 【嵌入式AI簡報20230414】黑芝麻智能7nm中央計算芯片正式發布、微軟開源“傻瓜式”類ChatGPT模型訓練工具
【嵌入式AI簡報20230414】黑芝麻智能7nm中央計算芯片正式發布、微軟開源“傻瓜式”類ChatGPT模型訓練工具
嵌入式 AI
AI 簡報 20230414 期
1. 黑芝麻智能7nm中央計算芯片正式發布,單芯片實現智能汽車跨域融合
原文:https://mp.weixin.qq.com/s/s-oDcsvKmwDx81E8LL1quw
在智能網聯概念的推動下,智能汽車的發展已經從域控逐漸過渡到域融合,并繼續向著中央集成去邁進。架構的變化對作為系統核心的計算芯片也提出了新的要求,為了幫助汽車產業更好地應對未來的智能汽車需求,在4月7日舉辦的“芯所向 至未來 BEST TECH Day 2023”黑芝麻智能戰略發布暨生態合作伙伴大會上,該公司正式發布首個車規級跨域計算平臺——武當系列,以及系列中首款產品C1200芯片。
武當系列面向架構創新
當前,汽車行業的發展可以說是日新月異,正在經歷前所未有之大變局,機會迎面而來,而機會也稍縱即逝。黑芝麻智能創始人兼CEO單記章表示,黑芝麻智能要做改變人類出行方式的芯片,用人工智能、感知技術、核心芯片去改變汽車行業。

“經過長達24個月的艱苦研發,我們向行業正式推出黑芝麻智能全新的產品線——武當系列,主打跨域計算。”他在介紹中提到,“目前,行業對于L3及以下級別自動駕駛的算力需求比較清晰,黑芝麻智能A1000芯片已經能夠很好地支持前融合BEV算法。面向未來,華山系列仍將繼續探索更高級別自動駕駛對算力的清晰需求,而武當系列則關注跨域融合向中央計算架構的轉變,通過架構創新,提升智能汽車的整體性能。”
黑芝麻智能產品副總裁丁丁在會上對武當系列和C1200進行了全面的介紹。他談到,智車時代,汽車行業將會有四大新需求,分別是架構創新、算力綜合、車規安全和平臺化方案。那么,作為智車時代的車載計算方案,就需要能夠支持七大類算力需求,依次是通用邏輯、圖形渲染、音頻音效、數學計算、實時控制、人工智能和數據處理。
為了解決未來的行業需求和算力需求,黑芝麻智能的武當系列芯片具有四大典型優勢——新、準、強、高。
“新”是指創新的架構融合。武當系列通過異構隔離技術,把不同算力根據不同場景,以及不同規格和安全要求,進行搭配組合,能夠支撐汽車電子電氣架構的靈活發展,支持雙腦、艙駕、中央計算等各種架構方案。
“準”是指準確的市場定位。如上所述,黑芝麻智能武當系列精準服務于海量的L2+級別融合計算市場,通過單芯片支持跨域融合的方式,力求在這一市場給下游客戶帶來高賦能價值、成本最優、系統最優的解決方案。
“強”是指強大的家族化平臺。武當系列基于當前行業最先進的平臺架構,其中C1200選擇的是7nm工藝,領先的工藝保證了芯片的算力、功耗、成本能夠達到更好的平衡。同時,黑芝麻智能在軟硬件結合上提供SDK配套方案,滿足客戶各場景需求,節省開發時間,以及后續的長期維護代價。因此,黑芝麻智能不僅芯片是家族化規劃,軟件平臺同樣如此,確保了客戶軟件資產能夠得到最好的繼承。
“高”是指滿足最高車規要求。丁丁在介紹時指出,黑芝麻智能三代車規級芯片,每一代都一次性流片成功,持續為客戶提供高可靠性+高功能性安全+高信息安全的方案體驗。武當系列在上一代芯片平臺的基礎上進一步優化了設計,可提供行業最高標準的Safety和Security能力。
智能汽車跨域計算平臺C1200
C1200是武當系列的首款產品,基于7nm計算平臺,內部搭載支持鎖步的車規級高性能CPU 核A78AE(性能高達150KDMIPS),和車規級高性能GPU核G78AE,提供強大的通用計算和通用渲染算力。C1200提供豐富的片上資源,包括黑芝麻智能自研DynamAI NN車規級低功耗神經網絡加速引擎,新一代自研多功能NeuralIQ ISP模塊,高性能HIFI DSP,支持多組鎖步的MCU算力,支持17MP高清攝像頭的MIPI等。

并且,丁丁強調,C1200還提供豐富的接口資源,比如支持處理多路CAN數據的接入和轉發,支持以太網接口并支持所有常用的顯示接口格式,支持雙通道的LPDDR5內存,等等。
在異構隔離技術的賦能下,黑芝麻智能C1200芯片開創性地實現了硬隔離獨立計算子系統,獨立渲染,獨立顯示,滿足儀表控制屏的高安全性和快速啟動的要求。同時,該子系統也可以靈活應用于自動駕駛、HUD抬頭顯示等需要獨立系統的計算場景。
當然,C1200芯片領先行業的安全性也需要特別指出。該芯片內置支持ASIL-D等級的Safety Island和國密二級和EVITA full的Security模塊,并滿足車規安全等級最高的可靠性要求。
基于這些領先性能,C1200單芯片支持跨域計算多種場景,包括CMS(電子后視鏡)系統、行泊一體、智能大燈、整車計算、信息娛樂系統、智能座艙、艙內感知系統等。
綜上所述,黑芝麻智能C1200將在跨域融合方面帶來極致的性價比。丁丁指出,目前基于C1200的原型機已經準備就緒,將在2023年內提供樣片。

黑芝麻智能定位全面升級
除了C1200單芯片支持智能汽車跨域融合以外,黑芝麻智能也是行業內首個提出單芯片支持行泊一體方案的公司。幾天前,該公司剛剛宣布實現能夠實現支持10V(攝像頭)NOA功能的行泊一體域控制器BOM成本控制在3000元人民幣以內,支持50-100T物理算力。
單記章指出,2023年汽車行業面臨著非常大的降價壓力,成本壓力也會傳導到上游的供應鏈。在自動駕駛方案上,合理的算力+高性能+高性價比將成為市場主流。50T左右的物理算力能夠支持L2+、L2++級別的自動駕駛已經成為市場的標準配置。
同時,會場外也展示出了基于黑芝麻智能芯片的豐富方案,來自該公司自己以及行業合作伙伴。這些具有顛覆性創新方案的背后是黑芝麻智能企業定位的升級。單記章表示,黑芝麻智能已經從“自動駕駛計算芯片的引領者”升級為“智能汽車計算芯片的引領者”。
他在演講中提到黑芝麻智能戰略定位的三步走計劃:
-
第一步:聚焦自動駕駛計算芯片及解決方案,實現產品的商業化落地,形成完整的技術閉環;
-
第二步:根據汽車電子電氣架構的發展趨勢,拓展產品線覆蓋到車內更多的計算節點,形成多產線的組合;
-
第三步:不斷擴充產品線覆蓋更多汽車的需求,為客戶提供基于我們芯片的多種汽車軟硬件解決方案。
單記章在會上呼吁:“中國市場已經開始逐漸走出一條屬于自己的自動駕駛技術路線,我們歡迎友商和合作伙伴光明正大地競爭和合作,這樣中國自動駕駛行業才能夠良性發展。”
后記
大會上,黑芝麻智能還發布了“華山開發者計劃”,并邀請到來自長安汽車、東風汽車和億咖通等公司的頂級行業專家進行技術分享。可以看出,伴隨著黑芝麻智能企業定位的升級,不僅是軟硬件方面會更加豐富,生態同樣在日益壯大。在堅持顛覆式創新之路上,黑芝麻智能路越走越遠,路也越走越寬。
2. 無需寫代碼能力,手搓最簡單BabyGPT模型:前特斯拉AI總監新作
原文:https://mp.weixin.qq.com/s/BBRBjH-y4hG8AoN2SfMyrw
我們知道,OpenAI 的 GPT 系列通過大規模和預訓練的方式打開了人工智能的新時代,然而對于大多數研究者來說,語言大模型(LLM)因為體量和算力需求而顯得高不可攀。在技術向上發展的同時,人們也一直在探索「最簡」的 GPT 模式。
近日,特斯拉前 AI 總監,剛剛回歸 OpenAI 的 Andrej Karpathy 介紹了一種最簡 GPT 的玩法,或許能為更多人了解這種流行 AI 模型背后的技術帶來幫助。
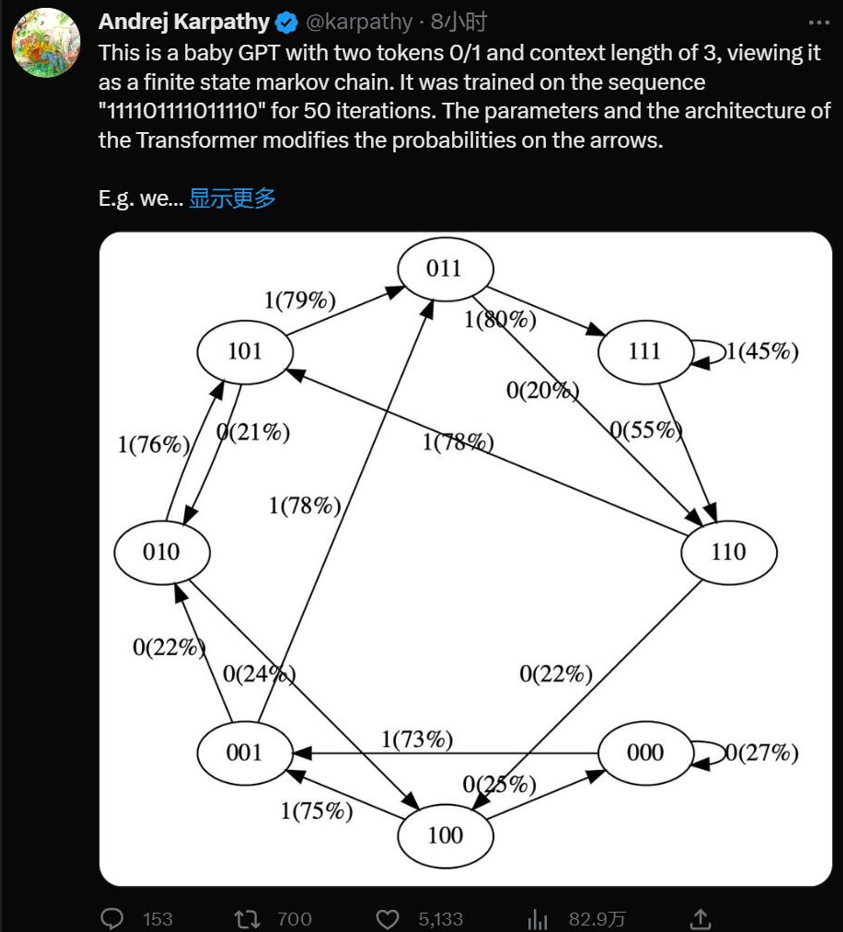
是的,這是一個帶有兩個 token 0/1 和上下文長度為 3 的極簡 GPT,將其視為有限狀態馬爾可夫鏈。它在序列「111101111011110」上訓練了 50 次迭代,Transformer 的參數和架構修改了箭頭上的概率。
