 NVIDIA Triton 系列文章(9):為服務器添加模型
NVIDIA Triton 系列文章(9):為服務器添加模型
前面已經用https://github.com/triton-inference-server/server/doc/examples 開源倉的范例資源,創建一個最基礎的模型倉以便執行一些基礎的用戶端范例,現在就要帶著讀者為模型倉添加新的模型。
在“創建模型倉”的文章里講解過,Triton 模型倉使用目錄結構與相關文件來形成一個模型的基礎要素,如下所列:
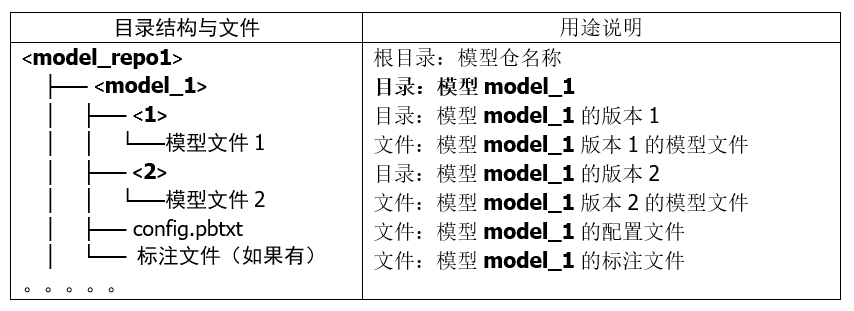
上面的目錄結構與模型文件是最基本的材料,處理起來是很容易的,比較復雜的部分是配置文件 config.pbtxt 的內容,里面提供 Triton 服務器用來管理模型執行特性的各項參數,這些設置的內容主要分為靜態的基礎(minimal)設置項與動態的優化(optimization)設置兩大部分,本文內容先針對基礎配置項的部分進行說明。
為了說明這些配置內容,這里先以范例模型倉里的 inception_graphdef 模型的配置文件 config.pbtxt 為例,來配合以下的簡單說明,比較容易讓大家理解詳細的內容:

每個配置文件里都至少包含以下5個部分:
1. 模型名稱:
這部分直接使用存放模型的文件夾名稱,因此可以省略,如果要指定的話就必須與文件夾名稱一致。
2. 平臺/后端名稱(Name, Platform and Backend):
這部分必須與模型訓練時使用的框架與文件格式相匹配,以下是使用頻率較高的種類:
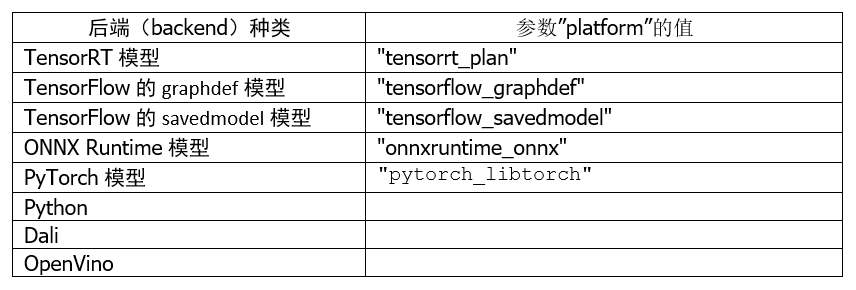
至于其他平臺/后端的對應名稱,就需要根據實際的平臺與對應名稱進行配置。
3. 模型執行策略(Model Transaction Policy):
這個屬性只有一個“解耦(decoupled)與否”的選項。使用解耦意味著模型生成的響應的數量可能與發出的請求的數量不同,并且響應可能與請求的順序無關。
默認值為 false,上面范例中并未列出這個參數的配置值,表示“不啟用解耦”功能,意味著該模型將為每個請求生成一個響應。
如果需要啟用解耦功能,就在配置文件內添加以下內容:
model_transaction_policy {
decoupled: True
}
4. 最大批量值(Maximum Batch Size):
Triton 服務器支持多種調度和批處理算法,可以為每個模型獨立選擇。這個屬性表示執行該推理模型計算時的最大批量規模,包括“無狀態(stateless)”或“有狀態(stateful)”等類型的模型。
這個參數主要配合下面“輸入/輸出節點內容”的張量尺度部分,例如本范例中輸入節點張量格式為“format: FORMAT_NHWC”,但是下面尺度“dims: [ 299, 299, 3 ]”的三個數值是對應到“HWC(高/寬/通道)”,缺少“批量值(N)”的部分,這正是這個“最大批量值”為輸入節點與輸出節點所配置的數值,這樣 Triton 可以使用動態批處理器或序列批處理器自動對模型進行批處理。
