 機器學習之關聯分析介紹
機器學習之關聯分析介紹
數據挖掘中應用較多的技術是機器學習。機器學習主流算法包括三種:關聯分析、分類分析、聚類分析。本文主要介紹關聯分析。
一、關聯分析概述
關聯分析可發現大量數據中隱藏的相關性(統計學的相關性分析不能直接發現數據中隱藏的相關性,需先人為猜測各變量間可能相關,再通過統計學計算相關性強弱),進而描述事物同時出現的規律和模式,被描述出的規律和模式可應用于市場營銷、事務分析等領域。
例如:某超市可通過關聯分析得出消費者購買牛奶和購買面包隱含的相關性。如果有關購買牛奶和購買面包衡量指標大于某一閾值,說明此二者相關,超市可以通過將售賣牛奶和面包的貨架靠近或推出牛奶和面包的組合裝促銷。
二、置信度與支持度
置信度與支持度是關聯分析的衡量指標。
置信度是指包含關聯規則所有特征(個人理解:特征可被理解為變量,包括自變量和因變量)的數據數量占包含自變量數據數量的比例。置信度高表示關聯規則所表示的自變量與因變量的相關性高。
支持度是指包含關聯規則的所有特征的數據數量占總數據數量的比例。支持度高表示關聯規則的出現頻率高,該關聯規則的重要性高。如果關聯規則的置信度高,但支持度低,表示該關聯規則出現頻率低,重要性低,利用價值低。
關聯分析需尋找支持度和置信度分別高于預先設定的支持度閾值和置信度閾值的關聯規則,該種關聯規則被稱為強關聯規則。不小于支持度閾值的關聯規則被稱為頻繁規則,不小于支持度閾值的特征集被稱為頻繁項集(項集可被理解為特征集,項、特征的具象化事物可以是商品,個人理解:頻繁規則和頻繁項集是一種事物兩個維度的表述)。
三、Apriori定律
在大數據關聯分析中,如果采用枚舉的方式找出所有的頻繁項集,則計算效率較低。因此,關聯分析可通過以下定律,簡化頻繁項集的確定過程。
Apriori定律1:頻繁項集的子集也是頻繁項集。如圖一所示,如果{C,D,E}是頻繁項集,意味著{C,D,E}在大數據中出現的頻率不小于支持度閾值,那么其子集如{C,D}在大數據出現的頻率也一定不小于支持度閾值,即為頻繁項集。 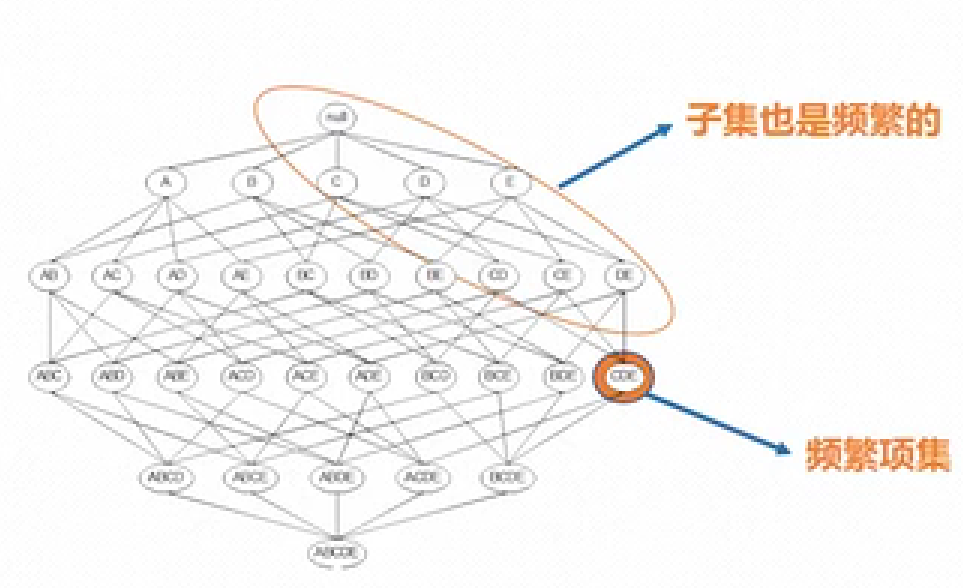
圖一,圖片來源:嗶哩嗶哩《數據科學導論》