例如我們可以看到:
-
在訓練數據中,狀態 101 確定性地轉換為 011,因此該轉換的概率變得更高 (79%)。但不接近于 100%,因為這里只做了 50 步優化。
-
狀態 111 以 50% 的概率分別進入 111 和 110,模型幾乎已學會了(45%、55%)。
-
在訓練期間從未遇到過像 000 這樣的狀態,但具有相對尖銳的轉換概率,例如 73% 轉到 001。這是 Transformer 歸納偏差的結果。你可能會想這是 50%,除了在實際部署中幾乎每個輸入序列都是唯一的,而不是逐字地出現在訓練數據中。
通過簡化,Karpathy 已讓 GPT 模型變得易于可視化,讓你可以直觀地了解整個系統。
你可以在這里嘗試它:
https://colab.research.google.com/drive/1SiF0KZJp75rUeetKOWqpsA8clmHP6jMg?usp=sharing
實際上,即使是 GPT 的最初版本,模型的體量很相當可觀:在 2018 年,OpenAI 發布了第一代 GPT 模型,從論文《Improving Language Understanding by Generative Pre-Training》可以了解到,其采用了 12 層的 Transformer Decoder 結構,使用約 5GB 無監督文本數據進行訓練。
但如果將其概念簡化,GPT 是一種神經網絡,它采用一些離散 token 序列并預測序列中下一個 token 的概率。例如,如果只有兩個標記 0 和 1,那么一個很小的二進制 GPT 可以例如告訴我們:
1[0,1,0]--->GPT--->[P(0)=20%,P(1)=80%]
在這里,GPT 采用位序列 [0,1,0],并根據當前的參數設置,預測下一個為 1 的可能性為 80%。重要的是,默認情況下 GPT 的上下文長度是有限的。如果上下文長度為 3,那么它們在輸入時最多只能使用 3 個 token。在上面的例子中,如果我們拋出一枚有偏差的硬幣并采樣 1 確實應該是下一個,那么我們將從原始狀態 [0,1,0] 轉換到新狀態 [1,0,1]。我們在右側添加了新位 (1),并通過丟棄最左邊的位 (0) 將序列截斷為上下文長度 3,然后可以一遍又一遍地重復這個過程以在狀態之間轉換。
很明顯,GPT 是一個有限狀態馬爾可夫鏈:有一組有限的狀態和它們之間的概率轉移箭頭。每個狀態都由 GPT 輸入處 token 的特定設置定義(例如 [0,1,0])。我們可以以一定的概率將其轉換到新狀態,如 [1,0,1]。讓我們詳細看看它是如何工作的:
1#hyperparametersforourGPT#vocabsizeis2,soweonlyhavetwopossibletokens:0,1vocab_size=2#contextlengthis3,sowetake3bitstopredictthenextbitprobabilitycontext_length=3
GPT 神經網絡的輸入是長度為 context_length 的 token 序列。這些 token 是離散的,因此狀態空間很簡單:
1print('statespace(forthisexercise)=',vocab_size**context_length)#statespace(forthisexercise)=8
細節:準確來說,GPT 可以采用從 1 到 context_length 的任意數量的 token。因此如果上下文長度為 3,原則上我們可以在嘗試預測下一個 token 時輸入 1 個、2 個或 3 個 token。這里我們忽略這一點并假設上下文長度已「最大化」,只是為了簡化下面的一些代碼,但這一點值得牢記。
1print('actualstatespace(inreality)=',sum(vocab_size**iforiinrange(1,context_length+1)))#actualstatespace(inreality)=14
我們現在要在 PyTorch 中定義一個 GPT。出于本筆記本的目的,你無需理解任何此代碼。
現在讓我們構建 GPT 吧:
1config=GPTConfig(block_size=context_length,vocab_size=vocab_size,n_layer=4,n_head=4,n_embd=16,bias=False,)gpt=GPT(config)
對于這個筆記本你不必擔心 n_layer、n_head、n_embd、bias,這些只是實現 GPT 的 Transformer 神經網絡的一些超參數。
GPT 的參數(12656 個)是隨機初始化的,它們參數化了狀態之間的轉移概率。如果你平滑地更改這些參數,就會平滑地影響狀態之間的轉換概率。
現在讓我們試一試隨機初始化的 GPT。讓我們獲取上下文長度為 3 的小型二進制 GPT 的所有可能輸入:
1defall_possible(n,k):#returnallpossiblelistsofkelements,eachinrangeof[0,n)ifk==0:yield[]else:foriinrange(n):forcinall_possible(n,k-1):yield[i]+clist(all_possible(vocab_size,context_length))
2
1[[0,0,0],[0,0,1],[0,1,0],[0,1,1],[1,0,0],[1,0,1],[1,1,0],[1,1,1]]
這是 GPT 可能處于的 8 種可能狀態。讓我們對這些可能的標記序列中的每一個運行 GPT,并獲取序列中下一個標記的概率,并繪制為可視化程度比較高的圖形:
1#we'llusegraphvizforprettyplottingthecurrentstateoftheGPTfromgraphvizimportDigraph
2
3defplot_model():dot=Digraph(comment='BabyGPT',engine='circo')
4
5forxiinall_possible(gpt.config.vocab_size,gpt.config.block_size):
6#forwardtheGPTandgetprobabilitiesfornexttokenx=torch.tensor(xi,dtype=torch.long)[None,...]#turnthelistintoatorchtensorandaddabatchdimensionlogits=gpt(x)#forwardthegptneuralnetprobs=nn.functional.softmax(logits,dim=-1)#gettheprobabilitiesy=probs[0].tolist()#removethebatchdimensionandunpackthetensorintosimplelistprint(f"input{xi}--->{y}")
7
8#alsobuildupthetransitiongraphforplottinglatercurrent_node_signature="".join(str(d)fordinxi)dot.node(current_node_signature)fortinrange(gpt.config.vocab_size):next_node=xi[1:]+[t]#cropthecontextandappendthenextcharacternext_node_signature="".join(str(d)fordinnext_node)p=y[t]label=f"{t}({p*100:.0f}%)"dot.edge(current_node_signature,next_node_signature,label=label)
