") GTC23 | 節(jié)能提速:NVIDIA Grace CPU 為每個(gè)數(shù)據(jù)中心鋪設(shè)節(jié)能計(jì)算快車道
GTC23 | 節(jié)能提速:NVIDIA Grace CPU 為每個(gè)數(shù)據(jù)中心鋪設(shè)節(jié)能計(jì)算快車道
主流應(yīng)用在運(yùn)行微服務(wù)、分析、模擬等工作時(shí)的能耗相比 X86 減少了 2 倍。
各項(xiàng)結(jié)果都表明,一個(gè)節(jié)能計(jì)算的新時(shí)代正在到來。
在真實(shí)工作負(fù)載測(cè)試中,NVIDIA Grace CPU 超級(jí)芯片在相同的功率范圍內(nèi)運(yùn)行主流數(shù)據(jù)中心 CPU 應(yīng)用的性能比 X86 處理器提高了 2 倍,這將帶來許多新的可能性。
這意味著數(shù)據(jù)中心可以處理兩倍的峰值流量并減少多達(dá)一半的電費(fèi)。它們還可以在空間有限的網(wǎng)絡(luò)邊緣實(shí)現(xiàn)更大的性能,甚至可以同時(shí)實(shí)現(xiàn)上述優(yōu)勢(shì)。
節(jié)能已成為數(shù)據(jù)中心的優(yōu)先事項(xiàng)
數(shù)據(jù)中心經(jīng)理需要依靠這些方案在當(dāng)今這個(gè)節(jié)能時(shí)代中快速發(fā)展。
摩爾定律實(shí)際上已經(jīng)過時(shí)。物理學(xué)不再允許工程師在保持空間和功耗不變的情況下加入更多的晶體管。
這就是為什么新一代 X86 CPU 的性能提升相比前一代產(chǎn)品還不到 30%”,這也是為什么越來越多的數(shù)據(jù)中心設(shè)置了功率上限。
再加上全球氣候變暖的威脅,數(shù)據(jù)中心電力供應(yīng)已經(jīng)沒有增容的余地,但它們?nèi)匀恍枰獫M足不斷增長(zhǎng)的算力需求。