Apriori定律2:非頻繁項集的超集(個人理解:某集合的超集是包含該集合的集合)也不是頻繁項集。如圖二所示,如果{A,B}不是頻繁項集,意味著{A,B}在大數據中出現的頻率小于支持度閾值,那么其超集如{A,B,C}在大數據出現的頻率也一定小于支持度閾值,即不是頻繁項集。 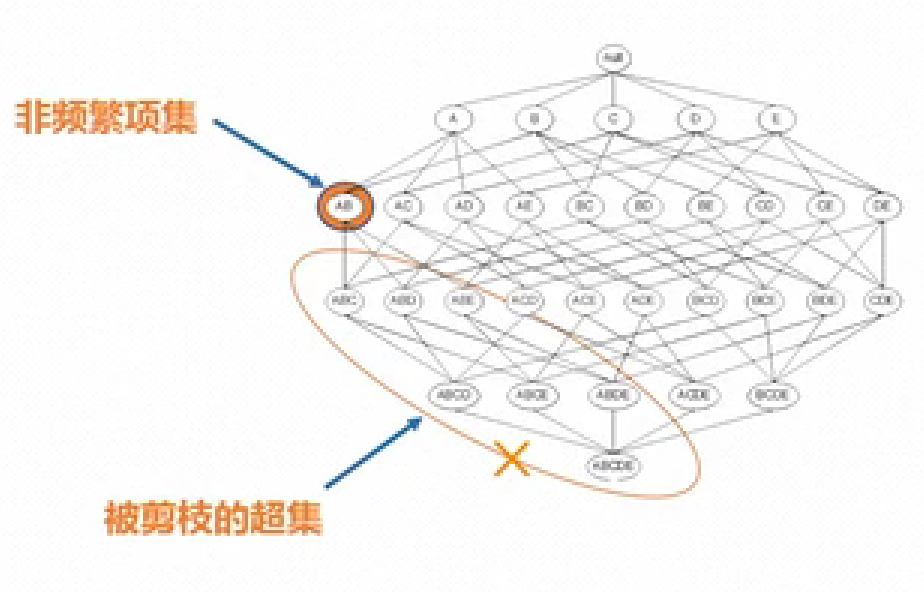
圖二,圖片來源:嗶哩嗶哩《數據科學導論》
以上兩定律在Apriori算法中被應用,Apriori算法是一種關聯分析算法。
四、關聯規則學習步驟
(1)找出所有的頻繁項集。
(2)根據頻繁項集生成頻繁規則。
(3)根據置信度指標進一步篩選頻繁規則。
五、確定候選項集的注意事項
在選擇候選項集(個人理解:候選項集指未進行置信度篩選的頻繁項集)需注意:
(1)應當避免產生太多不必要的候選項集。
(2)候選項集中不遺漏頻繁項集。
(3)不產生重復候選項集。
審核編輯:劉清
-
機器學習
+關注
關注
66文章
8438瀏覽量
133086 -
Apriori算法
+關注
關注
0文章
14瀏覽量
10578
原文標題:大數據相關介紹(24)——機器學習之關聯分析
文章出處:【微信號:行業學習與研究,微信公眾號:行業學習與研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
嵌入式機器學習的應用特性與軟件開發環境
【「具身智能機器人系統」閱讀體驗】+兩本互為支持的書

zeta在機器學習中的應用 zeta的優缺點分析
什么是機器學習?通過機器學習方法能解決哪些問題?

【《時間序列與機器學習》閱讀體驗】+ 時間序列的信息提取
【「時間序列與機器學習」閱讀體驗】+ 鳥瞰這本書
【「時間序列與機器學習」閱讀體驗】+ 簡單建議
【《時間序列與機器學習》閱讀體驗】+ 了解時間序列
【「時間序列與機器學習」閱讀體驗】全書概覽與時間序列概述
機器學習在數據分析中的應用
深度學習與傳統機器學習的對比
名單公布!【書籍評測活動NO.35】如何用「時間序列與機器學習」解鎖未來?
圖機器學習入門:基本概念介紹





 工商網監
工商網監
評論