9returndot
10
11plot_model()
1input[0,0,0]--->[0.4963349997997284,0.5036649107933044]input[0,0,1]--->[0.4515703618526459,0.5484296679496765]input[0,1,0]--->[0.49648362398147583,0.5035163760185242]input[0,1,1]--->[0.45181113481521606,0.5481888651847839]input[1,0,0]--->[0.4961162209510803,0.5038837194442749]input[1,0,1]--->[0.4517717957496643,0.5482282042503357]input[1,1,0]--->[0.4962802827358246,0.5037197470664978]input[1,1,1]--->[0.4520467519760132,0.5479532480239868]
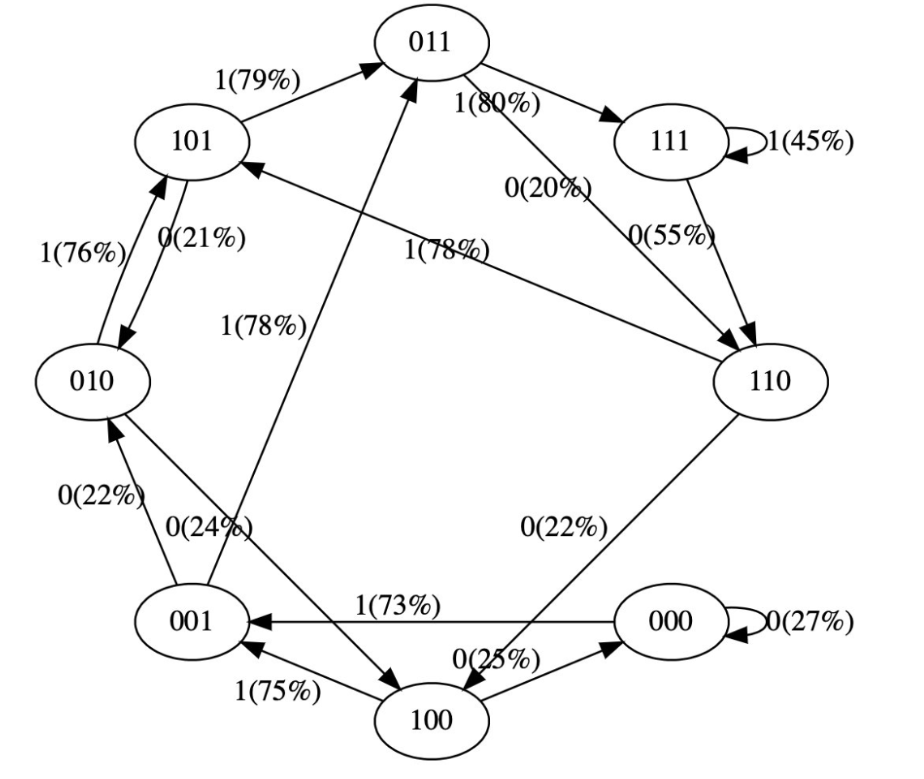
我們看到了 8 個狀態,以及連接它們的概率箭頭。因為有 2 個可能的標記,所以每個節點有 2 個可能的箭頭。請注意,在初始化時,這些概率中的大多數都是統一的(在本例中為 50%),這很好而且很理想,因為我們甚至根本沒有訓練模型。
下面開始訓練:
1#let'strainourbabyGPTonthissequenceseq=list(map(int,"111101111011110"))seq
1[1,1,1,1,0,1,1,1,1,0,1,1,1,1,0]
1#convertthesequencetoatensorholdingalltheindividualexamplesinthatsequenceX,Y=[],[]#iterateoverthesequenceandgrabeveryconsecutive3bits#thecorrectlabelforwhat'snextisthenextbitateachpositionforiinrange(len(seq)-context_length):X.append(seq[i:i+context_length])Y.append(seq[i+context_length])print(f"example{i+1:2d}:{X[-1]}-->{Y[-1]}")X=torch.tensor(X,dtype=torch.long)Y=torch.tensor(Y,dtype=torch.long)print(X.shape,Y.shape)
我們可以看到在那個序列中有 12 個示例。現在讓我們訓練它:
1#initaGPTandtheoptimizertorch.manual_seed(1337)gpt=GPT(config)optimizer=torch.optim.AdamW(gpt.parameters(),lr=1e-3,weight_decay=1e-1)
1#traintheGPTforsomenumberofiterationsforiinrange(50):logits=gpt(X)loss=F.cross_entropy(logits,Y)loss.backward()optimizer.step()optimizer.zero_grad()print(i,loss.item())
1print("Trainingdatasequence,asareminder:",seq)plot_model()我們沒有得到這些箭頭的準確 100% 或 50% 的概率,因為網絡沒有經過充分訓練,但如果繼續訓練,你會期望接近。
請注意一些其他有趣的事情:一些從未出現在訓練數據中的狀態(例如 000 或 100)對于接下來應該出現的 token 有很大的概率。如果在訓練期間從未遇到過這些狀態,它們的出站箭頭不應該是 50% 左右嗎?這看起來是個錯誤,但實際上是可取的,因為在部署期間的真實應用場景中,幾乎每個 GPT 的測試輸入都是訓練期間從未見過的輸入。我們依靠 GPT 的內部結構(及其「歸納偏差」)來適當地執行泛化。
大小比較:
-
GPT-2 有 50257 個 token 和 2048 個 token 的上下文長度。所以 `log2 (50,257) * 2048 = 每個狀態 31,984 位 = 3,998 kB。這足以實現量變。
-
GPT-3 的上下文長度為 4096,因此需要 8kB 的內存;大約相當于 Atari 800。
-
GPT-4 最多 32K 個 token,所以大約 64kB,即 Commodore64。
-
I/O 設備:一旦開始包含連接到外部世界的輸入設備,所有有限狀態機分析就會崩潰。在 GPT 領域,這將是任何一種外部工具的使用,例如必應搜索能夠運行檢索查詢以獲取外部信息并將其合并為輸入。
Andrej Karpathy 是 OpenAI 的創始成員和研究科學家。但在 OpenAI 成立一年多后,Karpathy 便接受了馬斯克的邀請,加入了特斯拉。在特斯拉工作的五年里,他一手促成了 Autopilot 的開發。這項技術對于特斯拉的完全自動駕駛系統 FSD 至關重要,也是馬斯克針對 Model S、Cybertruck 等車型的賣點之一。
今年 2 月,在 ChatGPT 火熱的背景下,Karpathy 回歸 OpenAI,立志構建現實世界的 JARVIS 系統。
英偉達人工智能科學家 Jim Fan 表示:「對于 Meta 的這項研究,我認為是計算機視覺領域的 GPT-3 時刻之一。它已經了解了物體的一般概念,即使對于未知對象、不熟悉的場景(例如水下圖像)和模棱兩可的情況下也能進行很好的圖像分割。最重要的是,模型和數據都是開源的。恕我直言,Segment-Anything 已經把所有事情(分割)都做的很好了。」
3. CV開啟大模型時代!谷歌發布史上最大ViT:220億參數,視覺感知力直逼人類
原文:https://mp.weixin.qq.com/s/lWgA5JiBhUYAzeGvgqE_mg
Transformer無疑是促進自然語言處理領域繁榮的最大功臣,也是GPT-4等大規模語言模型的基礎架構。
不過相比語言模型動輒成千上萬億的參數量,計算機視覺領域吃到Transformer的紅利就沒那么多了,目前最大的視覺Transformer模型ViT-e的參數量還只有40億參數。
最近谷歌發布了一篇論文,研究人員提出了一種能夠高效且穩定訓練大規模Vision Transformers(ViT)模型的方法,成功將ViT的參數量提升到220億。

論文鏈接:https://arxiv.org/abs/2302.05442
為了實現模型的擴展,ViT-22B結合了其他語言模型(如PaLM模型)的思路,使用 QK 歸一化改進了訓練穩定性,提出了一種異步并行線性操作(asynchronous parallel linear operations) 的新方法提升訓練效率,并且能夠在硬件效率更高的Cloud TPU上進行訓練。
在對ViT-22B模型進行實驗以評估下游任務性能時,ViT-22B也表現出類似大規模語言模型的能力,即隨著模型規模的擴大,性能也在不斷提升。
ViT-22B 還可以應用于PaLM-e中,與語言模型結合后的大模型可以顯著提升機器人任務的技術水平。
研究人員還進一步觀察到規模帶來的其他優勢,包括更好地平衡公平性和性能,在形狀/紋理偏見方面與人類視覺感知的一致性,以及更好的穩健性。
模型架構
