 Linux管道和FIFO應用筆記
Linux管道和FIFO應用筆記
概述
管道最常見的地方是shell中,比如:
$ ls | wc -l
為了執行上面的命令,shell創建了兩個進程來分別執行 ls 和 wc (通過 fork() 和 exec() 完成),如下:
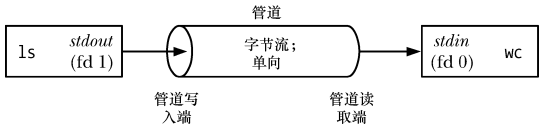
從上圖可以看出,可以將管道看成是一組水管,它允許數據從一個進程流向另一個進程,這也是管道名稱的由來。
從上圖可以看出,由兩個進程連接到了管道上,這樣寫入進程 ls 就將其標準輸出(文件描述符為1)連接到來管道的寫入段,讀取進程 wc 就將其標準輸入(文件描述符為0)連接到管道的讀取端。實際上,這兩個進程并不知道管道的存在,它們只是從標準文件描述符中讀取和寫入數據。shell 必須要完成相關的工作。
一個管道是一個字節流
管道是一個字節流,即在使用管道時是不存在消息或者消息邊界的概念的:
從管道中讀取數據的進程可以讀取任意大小的數據塊,而不管寫入進程寫入管道的數據塊的大小是什么
通過管道傳遞的數據是順序的,從管道中讀取出來的字節的順序與它們被寫入管道的順序是完全一樣的,在管道中無法使用 lseek() 來隨機的訪問數據
如果需要在管道中實現離散消息的概念,那么就必須要在應用程序中完成這些工作。雖然這是可行的,但如果碰到這種需求的話最好使用其他 IPC 機制,如消息隊列和數據報 socket。
從管道中讀取數據
試圖從一個當前為空的管道中讀取數據將會被阻塞直至至少有一個字節被寫入到管道中為止。
如果管道的寫入端被關閉了,那么從管道中讀取數據的進程在讀完管道中剩余的所有數據之后將會看到文件結束(即 read() 返回 0)。
管道是單向的
在管道中數據的傳遞方向是單向的。管道的一端用于寫入,另一端則用于讀取。
在其他一些 UNIX 實現上,特別是那些從 System V Release 4 演化而來的系統,管道是雙向的(所謂的流管道)。雙向管道并沒有在任何 UNIX 標準中進行規定,因此即使在提供了雙向管道的實現上最好也避免依賴這種語義。作為替代方案,可以使用 UNIX domain 流 socket 對(通過 socketpair() 系統調用來創建),它提供了一種標準的雙向通信機制,并且其語義與流管道是等價的。
可以確保寫入不超過 PIPE_BUF 字節的操作是原子的
如果多個進程寫入同一個管道,那么如果它們在一個時刻寫入的數據量不超過 PIPE_BUF 字節,那么就可以確保寫入的數據不會發生相互混合的情況。
SUSv3 要求 PIPE_BUF 至少為 _POSIX_PIPE_BUF(512)。一個實現應該定義 PIPE_BUF(在
當寫入管道的數據塊的大小超過了 PIPE_BUF 字節,那么內核可能會將數據分割成幾個較小的片段來傳輸,在讀者從管道中消耗數據時再附加上后繼的數據(write()調用會阻塞直到所有數據被寫入到管道為止)
當只有一個進程向管道寫入數據時(通常的情況),PIPE_BUF 的取值就沒有關系了
但如果有多個寫入進程,那么大數據塊的寫入可能會被分解成任意大小的段(可能會小于 PIPE_BUF 字節),并且可能會出現與其他進程寫入的數據交叉的現象
只有在數據被傳輸到管道的時候 PIPE_BUF 限制才會起作用。當寫入的數據達到 PIPE_BUF 字節時,write() 會在必要的時候阻塞知道管道中的可用空間足以原子的完成此操作。如果寫入的數據大于 PIPE_BUF 字節,那么 write() 會盡可能的多傳輸數據以充滿整個管道,然后阻塞直到一些讀取進程從管道中移除了數據。如果此類阻塞的 write() 被一個信號處理器中斷了,那么這個調用會被解除阻塞并返回成功傳輸到管道中的字節數,這個字節數會少于請求寫入的字節數(所謂的部分寫入)。
管道的容量是有限的
管道其實是一個在內核內存中維護的緩沖器,這個緩沖器的存儲能力是有限的。一旦管道被填滿之后,后繼向管道的寫入操作就會被阻塞直到讀者從管道中移除了一些數據為止。
