 超異構計算時代的操作系統架構綜述
超異構計算時代的操作系統架構綜述
經常有軟件的同學會問到一個尖銳的問題:在超異構軟硬件融合的時代,操作系統等軟件是不是需要重構,是不是要打破現有的整個軟件體系。我趕緊解釋:“超異構軟硬件融合不改變現有的軟件體系,所有的軟件該是什么樣還是什么樣。”
當然了,上層不改變,不意味著底層不調整。雖然可以“躺平”,在超異構計算平臺直接復制現有的軟件架構;但要想發揮超異構計算平臺的強大性能,底層軟件做一些調整也是必然的(當然,這些調整最好是潤物細無聲的漸進式迭代)。
底層軟件最核心的是操作系統。因此,引出了我們今天要討論的話題:在超異構計算時代,操作系統架構會有哪些改變?
本文來自個人的一些思考以及和周圍朋友們的一些探討,我不是操作系統專業出身,班門弄斧,拋磚引玉,希望得到各位專業人士的指正。
01經典操作系統綜述
1.1 操作系統的作用
操作系統是管理計算機硬件、軟件資源,并為應用程序提供公共服務的系統軟件,是計算機系統的內核與基石。操作系統需要:管理與配置內存、決定系統資源供需的優先次序、控制I/O設備、操作網絡,以及管理文件系統等基本事務,也需要提供一個讓用戶與系統交互的操作界面。
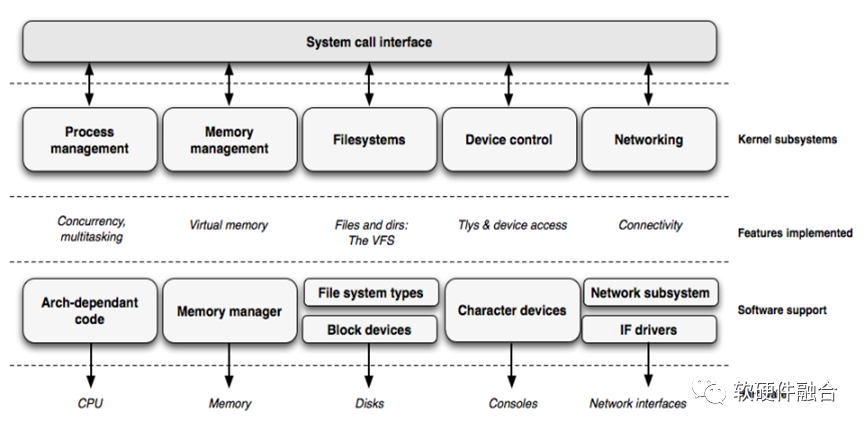
一個標準的操作系統通常提供以下功能:進程管理(Processing management)、內存管理(Memory management)、文件系統(File system)、網絡通信(Networking)、安全機制(Security)、用戶界面(User interface)和驅動程序(Device drivers)等。
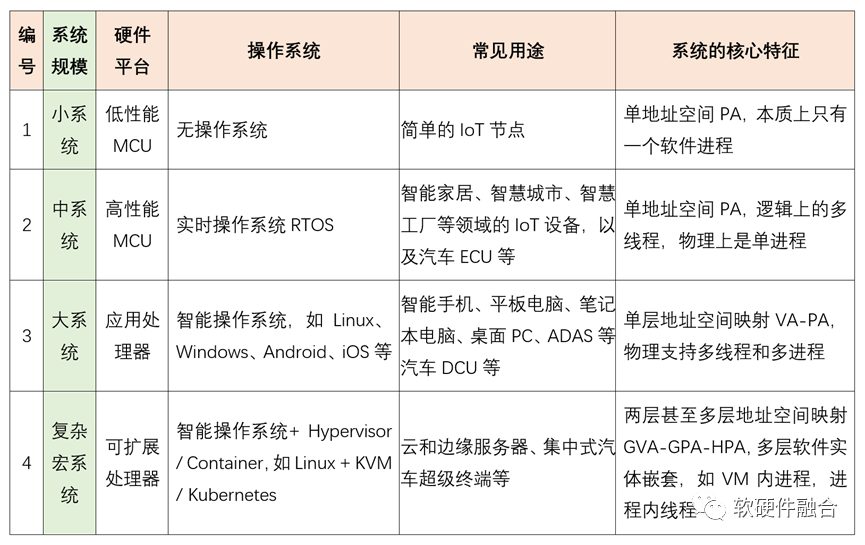
1.2 按照系統規模的操作系統分類
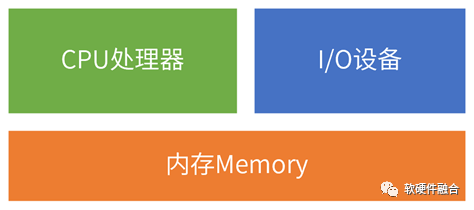
1.3 經典計算機的功能模塊
經典的馮諾依曼架構告訴我們,計算機是由五部分組成的:控制器、運算器、存儲器、輸入設備和輸出設備。我們可以把這個模型的組成部分再簡化一下,計算機是由三大部分組成的:
處理器:控制器和運算器組成處理器,用于數據的計算;
I/O設備:也就是輸入設備和輸出設備的整合,單個設備完成數據的輸入和輸出;
內存:數據存儲的地方,用于輸入數據的緩沖、中間結果的暫存以及輸出數據的緩沖。
