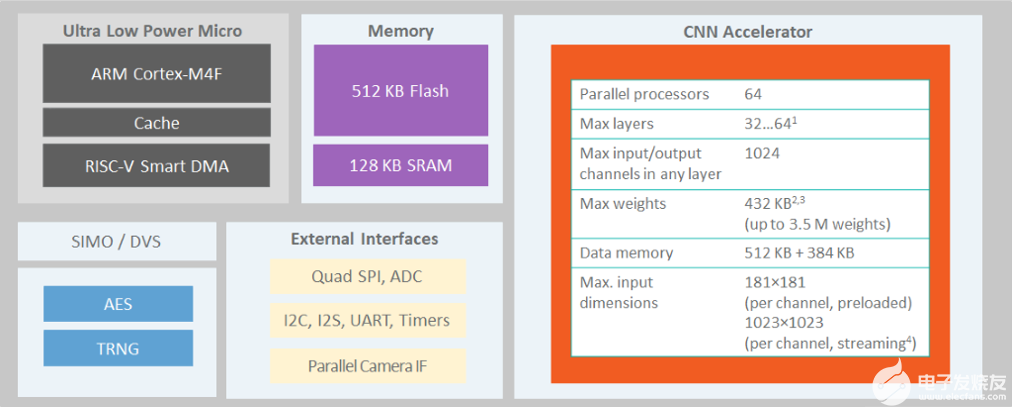
圖1.MAX78000的結構
MAX78000評估板[3]提供一個平臺,利用MAX78000的功能構建新一代AI器件。評估板具有板載硬件,如數字麥克風、串行端口、攝像頭模塊支持和3.5英寸觸摸彩色薄膜晶體管(TFT)顯示屏。
MAX78000開發流程
PyTorch或TensorFlow-Keras工具鏈可用于開發MAX78000的模型。該模型是使用一系列表示硬件的已定義子類創建的。池化或激活等一些操作融合到 1D 或 2D 卷積層以及全連接層。還添加了舍入和剪裁以匹配硬件。
該模型使用浮點權重和訓練數據進行訓練。權重可以在訓練期間(量化感知訓練)或訓練后(訓練后量化)量化。可以在評估數據集上評估量化結果,以檢查由于權重量化而導致的精度下降。
MAX78000合成器工具(ai8xize)接受PyTorch檢查點或TensorFlow導出的ONNX文件作為輸入,以及YAML格式的模型描述。輸入示例數據文件(.npy文件)也提供給合成器,以驗證硬件上的合成模型。將此數據文件的推理結果與預合成模型的預期輸出進行比較。
MAX78000頻率合成器自動生成C代碼,可在MAX78000上編譯和執行。C 代碼包括應用程序編程接口 (API) 調用,用于將權重以及提供的示例數據加載到硬件,對示例數據執行推理,并將分類結果與預期結果進行比較,作為通過/失敗健全性測試。此生成的 C 代碼可用作創建自定義應用程序的示例。圖2所示為MAX78000的整體開發流程。
