") 圖像預(yù)處理庫 CV-CUDA 開源了,打破預(yù)處理瓶頸,提升推理吞吐量 20 多倍
圖像預(yù)處理庫 CV-CUDA 開源了,打破預(yù)處理瓶頸,提升推理吞吐量 20 多倍
本文轉(zhuǎn)載自機器之心
當(dāng) CPU 圖像預(yù)處理成為視覺任務(wù)的瓶頸,最新開源的 CV-CUDA,將為圖像預(yù)處理算子提速百倍。
在如今信息化時代中,圖像或者說視覺內(nèi)容早已成為日常生活中承載信息最主要的載體,深度學(xué)習(xí)模型憑借著對視覺內(nèi)容強大的理解能力,能對其進(jìn)行各種處理與優(yōu)化。
然而在以往的視覺模型開發(fā)與應(yīng)用中,我們更關(guān)注模型本身的優(yōu)化,提升其速度與效果。相反,對于圖像的預(yù)處理與后處理階段,很少認(rèn)真思考如何去優(yōu)化它們。所以,當(dāng)模型計算效率越來越高,反觀圖像的預(yù)處理與后處理,沒想到它們竟成了整個圖像任務(wù)的瓶頸。
為了解決這樣的瓶頸,NVIDIA 攜手字節(jié)跳動機器學(xué)習(xí)團隊開源眾多圖像預(yù)處理算子庫 CV-CUDA,它們能高效地運行在 GPU 上,算子速度能達(dá)到 OpenCV(運行在 CPU)的百倍左右。如果我們使用 CV-CUDA 作為后端替換 OpenCV 和 TorchVision,整個推理的吞吐量能達(dá)到原來的二十多倍。此外,不僅是速度的提升,同時在效果上 CV-CUDA 在計算精度上已經(jīng)對齊了 OpenCV,因此訓(xùn)練推理能無縫銜接,大大降低工程師的工作量。
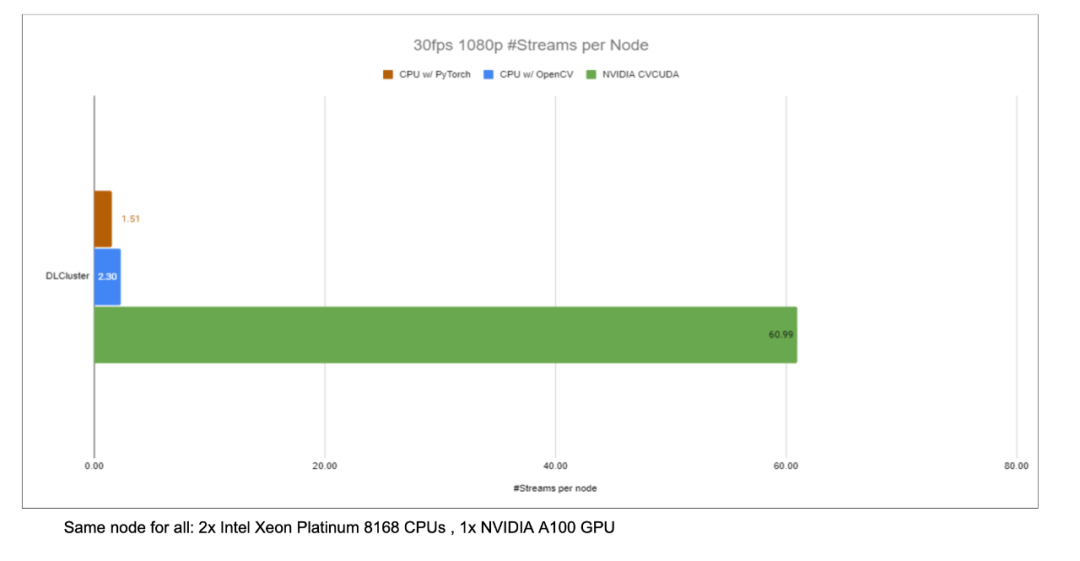
以圖像背景模糊算法為例,將 CV-CUDA 替換 OpenCV 作為圖像預(yù)/后處理的后端,整個推理過程吞吐量能加 20多倍。
如果小伙伴們想試試更快、更好用的視覺預(yù)處理庫,可以試試這一開源工具。
開源地址:https://github.com/CVCUDA/CV-CUDA
圖像預(yù)/后處理已成為CV瓶頸
很多涉及到工程與產(chǎn)品的算法工程師都知道,雖然我們常常只討論模型結(jié)構(gòu)和訓(xùn)練任務(wù)這類「前沿研究」,但實際要做成一個可靠的產(chǎn)品,中間會遇到很多工程問題,反而模型訓(xùn)練是最輕松的一環(huán)了。