所有的軟件都是在CPU處理器上運行的。
軟件在CPU的運行,主要有兩種作用,一種是硬件的管理(控制面),一種是硬件的使用(計算/數據面):
操作系統軟件主要是負責硬件的管理,包括CPU運行軟件的調度、I/O設備的驅動以及內存管理等。
而在硬件上(絕大部分時間)運行的是用戶的應用軟件,主要以進程和線程的方式運行。這里包括從I/O設備和內存的數據交互(也是驅動程序功能的一部分),CPU從內存的數據讀寫(包含在具體的應用程序里),以及CPU上運行的進行數據計算/處理的用戶程序進程/線程本身。
1.4 經典操作系統的任務調度
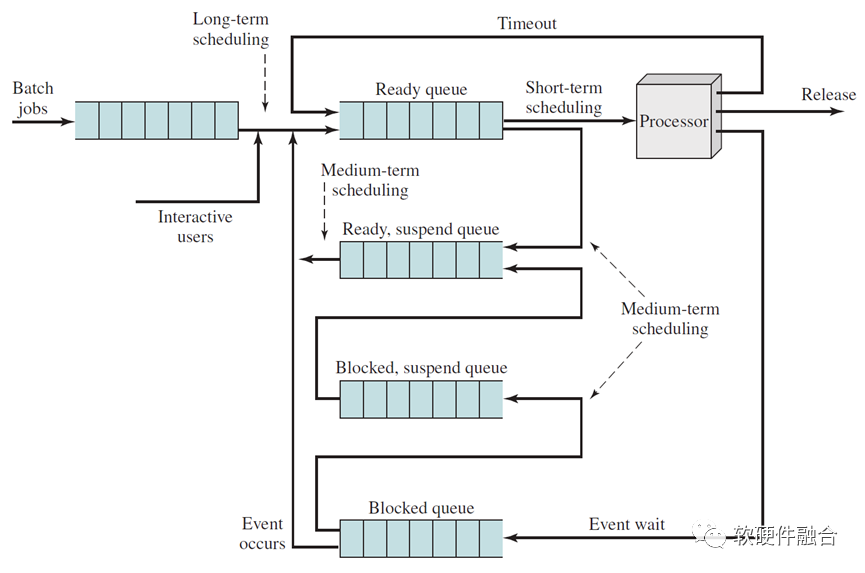
圖 單核系統的用于調度的隊列框圖
多進程宏觀并行、微觀分時調度是現代操作系統最顯著的特征。同一時刻,在內存中有多個進程/線程程序,它們分別處于運行態(在CPU中運行)、就緒態(在內存等待)、阻塞態(在內存掛起)。根據事件觸發以及進程/線程的狀態,也根據調度算法來選擇要進入執行狀態(送到處理器運行)的進程/線程,也決定了每個進程的狀態更新。
在現代操作系統里,每個進程會包含一個或多個線程,進程作為資源分配的最小單位,線程作為任務調度的最小單位。
多核任務調度,最簡單的是復用單處理器調度的基本架構,將所有的工作任務放入一個單獨的隊列。但這種方式擴展性不好,多核調度的時候需要頻繁地給隊列加鎖。鎖會帶來巨大的性能損失,并且隨著CPU核的數量增加而調度的性能指數級下降。還有一個問題,是調度可能會引起線程在不同的處理器運行,這會導致在CPU緩存中的程序現場需要跨CPU訪問,從而導致性能的下降。
于是,有了多隊列任務調度,比如給每個CPU核創建獨立的任務隊列,分別調度。每個CPU調度之間相互獨立,就避免了單隊列方式中由于數據共享及同步帶來的問題。多隊列任務調度,具有更好的擴展性,隨CPU核的數量增加,鎖和緩存跨CPU訪問的問題不會擴大。但多隊列也會有新問題,即負載可能會不夠均衡。所以,就需要任務在不同的隊列遷移,從而確保所有的CPU負載足夠均衡。
02操作系統視角看超異構計算架構
2.1 超異構計算簡介
從單核串行到(同構)多核并行,再從同構的多核并行到異構的多核并行。而典型的異構多核也有CPU+GPU以及CPU+DSA兩大類模式。