ViT-22B 是一個基于Transformer架構的模型,和原版ViT架構相比,研究人員主要做了三處修改以提升訓練效率和訓練穩定性。
并行層(parallel layers)
ViT-22B并行執行注意力塊和MLP塊,而在原版Transformer中為順序執行。
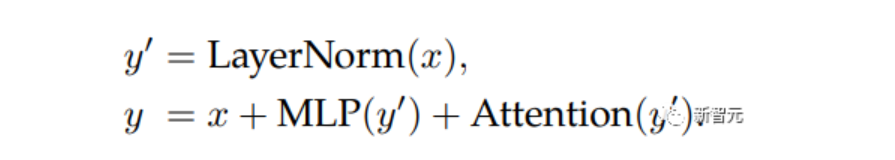
PaLM模型的訓練也采用了這種方法,可以將大模型的訓練速度提高15%,并且性能沒有下降。
query/key (QK) normalization
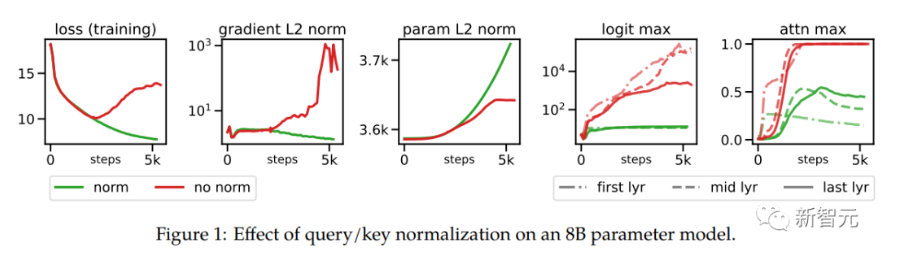
在擴展ViT的過程中,研究人員在80億參數量的模型中觀察到,在訓練幾千步之后訓練損失開始發散(divergence),主要是由于注意力logits的數值過大引起的不穩定性,導致零熵的注意力權重(幾乎one-hot)。
為了解決這個問題,研究人員在點乘注意力計算之前對Query和Key使用LayerNorm
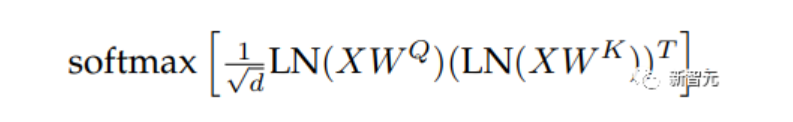
在80億參數模型上的實驗結果如下圖所示,歸一化可以緩解發散問題。
刪除QKV投影和LayerNorms上的偏置項
和PaLM模型一樣,ViT-22B從QKV投影中刪除了偏置項,并且在所有LayerNorms中都沒有偏置項(bias)和centering,使得硬件利用率提高了3%,并且質量沒有下降。
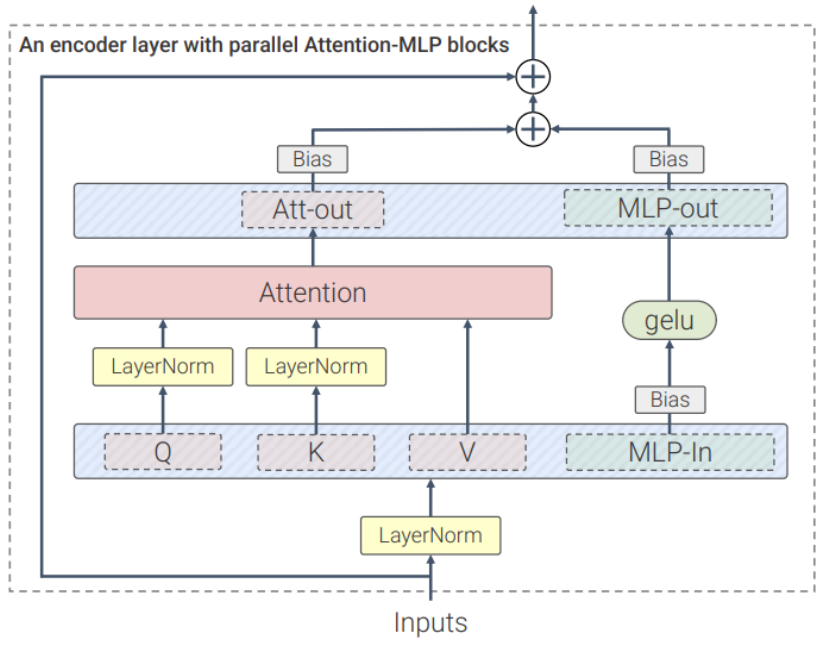
不過與PaLM不同的是,ViT-22B對(內部和外部)MLP稠密連接層使用了偏置項,可以觀察到質量得到了改善,并且速度也沒有下降。
ViT-22B的編碼器模塊中,嵌入層,包括抽取patches、線性投影和額外的位置嵌入都與原始ViT中使用的相同,并且使用多頭注意力pooling來聚合每個頭中的per-token表征。
ViT-22B的patch尺寸為14×14,圖像的分辨率為224×224(通過inception crop和隨機水平翻轉進行預處理)。
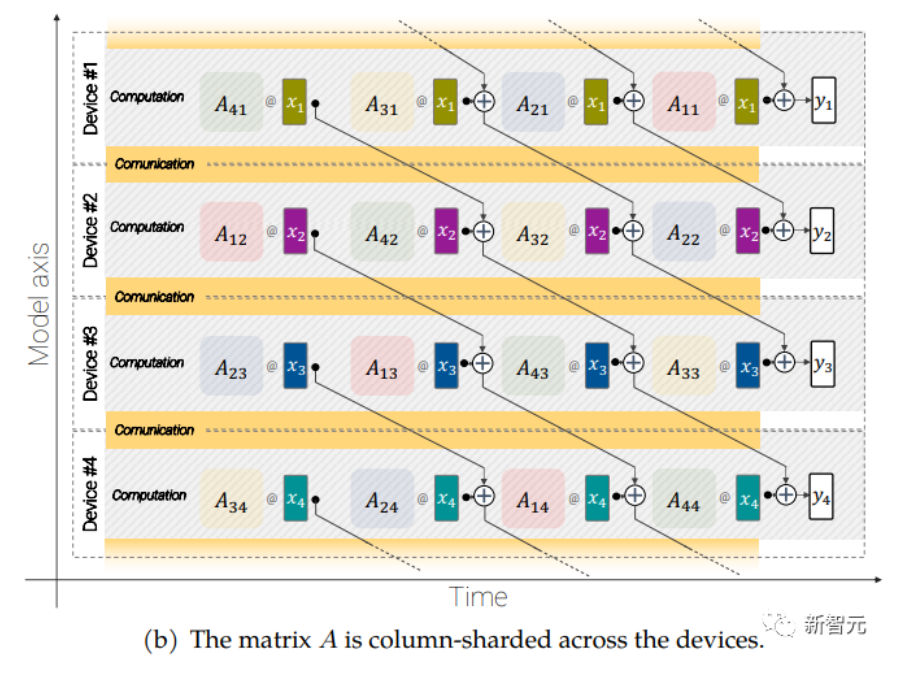
異步并聯線性運算(asynchronous parallel linear operations)
大規模的模型還需要分片(sharding),即將模型參數分布在不同的計算設備中,除此之外,研究人員還把激活(acctivations,輸入的中間表征)也進行分片。
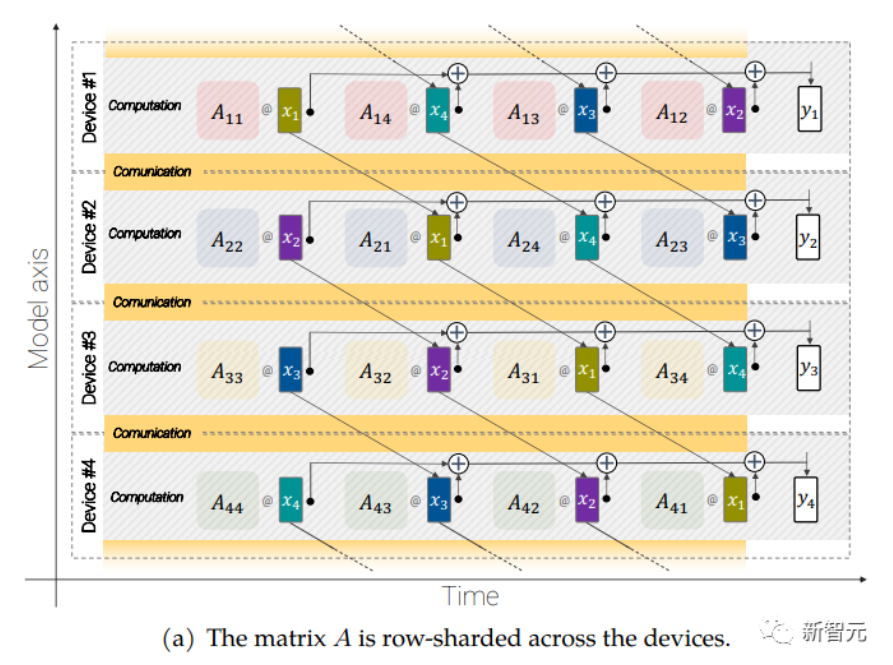
因為輸入和矩陣本身都是分布在各種設備上的,即使是像矩陣乘法這樣簡單的操作也需要特別小心。
研究人員開發了一種稱為異步并行線性運算的方法,可以在矩陣乘法單元(在TPU 中占據絕大多數計算能力的單元)中計算時,同時對設備之間的激活和權值進行通信。
異步方法最小化了等待傳入通信的時間,從而提高了設備效率。
異步并行線性運算的目標是計算矩陣乘法 y = Ax,但矩陣 A 和激活 x 都分布在不同的設備上,需要通過跨設備的重疊通信和計算來實現這一點。矩陣 A 在設備之間進行列分片(column-shard),每個矩陣包含一個連續的切片,每個塊表示為 Aij,更多細節請看原始論文。
實驗結果
為了說明ViT-22B學習到的表征非常豐富,研究人員使用LiT-tuning訓練一個文本模型來生成一些表征用來對齊文本和圖像。
下面是用Parti 和 Imagen 生成的分布外(out-of-distribution)圖像得到的實驗結果,可以看到ViT-22B的zero-shot圖像分類泛化能力非常強,僅從web上爬取的自然圖像就能識別出沒見過的物體和場景。
論文中還討論了ViT-22B在視頻分類、深度估計和語義分割任務上的效果。
結論
研究人員提出了一個目前最大的視覺Transformer模型 ViT-22B,包含220億參數。
通過對原始模型架構進行微小但關鍵的修改后,實現了更高的硬件利用率和訓練穩定性,從而得到了一個在幾個基準測試上提高了模型的上限性能。
使用凍結模型生成嵌入,只需要在頂部訓練幾層,即可獲得很好的性能,并且評估結果進一步表明,與現有模型相比,ViT-22B 在形狀和紋理偏差方面顯示出與人類視知覺更多的相似性,并且在公平性和穩健性方面提供了優勢。
4. 計算機視覺中的圖像標注工具總結
原文:https://mp.weixin.qq.com/s/ggxVzo4pEjRP5Jn0zzb0Fg
labelme
地址:https://github.com/wkentaro/labelme
你可以用它做什么
labelme 是一個基于 python 的開源圖像多邊形標注工具,可用于手動標注圖像以進行對象檢測、分割和分類。它是在線 LabelMe 的離線分支,最近關閉了新用戶注冊選項。所以,在這篇文章中,我們只考慮 labelme(小寫)。
該工具是具有直觀用戶界面的輕量級圖形應用程序。使用 labelme,您可以創建:多邊形、矩形、圓、線、點或線帶。通常,能夠以眾所周知的格式(例如 COCO、YOLO 或 PASCAL VOL)導出注釋以供后續使用通常很方便。但是,在 labelme 中,標簽只能直接從應用程序保存為 JSON 文件。如果要使用其他格式,可以使用 labelme 存儲庫中的 Python 腳本將注釋轉換為 PASCAL VOL。盡管如此,它還是一個相當可靠的應用程序,具有用于手動圖像標記和廣泛的計算機視覺任務的簡單功能。
安裝和配置
labelme 是一個跨平臺的應用程序,可以在多個系統上工作,例如 Windows、Ubuntu 或 macOS。安裝本身非常簡單,這里有很好的描述。例如,在 macOS 上,您需要在終端中運行以下命令:
-
安裝依賴:brew install pyqt
-
安裝labelme:pip install labelme
-
運行 labelme:labelme
labelImg
地址:https://github.com/tzutalin/labelImg
你可以用它做什么
labelImg 是一種廣泛使用的開源圖形注釋工具。它僅適用于目標定位或檢測任務,并且只能在考慮的對象周圍創建矩形框。盡管存在這種限制,我們還是建議使用此工具,因為該應用程序僅專注于創建盡可能簡化工具的邊界框。對于此任務,labelImg 具有所有必要的功能和方便的鍵盤快捷鍵。另一個優點是您可以以 3 種流行的注釋格式保存/加載注釋:PASCAL VOC、YOLO 和 CreateML。
安裝和配置
這里對安裝進行了很好的描述。還要注意 labelImg 是一個跨平臺的應用程序。例如,對于 MacOS,需要在命令行上執行以下操作:
-
安裝依賴:先 brew install qt,然后 brew install libxml2
-
選擇要安裝的文件夾的位置。
-
當你在文件夾中時,運行以下命令:git clone https://github.com/tzutalin/labelImg.git, cd labelImg 然后 make qt5py3
-
運行 labelImg:python3 labelImg.py
-
開發人員強烈建議使用 Python 3 或更高版本和 PyQt5。
CVAT
地址:https://github.com/openvinotoolkit/cvat
你可以用它做什么
CVAT 是一種用于圖像和視頻的開源注釋工具,用于對象檢測、分割和分類等任務。要使用此工具,您無需在計算機上安裝該應用程序。可以在線使用此工具的網絡版本。您可以作為一個團隊協作處理標記圖像并在用戶之間分配工作。還有一個很好的選擇,它允許您使用預先訓練的模型來自動標記您的數據,如果您使用 CVAT 儀表板中現有的可用模型,這可以簡化最流行的類(例如,COCO 中包含的類)的過程。或者,您也可以使用自己的預訓練模型。CVAT 具有我們已經考慮過的工具中最廣泛的功能集。特別是,它允許您以大約 15 種不同的格式保存標簽。可以在此處找到完整的格式列表。
