 Python-爬蟲開發02
Python-爬蟲開發02
谷歌瀏覽器分析post地址
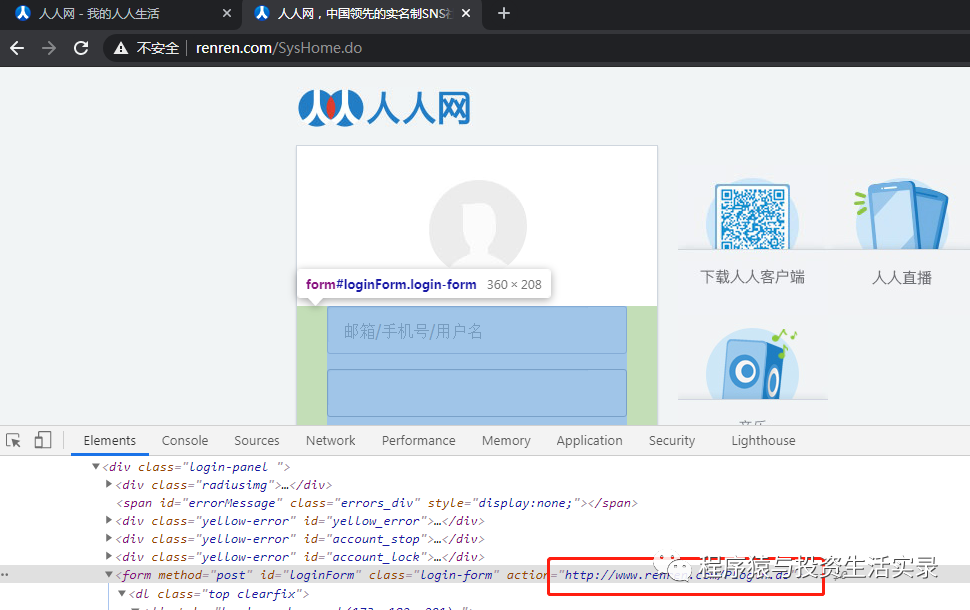
- 方式二: 直接點擊登錄按鈕,查看訪問的地址(需要注意下面請求時傳遞的參數,如果部分參數不知道如何得到,可能需要跟蹤js文件查看)
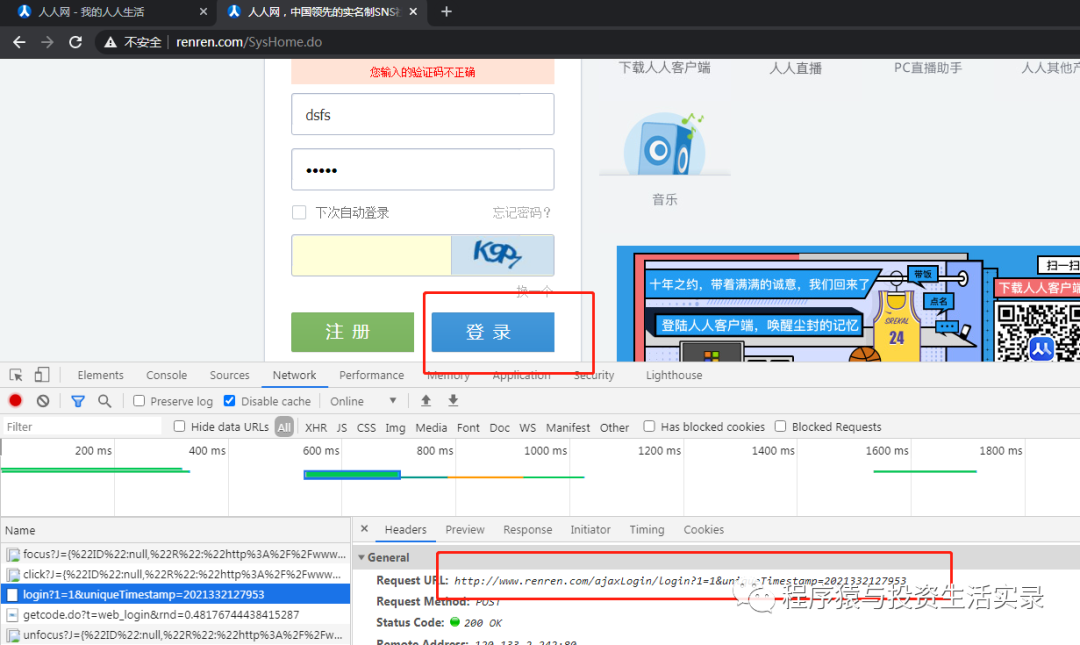
- 方式三: 部分網站的PC端請求時需要的參數較多,但是移動端會少些,所以可以切換到移動端看看請求地址與參數
requests小技巧
- requests.util.dict_from_cookiejar 把cookie對象轉化為字典
- 請求SSL證書驗證
- r=requests.get(url,verify=False)
- 設置超時
- r=requests.get(url,timeout=時間(單位是秒))
- 使用斷言判斷狀態碼是否成功
- assert respnose.status_code==200
爬蟲數據處理
數據分類
- 非結構化數據:html 等
- 處理方法:使用 正則表達式、xpath 處理數據
- 結構化數據:json、xml等
- 處理方法:轉化為python中的數據類型
數據處理之JSON
- JSON(JavaScript Object Notation) ,是一種輕量級的數據交換格式,它使得人們很容易進行閱讀和編寫。同時也方便了機器進行解析和生成。適用于進行數據交互的場景,比如網站的前后臺之間的數據交互。
- 爬取豆瓣電視劇列表示例
import json
import requests
class DouBanMovie:
def __init__(self):
self.url="https://m.douban.com/rexxar/api/v2/subject_collection/tv_domestic/items?os=android&for_mobile=1&start=0&count=18&loc_id=108288"
self.headers={
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Mobile Safari/537.36",
"Referer": "https://m.douban.com/tv/chinese"
}
def get_data(self):
response = requests.get(self.url, headers=self.headers)
if response.status_code==200:
# 將json字符串轉化為python中的數據類型
result=json.loads(response.content.decode())
return result
def write_file(self,fileName,data):
'''寫入文件'''
# json.dumps能夠把python中的類型數據轉化成json字符串
data=json.dumps(data,ensure_ascii=False)
with open(fileName,"w",encoding="utf-8") as f:
f.write(data)
def read_file(self,fileName):
'''讀取文件數據'''