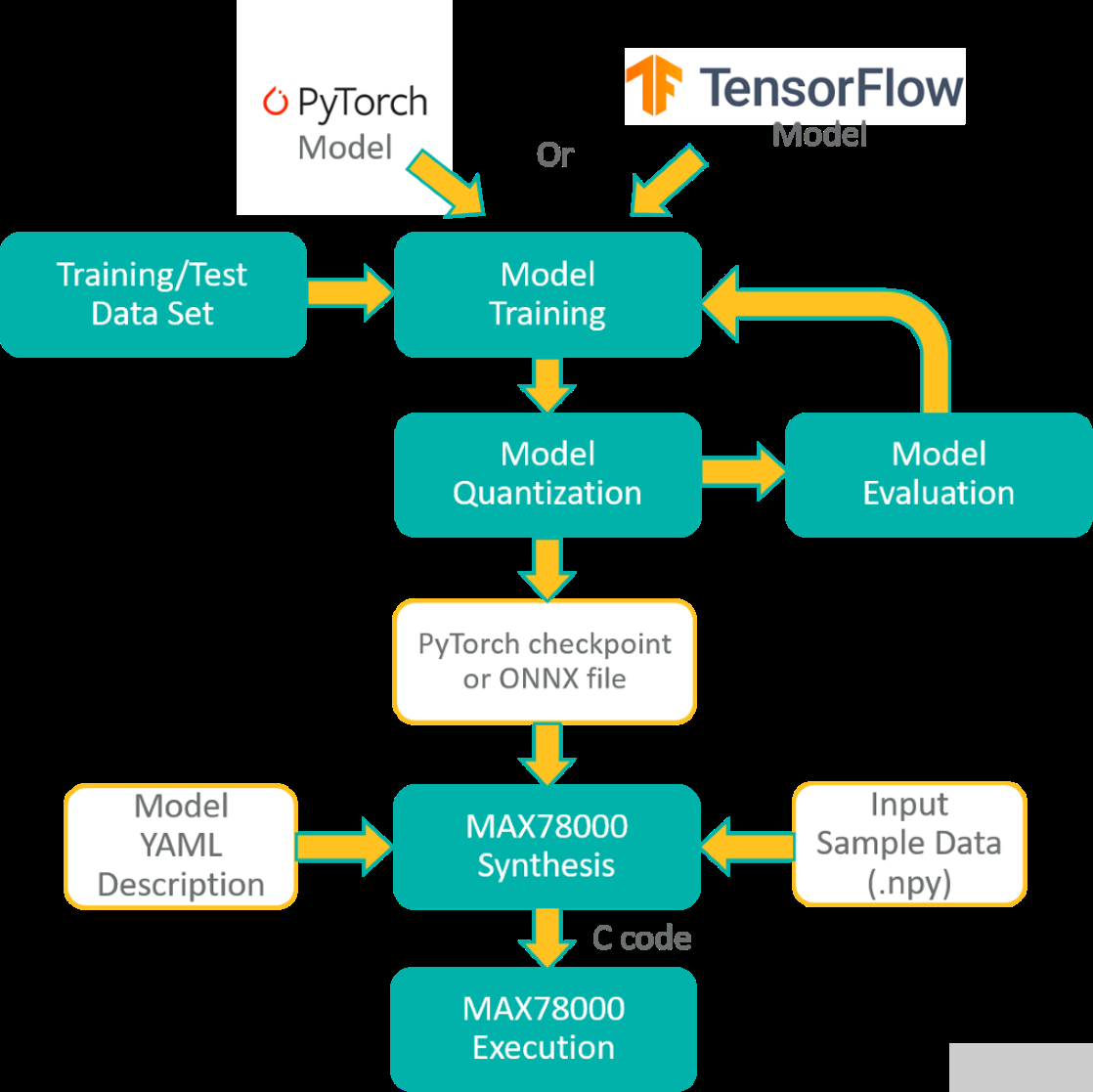
圖2.MAX78000的開發流程
面容模型開發方法
人臉識別問題分三個主要步驟解決:
人臉提取:檢測圖像中的人臉以提取僅包含一個人臉的矩形子圖像。
面部對齊:確定子圖像中面部的旋轉角度(3D),以通過仿射變換補償其效果。
人臉識別:使用提取和對齊的子圖像識別人。
前兩個步驟有不同的方法。多任務級聯卷積神經網絡 (MTCNN)[4]解決人臉檢測和對齊步驟。人臉識別通常作為一個不同的問題來研究,這是本次演示的重點。MAX78000評估板用于識別未裁剪的人臉,每張臉僅包含一個人臉。
所采用的方法基于為每個面部圖像學習簽名,即嵌入,其與另一個嵌入的距離可以衡量面部的相似性。預計可以觀察到同一個人的臉之間的距離很小,而不同人的臉之間的距離很大。
面網[5]是為基于嵌入的人臉識別方法開發的最流行的基于 CNN 的模型之一。三重損失是其成功背后的關鍵。此損失函數采用三個輸入樣本:錨點、與定位點來自同一恒等的正樣本和來自不同恒等式的負樣本。當錨點的距離接近正樣本而遠離負樣本時,三重損失函數給出較低的值(圖 3)。
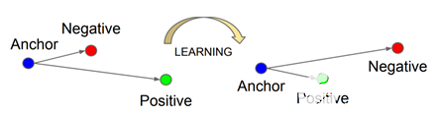
圖3.三重損耗使錨點和正極之間的距離最小化,并使錨點和負極之間的距離最大化[2].
