") 多語(yǔ)言AI的現(xiàn)狀
多語(yǔ)言AI的現(xiàn)狀
-01-
作者介紹
Sebastian Ruder是Google的研究科學(xué)家,致力于研究代表性不足的語(yǔ)言的自然語(yǔ)言處理(NLP)。在此之前,他是DeepMind的研究科學(xué)家。他在Insight Research Centre for Data Analytics完成了自然語(yǔ)言處理和深度學(xué)習(xí)博士學(xué)位。在學(xué)習(xí)期間,他曾與微軟,IBM的Extreme Blue,Google Summer of Code和SAP等公司合作。
-02-
譯者說(shuō)
據(jù)統(tǒng)計(jì),世界上有超過(guò)7000種不同的語(yǔ)言,每種語(yǔ)言都承載著不同的文化。但是在歷史的長(zhǎng)河中,已經(jīng)有很多語(yǔ)言已經(jīng)消失或者瀕臨消失。笛卡爾曾經(jīng)說(shuō)過(guò):“語(yǔ)言的分歧是人生最大的不幸之一”。長(zhǎng)久以來(lái),實(shí)現(xiàn)不同語(yǔ)言之間的互通,能夠在經(jīng)濟(jì)活動(dòng)、文化交流中消除語(yǔ)言造成的隔閡,是人類(lèi)共同努力的方向。多語(yǔ)言的模型可以抵消現(xiàn)有的語(yǔ)言鴻溝,確保一些非主流語(yǔ)言的使用者不會(huì)落后。而當(dāng)下的一些語(yǔ)言模型主要集中在英語(yǔ)和其他具有大量資源的語(yǔ)言上,對(duì)一些瀕危語(yǔ)言或者代表性較差的語(yǔ)言的研究十分不足。無(wú)論是當(dāng)下最流行的語(yǔ)言模型比如ChatGPT(目前我們已知它支持至少95種語(yǔ)言),還是Meta-AI最新開(kāi)發(fā)的多語(yǔ)言模型NLLB-200(目前種類(lèi)最多的多語(yǔ)言翻譯模型,可以實(shí)現(xiàn)200+語(yǔ)言的互譯),都無(wú)法實(shí)現(xiàn)世界上所有語(yǔ)言的互通,就更不用提在低資源語(yǔ)言上進(jìn)行其他研究了。因此,開(kāi)發(fā)適用于更多語(yǔ)言的模型十分重要。
原文鏈接:https://www.ruder.io/state-of-multilingual-ai/
-03-
譯文大綱
多語(yǔ)言研究現(xiàn)狀
近期進(jìn)展
挑戰(zhàn)與機(jī)遇
-04-
譯文
多語(yǔ)言研究現(xiàn)狀:全世界大約有7000種語(yǔ)言。大約400種語(yǔ)言的用戶超過(guò)100萬(wàn),大約200種語(yǔ)言的用戶超過(guò)10萬(wàn)[1]。有研究人員[2]回顧了在ACL 2008上發(fā)表的論文,發(fā)現(xiàn)63%的論文都集中在英語(yǔ)上。對(duì)于最近的一項(xiàng)研究[3],同樣回顧了ACL 2021的論文,發(fā)現(xiàn)近70%的論文僅在英語(yǔ)上進(jìn)行評(píng)估。10年過(guò)去了,以英語(yǔ)為主流的現(xiàn)象似乎沒(méi)有什么變化。 同樣的,使用這些低資源語(yǔ)言的研究人員在ML和NLP社區(qū)中的代表性同樣不足。例如,雖然我們可以觀察到隸屬于非洲大學(xué)的作者數(shù)量在頂級(jí)機(jī)器學(xué)習(xí)(ML)和NLP場(chǎng)所發(fā)表文章略有上升趨勢(shì),但與每年來(lái)自其他地區(qū)的數(shù)千名作者在這些場(chǎng)所發(fā)表文章相比,這種增長(zhǎng)相形見(jiàn)絀。