SUSv3 并沒有規定管道的存儲能力。在早于 2.6.11 的 Linux 內核中,管道的存儲能力與系統頁面的大小是一致的(如在 x86-32 上是 4096 字節),而從 Linux 2.6.11 起,管道的存儲能力是 65,536 字節。其他 UNIX 實現上的管道的存儲能力可能是不同的。
一般來講,一個應用程序無需知道管道的實際存儲能力。如果需要防止寫者進程阻塞,那么從管道中讀取數據的進程應該被設計成以盡可能快的速度從管道中讀取數據。
創建和使用管道
#includeint pipe(int fd[2]);
pipe() 創建一個新管道
成功的調用在數組 fd 中返回兩個打開的文件描述符,一個表示管道的讀取端 fd[0],一個表示管道的寫入端 fd[1]
調用 pipe() 函數時,首先在內核中開辟一塊緩沖區用于通信,它有一個讀端和一個寫端,然后通過 fd 參數傳出給用戶進程兩個文件描述符,fd[0] 指向管道的讀端,fd[1] 指向管道的寫段。
不要用 fd[0] 寫數據,也不要用 fd[1] 讀數據,其行為未定義的,但在有些系統上可能會返回 -1 表示調用失敗。數據只能從 fd[0] 中讀取,數據也只能寫入到fd[1],不能倒過來。
與所有文件描述符一樣,可以使用 read() 和 write() 系統調用來在管道上執行 IO,一旦向管道的寫入端寫入數據之后立即就能從管道的讀取端讀取數據。管道上的 read() 調用會讀取的數據量為所請求的字節數與管道中當前存在的字節數兩者之間的較小值。當管道為空時,讀取操作阻塞。
也可以在管道上使用 stdio 函數(printf()、scanf() 等),只需要首先使用 fdopen() 獲取一個與 filedes 中的某個描述符對應的文件流即可。但在這樣做的時候需要解決 stdio 緩沖問題。
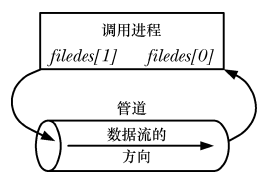
管道可以用于進程內部自己通信:
管道可以用于親緣關系(子進程會繼承父進程中的文件描述符的副本)進程中通信:
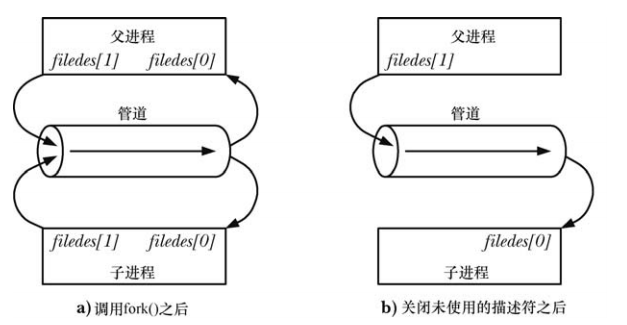
不建議將單個 pipe 用作全雙工的,或者不關閉用作半雙工而不關閉相應的讀端/寫端,這樣很可能導致死鎖:如果兩個進程同時試圖從管道中讀取數據,那么就無法確定哪個進程會首先讀取成功,從而產生兩個進程競爭數據了。要防止這種競爭情況的出現就需要使用某種同步機制。這時,就需要考慮死鎖問題了,因為如果兩個進程都試圖從空管道中讀取數據或者嘗試向已滿的管道中寫入數據就可能會發生死鎖。
如果我們想要一個雙向數據流時,可以創建兩個管道,每個方向一個。
管道允許相關進程間的通信
其實管道可以用于任意兩個甚至更多相關進程之間的通信,只要在創建子進程的系列 fork() 調用之前通過一個共同的祖先進程創建管道即可。
關閉未使用管道文件描述符
關閉未使用管道文件描述符不僅僅是為了確保進程不會消耗盡其文件描述符的限制。
從管道中讀取數據的進程會關閉其持有的管道的寫入描述符,這樣當其他進程完成輸出并關閉其寫入描述符之后,讀者就能夠看到文件結束。反之,如果讀取的進程沒有關閉管道的寫入端,那么在其他進程關閉了寫入描述符之后,即使讀者已經讀完了管道中的所有數據,也不會看到文件結束。因為此時內核知道至少還有一個管道的寫入描述符打開著,從而導致 read() 阻塞。
當一個進程視圖向一個管道中寫入數據但沒有任何進程擁有該管道的打開著的讀取描述符時,內核會向寫入進程發送一個 SIGPIPE 信號,默認情況下,這個信號將會殺死進程,但進程可以選擇忽略或者設置信號處理器,這樣 write() 將因為 EPIPE 錯誤而失敗。收到 SIGPIPE 信號和得到 EPIPE 錯誤對于標識管道的狀態是有意義的,這就是為什么需要關閉管道的未使用讀取描述符的原因。如果寫入進程沒有關閉管道的讀取端,那么即使在其他進程已經關閉了管道的讀取端之后,寫入進程仍然能夠向管道寫入數據,最后寫入進程會將數據充滿整個管道,后續的寫入請求會將永遠阻塞。
使用管道連接過濾器