圖像預(yù)處理就是這樣的工程難題,我們也許在實驗或者訓(xùn)練中只是簡單地調(diào)用一些 API 對圖像進(jìn)行幾何變換、濾波、色彩變換等等,很可能并不是特別在意。但是當(dāng)我們重新思考整個推理流程時會發(fā)現(xiàn),圖像預(yù)處理已經(jīng)成為了性能瓶頸,尤其是對于預(yù)處理過程復(fù)雜的視覺任務(wù)。
這樣的性能瓶頸,主要體現(xiàn)在 CPU 上。一般而言,對于常規(guī)的圖像處理流程,我們都會先在 CPU 上進(jìn)行預(yù)處理,再放到 GPU 運行模型,最后又會回到 CPU,并可能需要做一些后處理。
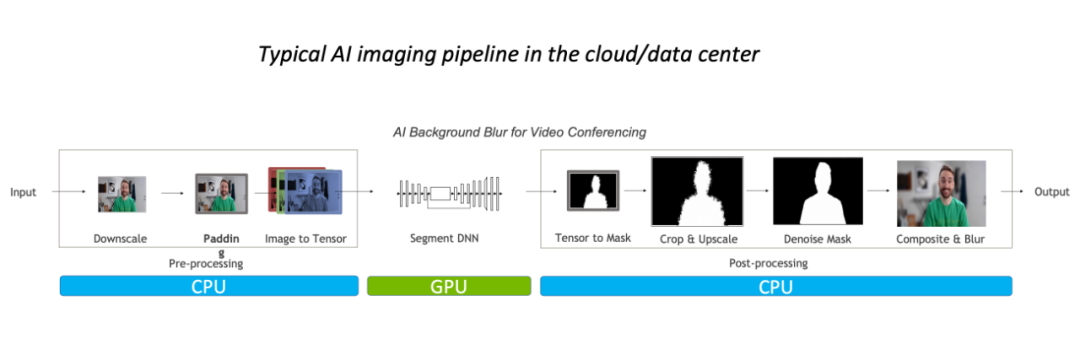
以圖像背景模糊算法為例,常規(guī)的圖像處理流程中預(yù)后處理主要在 CPU 完成,占據(jù)整體 90% 的工作負(fù)載,其已經(jīng)成為該任務(wù)的瓶頸。
因此對于視頻應(yīng)用,或者 3D 圖像建模等復(fù)雜場景,因為圖像幀的數(shù)量或者圖像信息足夠大,預(yù)處理過程足夠復(fù)雜,并且延遲要求足夠低,優(yōu)化預(yù)/后處理算子就已經(jīng)迫在眉睫了。一個更好地做法,當(dāng)然是替換掉 OpenCV,使用更快的解決方案。
為什么 OpenCV 仍不夠好?
在 CV 中,應(yīng)用最廣泛的圖像處理庫當(dāng)然就是長久維護(hù)的 OpenCV 了,它擁有非常廣泛的圖像處理操作,基本能滿足各種視覺任務(wù)的預(yù)/后處理所需。但是隨著圖像任務(wù)負(fù)載的加大,它的速度已經(jīng)有點慢慢跟不上了,因為 OpenCV 絕大多數(shù)圖像操作都是 CPU 實現(xiàn),缺少 GPU 實現(xiàn),或者 GPU 實現(xiàn)本來就存在一些問題。
在 NVIDIA 與字節(jié)跳動算法同學(xué)的研發(fā)經(jīng)驗中,他們發(fā)現(xiàn) OpenCV 中那些少數(shù)有 GPU 實現(xiàn)的算子存在三大問題:
-
部分算子的 CPU 和 GPU 結(jié)果精度無法對齊;
-
部分算子 GPU 性能比 CPU 性能還弱;
-