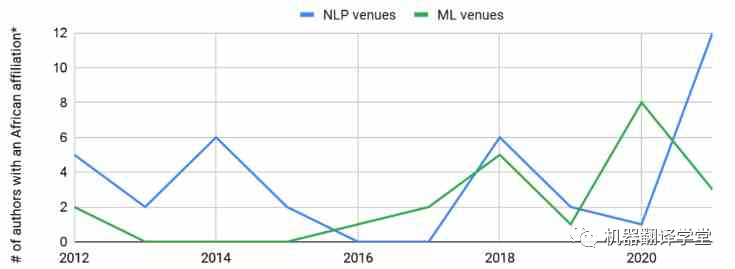
圖1. 非洲NLP研究人員在頂級(jí)ML和NLP會(huì)議中的代表。*:不考慮在國(guó)外工作的非洲作家。數(shù)據(jù)基于:Marek Rei的ml_nlp_paper_data。NLP會(huì)議:ACL,CL,COLING,CoNLL,EACL,EMNLP,NAACL,TACL;ML會(huì)議:AAAI,ICLR,ICML,NeurIPS。
許多 ML 領(lǐng)域中當(dāng)前最先進(jìn)的模型主要基于兩個(gè)要素:1) 大型的可擴(kuò)展模型結(jié)構(gòu)(通常基于 Transformer[4])和 2)遷移學(xué)習(xí)[5]。鑒于這些模型的一般性質(zhì),它們可以應(yīng)用于各種類(lèi)型的數(shù)據(jù),包括圖像[6],視頻[7]和音頻[8]。最近NLP中一些成功的模型如BERT[9],RoBERTa[10],BART[11],T5[12]和DeBERTa[13],它們使用了多種掩碼語(yǔ)言建模(masked language modeling)方法的變體在數(shù)十億個(gè)token的文本上進(jìn)行了訓(xùn)練。在語(yǔ)音方面,wav2vec 2.0[14]也在大量未標(biāo)記的語(yǔ)音上進(jìn)行了預(yù)訓(xùn)練。
多語(yǔ)言模型: 在當(dāng)下的深度學(xué)習(xí)領(lǐng)域中,許多較為先進(jìn)的模型都在數(shù)十億個(gè)token的文本上使用了多種掩碼語(yǔ)言建模(masked language modeling)進(jìn)行預(yù)訓(xùn)練。在NLP中,諸如mBERT,RemBERT[15],XLM-RoBERTa[16],mBART[17],mT5[18]和mDeBERTa[13]等模型,都使用了類(lèi)似的方式進(jìn)行訓(xùn)練:在大約100種語(yǔ)言的預(yù)料上,隨機(jī)預(yù)測(cè)被mask的token。與單語(yǔ)模型相比,這些多語(yǔ)言模型需要更大的詞匯表來(lái)表示多種語(yǔ)言中的token。同時(shí),也有一些研究致力于學(xué)習(xí)更魯棒的多語(yǔ)言表示,包括shared token[19],subword fertility[20]和詞嵌入對(duì)齊[21]等方法。在語(yǔ)音中,XSLR[22]和 UniSpeech[23]等模型分別針對(duì) 53 種和 60 種語(yǔ)言的大量未標(biāo)記數(shù)據(jù)進(jìn)行了預(yù)訓(xùn)練。
多語(yǔ)言的詛咒: 為什么這些模型最多只能涵蓋 200種語(yǔ)言?其中一個(gè)原因是“多語(yǔ)言的詛咒”[16]。與許多其他任務(wù)的訓(xùn)練過(guò)程相似,模型預(yù)訓(xùn)練數(shù)據(jù)的語(yǔ)言越多,可用于學(xué)習(xí)每種語(yǔ)言表示的模型容量就越少。增加模型的大小在一定程度上可以改善這一點(diǎn),使得模型能夠?yàn)槊糠N語(yǔ)言提供更多容量[24]。