但是,該型號有750萬個參數,對于MAX78000來說太大了。它還需要 1.6G 浮點運算,這使得該模型很難在許多移動或物聯網設備上運行。因此,設計了小于450k參數的新模型架構,以適應MAX78000。
采用知識蒸餾方法來開發FaceNet的這個更小的CNN模型,因為它是FaceID應用程序廣泛贊賞的神經網絡。
機器學習中的知識蒸餾是將知識從大型模型轉移到較小模型的過程[6].大型模型比小型模型具有更高的知識容量。然而,這一能力可能沒有得到充分利用。因此,這里的目的是將大網絡的確切行為傳授給較小的網絡。
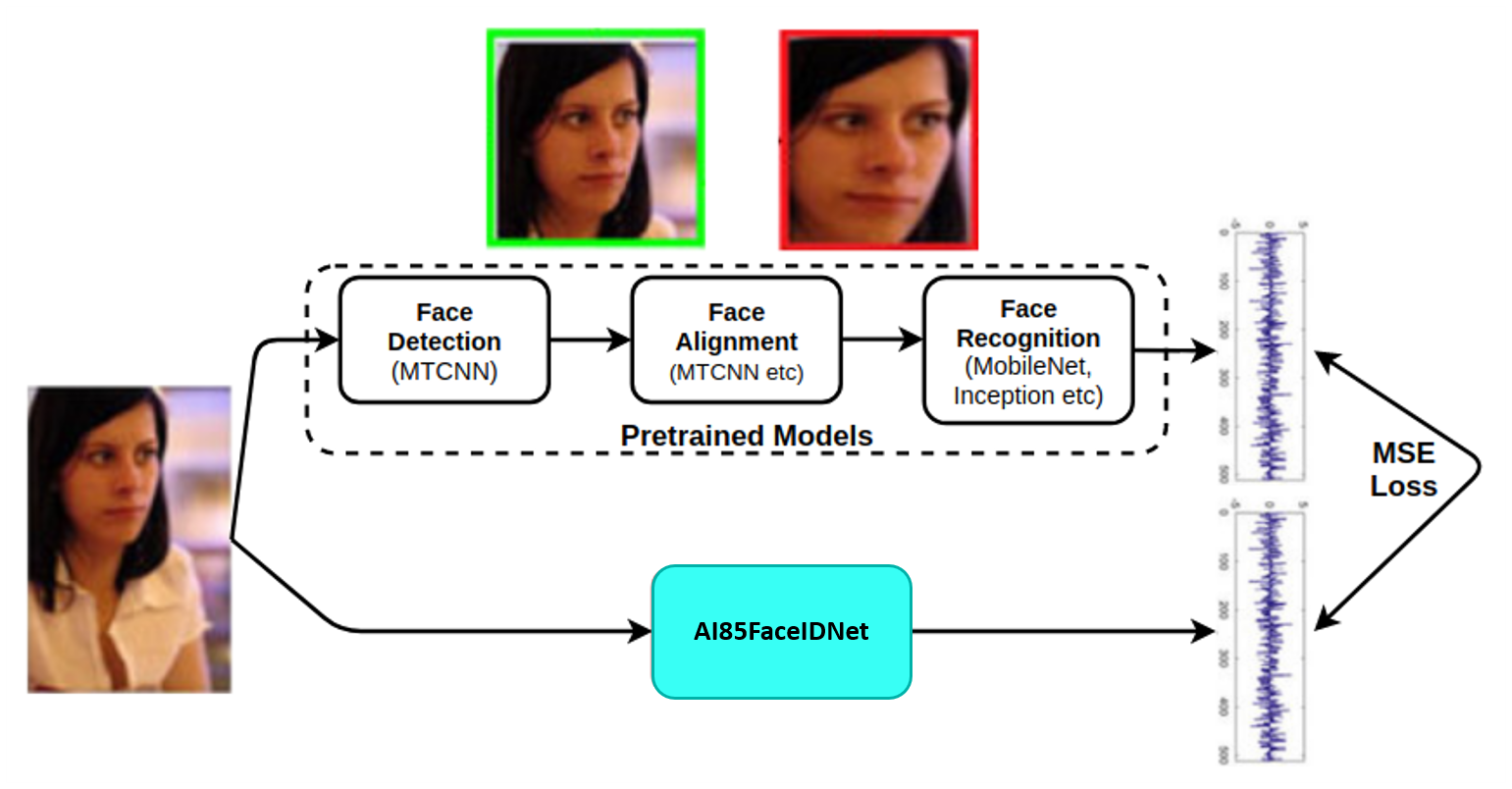
圖4.模型開發的方法。
圖4.模型開發方法總結了如何利用預訓練的MTCNN和FaceNet模型來開發緊湊的FaceID模型AI85FaceIdNet。嵌入FaceNet模型被用作AI85FaceIdNet的目標。沒有中心損失、三重損失等,因為這些都由 FaceNet 模型覆蓋。模型開發中使用的損失是目標嵌入和預測嵌入之間的均方誤差 (MSE),這也是定義人臉相似性的距離。
數據
模型的訓練是使用以下數據集完成的:
VGGFace-2 [7]:一個大規模的人臉識別數據集。
YouTube面孔[8]:旨在研究不受約束的人臉識別問題的人臉視頻數據庫。
根據網絡上找到的六張圖像為選定的 15 位女性和 15 位男性名人創建一個數據集來測試模型。此數據集在本文檔的其余部分中稱為 MaximCeleb。
數據集生成和擴充