with open(fileName, "r", encoding="utf-8") as f:
# 加載json類型數據的文件
result=json.load(f)
return result
def run(self):
# 獲取數據
result=self.get_data()
# 將豆瓣數據寫入文件
self.write_file("douban.txt",result)
# 讀取文件內容
readResult=self.read_file("douban.txt")
print(readResult)
if __name__ == '__main__':
douban=DouBanMovie()
douban.run()
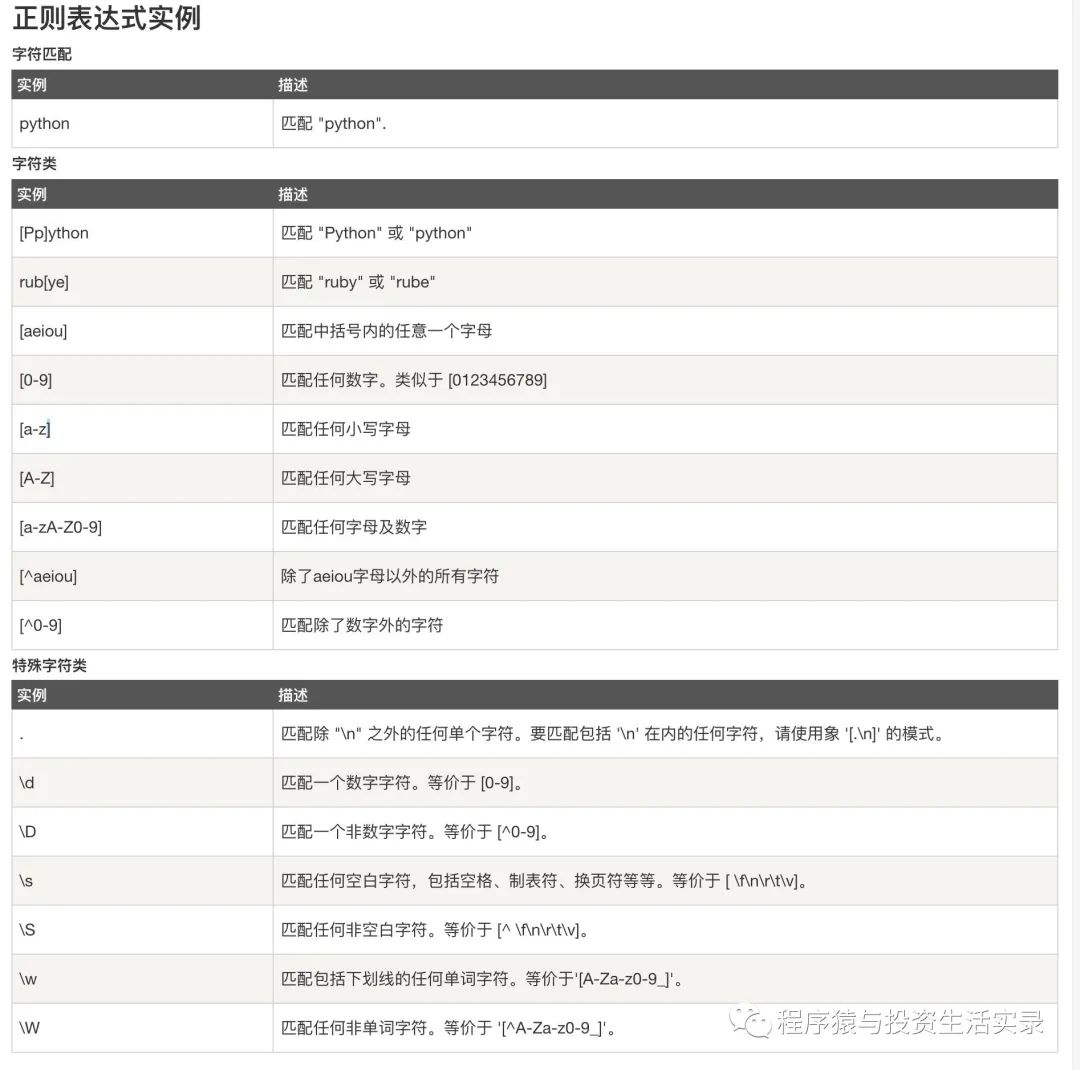
數據處理之正則表達式
- 正則表達式定義
- 就是用事先定義好的一些特定字符、及這些特定字符的組合,組成一個” 規則字符串 “,這個”規則字符串“用來表達對字符串的一種過濾邏輯
- 常用正則表達式的方法
- re.compile(編譯)
- pattern.match(從頭開始匹配一個)
- pattern.search(從任何位置開始匹配一個)
- pattern.findall(匹配所有)
- pattern.sub(替換)
- Python正則表達式中的re.S,re.M,re.I的作用
- 正則表達式可以包含一些可選標志修飾符來控制匹配的模式。修飾符被指定為一個可選的標志。多個標志可以通過按位 OR(|) 它們來指定。如 re.I | re.M 被設置成 I 和 M 標志


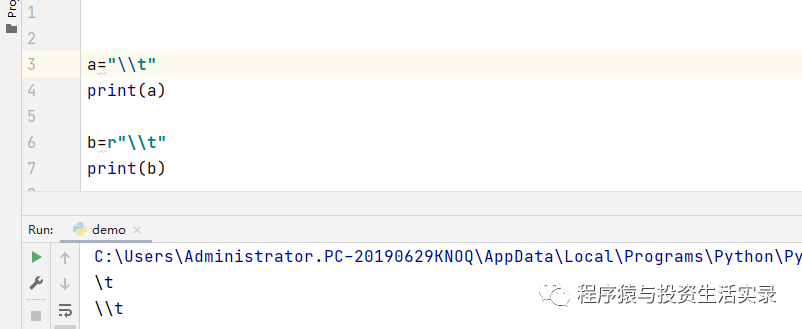
- python中 r 的用法
- 'r'是防止字符轉義的 如果路徑中出現'\\t'的話 不加r的話\\t就會被轉義 而加了'r'之后'\\t'就能保留原有的樣子
- 示例(提取成語故事)
import requests
import re
class ChengYu:
def __init__(self):
self.url="http://www.hydcd.com/cy/gushi/0259hs.htm"
self.headers={
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Mobile Safari/537.36"
}
def get_data(self):
response=requests.get(self.url,self.headers)
result=None
if response.status_code==200:
result=response.content.decode("gb2312")
return result
def handle_data(self,html_str_list):
if html_str_list==None or len(html_str_list)==0:
return None
html_str=html_str_list[0]
result=re.sub(r"\\r|\\t|
","",html_str)
return result
def run(self):
# 訪問網頁信息
html_str=self.get_data()