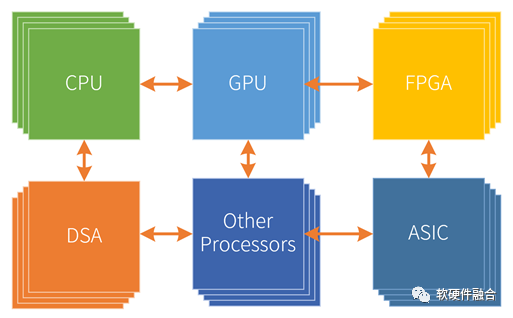
超異構計算指的是多種異構計算的融合,最終形成CPU+GPU+多個不同類型DSA以及其他各種可能的處理器類型的模式。
因此,我們可以把計算架構的發展分為如下幾個階段:
第一階段,單核CPU串行計算;
第二階段,多核CPU同構并行計算;
第三階段,CPUs+GPUs的異構并行計算;
第四階段,CPUs+DSAs的異構并行階段(n,單個領域的多個同構DSA);
第五階段,CPUs+GPUs+DSAs的超異構并行階段(m*n,多個領域DSA,每個DSA還有多個)。
2.2 超異構計算機的功能模塊分類
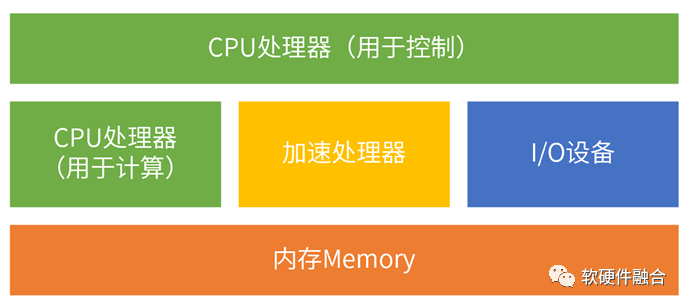
在經典計算機架構下,我們劃分了三個模塊:CPU處理器、I/O設備和內存。在超異構架構下,我們做一些調整:
內存和I/O設備保持不變,跟經典計算機的作用一致。
把CPU按照功能分為兩類,一類是用于控制類任務的CPU,一類是用于計算類任務的CPU。計算類CPU則和加速處理器組成對等架構下的計算處理器節點。需要注意的是,這里的CPU劃分是邏輯上的,物理上可能還會是同一個CPU,控制CPU和計算CPU分時共享同一個物理CPU。
跟異構計算一樣,增加了加速處理器類別。但和異構的單個加速處理器相比,超異構情況下的加速處理器可以有很多類型,每種類型還可以有很多處理核。在以CPU為中心架構下,加速處理器是跟I/O類似的外圍設備;在超異構計算以數據為中心架構下,加速處理器是和CPU功能類似的對等的計算處理器。
2.3 超異構操作系統的任務調度
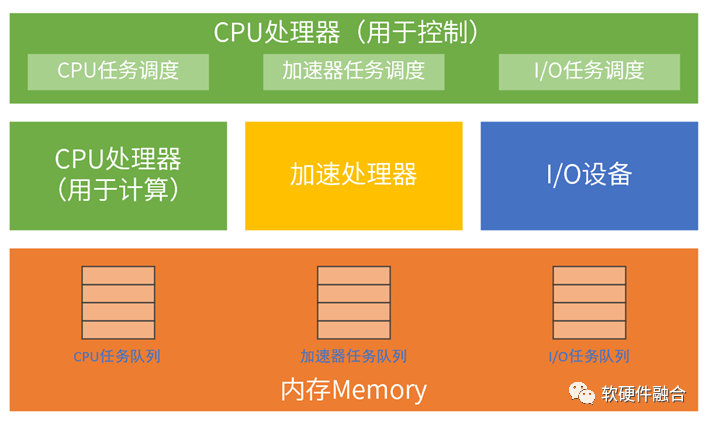
我們在上一節的超異構計算機的功能模塊圖基礎上,加入任務調度的示意信息,超異構操作系統的任務調度包含三部分:
CPU任務調度和經典CPU計算機一致,負責CPU任務的調度,最終把任務送到CPU去執行;任務的執行會包含任務的程序(片段)輸入、數據的輸入以及計算結果的輸出。
I/O任務調度和經典CPU計算機一致,這里的任務調度,是通過驅動來完成的;任務的執行主要是外部數據的輸入輸出,比如網絡、存儲等數據。
增加的加速處理器調度部分,也是復用現有的各種加速器的框架及Runtime等相關的加速處理器軟件堆棧。任務的執行,跟CPU類似,有程序(片段)、數據輸入和結果輸出。