當管道被創建之后,為管道的兩端分配的文件描述符是可用描述符中數值最小的兩個,由于通常情況下,進程已經使用了描述符 0,1,2,因此會為管道分配一些數值更大的描述符。如果需要使用管道連接兩個過濾器(即從 stdin 讀取和寫入到 stdout),使得一個程序的標準輸出被重定向到管道中,就需要采用復制文件描述符技術。
int pfd[2]; pipe(pfd); close(STDOUT_FILENO); dup2(pfd[1],STDOUT_FILENO);
上面這些調用的最終結果是進程的標準輸出被綁定到管道的寫入端,而對應的一組調用可以用來將進程的標準的輸入綁定到管道的讀取端上。
通過管道與 shell 命令進行通信: popen()
#includeFILE *popen (const char *command, const char *mode);
pipe() 和 close() 是最底層的系統調用,它的進一步封裝是 popen() 和 pclose()
popen()函數創建了一個管道,然后創建了一個子進程來執行 shell,而 shell 又創建了一個子進程來執行command字符串
mode 參數是一個字符串:
它確定調用進程是從管道中讀取數據(mode 是 r)還是將數據寫入到管道中(mode 是 w)
由于管道是向的,因此無法在執行的 command 中進行雙向通信
mode 的取值確定了所執行的命令的標準輸出是連接到管道的寫入端還是將其標準輸入連接到管道的讀取端
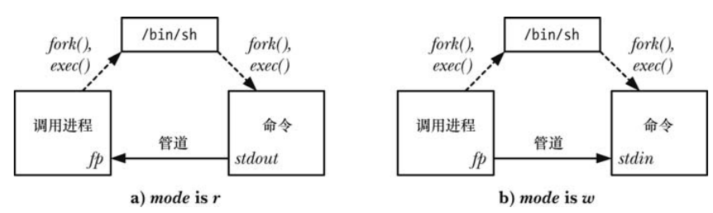
popen() 在成功時會返回可供 stdio 庫函數使用的文件流指針。當發生錯誤時,popen() 會返回 NULL 并設置 errno 以標示出發生錯誤的原因
在 popen() 調用之后,調用進程使用管道來讀取 command 的輸出或使用管道向其發送輸入。與使用 pipe() 創建的管道一樣,當從管道中讀取數據時,調用進程在 command 關閉管道的寫入端之后會看到文件結束;當向管道寫入數據時,如果 command 已經關閉了管道的讀取端,那么調用進程就會收到 SIGPIPE 信號并得到 EPIPE 錯誤
#includeint pclose ( FILE * stream);
一旦IO結束之后可以使用 pclose() 函數關閉管道并等待子進程中的 shell 終止(不應該使用 fclose() 函數,因為它不會等待子進程。)
pclose() 在成功時會返回子進程中 shell 的終止狀態(即 shell 所執行的最后一條命令的終止狀態,除非 shell 是被信號殺死的)
和 system() 一樣,如果無法執行shell,那么 pclose() 會返回一個值就像子進程中的 shell 通過調用 _exit(127) 來終止一樣
如果發生了其他錯誤,那么 pclose() 返回 ?1。其中可能發生的一個錯誤是無法取得終止狀態
當執行等待以獲取子進程中 shell 的狀態時,SUSv3 要求 pclose() 與 system() 一樣,即在內部的 waitpid() 調用被一個信號處理器中斷之后自動重啟該調用。
與 system() 一樣,在特權進程中永遠都不應該使用 popen()。
popen優缺點:
優點:在 Linux 中所有的參數擴展都是由 shell 來完成的。所以在啟動 command 命令之前程序先啟動 shell 來分析 command 字符串,就可以使用各種 shell 擴展(比如通配符),這樣我們可以通過 popen() 調用非常復雜的 shell 命令
缺點:對于每個 popen() 調用,不僅要啟動一個被請求的程序,還需要啟動一個 shell。即每一個 popen() 將啟動兩個進程。從效率和資源的角度看,popen() 函數的調用比正常方式要慢一些
pipe() VS popen()
pipe()是一個底層調用,popen() 是一個高級的函數
pipe() 單純的創建管道,而 popen() 創建管道的同時 fork() 子進程