數據集中的每個圖像隨機裁剪 120 × 160 × 3(寬度×高度×深度)子圖像。由預訓練的MTCNN模型在子圖像中檢測到并對齊的人臉被饋送到預訓練的FaceNet模型以創建嵌入。請注意,兩個重新訓練的模型都取自[9].因此,生成的嵌入的長度為 512。最后,將 120 × 160 個 RGB 面部圖像與其所有者和嵌入一起存儲,以便在訓練期間使用。
面部在新圖像中的位置和方向各不相同。預計它應該有一個模型,該模型對圖像中頭部的少量轉換具有魯棒性。
CNN 模型訓練
MAX78000 FaceID型號AI85FaceIdNet由8個順序卷積模塊組成。圖7.AI85FaceIdNet網絡結構顯示了CNN模型。某些圖層包括池化操作以減小輸入的大小。類似地,將 512 × 5 × 3 大小的張量與 (5 × 3) 核平均,以獲得最后一層的 512 大小的嵌入。

圖7.AI85人臉網絡結構。
使用以下命令使用Maxim工具對模型進行訓練:
train.py –epochs 100 –optimizer Adam –lr 0.001 –deterministic –compress schedule-faceid.yaml –model ai85faceidnet –dataset FaceID --batch-size 100 –device MAX78000 –regression
該腳本在訓練過程結束時創建模型的檢查點文件,并在驗證集上得分最高。然后,對浮點權重進行量化,MAX78000為整數運算器件。使用以下命令的Maxim工具進行轉換也很簡單:
./quantize.py --device MAX78000 -v -c networks/faceid.yaml –scale 1.05
模型性能