在保持功耗不變的情況下提高性能
麥肯錫的一項(xiàng)研究顯示,美國(guó)的計(jì)算需求每年增長(zhǎng) 10%,并將在 2022 至 2030 年的八年內(nèi)翻倍。
麥肯錫表示:“因此,確保數(shù)據(jù)中心可持續(xù)性的壓力很大,一些監(jiān)管機(jī)構(gòu)和政府正在對(duì)新建的數(shù)據(jù)中心推行可持續(xù)性標(biāo)準(zhǔn)。”
根據(jù)麥肯錫所引用的一項(xiàng)調(diào)查,隨著摩爾定律的終結(jié),數(shù)據(jù)中心在計(jì)算效率上的進(jìn)展已停滯不前(見下圖)。
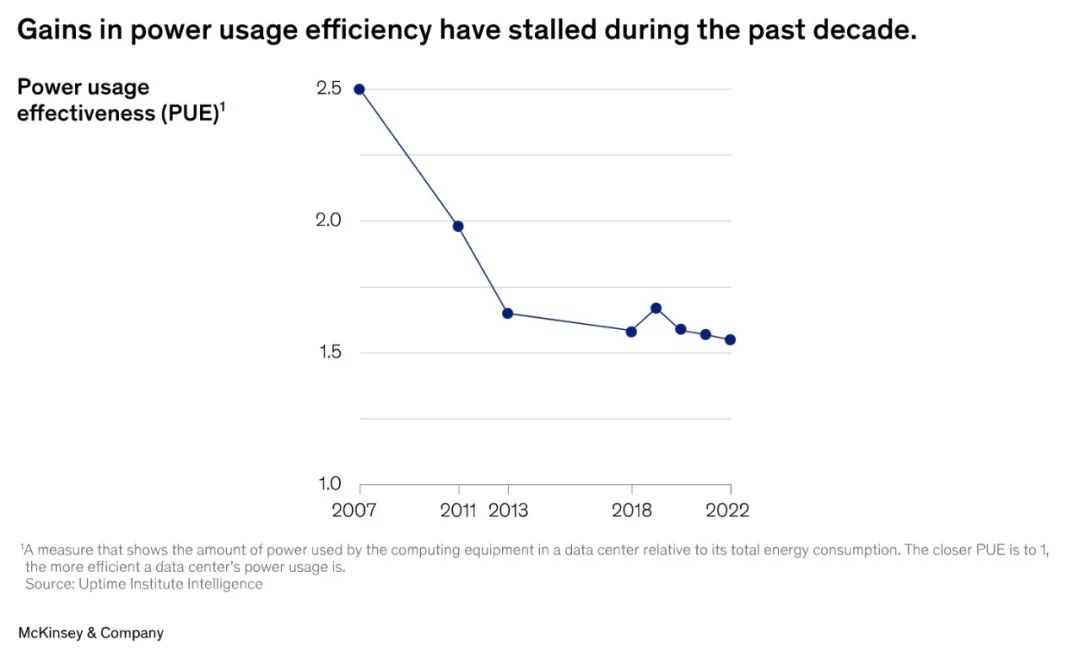
在當(dāng)今的環(huán)境下,NVIDIA Grace 所實(shí)現(xiàn)的 2 倍提升等于實(shí)現(xiàn)了驚人的多代飛躍,符合當(dāng)今數(shù)據(jù)中心高管的需求。
全球服務(wù)商 Equinix 管理著 240 多座數(shù)據(jù)中心。該公司的邊緣基礎(chǔ)設(shè)施負(fù)責(zé)人 Zac Smith 在一篇關(guān)于節(jié)能計(jì)算的文章中描述了這些需求。
“我們需要在減少碳排放的前提下提高性能。”Zac 表示:“我們有 1 萬家客戶指望我們?cè)谶@個(gè)過程中提供幫助。他們需要更多的數(shù)據(jù)和更高的智能化水平,而且往往要求使用 AI。另外,他們希望以可持續(xù)的方式來實(shí)現(xiàn)這一目標(biāo)。”
三項(xiàng) CPU 創(chuàng)新
得益于三項(xiàng)創(chuàng)新,Grace CPU 提供了高效性能。
它在一塊對(duì)分帶寬(一項(xiàng)吞吐量指標(biāo))為 3.2 TB/s 的裸芯片中使用一種超快的結(jié)構(gòu)將 72 個(gè) Arm Neoverse V2 核心連接在一起,然后使用 NVIDIA NVLink-C2C 互連技術(shù)在一個(gè)超級(jí)芯片封裝中連接其中的兩塊裸片,實(shí)現(xiàn) 900GB/s 的帶寬。