同時存在各種 CPU 算子與各種GPU算子,當(dāng)處理流程需要同時使用兩種,就額外增加了內(nèi)存與顯存中的空間申請與數(shù)據(jù)遷移/數(shù)據(jù)拷貝
比如說第一個問題結(jié)果精度無法對齊,NVIDIA 與字節(jié)跳動算法同學(xué)會發(fā)現(xiàn),當(dāng)我們在訓(xùn)練時 OpenCV 某個算子使用了 CPU,但是推理階段考慮到性能問題,換而使用 OpenCV 對應(yīng)的 GPU 算子,也許 CPU 和 GPU 結(jié)果精度無法對齊,導(dǎo)致整個推理過程出現(xiàn)精度上的異常。當(dāng)出現(xiàn)這樣的問題,要么換回 CPU 實現(xiàn),要么需要費很多精力才有可能重新對齊精度,是個不好處理的難題。
既然 OpenCV 仍不夠好,可能有讀者會問,那 Torchvision 呢?它其實會面臨和 OpenCV 一樣的問題,除此之外,工程師部署模型為了效率更可能使用 C++ 實現(xiàn)推理過程,因此將沒辦法使用 Torchvision 而需要轉(zhuǎn)向 OpenCV 這樣的 C++視覺庫,這不就帶來了另一個難題:對齊 Torchvision 與 OpenCV 的精度。
總的來說,目前視覺任務(wù)在 CPU 上的預(yù)/后處理已經(jīng)成為了瓶頸,然而當(dāng)前 OpenCV 之類的傳統(tǒng)工具也沒辦法很好地處理。因此,將操作遷移到 GPU 上,完全基于 CUDA 實現(xiàn)的高效圖像處理算子庫 CV-CUDA,就成為了新的解決方案。
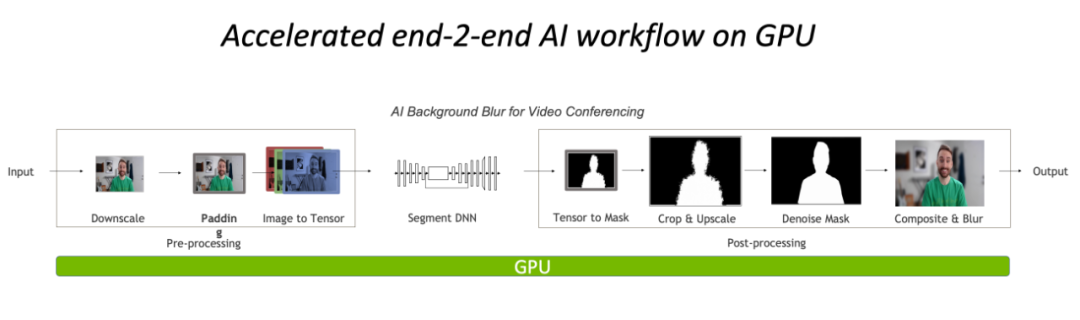
完全在 GPU 上進(jìn)行預(yù)處理與后處理,將大大降低圖像處理部分的 CPU 瓶頸。
GPU 圖像處理加速庫:CV-CUDA
作為基于 CUDA 的預(yù)/后處理算子庫,算法工程師可能最期待的是三點:足夠快、足夠通用、足夠易用。NVIDIA 和字節(jié)跳動的機器學(xué)習(xí)團隊聯(lián)合開發(fā)的 CV-CUDA 正好能滿足這三點,利用 GPU 并行計算能力提升算子速度,對齊 OpenCV 操作結(jié)果足夠通用,對接 C++/Python 接口足夠易用。
CV-CUDA 的速度