在這種情況下,max_batch_size 應設置為大于或等于1的值,表示應與該模型一起使用的最大批次大小;對于不支持批處理或不支持以上述特定方式進行批處理的推理模型,則將 max_batch_size 設置為 0。
5. 輸入節點與輸出節點(Inputs and Outputs):
每個推理模型都有至少一個輸入節點與輸出節點,這部分的內容必須配合模型的內容,不能自己隨便定義。
要添加新的推理模型時,推薦使用 Netron 工具查看模型的網絡結構,只要在瀏覽器上輸入“netron.app”后打開模型文件就可以。目前經過測試,Netron.APP 工具能查看 ONNX、TensorFlow/graphdef、Pytorch 等模型文件的網絡結構,相當方便。
下圖是 model_repository/inception_graphdef/1/model.graphdef 模型文件所能看到的輸入/輸出節點的內容:
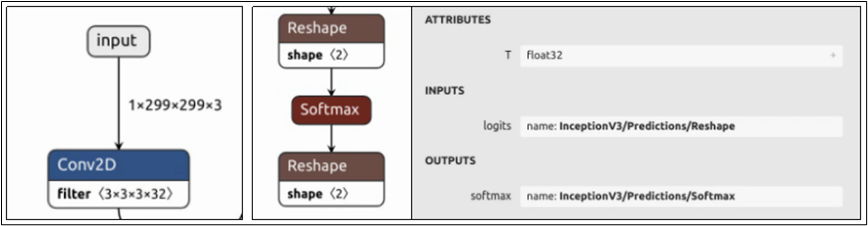
每個節點都包含“名稱”、“數據類型”與“尺度(shape)”三個部分,現在就進一步說明:
(1) 節點名稱(name):
上圖最左邊的輸入節點在整個網絡結構的最上方,名稱為“input”;中間輸出節點在網絡結構最下方,點選“softmax”節點會出現右邊灰色信息塊,顯示其完整名稱為“InceptionV3/Predictions/Softmax”。現在對照模型的 config.pbtxt 里對應內容,是必須能匹配的,否則啟動 Triton 服務器時會出現錯誤。
不過這個環節里對 PyTorch 模型需要特殊的處理,由于 TorchScript 模型文件中輸入/輸出的元數據不足,配置中輸入/輸出的“名稱屬性”必須遵循以下特定的命名約定:
-
使用張量字典(Dictionary of Tensor):
-
映射到 forward() 函數的輸入值:
-
使用_格式:
-
如果所有輸入(或輸出)不遵循相同的命名約定,那么我們從模型配置中強制執行嚴格排序,即我們假設配置中輸入(或輸出)的順序是這些輸入的真實順序。
(2) 數據類型(data_type):
輸入和輸出張量所允許的數據類型因模型類型而異,數據類型部分描述了允許的數據類型以及它們如何映射到每個模型類型的數據類型。
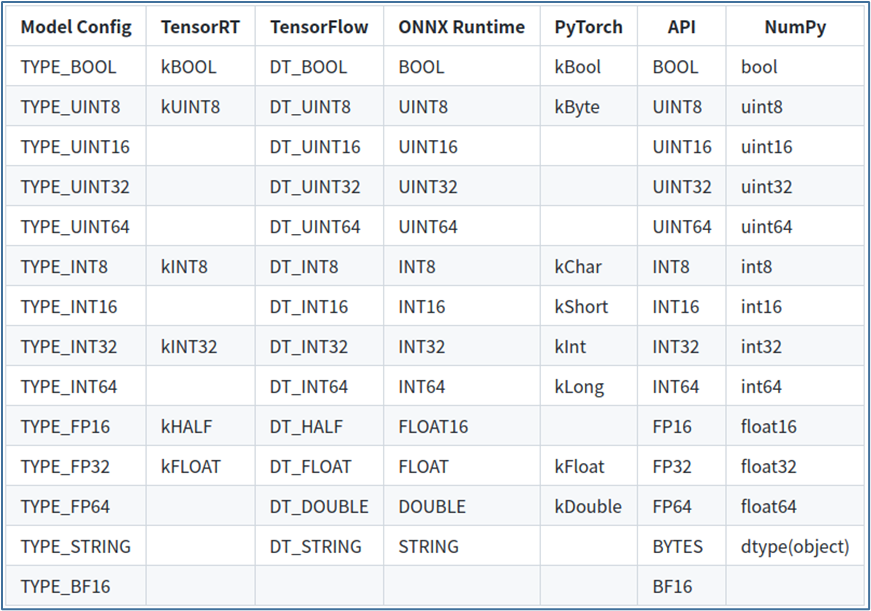
下表顯示了 Triton 支持的張量數據類型:
-
第 1 列顯示模型配置文件中顯示的數據類型的名稱;
-
第 2~5 列顯示了支持的模型框架的相應數據類型,如果模型框架沒有給定數據類型的條目,則 Triton 不支持該模型的數據類型;
-
第 6 列為“API”,顯示 TRITONSERVER C API、TRITONBACKEND C API、HTTP/REST 協議和 GRPC 協議的對應數據類型;
-
第 7 列顯示 Python numpy 庫的對應數據類型。
以上是關于模型數據類型的部分。
(3)張量尺度(dims):