使用包含30位名人(15位女性和15位男性)面孔的MaximCeleb數據集分析模型的性能。
對于女性和男性數據集,通過使用其自身嵌入到其余89張圖像嵌入的距離,根據每個圖像的識別準確性,分別評估模型的性能。用于定義最近嵌入的距離度量和算法也是應用程序中的度量和算法。
在此分析中,選擇 L2(歐幾里得)范數作為嵌入之間的距離。提取所有主體的嵌入到給定圖像嵌入的平均距離,以確定最近的主體。然后,該算法返回其嵌入平均最接近給定嵌入的主題。表1顯示了MTCNN和FaceNet組合的性能,以及MAX78000上運行的AI85FaceIdNet的性能。圖 8 和圖 9 顯示了每個數據集的混淆矩陣。
| 馬克西西勒布數據集 | ||||
| 女性 | 雄 | |||
| MTCNN+FACENET | AI85面孔 | MTCNN+FACENET | AI85面孔 | |
| 準確度 (%) | 94.4 | 78.9 | 94.4 | 88.9 |
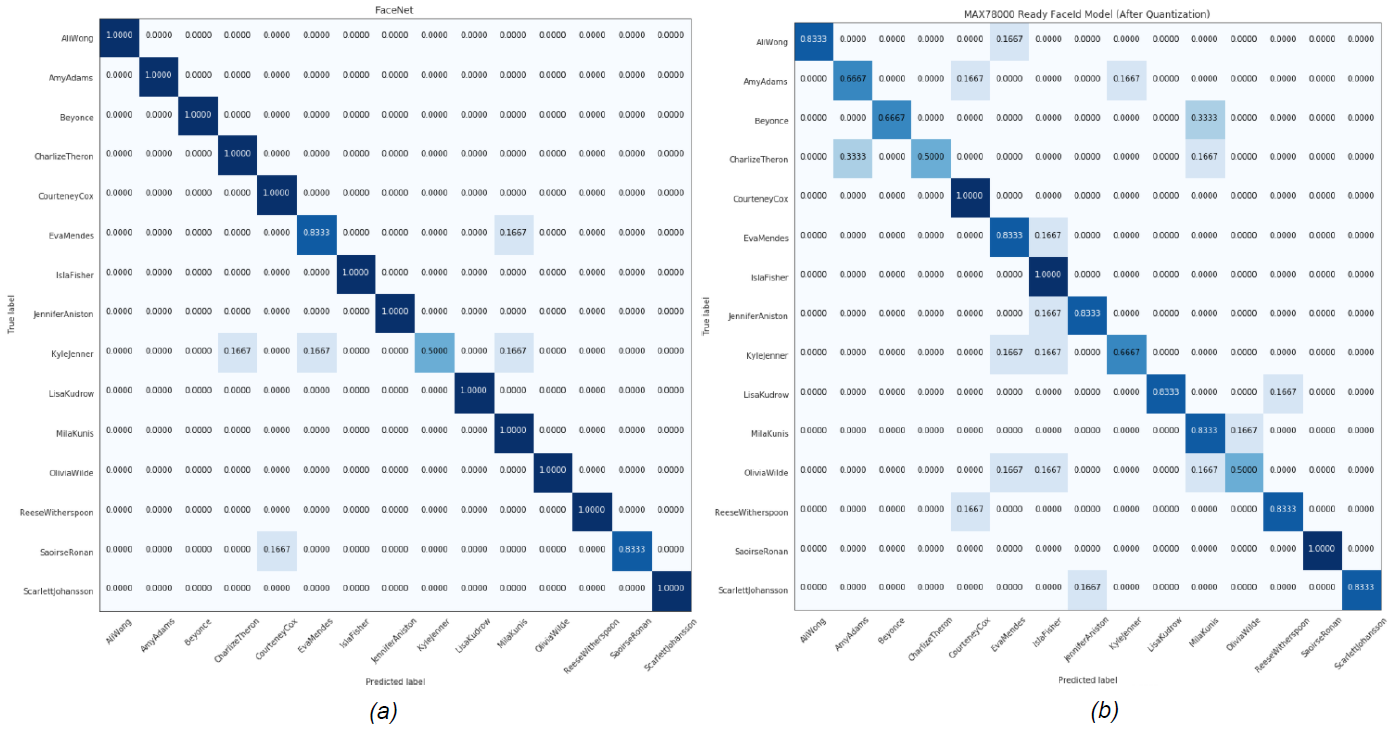
圖8.女性MaximCeleb數據集的(a)MTCNN+FaceNet (b)AI85FaceIdNet模型的混淆矩陣。
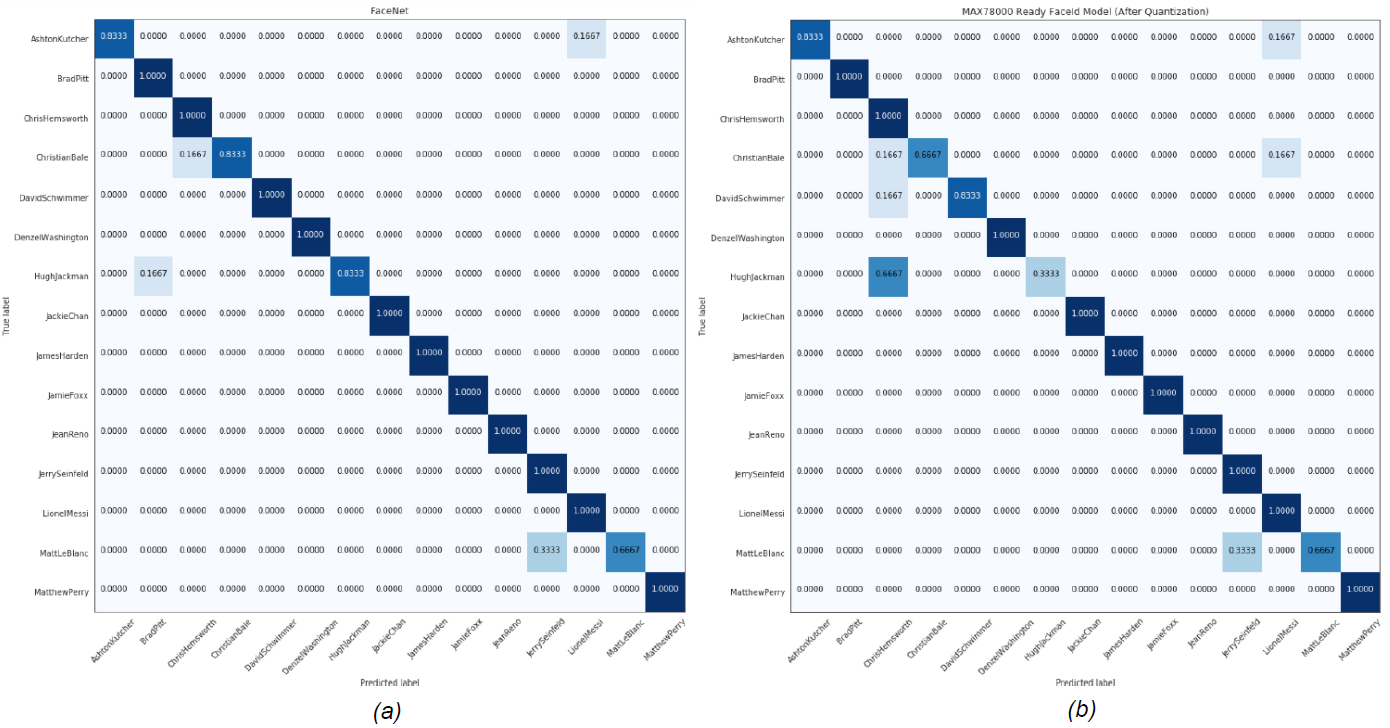
圖9.男性MaximCeleb數據集的(a)MTCNN+FaceNet(b)AI85FaceIdNet模型的混淆矩陣。
識別未知受試者
利用所開發模型的受試者工作特征(ROC)曲線來識別未知受試者。ROC 曲線是一個圖形圖,說明了二元分類器系統在其區分閾值變化時的診斷能力[10].