CV-CUDA 的快,首先體現(xiàn)在高效的算子實現(xiàn),畢竟是 NVIDIA 寫的,CUDA 并行計算代碼肯定經(jīng)過大量的優(yōu)化的。其次是它支持批量操作,這就能充分利用 GPU 設(shè)備的計算能力,相比 CPU 上一張張圖像串行執(zhí)行,批量操作肯定是要快很多的。最后,還得益于 CV-CUDA 適配的 Volta、Turing、Ampere 等 GPU 架構(gòu),在各 GPU 的 CUDA kernel 層面進(jìn)行了性能上的高度優(yōu)化,從而獲得最好的效果。也就是說,用的 GPU 卡越好,其加速能力越夸張。
正如前文的背景模糊吞吐量加速比圖,如果采用 CV-CUDA 替代 OpenCV 和 TorchVision 的前后處理后,整個推理流程的吞吐率提升 20多倍。其中預(yù)處理對圖像做 Resize、Padding、Image2Tensor 等操作,后處理對預(yù)測結(jié)果做的 Tensor2Mask、Crop、Resize、Denoise 等操作。
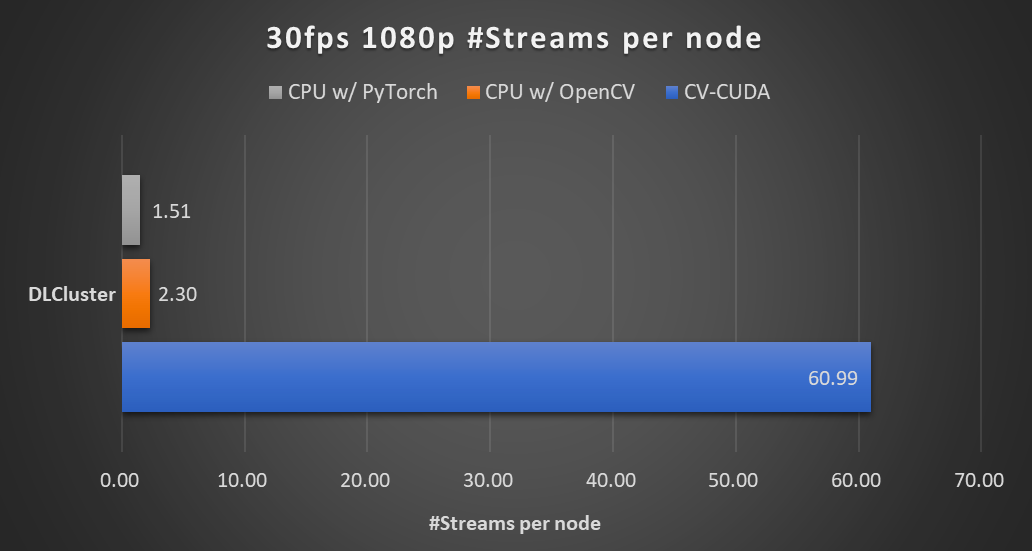
在同一個計算節(jié)點上(2x Intel Xeon Platinum 8168 CPUs,1x NVIDIA A100 GPU),以 30fps 的幀率處理 1080p 視頻,采用不同 CV 庫所能支持的最大的并行流數(shù)。測試采用了 4 個進(jìn)程,每個進(jìn)程 batchSize 為 64。
對于單個算子的性能,NVIDIA 和字節(jié)跳動的小伙伴也做了性能測試,很多算子在 GPU 上的吞吐量能達(dá)到 CPU 的百倍。
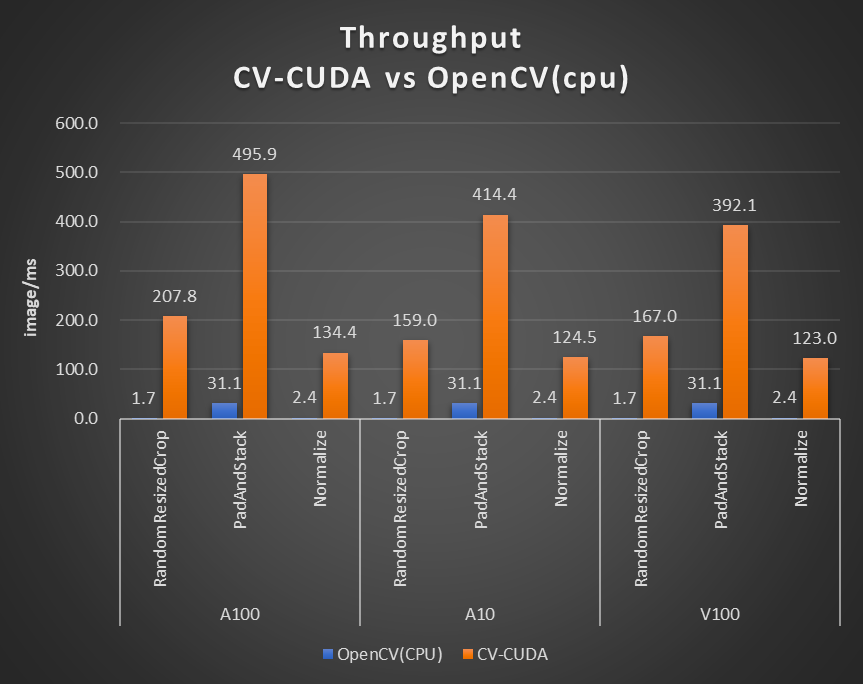
圖片大小為 480*360,CPU 選擇為 Intel(R) Core(TM) i9-7900X,BatchSize 大小為 1,進(jìn)程數(shù)為 1
盡管預(yù)/后處理算子很多都不是單純的矩陣乘法等運算,為了達(dá)到上述高效的性能,CV-CUDA 其實做了很多算子層面的優(yōu)化。例如采用大量的 kernel 融合策略,減少了 kernel launch 和 global memory 的訪問時間;優(yōu)化訪存以提升數(shù)據(jù)讀寫效率;所有算子均采用異步處理的方式,以減少同步等待的耗時等等。
CV-CUDA 的通用與靈活