這里提供的張量尺度內容是去除第一個 batch_size 的部分,因此需要與前面設定的 max_batch_size 組合形成完整的張量尺度。
輸入節點的張量尺度(如“dims: [ 299, 299, 3 ]”),表示模型和 Triton 在推理請求中預期的張量尺寸;輸出節點的張量尺度(如“dims: [ 1001 ]”),表示模型生成的輸出張量的形狀,并由 Triton 服務器響應推斷請求返回。
輸入和輸出尺度內的值都必須大于或等于 1,也就是不允許使用[]空尺度,節點的尺度由 max_batch_size 和輸入或輸出 dims 屬性指定的維度的組合指定。
-
max_batch_size > 0時:整個尺度的形式為[-1, dims]。
-
max_batch_size = 0時:整個形狀形成為[ dims]。
例如本文范例中輸入節點的尺度為“dims: [ 299, 299, 3 ]”、max_batch_size=128,則張量尺度的完整表達為“[ -1, 299, 299, 3]”;如果 max_batch_size=0 時,則張量尺度的完整表達為“[ 299, 299, 3]”。
6. 版本策略(version_policy):
每個模型可以有一個或多個版本,模型配置的 ModelVersionPolicy 屬性用于設置以下策略之一。
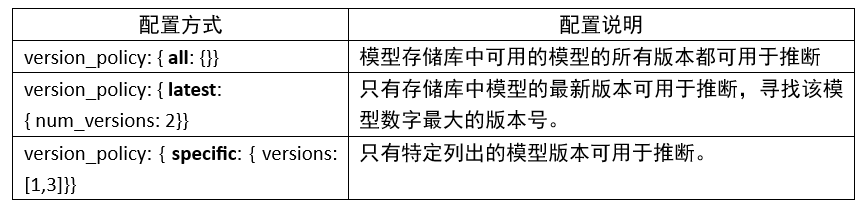
如果未指定版本策略,則使用最新版本(n=1)作為默認值,表示 Triton 僅提供最新版本的模型。在所有情況下,從模型存儲庫中添加或刪除版本子目錄都可以更改后續推理請求中使用的模型版本。
以上是完成一個 config.pbtxt 模型配置文件的最基礎內容,大部分內容都比較直觀,除了最后面的張量尺度會有比較多的變化之外,不過只要逐漸熟悉推理運作的過程之后,就能更進一步掌握與 batch_size 相關的應用與調試方式。
原文標題:NVIDIA Triton 系列文章(9):為服務器添加模型
文章出處:【微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3848瀏覽量
91995
原文標題:NVIDIA Triton 系列文章(9):為服務器添加模型
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NVIDIA推出開放式Llama Nemotron系列模型
Triton編譯器的優化技巧
Triton編譯器的優勢與劣勢分析
Triton編譯器功能介紹 Triton編譯器使用教程
NVIDIA AI服務器領域重大革新:預計明年首推插槽式設計
NVIDIA助力提供多樣、靈活的模型選擇
NVIDIA攜手Meta推出AI服務,為企業提供生成式AI服務
英偉達推出全新NVIDIA AI Foundry服務和NVIDIA NIM推理微服務
NVIDIA AI Foundry 為全球企業打造自定義 Llama 3.1 生成式 AI 模型







 工商網監
工商網監
評論