# 用正則表達式提取 成語故事
html_str_list=re.findall(r"(.*?)",html_str,re.S)
# 處理語句中的換行、制表等標識體符
result=self.handle_data(html_str_list)
print(result)
if __name__ == '__main__':
chengYu=ChengYu()
chengYu.run()
數據處理之xpath
- lxml 是一款高性能的python html/xml 解析器,我們可以利用xpath,來快速定位特定元素以及獲取節點信息
- xpath(xml path langueage)是一門在 html/xml 文檔中查找信息的語言,可以用來在html/xml 文檔中對元素和屬性進行遍歷
- 官網地址:https://www.w3school.com.cn/xpath/index.asp
- xpath 節點選擇語法
- xpath 使用路徑表達式來選取xml,文檔中的節點或者節點集,這些路徑表達式和我們在常規的電腦文件系統中看到的表達式非常相似
| 表達式 | 描述 |
|---|---|
| node name | 選取此節點的所有子節點 |
| / | 從根節點選取 |
| // | 從匹配選擇的當前節點選擇文檔中的節點,而不考慮它們的位置 |
| . | 選取當前節點 |
| .. | 選取當前節點的父節點 |
| @ | 選取屬性 |
- 常用節點的選擇工具
- Chrome插件 XPath Helper
- 開源的 XPath表達式編輯工具:XML Quire(xml 格式文件可用)
- Firefox插件 XPath Checker
- lxml庫
- 安裝lxml:pip install lxml
- 使用方法:** from lxml import etree**
- 利用 etree.HTML ,將字符串轉化為 Element對象
- Element對象具有xpath的方法:html=etree.HTML(字符串)
- 示例
import requests
import re
from lxml import etree
class ChengYu:
def __init__(self):
self.url="http://www.hydcd.com/cy/gushi/0259hs.htm"
self.headers={
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Mobile Safari/537.36"
}
def get_data(self):
response=requests.get(self.url,self.headers)
result=None
if response.status_code==200:
result=response.content.decode("gb2312")
return result
def handle_data(self,html_str_list):
if html_str_list==None or len(html_str_list)==0:
return None
html_str=html_str_list[0]+html_str_list[1]
result=re.sub(r"\\r|\\t|