運算結(jié)果的穩(wěn)定,對于實際的工程可太重要了,就比如常見的 Resize 操作,OpenCV、OpenCV-gpu 以及 Torchvision 的實現(xiàn)方式都不一樣,那從訓(xùn)練到部署,就會多很多工作量以對齊結(jié)果。
CV-CUDA 在設(shè)計之初,就考慮到當(dāng)前圖像處理庫中,很多工程師習(xí)慣使用 OpenCV 的 CPU 版本,因此在設(shè)計算子時,不管是函數(shù)參數(shù)還是圖像處理結(jié)果上,盡可能對齊 OpenCV CPU 版本的算子。因此從 OpenCV 遷移到 CV-CUDA,只需要少量改動就能獲得一致的運算結(jié)果,模型也就不必要重新訓(xùn)練。
此外,CV-CUDA 是從算子層面設(shè)計的,因此不論模型的預(yù)/后處理流程是什么樣的,其都能自由組合,具有很高的靈活性。
字節(jié)跳動機器學(xué)習(xí)團隊表示,在企業(yè)內(nèi)部訓(xùn)練的模型多,需要的預(yù)處理邏輯也多種多樣有許多定制的預(yù)處理邏輯需求。CV-CUDA 的靈活性能保證每個 OP 都支持 stream 對象和顯存對象(Buffer 和 Tensor 類,內(nèi)部存儲了顯存指針)的傳入,從而能更加靈活地配置相應(yīng)的 GPU 資源。每個 op 設(shè)計開發(fā)時,既兼顧了通用性,也能按需提供定制化接口,能夠覆蓋圖片類預(yù)處理的各種需求。
CV-CUDA 的易用
可能很多工程師會想著,CV-CUDA 涉及到底層 CUDA 算子,那用起來應(yīng)該比較費勁?但其實不然,即使不依賴更上層的 API,CV-CUDA 本身底層也會提供 Image 等結(jié)構(gòu)體,提供 Allocator 類,這樣在 C++ 上調(diào)起來也不麻煩。此外,往更上層,CV-CUDA 提供了 PyTorch、OpenCV 和 Pillow 的數(shù)據(jù)轉(zhuǎn)化接口,工程師能快速地以之前熟悉的方式進(jìn)行算子替換與調(diào)用。
此外,因為 CV-CUDA 同時擁有 C++ 接口與 Python 接口,它能同時用于訓(xùn)練與服務(wù)部署場景,在訓(xùn)練時用 Python 接口跟快速地驗證模型能力,在部署時利用 C++ 接口進(jìn)行更高效地預(yù)測。CV-CUDA 免于繁瑣的預(yù)處理結(jié)果對齊過程,提高了整體流程的效率。