上一節將人臉到主體的距離定義為人臉嵌入到為每個主體存儲的整個嵌入的平均 L2 距離。決定是在確定與面部嵌入的距離最小的受試者時做出的。可以使用模型的 ROC 確定最小距離的閾值,因為每個圖像都被標識為數據庫中的主體之一。
ROC 曲線是通過繪制不同閾值下的真陽性 (TP) 率與假陽性 (FP) 率的對比來創建的。因此,當它在ROC曲線上移動時,閾值設置會發生變化,并且可以相對于所選性能確定閾值。
30個受試者的Maxim Celebrity數據集用于生成ROC曲線,其中數據庫中僅假設有15名女性(或男性)受試者。其余的被確定為未知受試者。正確分類的樣品可提高 TP 率,而其他樣品可提高 FP 率。圖 10 顯示了男性和女性數據集的 AI85FaceId 模型的 ROC 曲線。
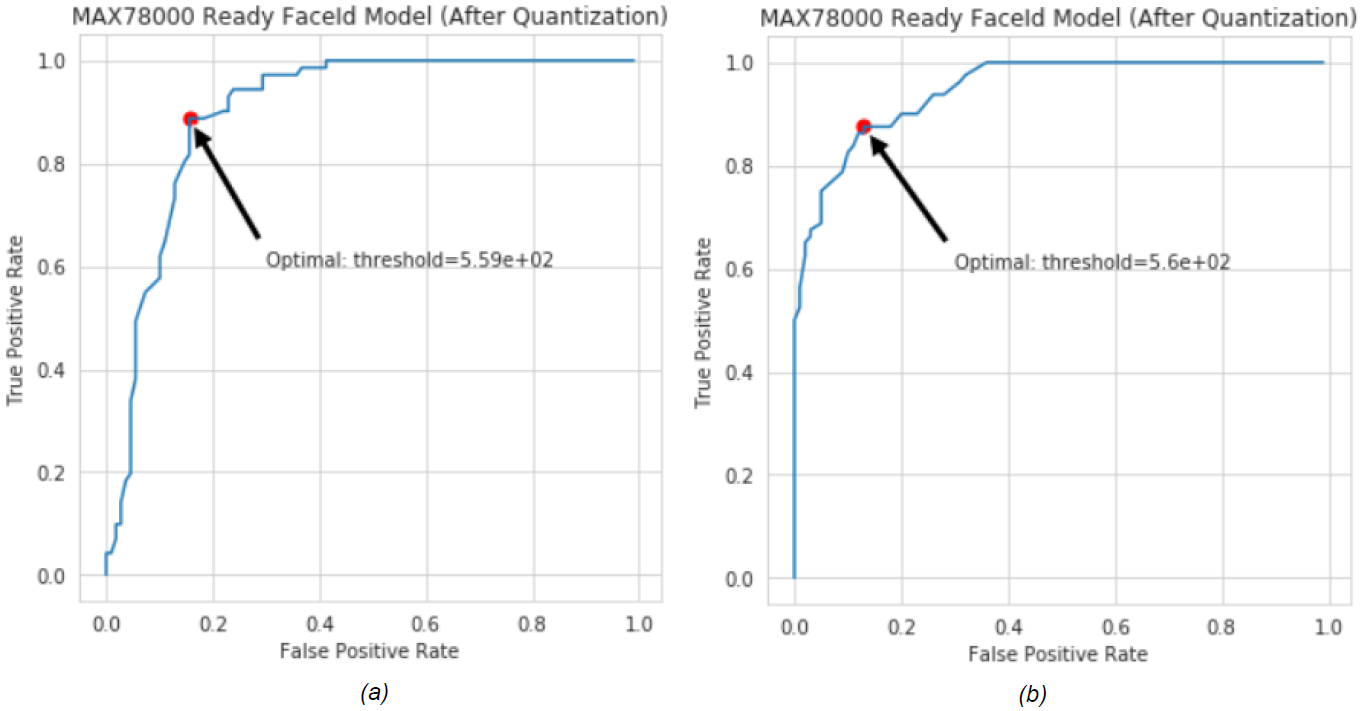
圖 10.AI85FaceIdNet的ROC曲線,用于(a)女性和(b)男性MaximCeleb數據集。
有不同的方法可以確定最佳閾值。ROC 曲線上最接近該點 (TP = 1.0, FP = 0.0) 的點被選為閾值(圖 10)。兩組的最佳值都非常接近 560。因此,FaceID 應用程序的未知主體閾值設置為 560。
CNN 模型合成
通過CNN模型訓練部分給出的步驟得到的量化模型是MAX78000使用Maxim工具中的python腳本合成的。此腳本生成一個 C 代碼,其中包括初始化 CNN 加速器、加載量化的 CNN 權重、為給定的示例輸入樣本運行模型以及在準備好以下三項后從設備獲取模型輸出的函數:
量化的 PyTorch 檢查點文件或 TensorFlow 模型導出為 ONNX 格式。
網絡模型 YAML 說明。
一個示例輸入,其中包含要包含在生成的 C 代碼中進行驗證的預期結果。
運行以下腳本以生成合成代碼:
./ai8xize.py -e --verbose --top-level cnn -L --test-dir --prefix faceid --checkpoint-file --config-file networks/faceid.yaml --device MAX78000 --fifo --compact-data --mexpress --display-checkpoint --unload
