") 異構(gòu)數(shù)據(jù)庫排序一致性填坑教程
異構(gòu)數(shù)據(jù)庫排序一致性填坑教程
不同數(shù)據(jù)庫對于字符值的排序規(guī)則各不相同,要達(dá)成在不同數(shù)據(jù)庫上對于同樣數(shù)據(jù)集執(zhí)行查詢語句的輸出結(jié)果順序一致性目標(biāo),則必須進(jìn)行相應(yīng)的設(shè)置或改寫,本文通過對五種數(shù)據(jù)庫的分析,對該問題進(jìn)行了較為深入的分析。
01
概述.
在異構(gòu)數(shù)據(jù)庫之間進(jìn)行數(shù)據(jù)遷移之后,為驗(yàn)證數(shù)據(jù)一致性,就需要比對源庫和目標(biāo)庫的同表數(shù)據(jù)是否一致。
為了提高比對效率,一般而言會將數(shù)據(jù)排序并抽取出來后進(jìn)行比對。
在實(shí)際過程中發(fā)現(xiàn),指定了ORDER BY的同樣兩條SQL語句在不同數(shù)據(jù)庫執(zhí)行后,輸出結(jié)果集的順序經(jīng)常會不同,本文關(guān)注該問題的產(chǎn)生并提供了相應(yīng)的解決方案。
02
數(shù)據(jù)準(zhǔn)備.
本文涉及的數(shù)據(jù)庫為:
- Oracle
- MySQL
- Postgres
- Gauss(華為open Gauss)
- GoldiLocks(科藍(lán))
所有的數(shù)據(jù)庫均采用UTF8編碼,且MySQL數(shù)據(jù)庫不區(qū)分大小寫建表。
在各數(shù)據(jù)庫中創(chuàng)建一張測試表LEXSORT,該表僅有一個字符列NAME,具體語句如下:
CREATE TABLE LEXSORT ( NAME VARCHAR(10) );
然后將以下數(shù)據(jù)插入該表中:
INSERT INTO LEXSORT VALUES ('0');
INSERT INTO LEXSORT VALUES ('9');
INSERT INTO LEXSORT VALUES ('a');
INSERT INTO LEXSORT VALUES ('z');
INSERT INTO LEXSORT VALUES ('A');
INSERT INTO LEXSORT VALUES ('Z');
INSERT INTO LEXSORT VALUES ('_');
INSERT INTO LEXSORT VALUES ('~');
INSERT INTO LEXSORT VALUES (NULL);
03
查詢結(jié)果.
在各個數(shù)據(jù)庫中執(zhí)行如下查詢語句:
SELECT * FROM LEXSORT ORDER BY NAME;
其輸出結(jié)果見下圖:
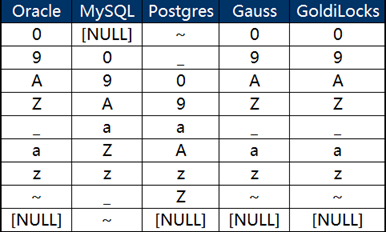
通過上面的結(jié)果可以發(fā)現(xiàn):
其一,Oracle、Gauss和GoldiLocks的缺省排序保持一致,而與MYSQL和Postgres的各不相同。
其二,數(shù)據(jù)排序的不同體現(xiàn)在兩個方面上
- NULL值與非NULL字符值之間的順序
- 非NULL字符值之間的順序
那么,這背后的機(jī)制是什么呢?又該如何解決呢?
04
數(shù)據(jù)庫分析.
其實(shí),產(chǎn)生這一現(xiàn)象的原因是各數(shù)據(jù)庫的缺省排序規(guī)則各不相同所致。要解決這一問題,就需要從各數(shù)據(jù)庫自身出發(fā),了解其排序規(guī)則,并分別進(jìn)行設(shè)置,才可能達(dá)到在不同數(shù)據(jù)庫之間的一致性。
具體如何操作,后文將為您逐一展開。
Oracle數(shù)據(jù)庫
**Oracle數(shù)據(jù)庫提供了控制排序規(guī)則的參數(shù),可以在系統(tǒng)級別和會話級別分別進(jìn)行設(shè)置,一般而言,為了不影響其他應(yīng)用,我們在會話級別進(jìn)行設(shè)置即可。
**
1. NULL值的排序規(guī)則
Oracle支持在ORDER BY字句的每個字段上進(jìn)行控制。可以指定為NULLS FIRST或NULLS LAST,即NULL值排在前面還是后面,缺省為NULLS LAST,即NULL值排在其它非NULL值的后面。
Postgres、Gauss和GoldiLocks也采用了同樣的處理,后文不再贅述。
2. 非NULL值的排序規(guī)則
Oracle提供了控制參數(shù)NLS_SORT來指定排序規(guī)則,缺省的排序規(guī)則為BINARY,即按照字符串中每個字符的編碼值進(jìn)行排序,另一個常用排序規(guī)則為BINARY_CI,即按照二進(jìn)制值進(jìn)行排序,同時字母(A-Z,a-z)不區(qū)分大小寫。
根據(jù)以上規(guī)則重新修改一下SQL語句或會話設(shè)置:
ALTER SESSION SET NLS_SORT=BINARY;
ALTER SESSION SET NLS_SORT=BINARY_CI;
SELECT * FROM LEXSORT ORDER BY NAME NULLS FIRST;
此時不同組合后查詢的輸出結(jié)果見下圖:
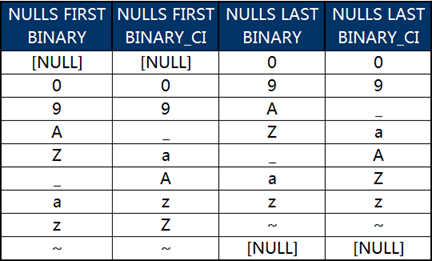
在上圖中我們會注意到,不區(qū)分大小寫排序時字符“_”的位置似乎有些“飄忽不定”。為了解決這個問題,我們把這些字符對應(yīng)的編碼數(shù)值出來看一下:

根據(jù)編碼值就會發(fā)現(xiàn),“飄忽不定”的符號“_”的編碼正好位于大寫字母和小寫字母之間,與它存在同樣情況的還有5個字符。這就意味著,Oracle在采用BINARY_CI方式忽略字母大小寫排序時,會自動將所有的字母視為了小寫字母。
MySQL數(shù)據(jù)庫
MySQL數(shù)據(jù)庫在排序控制方面較弱,首先對于NULL值,MySQL自動視為NULLS FIRST,在ORDER BY字句中無相應(yīng)的控制選項(xiàng)。
再看一下字母的排序,MySQL在建表時可以指定區(qū)分大小寫或不區(qū)分大小寫,一旦指定無法再修改,除非重新建表。
因此對于區(qū)分大小寫的庫,其排序規(guī)則會與Oracle的BINARY規(guī)則保持一致。
那么不區(qū)分大小寫的呢?其實(shí)在前面的截圖中已經(jīng)有了體現(xiàn),不過為了清晰起見,我們將Oracle設(shè)置為NULL FIRST和不區(qū)分大小寫,單獨(dú)拿出來再進(jìn)行一下比較:
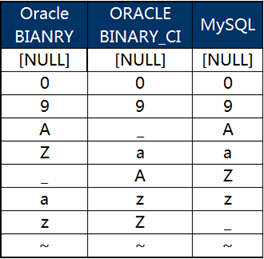
此時我們會發(fā)現(xiàn)Oracle和MySQL的排序依然不一致!發(fā)生問題的依然是那個“飄忽不定”的“_”。
顯然,稍加分析后我們就會知道,在不區(qū)分大小寫的情形下,MySQL自動將所有字母視為了大寫字母進(jìn)行排序,正是因?yàn)檫@個區(qū)別,位于大寫和小寫字母之間的那六個字符又一次給我們?nèi)橇寺闊?/strong>
這樣,不區(qū)分大小寫建表的MySQL數(shù)據(jù)庫與Oracle數(shù)據(jù)庫的排序一致性就不存在完美的解決方案!
Postgres數(shù)據(jù)庫
Postgres數(shù)據(jù)庫的缺省排序?qū)ξ襾碚f一直是個迷……