CV-CUDA 進(jìn)行Resize的C++ 接口
實戰(zhàn),CV-CUDA 怎么用
如果我們在訓(xùn)練過程中使用 CV-CUDA 的 Python 接口,那其實使用起來就會很簡單,只需要簡單幾步就能將原本在 CPU 上的預(yù)處理操作都遷移到 GPU 上。
以圖片分類為例,基本上我們在預(yù)處理階段需要將圖片解碼為張量,并進(jìn)行裁切以符合模型輸入大小,裁切完后還要將像素值轉(zhuǎn)化為浮點數(shù)據(jù)類型并做歸一化,之后傳到深度學(xué)習(xí)模型就能進(jìn)行前向傳播了。下面我們將從一些簡單的代碼塊,體驗一下 CV-CUDA 是如何對圖片進(jìn)行預(yù)處理,如何與 Pytorch 進(jìn)行交互。

常規(guī)圖像識別的預(yù)處理流程,使用 CV-CUDA 將會把預(yù)處理過程與模型計算都統(tǒng)一放在 GPU 上運行。
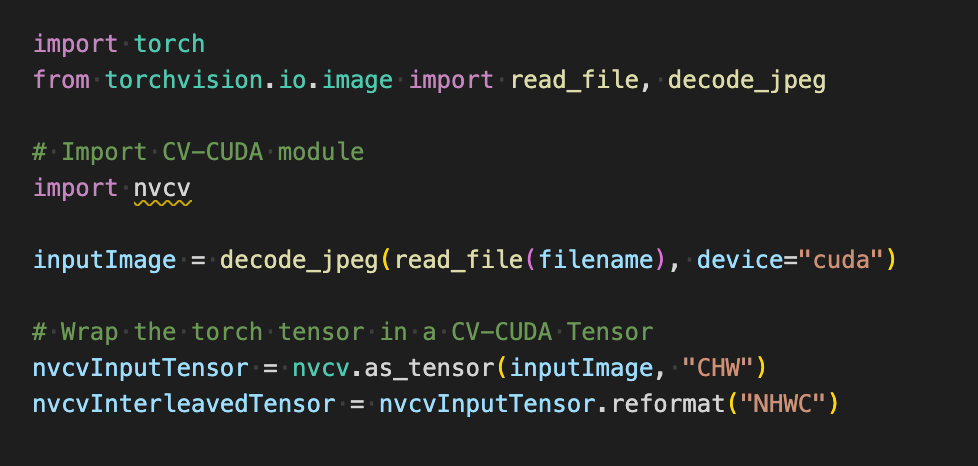
如下在使用 torchvision 的 API 加載圖片到 GPU 之后,Torch Tensor 類型能直接通過 as_tensor 轉(zhuǎn)化為 CV-CUDA 對象 nvcvInputTensor,這樣就能直接調(diào)用 CV-CUDA 預(yù)處理操作的 API,在 GPU 中完成對圖像的各種變換。
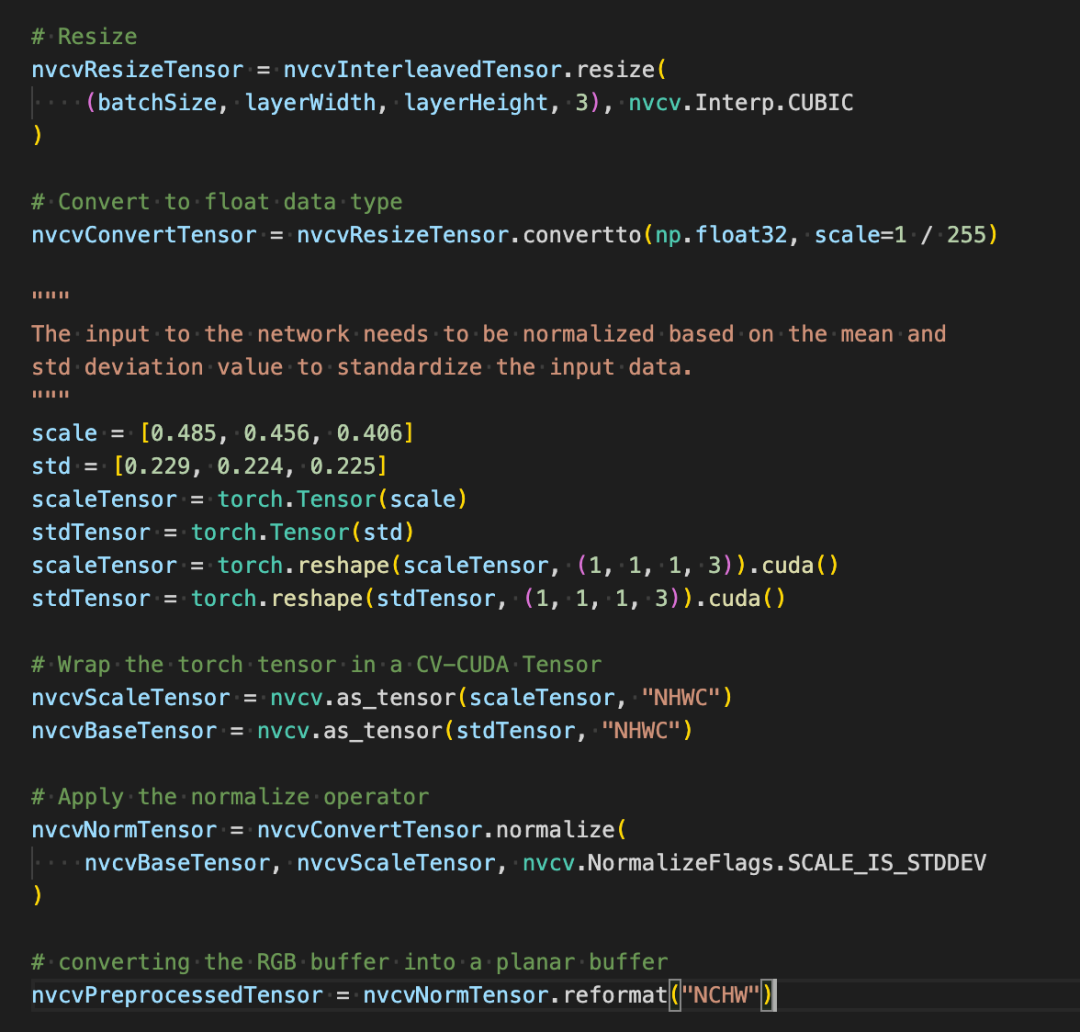
如下幾行代碼將借助 CV-CUDA 在 GPU 中完成圖像識別的預(yù)處理過程:裁剪圖像并對像素進(jìn)行歸一化。其中 resize()將圖像張量轉(zhuǎn)化為模型的輸入張量尺寸;convertto() 將像素值轉(zhuǎn)化為單精度浮點值;normalize() 將歸一化像素值,以令取值范圍更適合模型進(jìn)行訓(xùn)練。
CV-CUDA 各種預(yù)處理操作的使用與 OpenCV 或 Torchvision 中的不會有太大區(qū)別,只不過簡單調(diào)個方法,其背后就已經(jīng)在 GPU 上完成運算了。