2.4 超異構操作系統分層架構
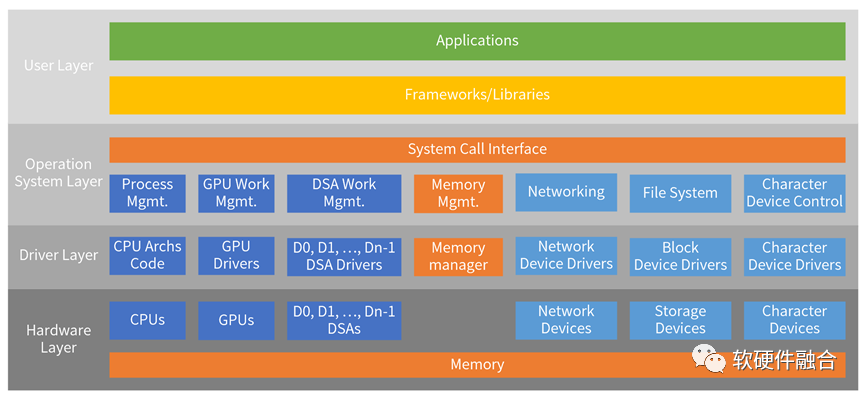
根據1.1節的經典操作系統分層架構,我們可以給出一個典型的超異構操作系統的分層架構圖。除了經典計算機的各種功能組件之外,還需要加入GPU、各類DSA的相關軟件棧。
以硬件資源為單位的獨立的軟件堆棧和經典計算機操作系統以及添加了異構計算軟件框架的內容是基本一致的。如果不考慮性能優化的話,可以復用現有的技術棧。但這樣能提升的性能非常有限,這跟SOC中的多異構軟件級協同沒有本質區別。
隨著性能要求越來越高,也隨著硬件資源類型和數量越來越多,不同硬件資源之間的交互問題會凸顯。需要考慮基于硬件所形成的垂直軟件棧之間的協同,才能最大限度地釋放超異構平臺的性能優勢。
03超異構平臺軟件架構
需要解決的若干技術挑戰
3.1 處理器架構標準化問題

加速處理器的運行,必然是需要有Host CPU的上層軟件的控制和協作;加速處理器要想更加高效的運行,把性能優勢發揮出來,并且讓軟件人員更容易使用,就需要有功能強大的軟件框架,也需要形成相應的生態。例如,強大的NVIDIA GPU,離不開CUDA軟件框架和生態。理想化的,這個框架需要足夠開放標準,并且最好能集成進主流的操作系統,比如Linux。
框架承上啟下:從框架往下,硬件設計者需要自己的硬件支持主流開發框架,才能使得自己的產品在客戶的業務場景低門檻的使用起來;從框架往上,軟件開發者不需要關注硬件細節,只需要關注自己的業務創新,把精力投入到更高價值的工作。
傳統的開發思路是“從下而上,硬件定義軟件”:比如x86做得足夠的好,所以才有了基于x86平臺的工具鏈以及成熟的商業應用軟件等強大的軟件生態;再比如NVIDIA的GPU和CUDA,基于自己的GPGPU,構建了足夠好的CUDA框架。上層的軟件開發者都是基于這些硬件平臺來構建自己的軟件。
隨著行業的發展,現在逐漸地過渡到了“自上而下,軟件定義硬件”的階段:通常是,用戶的業務已經在x86 CPU平臺完成了開發,并且整個業務系統已經得到了充分的驗證,業務邏輯也是相當的確定。用戶希望自己掌控系統的一切,硬件只是整個系統的運行平臺而已。客戶面臨性能和成本的壓力,于是希望從x86遷移到ARM或RSIC-v,或者通過硬件進行性能加速——但絕對不希望改變自己已有的軟件業務邏輯!