最后,它是第一個(gè)使用服務(wù)器級(jí) LPDDR5X 內(nèi)存的數(shù)據(jù)中心 CPU。這幫助它在成本相仿的情況下增加了高達(dá) 50%的內(nèi)存帶寬,且功耗只有常規(guī)服務(wù)器內(nèi)存的八分之一。緊湊的尺寸使其密度比典型的卡式內(nèi)存設(shè)計(jì)增加了 2 倍。
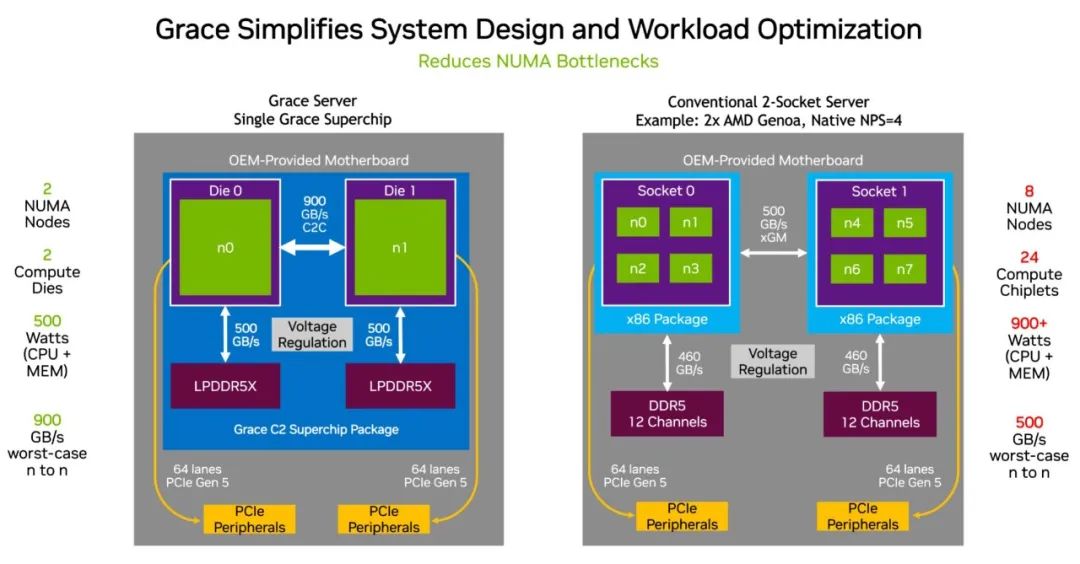
與現(xiàn)有的 x86 CPU 相比,NVIDIA Grace 的設(shè)計(jì)更加簡(jiǎn)單,提供更高的帶寬,而且能耗更低。
首批結(jié)果揭曉
現(xiàn)今,NVIDIA 工程師在 Grace 上運(yùn)行了真實(shí)的數(shù)據(jù)中心工作負(fù)載。
他們發(fā)現(xiàn),在相同的功率下,相比數(shù)據(jù)中心現(xiàn)有的 x86 CPU,Grace 更具優(yōu)勢(shì):
-
運(yùn)行微服務(wù)的速度快 2.3 倍
-
內(nèi)存密集型數(shù)據(jù)處理性能快 2 倍
-
在多個(gè)技術(shù)計(jì)算應(yīng)用上運(yùn)行流體力學(xué)計(jì)算工作時(shí),速度快 1.9 倍
如下圖所示,數(shù)據(jù)中心通常需要等到兩代或兩代以上的 CPU 才能獲得以上優(yōu)勢(shì)。
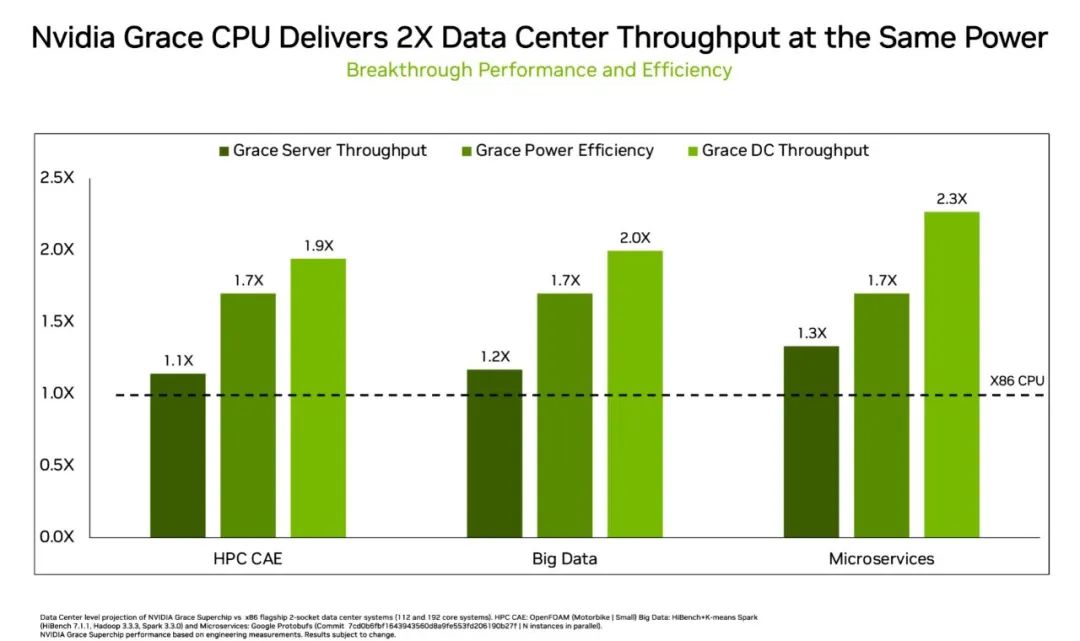
凈提升(淺綠色)來自于服務(wù)器間的性能提升(深綠色)以及附加的 Grace 服務(wù)器。憑借節(jié)能性,Grace 服務(wù)器適用于這一 x86 功率范圍(中間條)。
甚至在這些 CPU 工作結(jié)果出爐之前,用戶就對(duì) Grace 的創(chuàng)新做出了反應(yīng)。