hasty.ai
地址:https://hasty.ai/
你可以用它做什么
與上述所有工具不同,hasty.ai 不是免費的開源服務,但由于所謂的對象檢測和分割的 AI 助手,它非常方便地標記數據。自動支持允許您顯著加快注釋過程,因為在標記期間輔助模型正在訓練。換句話說,標記的圖像越多,助手的工作就越準確。我們將在下面看一個例子來說明它是如何工作的。
您也可以免費試用此服務。該試驗提供 3000 積分,足以為一個物體檢測任務自動生成大約 3000 個物體的建議標簽。
hasty.ai 允許您以 COCO 或 Pascal VOC 格式導出數據。您還可以作為一個團隊處理單個項目并在項目設置中分配角色。
免費積分用完后,hasty.ai 仍然可以免費使用,但標記將完全由手動操作。在這種情況下,最好考慮上述免費工具。
配置
-
要使用該工具,您需要在 hasty.ai 上注冊。
-
登錄您的帳戶。
-
單擊創建新項目。
-
用名稱和描述填寫表單并導航到項目設置,您可以在其中定義考慮中的類,為該項目添加數據。
-
此外,您可以添加其他用戶來共同處理項目。積分將從共享項目的用戶的帳戶中使用。
5. 微軟開源“傻瓜式”類ChatGPT模型訓練工具,成本大大降低,速度提升15倍
原文:https://mp.weixin.qq.com/s/t3HA4Hu61LLDC3h2Njmo_Q
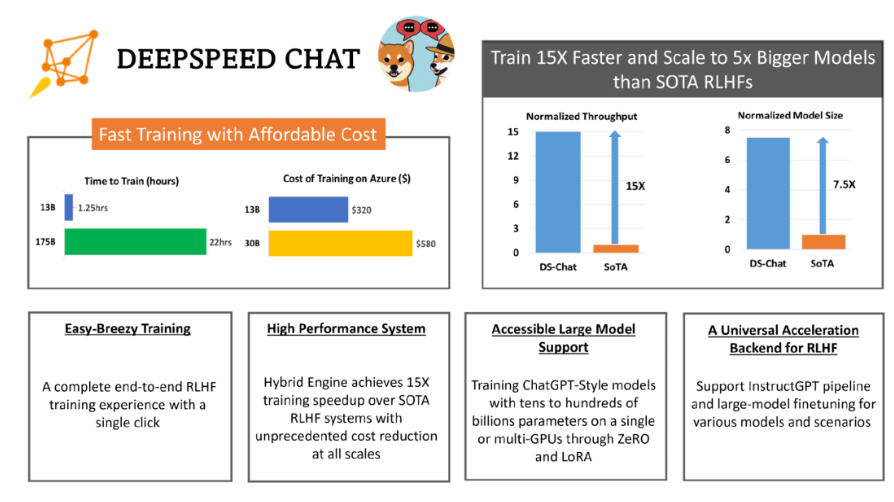
當地時間 4 月 12 日,微軟宣布開源 DeepSpeed-Chat,幫助用戶輕松訓練類 ChatGPT 等大語言模型。
據悉,Deep Speed Chat 是基于微軟 Deep Speed 深度學習優化庫開發而成,具備訓練、強化推理等功能,還使用了 RLHF(基于人類反饋的強化學習)技術,可將訓練速度提升 15 倍以上,而成本卻大大降低。
如下圖,一個 130 億參數的類 ChatGPT 模型,訓練時間只需要 1.25 小時。
簡單來說,用戶只需要通過 Deep Speed Chat 提供的 “傻瓜式” 操作,就能以最短的時間、最高效的成本訓練類 ChatGPT 大語言模型。
使 RLHF 訓練真正在 AI 社區普及
近來,ChatGPT 及類似模型引發了 AI 行業的一場風潮。ChatGPT 類模型能夠執行歸納、編程、翻譯等任務,其結果與人類專家相當甚至更優。為了能夠使普通數據科學家和研究者能夠更加輕松地訓練和部署 ChatGPT 等模型,AI 開源社區進行了各種嘗試,如 ChatLLaMa、ChatGLM-6B、Alpaca、Vicuna、Databricks-Dolly 等。
然而,目前業內依然缺乏一個支持端到端的基于人工反饋機制的強化學習(RLHF)的規模化系統,這使得訓練強大的類 ChatGPT 模型十分困難。
例如,使用現有的開源系統訓練一個具有 67 億參數的類 ChatGPT 模型,通常需要昂貴的多卡至多節點的 GPU 集群,但這些資源對大多數數據科學家或研究者而言難以獲取。同時,即使有了這樣的計算資源,現有的開源系統的訓練效率通常也達不到這些機器最大效率的 5%。
簡而言之,即使有了昂貴的多 GPU 集群,現有解決方案也無法輕松、快速、經濟的訓練具有數千億參數的最先進的類 ChatGPT 模型。
與常見的大語言模型的預訓練和微調不同,ChatGPT 模型的訓練基于 RLHF 技術,這使得現有深度學習系統在訓練類 ChatGPT 模型時存在種種局限。
微軟在 Deep Speed Chat 介紹文檔中表示,“為了讓 ChatGPT 類型的模型更容易被普通數據科學家和研究者使用,并使 RLHF 訓練真正在 AI 社區普及,我們發布了 DeepSpeed-Chat。”
據介紹,為了實現無縫的訓練體驗,微軟在 DeepSpeed-Chat 中整合了一個端到端的訓練流程,包括以下三個主要步驟:
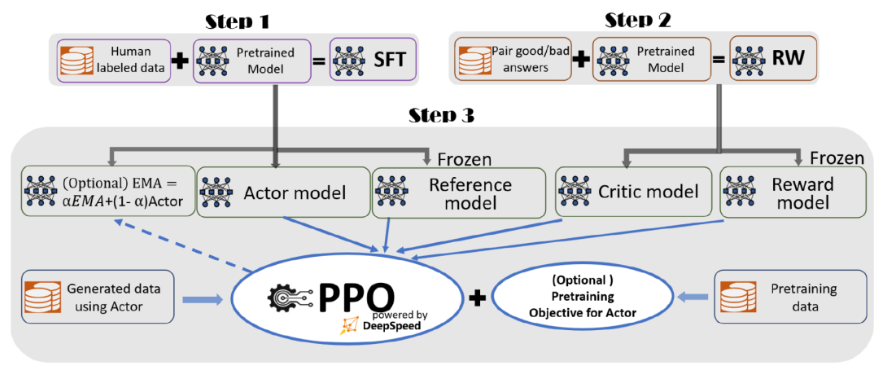
-
監督微調(SFT),使用精選的人類回答來微調預訓練的語言模型以應對各種查詢;
-
獎勵模型微調,使用一個包含人類對同一查詢的多個答案打分的數據集來訓練一個獨立的(通常比 SFT 小的)獎勵模型(RW);
-
RLHF 訓練,利用 Proximal Policy Optimization(PPO)算法,根據 RW 模型的獎勵反饋進一步微調 SFT 模型。
在步驟 3 中,微軟提供了指數移動平均(EMA)和混合訓練兩個額外的功能,以幫助提高模型質量。根據 InstructGPT,EMA 通常比傳統的最終訓練模型提供更好的響應質量,而混合訓練可以幫助模型保持預訓練基準解決能力。
總體來說,DeepSpeed-Chat 具有以下三大核心功能:
1.簡化 ChatGPT 類型模型的訓練和強化推理體驗:只需一個腳本即可實現多個訓練步驟,包括使用 Huggingface 預訓練的模型、使用 DeepSpeed-RLHF 系統運行 InstructGPT 訓練的所有三個步驟、甚至生成你自己的類 ChatGPT 模型。此外,微軟還提供了一個易于使用的推理API,用于用戶在模型訓練后測試對話式交互。
2.DeepSpeed-RLHF 模塊:DeepSpeed-RLHF 復刻了 InstructGPT 論文中的訓練模式,并確保包括 SFT、獎勵模型微調和 RLHF 在內的三個步驟與其一一對應。此外,微軟還提供了數據抽象和混合功能,以支持用戶使用多個不同來源的數據源進行訓練。
3.DeepSpeed-RLHF 系統:微軟將 DeepSpeed 的訓練(training engine)和推理能力(inference engine) 整合到一個統一的混合引擎(DeepSpeed-HE)中用于 RLHF 訓練。DeepSpeed-HE 能夠在 RLHF 中無縫地在推理和訓練模式之間切換,使其能夠利用來自 DeepSpeed-Inference 的各種優化,如張量并行計算和高性能 CUDA 算子進行語言生成,同時對訓練部分還能從 ZeRO- 和 LoRA-based 內存優化策略中受益。此外,DeepSpeed-HE 還能自動在 RLHF 的不同階段進行智能的內存管理和數據緩存。
高效、經濟、擴展性強
據介紹,DeepSpeed-RLHF 系統在大規模訓練中具有出色的效率,使復雜的 RLHF 訓練變得快速、經濟并且易于大規模推廣。
具體而言,DeepSpeed-HE 比現有系統快 15 倍以上,使 RLHF 訓練快速且經濟實惠。例如,DeepSpeed-HE 在 Azure 云上只需 9 小時即可訓練一個 OPT-13B 模型,只需 18 小時即可訓練一個 OPT-30B 模型。這兩種訓練分別花費不到 300 美元和 600 美元。
此外,DeepSpeed-HE 也具有卓越的擴展性,其能夠支持訓練擁有數千億參數的模型,并在多節點多 GPU 系統上展現出卓越的擴展性。因此,即使是一個擁有 130 億參數的模型,也只需 1.25 小時就能完成訓練。而對于參數規模為 1750 億的更大模型,使用 DeepSpeed-HE 進行訓練也只需不到一天的時間。
另外,此次開源有望實現 RLHF 訓練的普及化。微軟表示,僅憑單個 GPU,DeepSpeed-HE 就能支持訓練超過 130 億參數的模型。這使得那些無法使用多 GPU 系統的數據科學家和研究者不僅能夠輕松創建輕量級的 RLHF 模型,還能創建大型且功能強大的模型,以應對不同的使用場景。
那么,人手一個專屬 ChatGPT 的時代,還有多遠?