最終,扮演關鍵角色的會是框架:
框架可能是芯片巨頭提供的封閉或開放框架(對自己的芯片更加友好);
也可能是某些大客戶自有的框架(需要芯片公司去適配);
還可能是全行業形成廣泛共識的框架(軟件基于公有框架開發,不綁定硬件;硬件基于框架設計,不需要太多差異化定制,芯片可以起量,降低單位芯片成本)。
在框架的約束下,各類加速處理器的架構需要逐步收斂,走向標準化。
這里再強調一下“架構”的概念:架構指的是硬件呈現給軟件的接口,也即軟件視角看到的硬件;而硬件實現的架構通常稱為微架構。
3.2 內存旁路實現高性能數據交互
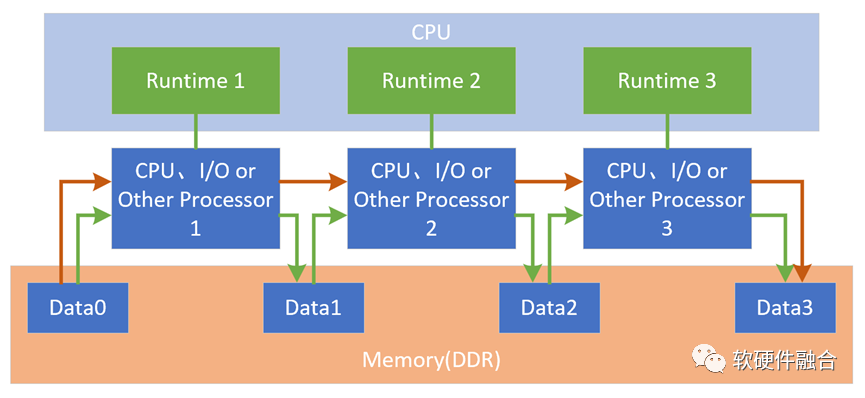
在SOC平臺上,所有的硬件加速器是通過軟件聯系到一起的,如上圖的綠色連線部分。這樣的方式有如下一些問題:
所有的數據交互需要CPU軟件參與,然后數據共享是通過內存。但是,隨著大通量數據處理越來越多,而CPU已經性能瓶頸,CPU越來越成為整個系統的性能瓶頸。
因為要頻繁的訪問主存,對存儲的帶寬要求很高;并且從整個處理數據通路比較長,也會顯著的增加處理延遲。
隨著硬件的處理器資源越來越多,處理器交互的流量會指數級激增,也對現有的軟件實現的交互架構提出了更多的挑戰。
需要構建一套快速的內存旁路機制,讓加速處理器的處理結果不需要回到內存,而是直接的發送給下一個處理器,如圖中橙色連線部分。
當然,這里只是對這個問題的簡單示意,實際的問題遠比這個示意情況復雜的多。
3.3 應用跨不同類型處理器的問題
當處理器的類型越來越多,應用也需要有一定的適應性:
不但可以跨不同的同類型處理器運行;
還需要能跨CPU、GPU和DSA運行;
并且這種跨越可以是靜態的也可以是動態的。
應用跨處理器類型的價值體現在:
最大化的利用硬件提供的更高層次的能力。性能能力DSA>>GPU>>CPU,而不同平臺的處理器資源不盡相同,可以讓應用盡可能選擇性能更好的處理器。
同時,也提高了整個軟件系統的的自適應能力。使得整個軟件系統可以在,由不同資源組合而成的,異質的超異構平臺上運行。
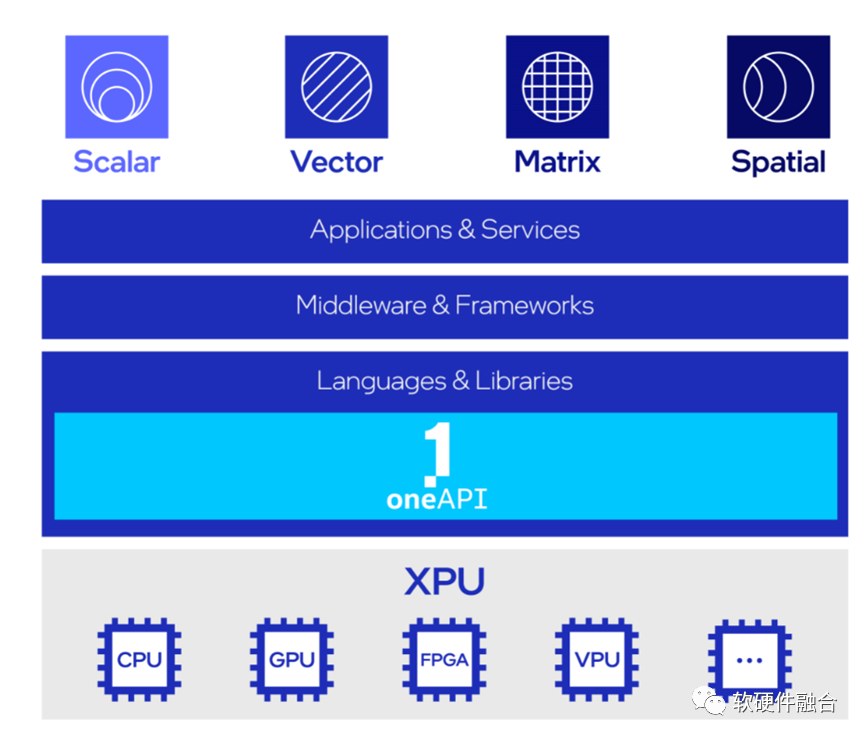