美國(guó)洛斯阿拉莫斯國(guó)家實(shí)驗(yàn)室在 5 月宣布將在 Venado 中使用 Grace。這臺(tái) 10 EXAFLOP AI 超級(jí)計(jì)算機(jī)將推動(dòng)該實(shí)驗(yàn)室在材料科學(xué)和可再生能源等領(lǐng)域的工作。同時(shí),歐洲和亞洲的數(shù)據(jù)中心正在評(píng)估 Grace 的工作負(fù)載。
NVIDIA Grace 目前正在提供樣品,將在下半年投入生產(chǎn)。華碩、Atos、技嘉、慧與、高通、超微、緯創(chuàng)和 ZT Systems 正在建造使用該產(chǎn)品的服務(wù)器。
深入了解可持續(xù)計(jì)算
想要深入了解細(xì)節(jié),掃描二維碼閱讀關(guān)于 Grace 架構(gòu)的白皮書。
 ?
?
?
? ?
?
3 月 24 日 下午 14:00-16:00,繼續(xù)鎖定 GTC23,加入在線觀看(Watch Party) 派對(duì),從黃仁勛與 OpenAI 創(chuàng)始人兼首席科學(xué)家高能對(duì)話中,看 AI 的現(xiàn)狀和未來!
Watch Party 觀看指南
會(huì)議開始前 15 分鐘,
點(diǎn)擊下方出現(xiàn)的“JOIN WATCH PARTY NOW"

原文標(biāo)題:GTC23 | 節(jié)能提速:NVIDIA Grace CPU 為每個(gè)數(shù)據(jù)中心鋪設(shè)節(jié)能計(jì)算快車道
文章出處:【微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3848瀏覽量
91983
原文標(biāo)題:GTC23 | 節(jié)能提速:NVIDIA Grace CPU 為每個(gè)數(shù)據(jù)中心鋪設(shè)節(jié)能計(jì)算快車道