現(xiàn)在借助借助 CV-CUDA 的各種 API,圖像分類任務(wù)的預(yù)處理已經(jīng)都做完了,其能高效地在 GPU 上完成并行計算,并很方便地融合到 PyTorch 這類主流深度學(xué)習(xí)框架的建模流程中。剩下的,只需要將 CV-CUDA 對象 nvcvPreprocessedTensor 轉(zhuǎn)化為 Torch Tensor 類型就能饋送到模型了,這一步同樣很簡單,轉(zhuǎn)換只需一行代碼:
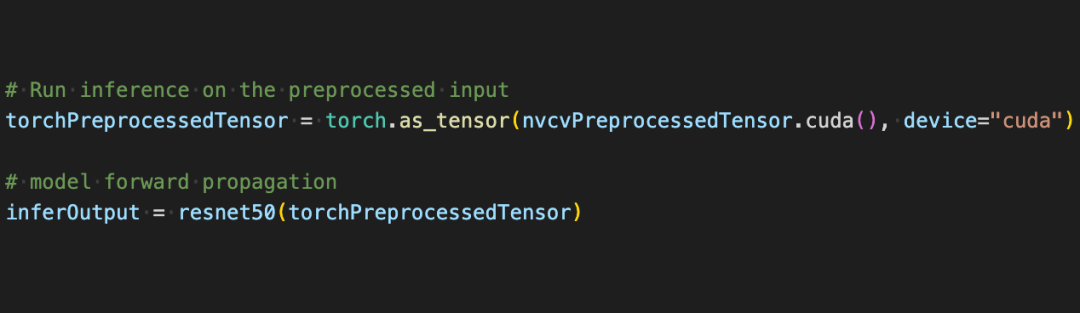
通過這個簡單的例子,很容易發(fā)現(xiàn) CV-CUDA 確實很容易就嵌入到正常的模型訓(xùn)練邏輯中。如果讀者希望了解更多的使用細(xì)節(jié),還是可以查閱前文 CV-CUDA 的開源地址。
CV-CUDA 對實際業(yè)務(wù)的提升
CV-CUDA 實際上已經(jīng)經(jīng)過了實際業(yè)務(wù)上的檢驗。在視覺任務(wù),尤其是圖像有比較復(fù)雜的預(yù)處理過程的任務(wù),利用 GPU 龐大的算力進(jìn)行預(yù)處理,能有效提神模型訓(xùn)練與推理的效率。CV-CUDA 目前在抖音集團內(nèi)部的多個線上線下場景得到了應(yīng)用,比如搜索多模態(tài),圖片分類等。
字節(jié)跳動機器學(xué)習(xí)團隊表示,CV-CUDA 在內(nèi)部的使用能顯著提升訓(xùn)練與推理的性能。例如在訓(xùn)練方面,字節(jié)跳動一個視頻相關(guān)的多模態(tài)任務(wù),其預(yù)處理部分既有多幀視頻的解碼,也有很多的數(shù)據(jù)增強,導(dǎo)致這部分邏輯很復(fù)雜。復(fù)雜的預(yù)處理邏輯導(dǎo)致 CPU 多核性能在訓(xùn)練時仍然跟不上,因此采用 CV-CUDA 將所有 CPU 上的預(yù)處理邏輯遷移到 GPU,整體訓(xùn)練速度上獲得了 90% 的加速。注意這可是整體訓(xùn)練速度上的提升,而不只是預(yù)處理部分的提速。
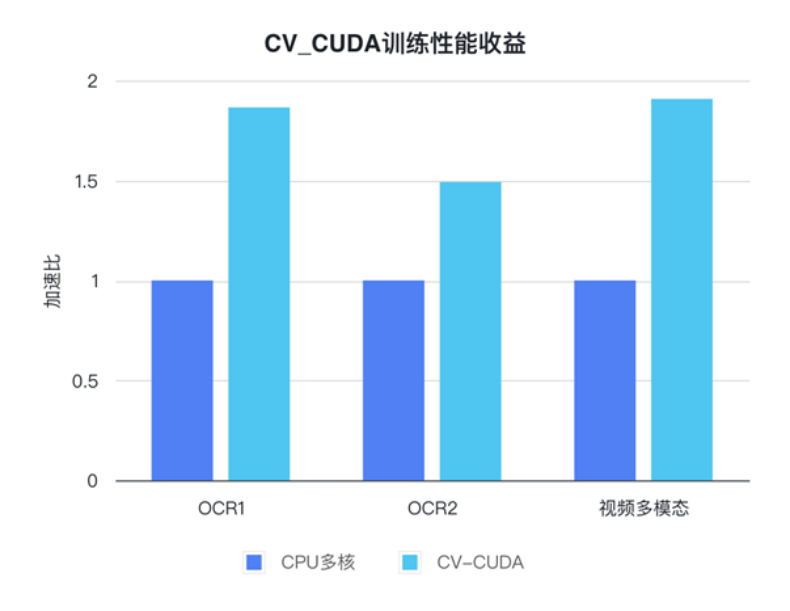
在字節(jié)跳動 OCR 與視頻多模態(tài)任務(wù)上,通過使用 CV-CUDA,整體訓(xùn)練速度能提升 1 到 2 倍(注意:是模型整體訓(xùn)練速度的提升)