6. 10張圖總結2023年人工智能狀況
https://mp.weixin.qq.com/s/oKPPsfzKK8DbGg_vzaTRuQ
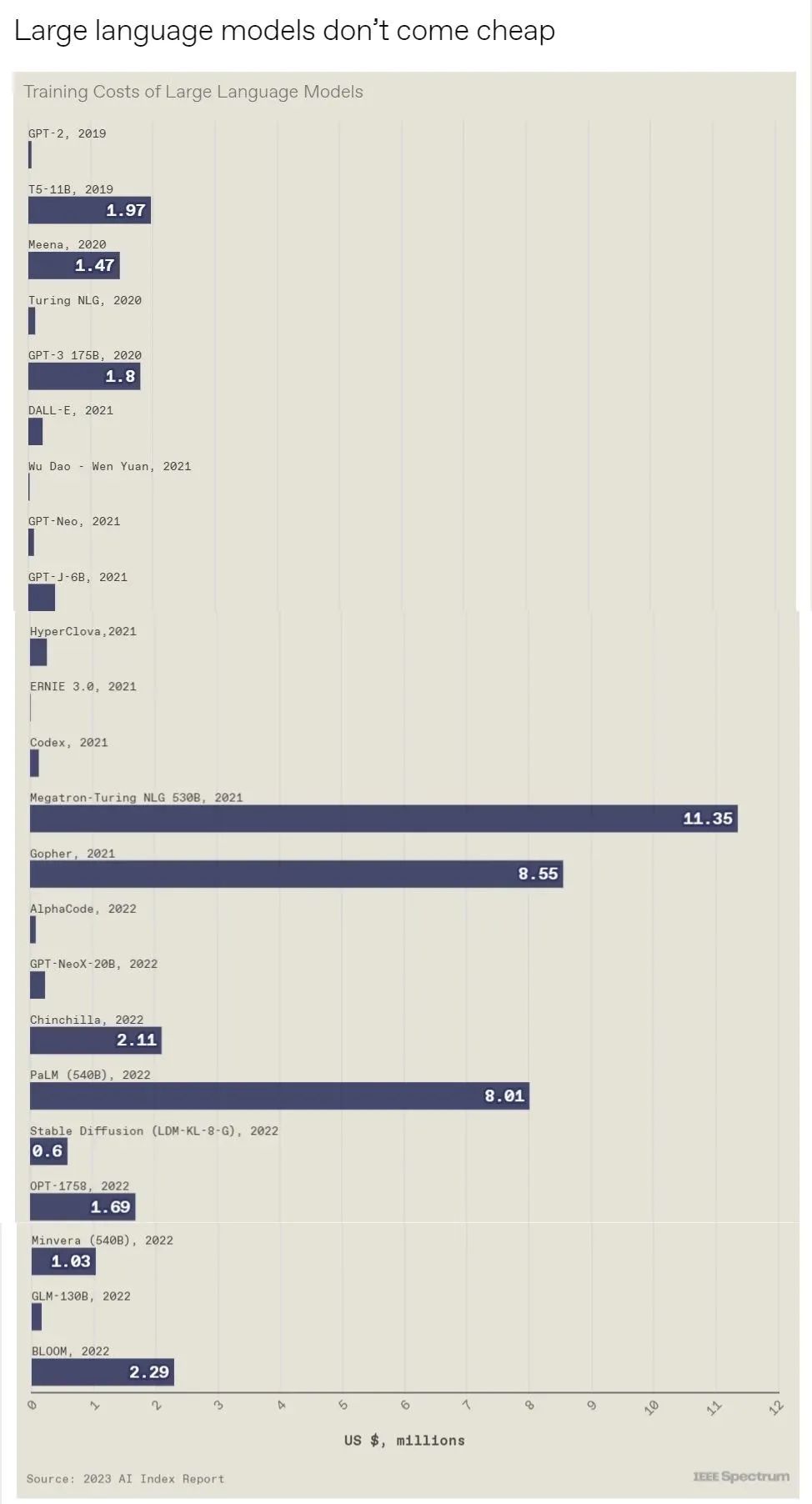
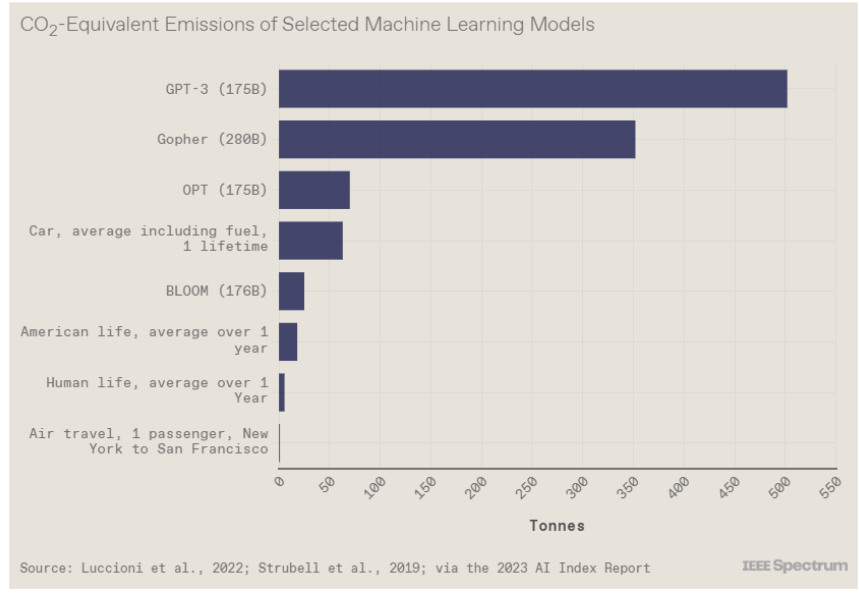
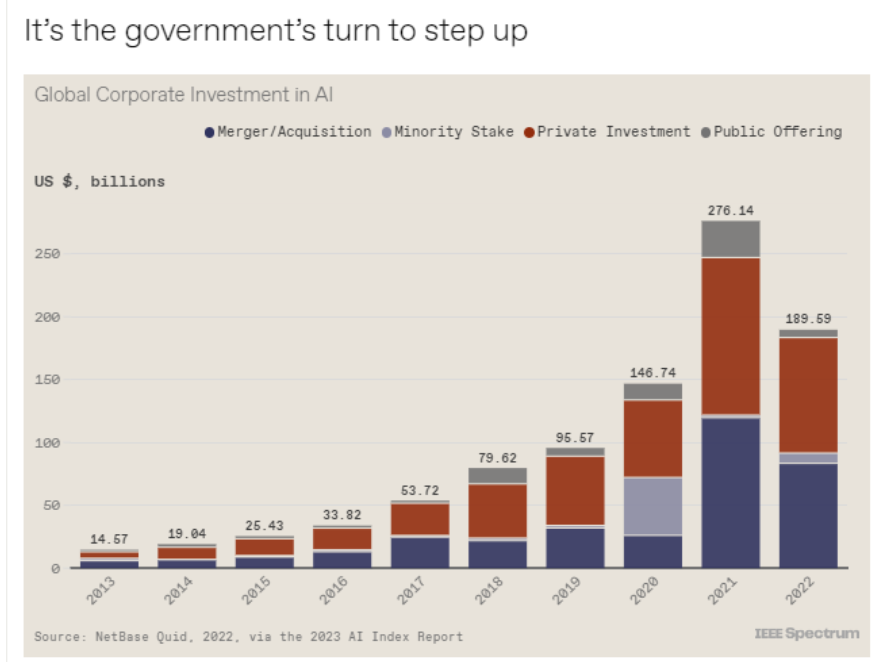
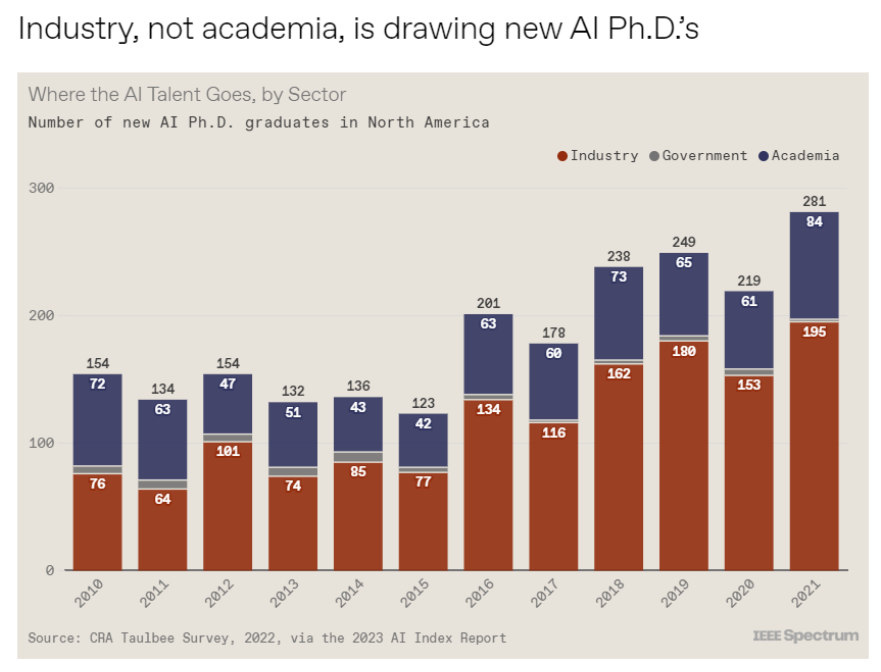
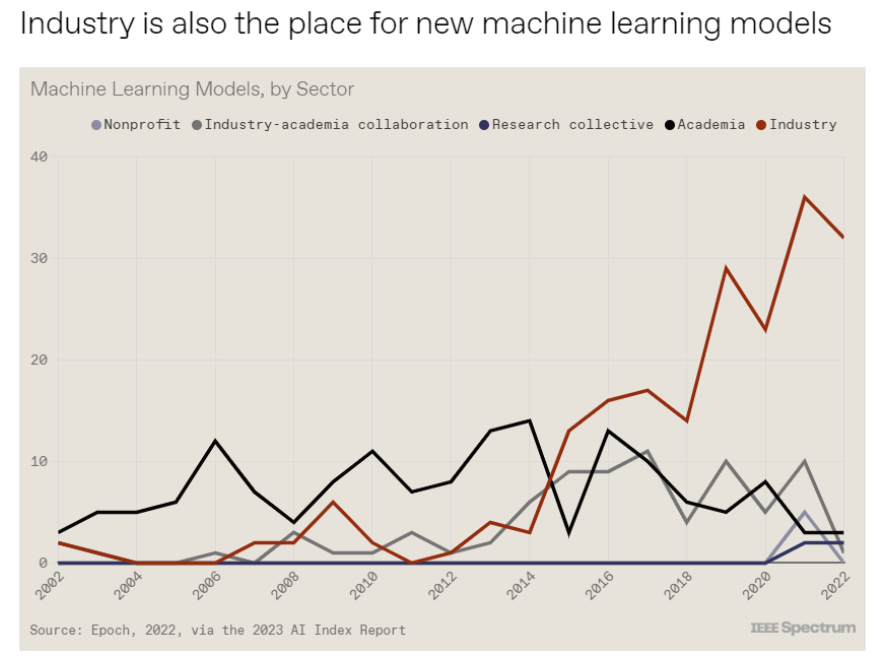
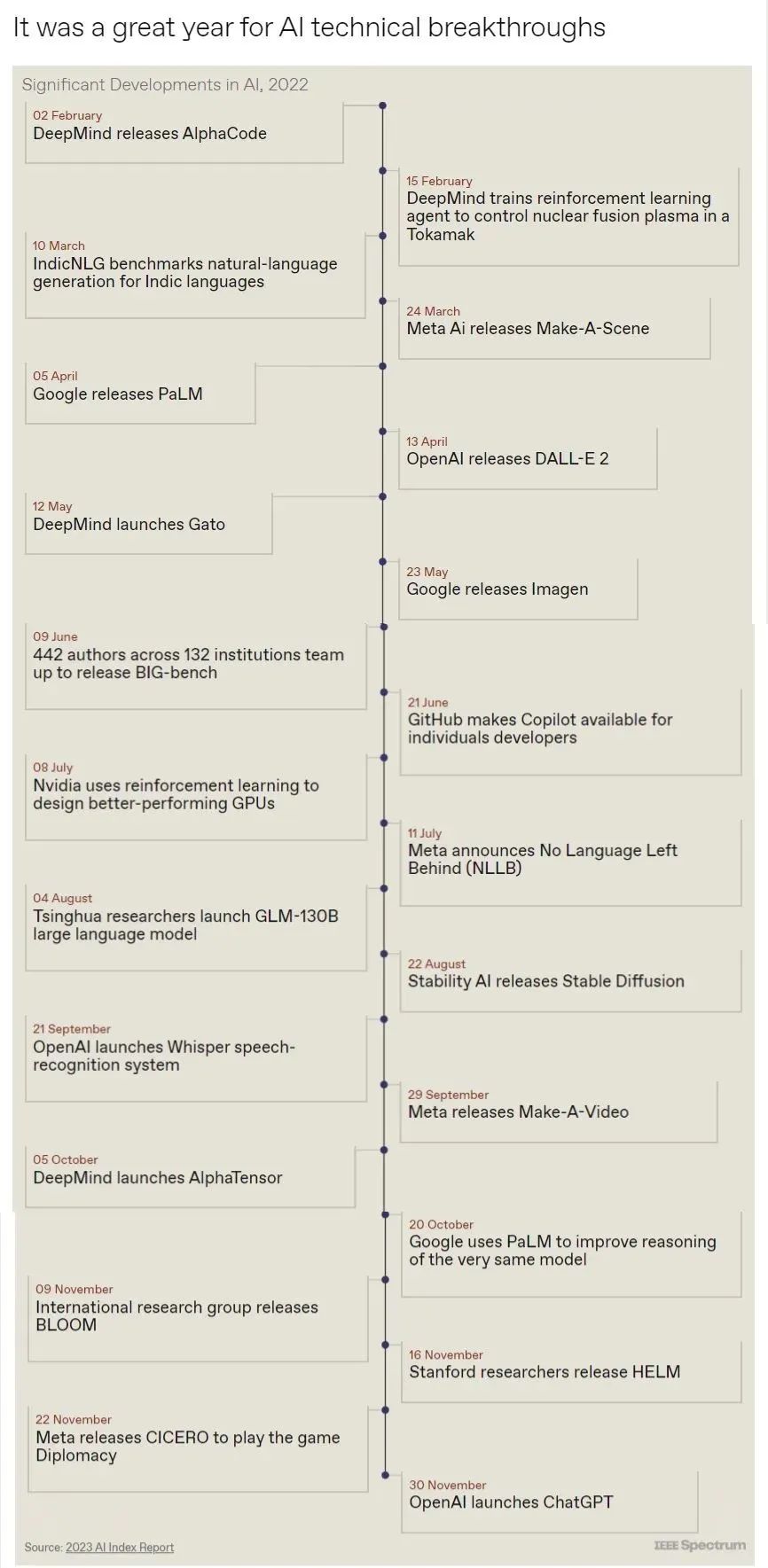
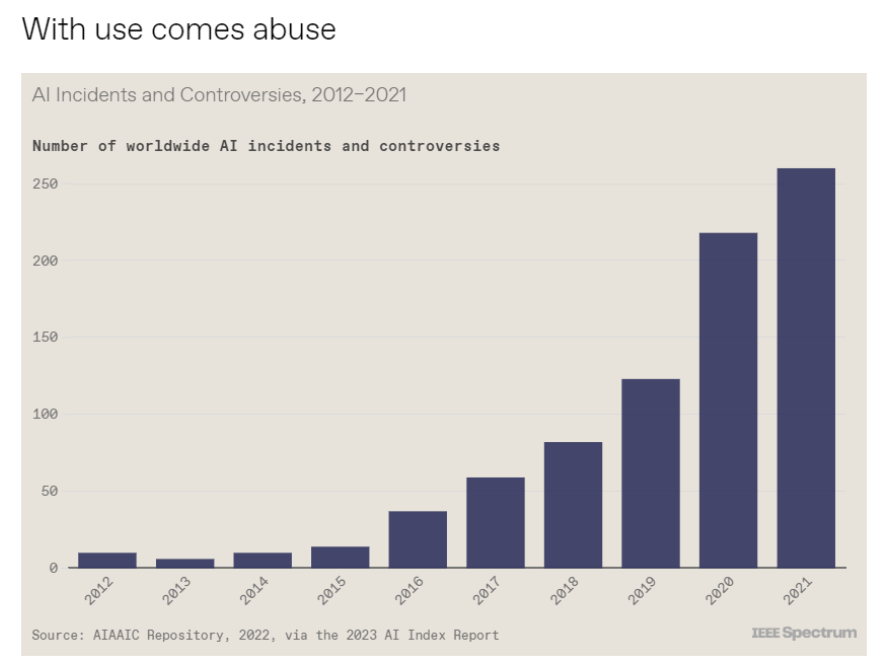
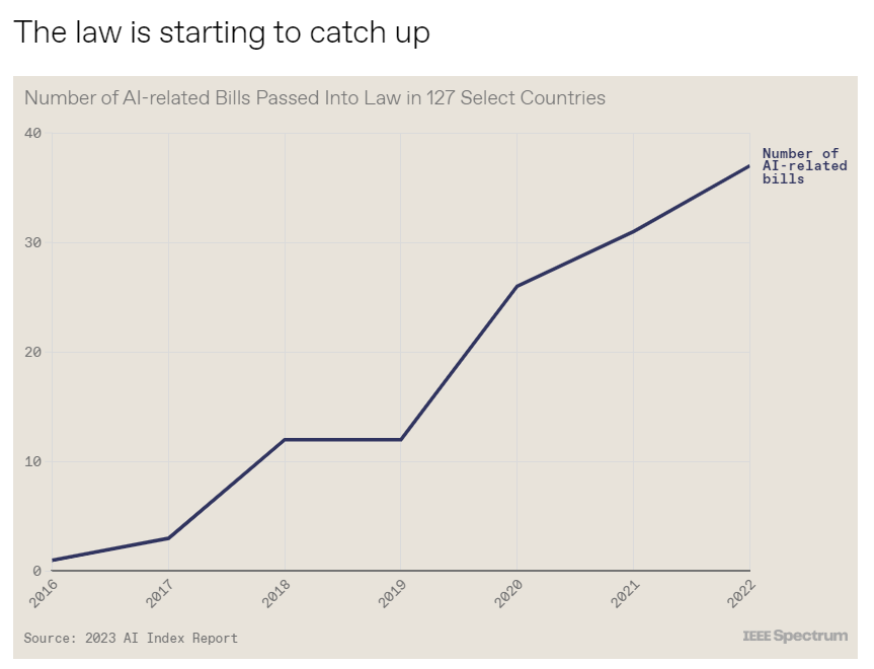
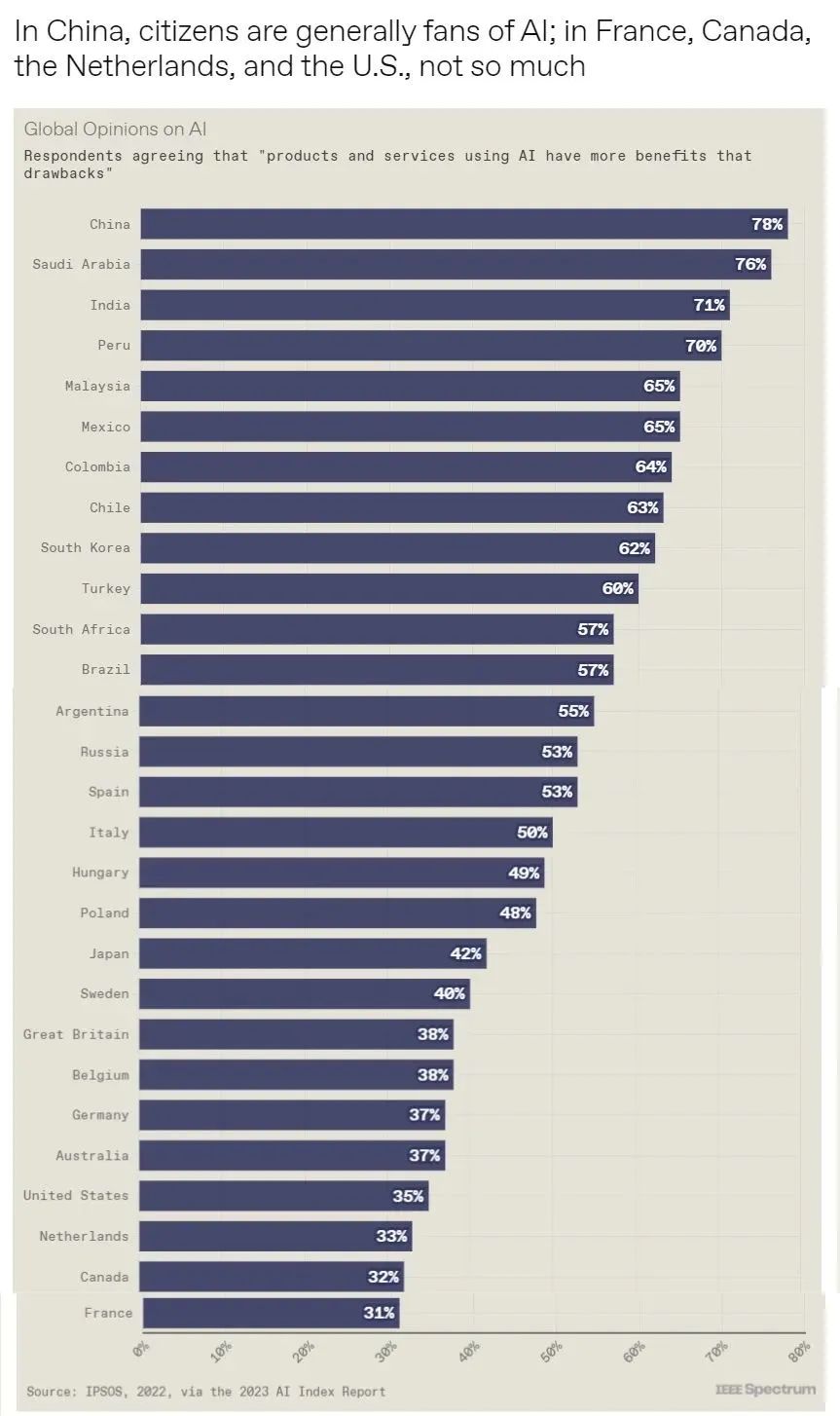
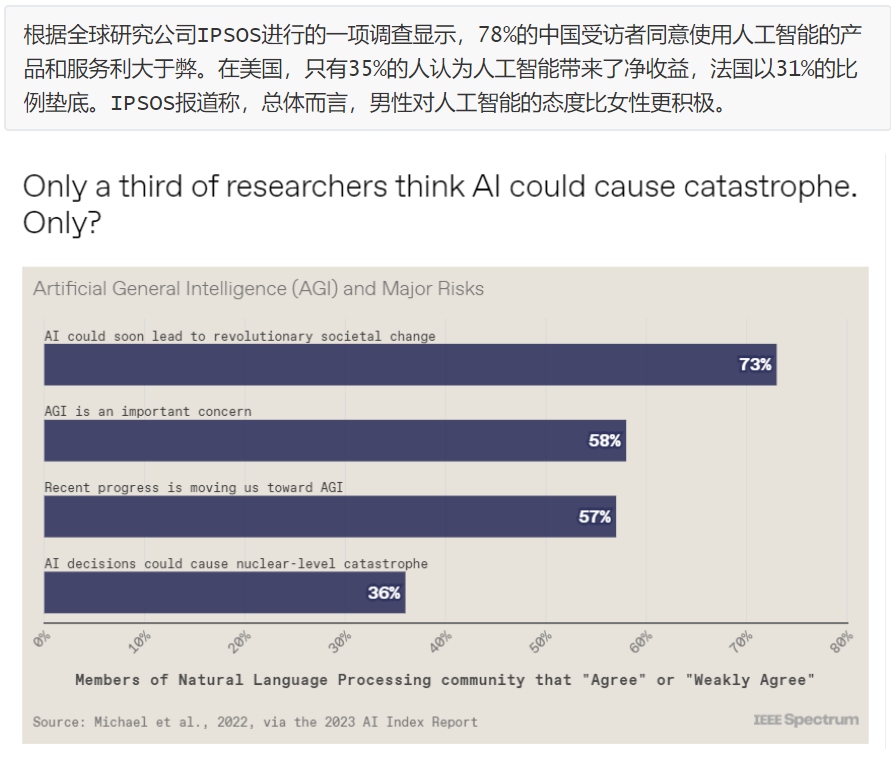
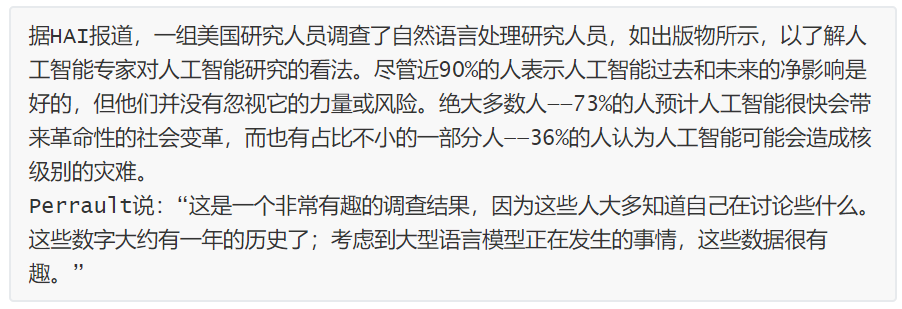
斯坦福大學以人為本人工智能研究所(Human-Centered AI Institute,HAI)收集了一年的人工智能數據(https://hai.stanford.edu/),提供了當今人工智能世界的全面情況。