準系統C代碼用作構建FaceID演示應用程序的基礎,以初始化設備,加載權重(內核),推送示例輸入并獲取結果。
生成嵌入集
更改包含主題嵌入的頭文件 embeddings.h,以創建自定義數據集以運行 FaceID 演示。db_gen文件夾中的 Python 腳本 generate_face_db.py 用于此目的。腳本的示例用法在gen_db.sh中給出。該腳本將存儲主題圖像的文件夾名稱作為參數。此文件夾必須包括每個主題的單獨子文件夾,并且這些子文件夾必須以主題的名稱或標識符命名。圖 11 顯示了示例 db 文件夾結構。受試者的圖像放置在關聯的文件夾中。
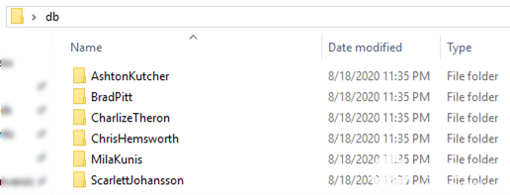
圖 11.用于生成自定義嵌入集的示例數據庫文件夾結構。
像gen_db.sh和generate_face_db.py一樣使用參數調用,會自動生成嵌入 embeddings.h,其中包含 db 文件夾中的圖像和主題。更改文件后,下一個構建將成為具有更新嵌入列表的自定義版本。
$ ./gen_db.sh
用MTCNN進行人臉識別,用檢測到的人臉裁剪120×160幀,并在generate_face_db.py中進行照明校正。圖像必須大于 120 × 160,并且只能包含一個面向相機的主體。建議每個受試者至少五張圖像,以提高識別準確性。
面容演示平臺
人臉識別在MAX78000評估板上使用FaceID固件進行演示。評估板(圖12.MAX78000上的FaceID應用截圖和圖11所示的主題數據庫)由TFT屏幕和視頻圖形陣列(VGA)攝像頭組成,均朝上以在自拍模式下工作。演示應用程序持續運行并報告每個幀的一個預測。如果提取的嵌入與數據庫中主題的接近程度不超過預定義的閾值,則會報告未知類。閾值是按照前面部分所述獲得的,可以更新(embedding_process.h 中的變量thresh_for_unknown_subject)。 可以使用 L1(曼哈頓)距離代替 L2 范數,因為它需要較少的計算。但必須相應地重復未知閾值確定步驟。

圖 12.MAX78000上的FaceID應用截圖,主題數據庫如圖11所示。