在推理過程也一樣,字節(jié)跳動機器學(xué)習(xí)團隊表示,在一個搜索多模態(tài)任務(wù)中使用 CV-CUDA 后,整體的上線吞吐量相比于用 CPU 做預(yù)處理時有了 2 倍多的提升。值得注意的是,這里的 CPU 基線結(jié)果本來就經(jīng)過多核高度優(yōu)化,并且該任務(wù)涉及到的預(yù)處理邏輯較簡單,但使用 CV-CUDA 之后加速效果依然非常明顯。
速度上足夠高效以打破視覺任務(wù)中的預(yù)處理瓶頸,再加上使用也簡單靈活,CV-CUDA 已經(jīng)證明了在實際應(yīng)用場景中能很大程度地提升模型推理與訓(xùn)練效果,所以要是讀者們的視覺任務(wù)同樣受限于預(yù)處理效率,那就試試最新開源的 CV-CUDA 吧。
原文標(biāo)題:圖像預(yù)處理庫 CV-CUDA 開源了,打破預(yù)處理瓶頸,提升推理吞吐量 20 多倍
文章出處:【微信公眾號:NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3848瀏覽量
91979
原文標(biāo)題:圖像預(yù)處理庫 CV-CUDA 開源了,打破預(yù)處理瓶頸,提升推理吞吐量 20 多倍
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
數(shù)據(jù)吞吐量提升!面向下一代音頻設(shè)備,藍(lán)牙HDT、星閃、Wi-Fi、UWB同臺競技
cmp在數(shù)據(jù)處理中的應(yīng)用 如何優(yōu)化cmp性能
Minitab 數(shù)據(jù)清理與預(yù)處理技巧
TMS320VC5510 HPI吞吐量和優(yōu)化

16bit 6通道帶信號預(yù)處理的高速模數(shù)轉(zhuǎn)換器——AiP8348
求助,關(guān)于使用iperf測量mesh節(jié)點吞吐量問題求解
機器學(xué)習(xí)中的數(shù)據(jù)預(yù)處理與特征工程
信號的預(yù)處理包括哪些環(huán)節(jié)
【RTC程序設(shè)計:實時音視頻權(quán)威指南】音頻采集與預(yù)處理
利用NVIDIA組件提升GPU推理的吞吐
C預(yù)處理器及其工作原理
C語言中的預(yù)處理器





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論