該報告自2017年起,由斯坦福大學開始主導研究。AI指數報告作為一項獨立計劃,每年發布AI指數年度報告,全面追蹤人工智能的最新發展狀態和趨勢。今年的綜合報告共有302頁,這比2022年的報告增長了近60%。這在很大程度上要歸功于2022年需求關注的生成性人工智能的蓬勃發展,以及收集人工智能和道德數據的努力越來越大。
對于那些像我(作者,以下簡稱我)一樣渴望閱讀整個《2023年人工智能指數報告》(https://aiindex.stanford.edu/report/)的人,你可以首先在這里進行了解。下面是10張圖表,捕捉了當今人工智能的基本趨勢。








———————End———————
RT-Thread線下入門培訓-4月場次 青島、北京
1.免費2.動手實驗+理論3.主辦方免費提供開發板4.自行攜帶電腦,及插線板用于筆記本電腦充電5.參與者需要有C語言、單片機(ARM Cortex-M核)基礎,請提前安裝好RT-Thread Studio 開發環境

立即掃碼報名
報名鏈接
https://jinshuju.net/f/UYxS2k
巡回城市:青島、北京、西安、成都、武漢、鄭州、杭州、深圳、上海、南京
你可以添加微信:rtthread2020 為好友,注明:公司+姓名,拉進RT-Thread官方微信交流群!
點擊閱讀原文,進入RT-Thread 官網
原文標題:【嵌入式AI簡報20230414】黑芝麻智能7nm中央計算芯片正式發布、微軟開源“傻瓜式”類ChatGPT模型訓練工具