popen() 在兩個進程中傳遞數據時需要調用 shell 來解釋請求命令;pipe() 在兩個進程中傳遞數據不需要啟動 shell 來解釋請求命令,同時提供了對讀寫數據的更多控制(popen() 必須時 shell 命令,pipe() 則無硬性要求)
popen() 函數是基于文件流(FILE)工作的,而 pipe() 是基于文件描述符工作的,所以在使用 pipe() 后,數據必須要用底層的read() 和 write() 調用來讀取和發送
管道和 stdio 緩沖
由于 popen() 調用返回的文件流指針沒有引用一個終端,因此 stdio 庫會對這種流應用塊緩沖。這意味著當 mode 的值為 w 來調用 popen() 時,默認情況下只有當 stdio 緩沖區被充滿或者使用 pclose() 關閉了管道之后才會被發送到管道的另一端的子進程。在很多情況下,這種處理方式是不存在問題的。但如果需要確保子進程能夠立即從管道中接收數據,那么就需要定期調用 fflush() 或使用 setbuf(fp, NULL) 調用禁用 stdio 緩沖。當使用 pipe() 系統調用創建管道,然后使用 fdopen() 獲取一個與管道的寫入端對應的 stdio 流時也可以使用這項技術
如果調用 popen() 的進程正在從管道中讀取數據(即 mode 是 r),那么事情就不是那么簡單了。在這樣情況下如果子進程正在使用 stdio 庫,那么——除非它顯式地調用了 fflush() 或 setbuf() ,其輸出只有在子進程填滿 stdio 緩沖器或調用了 fclose() 之后才會對調用進程可用。(如果正在從使用 pipe() 創建的管道中讀取數據并且向另一端寫入數據的進程正在使用 stdio 庫,那么同樣的規則也是適用的。)如果這是一個問題,那么能采取的措施就比較有限的,除非能夠修改在子進程中運行的程序的源代碼使之包含對 setbuf() 或 fflush() 調用。
如果無法修改源代碼,那么可以使用偽終端來替換管道。一個偽終端是一個 IPC 通道,對進程來講它就像是一個終端。其結果是 stdio 庫會逐行輸出緩沖器中的數據。
命名管道(FIFO)
上述管道雖然實現了進程間通信,但是它具有一定的局限性:
匿名管道只能是具有血緣關系的進程之間通信
它只能實現一個進程寫另一個進程讀,而如果需要兩者同時進行時,就得重新打開一個管道
為了使任意兩個進程之間能夠通信,就提出了命名管道(named pipe 或 FIFO):
FIFO 與管道的區別:FIFO 在文件系統中擁有一個名稱,并且其打開方式與打開一個普通文件一樣,能夠實現任何兩個進程之間通信。而匿名管道對于文件系統是不可見的,它僅限于在父子進程之間的通信
一旦打開了 FIFO,就能在它上面使用與操作管道和其他文件的系統調用一樣的 IO 系統調用 read(),write(),close()。與管道一樣,FIFO 也有一個寫入端和讀取端,并且總是遵循先進先出的原則,即第一個進來的數據會第一個被讀走
與管道一樣,當所有引用 FIFO 的描述符都關閉之后,所有未被讀取的數據都將被丟棄
使用 mkfifo 命令可以在 shell 中創建一個 FIFO:
mkfifo [-m mode] pathname
pathname 是創建的 FIFO 的名稱,-m 選項指定權限 mode,其工作方式與 chmod 命令一樣
fstat() 和 stat() 函數會在 stat 結構的 st_mode 字段返回 S_IFIFO,使用 ls -l 列出文件時,FIFO 文件在第一列的類型為 p,ls -F 會在 FIFO 路徑名后面附加管道符 |
#include#include int mkfifo(const char *pathname,mode_t mode);
mode 參數指定了新 FIFO 的權限,這些權限會按照進程的 umask 值來取掩碼
一旦創建了 FIFO,任何進程都能夠打開它,只要它通過常規的文件權限檢測