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
2024年星閃進(jìn)入規(guī)模商用快車道
云計(jì)算與數(shù)據(jù)中心的關(guān)系
ALDC 2024第四屆數(shù)據(jù)中心液冷產(chǎn)業(yè)大會(huì)圓滿舉辦

數(shù)據(jù)中心能耗較多 如何科學(xué)智慧化進(jìn)行整體解決方案呢
數(shù)據(jù)中心液冷需求、技術(shù)及實(shí)際應(yīng)用
安森美推出新款碳化硅芯片,助力AI數(shù)據(jù)中心節(jié)能
NVIDIA為新工業(yè)革命打造 AI 工廠和數(shù)據(jù)中心
計(jì)算機(jī)行業(yè)攜手 NVIDIA 為新工業(yè)革命打造 AI 工廠和數(shù)據(jù)中心

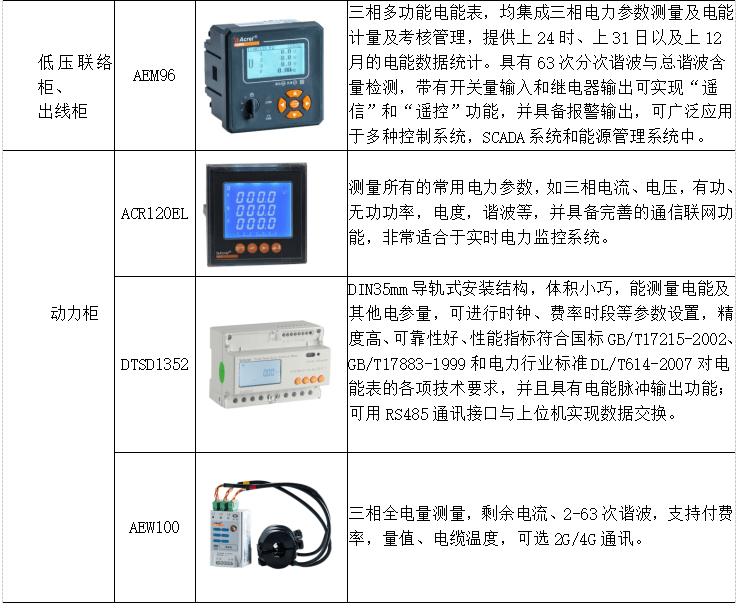
【解決方案】機(jī)房能源末端 數(shù)據(jù)中心 精密配電管理系統(tǒng)
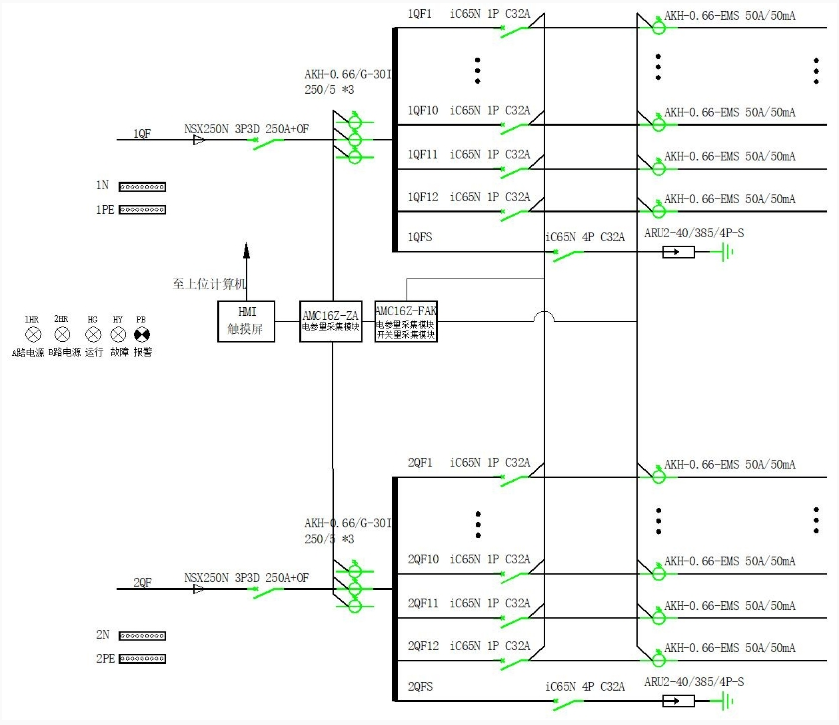
淺談數(shù)據(jù)中心節(jié)能措施探析與研究
安科瑞數(shù)據(jù)中心精密配電監(jiān)控裝置--列頭柜/UPS柜用電監(jiān)控
Green500全球最節(jié)能超級(jí)計(jì)算機(jī)榜單:采用NVIDIA技術(shù)包攬前三
進(jìn)一步解讀英偉達(dá) Blackwell 架構(gòu)、NVlink及GB200 超級(jí)芯片
中心能耗分析及節(jié)能策略研究與應(yīng)用
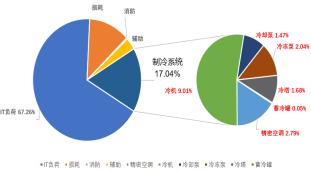
數(shù)據(jù)中心末端配電監(jiān)控解決方案-AMC100精密配電柜監(jiān)控





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論