-
RT-Thread
+關注
關注
31文章
1305瀏覽量
40391
原文標題:【嵌入式AI簡報20230414】黑芝麻智能7nm中央計算芯片正式發布、微軟開源“傻瓜式”類ChatGPT模型訓練工具
文章出處:【微信號:RTThread,微信公眾號:RTThread物聯網操作系統】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
黑芝麻智能與RockAI聯手發布AI Agent解決方案
黑芝麻智能與Nullmax聯袂發布A2000多模態大模型智駕方案
黑芝麻智能與Elektrobit聯手推出武當系列解決方案
黑芝麻智能與RockAI發布AI Agent解決方案
黑芝麻智能、NESINEXT、傅利葉聯合發布“靈巧手”
黑芝麻智能與Elektrobit推出Classic AUTOSAR解決方案
嵌入式系統的未來趨勢有哪些?
開啟全新AI時代 智能嵌入式系統快速發展——“第六屆國產嵌入式操作系統技術與產業發展論壇”圓滿結束
智能汽車AI芯片第一股黑芝麻智能在港交所掛牌上市
EVASH Ultra EEPROM:助力ChatGPT等AI應用的嵌入式存儲解決方案
黑芝麻智能獲國際最高安全標準認證
AI引爆邊緣計算變革,塑造嵌入式產業新未來AI引爆邊緣計算變革,塑造嵌入式產業新未來——2024研華嵌入式






 工商網監
工商網監
評論