MAX78000評估板上的演示以縱向位置運行,更適合拍攝和顯示自拍照。人臉必須位于藍色矩形中,因為此部分是要裁剪以進行處理的區域的中心。從原始捕獲中裁剪出三個 120 × 160 圖像,具有不同的 X 和 Y 偏移。這些被饋送到CNN模型,以提高作為增強方法的準確性。在報告預測之前,通過向CNN發送多張覆蓋面部的圖像來測試預測的一致性。同樣,還測試了連續時間樣本中預測的一致性。這可能會給識別速度帶來一些滯后,但會增加應用程序的魯棒性。圖 13 顯示了應用程序的流程圖。
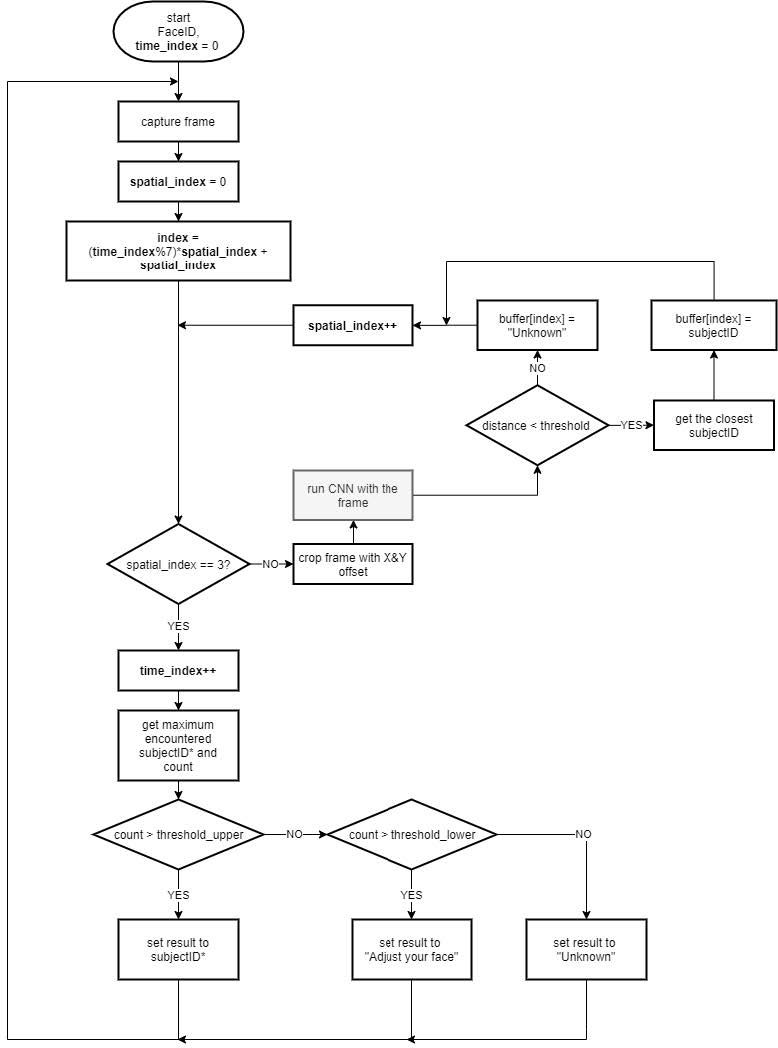
圖 13.MAX78000上FaceID演示應用的工藝流程
結論
本應用筆記演示了在MAX78000中實現人臉識別模型,以及如何在超低功耗MAX78000平臺上部署,用于資源受限的邊緣或物聯網應用。該應用遵循基于知識蒸餾的模型開發方法,以滿足MAX78000的要求。因此,本文檔也可以作為將高性能大型網絡遷移到邊緣設備的指南。應用筆記介紹了模型的性能分析以及合成模型以部署MAX78000所需的步驟。
審核編輯:郭婷
-
物聯網
+關注
關注
2913文章
44923瀏覽量
377014 -
人工智能
+關注
關注
1796文章
47666瀏覽量
240285 -
人臉識別
+關注
關注
76文章
4015瀏覽量
82313
發布評論請先 登錄
相關推薦
基于MAX78000FTHR的機器學習實時處理方案
請問各位大神,菜鳥要做雙目攝像頭來進行人臉識別該用什么dsp芯片??
Dragonboard 410c USB攝像頭進行人臉識別
MAX78000將能耗和延遲降低100倍,從而在IoT邊緣實現復雜的嵌入式決策
Maxim Integrated新型神經網絡加速器MAX78000 SoC在貿澤開售
美信半導體新型神經網絡加速器MAX78000 SoC
在MAX78000上開發功耗優化應用
用于MAX78000模型訓練的數據加載器設計
厲害了,這3個項目獲得了MAX78000設計大賽一等獎!
在MAX78000上開發功耗優化應用
MAX78000人工智能設計大賽第二季回歸!賽題廣任意玩,獎勵足直接沖!

MAX78000: Artificial Intelligence Microcontroller with Ultra-Low-Power Convolutional Neural Network Accelerator Data Sheet MAX78000: Artific






 工商網監
工商網監
評論