使用 FIFO 時唯一明智的做法是在兩端分別設置一個讀取進程和一個寫入進程。這樣在默認情況下,打開一個 FIFO 以便讀取數據(open() O_RDONLY 標記)將會阻塞直到另一個進程打開 FIFO 以寫入數(open() O_WRONLY 標記)為止。相應地,打開一個 FIFO 以寫入數據將會阻塞直到另一個進程打開 FIFO 以讀取數據為止。換句話說,打開一個 FIFO 會同步讀取進程和寫入進程。如果一個 FIFO 的另一端已經打開(可能是因為一對進程已經打開了 FIFO 的兩端),那么open() 調用會立即成功。
在大多數 Unix 實現上(包含 Linux),當打開一個 FIFO 時可以通過指定 O_RDWR 標記來繞過打開 FIFO 時的阻塞行為。這樣,open() 會立即返回,但無法使用返回的文件描述符在 FIFO 上讀取和寫入數據。這種做法破壞了 FIFO 的 IO 模型,SUSv3 明確指出以 O_RDWR 標記打開一個 FIFO 的結果是未知的,因此出于可移植性的原因,開發人員不應該使用這項技術。對于那些需要避免在打開 FIFO 時發生阻塞的需求,open() 的 O_NONBLOCK 標記提供了一種標準化的方法來完成這個任務:
open(const char *path, O_RDONLY | O_NONBLOCK); open(const char *path, O_WRONLY | O_NONBLOCK);
在打開一個 FIFO 時避免使用 O_RDWR 標記還有另外一個原因,當采用那種方式調用 open() 之后,調用進程在從返回的文件描述符中讀取數據時永遠都不會看到文件結束,因為永遠都至少存在一個文件描述符被打開著以等待數據被寫入 FIFO,即進程從中讀取數據的那個描述符。
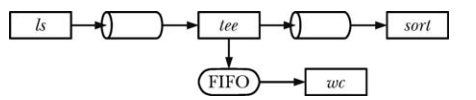
使用 FIFO 和 tee 創建雙重管道線
shell 管道線的其中一個特征是它們是線性的,管道線中的每個進程都能讀取前一個進程產生的數據并將數據發送到其后一個進程中,使用 FIFO 就能夠在管道線中創建子進程,這樣除了將一個進程的輸出發送給管道線中的后面一個進程之外,還可以復制進程的輸出并將數據發送到另一個進程中,要完成這個任務就需要使用 tee 命令,它將其從標準輸入中讀取到的數據復制兩份并輸出:一份寫入標準輸出,另一份寫入到通過命令行參數指定的文件中。
mkfifo myfifo wc -l < myfifo & ls -l | tee myfifo | sort -k5n
非阻塞 IO
當一個進程打開一個 FIFO 的一端時,如果 FIFO 的另一端還沒有被打開,那么該進程會被阻塞。但有些時候阻塞并不是期望的行為,而這可以通過在調用 open() 時指定 O_NONBLOCK 標記來實現。
如果 FIFO 的另一端已經被打開,那么 O_NONBLOCK 對 open() 調用不會產生任何影響,它會像往常一樣立即成功地打開 FIFO。只有當 FIFO 的另一端還沒有被打開的時候 O_NONBLOCK 標記才會起作用,而具體產生的影響則依賴于打開 FIFO 是用于讀取還是用于寫入的:
如果打開 FIFO 是為了讀取,并且 FIFO 的寫入端當前已經被打開,那么 open() 調用會立即成功(就像 FIFO 的另一端已經被打開一樣)
如果打開 FIFO 是為了寫入,并且還沒有打開 FIFO 的另一端來讀取數據,那么 open() 調用會失敗,并將 errno 設置為 ENXIO
為讀取而打開 FIFO 和為寫入而打開 FIFO 時 O_NONBLOCK 標記所起的作用不同是有原因的。當 FIFO 的另一個端沒有寫者時打開一個 FIFO 以便讀取數據是沒有問題的,因為任何試圖從 FIFO 讀取數據的操作都不會返回任何數據。但當試圖向沒有讀者的 FIFO 中寫入數據時將會導致 SIGPIPE 信號的產生以及 write() 返回 EPIPE 錯誤。
在 FIFO 上調用 open() 的語義總結如下:

在打開一個 FIFO 時,使用 O_NOBLOCK 標記存在兩個目的:
它允許單個進程打開一個 FIFO 的兩端,這個進程首先會在打開 FIFO 時指定 O_NOBLOCK 標記以便讀取數據,接著打開 FIFO 以便寫入數據
它防止打開兩個 FIFO 的進程之間產生死鎖
例如,下面的情況將會發生死鎖:

非阻塞 read() 和 write()
O_NONBLOCK 標記不僅會影響 open() 的語義,而且還會影響——因為在打開的文件描述中這個標記仍然被設置著——后續的 read() 和 write() 調用的語義。
有些時候需要修改一個已經打開的 FIFO(或另一種類型的文件)的 O_NONBLOCK 標記的狀態,具體存在這個需求的場景包括以下幾種:
使用 O_NONBLOCK 打開了一個 FIFO 但需要后續的 read() 和 write() 在阻塞模式下運行
需要啟用從 pipe() 返回的一個文件描述符的非阻塞模式。更一般地,可能需要更改從除 open() 調用之外的其他調用中,如每個由 shell 運行的新程序中自動被打開的三個標準描述符的其中一個或 socket() 返回的文件描述符,取得的任意文件描述符的非阻塞狀態
出于一些應用程序的特殊需求,需要切換一個文件描述符的 O_NONBLOCK 設置的開啟和關閉狀態
當碰到上面的需求時可以使用 fcntl() 啟用或禁用打開著的文件的 O_NONBLOCK 狀態標記。通過下面的代碼(忽略的錯誤檢查)可以啟用這個標記:
int flags; flags = fcntl(fd, F_GETFL); flags != O_NONBLOCK; fcntl(fd, F_SETFL, flags);
通過下面的代碼可以禁用這個標記:
flags = fcntl(fd, F_GETFL); flags &= ~O_NONBLOCK; fcntl(fd, F_SETFL, flags);
管道和 FIFO 中 read() 和 write() 的語義
FIFO 上的 read() 操作:

只有當沒有數據并且寫入端沒有被打開時阻塞和非阻塞讀取之間才存在差別。在這種情況下,普通的 read() 會被阻塞,而非阻塞 read() 會失敗并返回 EAGAIN 錯誤。
當 O_NONBLOCK 標記與 PIPE_BUF 限制共同起作用時 O_NONBLOCK 標記對象管道或 FIFO 寫入數據的影響會變得復雜。
FIFO 上的 write() 操作:
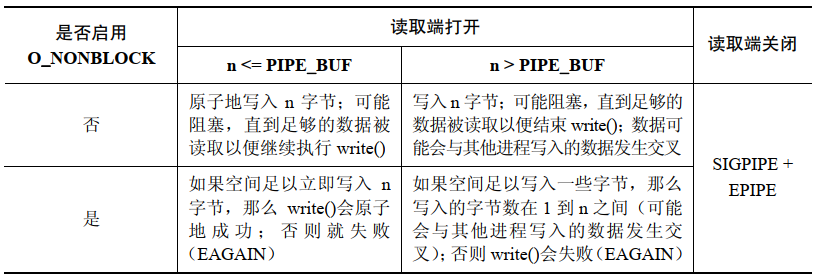
當數據無法立即被傳輸時 O_NONBLOCK 標記會導致在一個管道或 FIFO 上的 write() 失敗(錯誤是 EAGAIN)。這意味著當寫入了 PIPE_BUF 字節之后,如果在管道或 FIFO 中沒有足夠的空間了,那么 write() 會失敗,因為內核無法立即完成這個操作并且無法執行部分寫入,否則就會破壞不超過 PIPE_BUF 字節的寫入操作的原子性的要求
當一次寫入的數據量超過 PIPE_BUF 字節時,該寫入操作無需是原子的。因此,write() 會盡可能多地傳輸字節(部分寫)以充滿管道或 FIFO。在這種情況下,從 write() 返回的值是實際傳輸的字節數,并且調用者隨后必須要進行重試以寫入剩余的字節。但如果管道或 FIFO 已經滿了,從而導致哪怕連一個字節都無法傳輸了,那么 write() 會失敗并返回 EAGAIN 錯誤
審核編輯:湯梓紅
-
Linux
+關注
關注
87文章
11345瀏覽量
210389 -
fifo
+關注
關注
3文章
389瀏覽量
43855 -
命令
+關注
關注
5文章
696瀏覽量
22108 -
管道
+關注
關注
3文章
145瀏覽量
18023 -
Shell
+關注
關注
1文章
366瀏覽量
23444
原文標題:Linux管道和FIFO應用筆記
文章出處:【微信號:strongerHuang,微信公眾號:strongerHuang】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦







 工商網監
工商網監
評論