要實現應用跨不同類型處理器運行,需要在框架層面做很多工作。這塊的技術和知識,可以參考Intel的oneAPI。
oneAPI是開源的跨平臺編程框架,底層是不同的XPU處理器,通過oneAPI提供一致性編程接口,使得應用跨平臺復用。
3.4 分布式擴展的問題

在數據中心,大家進行資源和算力擴展的時候通常有兩種方式,一種是提升單位設備的能力(Scale up),一種是提高設備的數量(Scale out)。
在之前文章中講到算力提升的時候,我們也給出了一個公式:“實際總算力=(單處理器芯片)性能x處理器芯片數量x利用率”:
一方面,我們需要通過超異構來實現單芯片的性能飛速提升(Scale up);
另一方面,還需要考慮芯片的高可擴展性,這樣就可以通過擴展芯片和設備數量的方式快速的提升整體算力(Scale out);
此外,還需要有強大的分布式操作系統的支持,把更多的跨芯片、跨服務器、跨數據中心、跨云網邊端的宏觀數以億計的各種資源整合成一個資源和算力整體,這樣就可以非常方便的、隨時隨地的為千千萬的用戶提供無窮無盡的算力,從而支持用戶數以萬億計的各類應用和服務。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19409瀏覽量
231190 -
操作系統
+關注
關注
37文章
6896瀏覽量
123749 -
計算機系統
+關注
關注
0文章
289瀏覽量
24214 -
網絡通信
+關注
關注
4文章
814瀏覽量
29947 -
處理器芯片
+關注
關注
0文章
117瀏覽量
19833
原文標題:超異構計算時代的操作系統架構初探
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

【一文看懂】什么是異構計算?

異構計算的前世今生
「深圳云棲大會」大數據時代以及人工智能推動下的阿里云異構計算
異構計算的前世今生
異構計算場景下構建可信執行環境
異構計算的兩大派別 為什么需要異構計算?
異構計算,你準備好了么?
異構計算面臨的挑戰和未來發展趨勢
新一代計算架構超異構計算技術是什么 異構走向超異構案例分析

異構計算:解鎖算力潛能的新途徑





 工商網監
工商網監
評論