","",html_str)
return result
def run(self):
# 訪問網頁信息
html_str=self.get_data()
# 用xpath提取元素
html=etree.HTML(html_str)
result=html.xpath("http://font[@color=\"#10102C\"]/text()")
# 處理語句中的換行、制表等標識體符
result=self.handle_data(result)
print(result)
if __name__ == '__main__':
chengYu=ChengYu()
chengYu.run()
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
網站
+關注
關注
2文章
259瀏覽量
23241 -
數據交換
+關注
關注
0文章
104瀏覽量
17968 -
JSON
+關注
關注
0文章
119瀏覽量
7011
發布評論請先 登錄
相關推薦
Python數據爬蟲學習內容
,利用爬蟲,我們可以解決部分數據問題,那么,如何學習Python數據爬蟲能?1.學習Python基礎知識并實現基本的爬蟲過程一般獲取數據的過
發表于 05-09 17:25
Python爬蟲與Web開發庫盤點
Python爬蟲和Web開發均是與網頁相關的知識技能,無論是自己搭建的網站還是爬蟲爬去別人的網站,都離不開相應的Python庫,以下是常用的
發表于 05-10 15:21
0基礎入門Python爬蟲實戰課
學習資料良莠不齊爬蟲是一門實踐性的技能,沒有實戰的課程都是騙人的!所以這節Python爬蟲實戰課,將幫到你!課程從0基礎入門開始,受眾人群廣泛:如畢業大學生、轉行人群、對Python
發表于 07-25 09:28
Python爬蟲簡介與軟件配置
Python爬蟲練習一、爬蟲簡介1. 介紹2. 軟件配置二、爬取南陽理工OJ題目三、爬取學校信息通知四、總結五、參考一、爬蟲簡介1. 介紹網絡爬蟲
發表于 01-11 06:32


python爬蟲入門教程之python爬蟲視頻教程分布式爬蟲打造搜索引擎
本文檔的主要內容詳細介紹的是python爬蟲入門教程之python爬蟲視頻教程分布式爬蟲打造搜索引擎
發表于 08-28 15:32
?29次下載
python為什么叫爬蟲 python工資高還是java的高
人工智能的現世,讓python學習成風,由于其發展前景好,薪資高,一時成為眾多語言的首選。Python是一門非常適合開發網絡爬蟲的編程語言,十分的簡潔方便所以是網絡
發表于 02-19 17:56
?565次閱讀
python爬蟲框架有哪些
本視頻主要詳細介紹了python爬蟲框架有哪些,分別是Django、CherryPy、Web2py、TurboGears、Pylons、Grab、BeautifulSoup、Cola。
Python-爬蟲開發01
網絡爬蟲(被稱為 網頁蜘蛛,網絡機器人 ),就是 模擬客戶端發送網絡請求 ,接收請求響應,一種按照一定的規則,自動地抓取互聯網信息的程序

如何解決Python爬蟲中文亂碼問題?Python爬蟲中文亂碼的解決方法
如何解決Python爬蟲中文亂碼問題?Python爬蟲中文亂碼的解決方法 在Python爬蟲過程





 工商網監
工商網監
評論