上圖中,符號排在最前面,而“~”的編碼卻比“_”大,相當(dāng)于降序;然后是數(shù)字和字母,而此時又是升序。鑒于本人對Postgres的研究有限,此處暫不作深究,只專注如何解決排序一致性問題。
Postgres提供了collate語句用以調(diào)整排序規(guī)則。將排序規(guī)則設(shè)置為C(必須用雙引號括起來且為大寫字母)或ucs_basic(如果用雙引號括起則必須為小寫)則代表按照字符編碼排序,此時會區(qū)分大小寫。
不區(qū)分大小寫且又要按照編碼值進(jìn)行排序,目前暫未找到合適的方法。
需要注意指定collate和null first時的SQL語句順序問題,當(dāng)二者都需指定時示例語句如下,具體的輸出結(jié)果大家可以自行測試:
SELECT * FROM LEXSORT ORDER BY NAME COLLATE ucs_basic NULLS FIRST;
Gauss數(shù)據(jù)庫
大家都知道Open Gauss實(shí)際上是基于Postgres進(jìn)行的定制,它在增加部分功能的同時也刪減了部分Postgres的功能。不過對于ORDER BY子句,Gauss依然保留了Postgres的能力,也就是說collate子句同樣適用于Gauss數(shù)據(jù)庫,不過Gauss數(shù)據(jù)庫的缺省排序規(guī)則即為按照字符編碼值進(jìn)行排序。
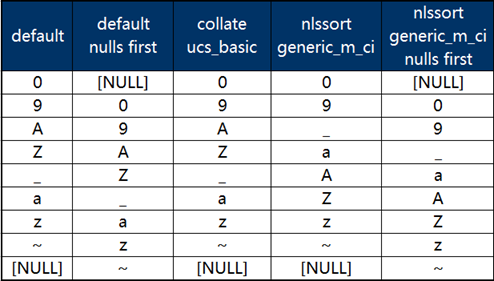
同時,Gauss數(shù)據(jù)庫提供了排序函數(shù)NLSSORT,解決了不區(qū)分大小排序的問題,此時其排序結(jié)果與Oracle保持一致。使用該函數(shù)時需指定排序規(guī)則,不區(qū)分大小寫的規(guī)則為generic_m_ci,具體SQL示例語句如下:
SELECT * FROM LEXSORT ORDER BY NLSSORT(NAME,'nls_sort=generic_m_ci');
SELECT * FROM LEXSORT ORDER BY NLSSORT(NAME,'nls_sort=generic_m_ci') NULLS FIRST;
幾種不同組合的查詢結(jié)果見下圖(未寫明null first時均為nulls last):
****GoldiLocks數(shù)據(jù)庫 ****
該數(shù)據(jù)庫除了NULLS FIRST/LAST處理與Oracle保持一致外,并沒有可以修改排序規(guī)則的參數(shù),不過其缺省的排序規(guī)則即為按照字符編碼值進(jìn)行排序。因此在排序一致性方面依然可以與Oracle、Postgres、Gauss做到很好的兼容。
05
總結(jié).
雖然本文起源于數(shù)據(jù)比對場景,不過通過上面的分析,我們可以意識到,排序一致性問題也是異構(gòu)數(shù)據(jù)庫遷移時必須考慮的問題之一。試想一下,如果不做SQL語句改造,原有的業(yè)務(wù)查詢語句在新數(shù)據(jù)庫中結(jié)果集排序可能會發(fā)生變化,進(jìn)而導(dǎo)致后續(xù)處理結(jié)果也可能發(fā)生變化。
通過分析我們也發(fā)現(xiàn),大多數(shù)數(shù)據(jù)庫的排序一致性可以通過設(shè)置會話參數(shù)或修改SQL語句等來實(shí)現(xiàn)保持不變,不過部分?jǐn)?shù)據(jù)庫,例如本例中的MySQL,卻缺乏完美的解決方案,那么我們就必須要分析其影響并進(jìn)行應(yīng)對。
-
數(shù)據(jù)庫
+關(guān)注
關(guān)注
7文章
3846瀏覽量
64685 -
Oracle
+關(guān)注
關(guān)注
2文章
296瀏覽量
35234 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1209瀏覽量
24833
發(fā)布評論請先 登錄
相關(guān)推薦
如何解決數(shù)據(jù)庫與緩存一致性

一致性規(guī)劃研究
加速器一致性接口
速度不可測的異構(gòu)多智能體系統(tǒng)一致性分析
時延異構(gòu)多自主體系統(tǒng)的群一致性分析
分布式大數(shù)據(jù)不一致性檢測
優(yōu)化模型的乘性偏好關(guān)系一致性改進(jìn)
緩存與數(shù)據(jù)庫一致性問題如何解決
什么是數(shù)據(jù)庫營銷
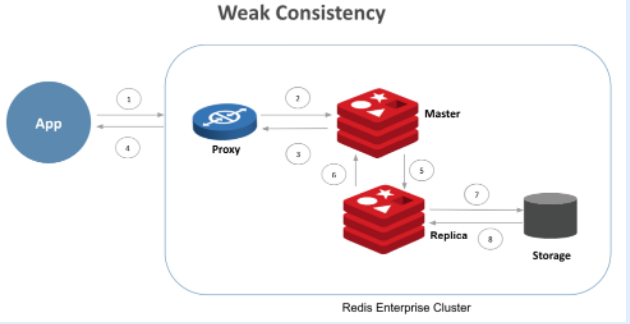
虹科干貨 | 什么是數(shù)據(jù)庫一致性?
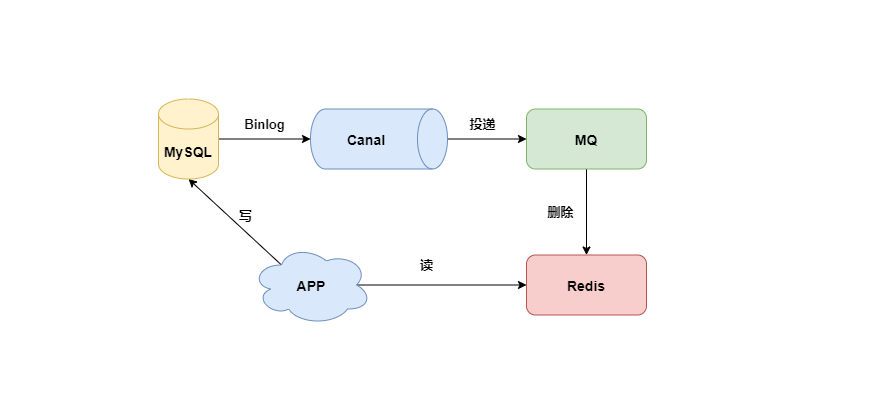
Redis緩存與Mysql如何保證一致性?

DDR一致性測試的操作步驟
深入理解數(shù)據(jù)備份的關(guān)鍵原則:應(yīng)用一致性與崩潰一致性的區(qū)別

異構(gòu)計(jì)算下緩存一致性的重要性





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論