預(yù)訓(xùn)練數(shù)據(jù)的缺乏: 除了模型容量,多語(yǔ)言模型的另一個(gè)限制因素是數(shù)據(jù)。網(wǎng)絡(luò)上的數(shù)據(jù)偏向于西方國(guó)家使用的語(yǔ)言,對(duì)于那些低資源數(shù)據(jù)嚴(yán)重不足。這令人擔(dān)憂,因?yàn)橹坝醒芯勘砻鳎A(yù)訓(xùn)練數(shù)據(jù)量與某些任務(wù)的下游性能相關(guān)[25][26][27]。特別是,在預(yù)訓(xùn)練期間從未見(jiàn)過(guò)的語(yǔ)言通常會(huì)導(dǎo)致模型在實(shí)際應(yīng)用中性能不佳[28][29]。
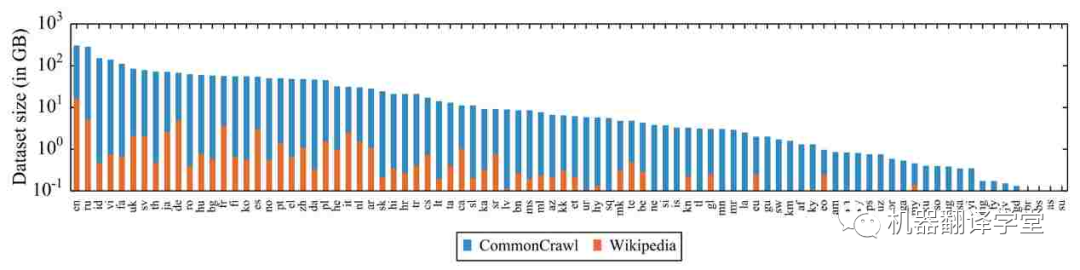
圖2. 維基百科和 CommonCrawl[16] 中統(tǒng)計(jì)的 88 種語(yǔ)言和其對(duì)應(yīng)的數(shù)據(jù)量(對(duì)數(shù)尺度)。
現(xiàn)有多語(yǔ)言資源的質(zhì)量問(wèn)題 :即使對(duì)于數(shù)據(jù)豐富的語(yǔ)言,過(guò)去的工作也表明,一些常用的多語(yǔ)言資源存在嚴(yán)重的質(zhì)量問(wèn)題。例如WikiAnn[30](基于維基百科的弱監(jiān)督多語(yǔ)言命名實(shí)體識(shí)別數(shù)據(jù)集)中的實(shí)體跨度有很多是錯(cuò)誤的[31]。同樣,一些自動(dòng)挖掘的資源和用于機(jī)器翻譯的自動(dòng)對(duì)齊語(yǔ)料庫(kù)也是有問(wèn)題的[32]。但是總的來(lái)說(shuō),在代表性不足的語(yǔ)言中,性能似乎主要受到數(shù)據(jù)數(shù)量而不是質(zhì)量的限制[33]。
多語(yǔ)言評(píng)估 :我們可以在一些具有代表性的多語(yǔ)言評(píng)估指標(biāo)(例如XTREME[25]和SuperGLUE[34])上查看最新模型的性能,從而更好地了解最新技術(shù)。該XTREME可以測(cè)試模型在9個(gè)任務(wù)和40種語(yǔ)言上的性能。從兩年半前的第一個(gè)多語(yǔ)言預(yù)訓(xùn)練模型開(kāi)始,多語(yǔ)言模型的性能穩(wěn)步提高,并且正在慢慢接近基準(zhǔn)測(cè)試上的人類(lèi)水平。
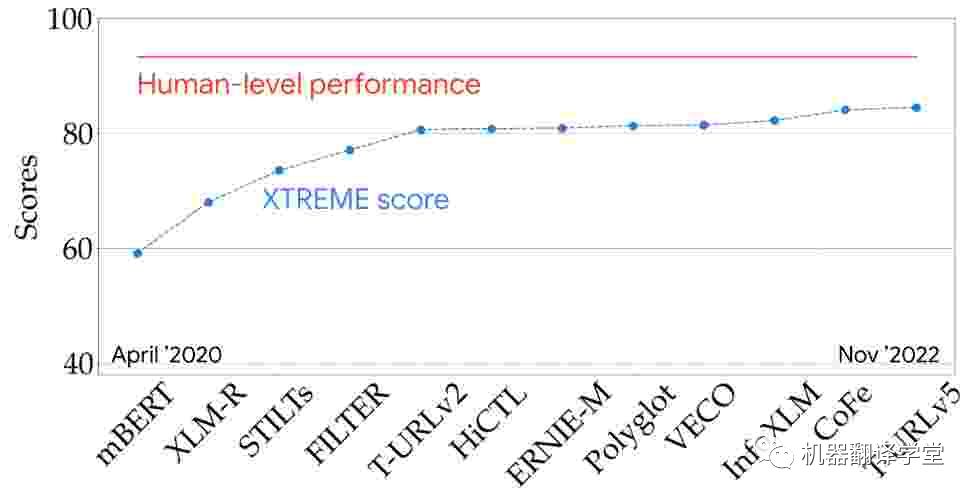
圖3. 模型在 XTREME 排行榜上的表現(xiàn)(9 個(gè)任務(wù)和 40 種語(yǔ)言)
多語(yǔ)言模型和以英語(yǔ)為中心的模型 :觀察最近 NLP 中的大型語(yǔ)言模型,我們根據(jù)預(yù)訓(xùn)練中的非英語(yǔ)數(shù)據(jù)的比例繪制了如下圖片。基于這種特征,我們可以發(fā)現(xiàn)有兩個(gè)不同的研究流派:1)直接使用多種語(yǔ)言數(shù)據(jù)進(jìn)行訓(xùn)練的多語(yǔ)言模型和2)主要在英語(yǔ)數(shù)據(jù)上訓(xùn)練的以英語(yǔ)為中心的模型。
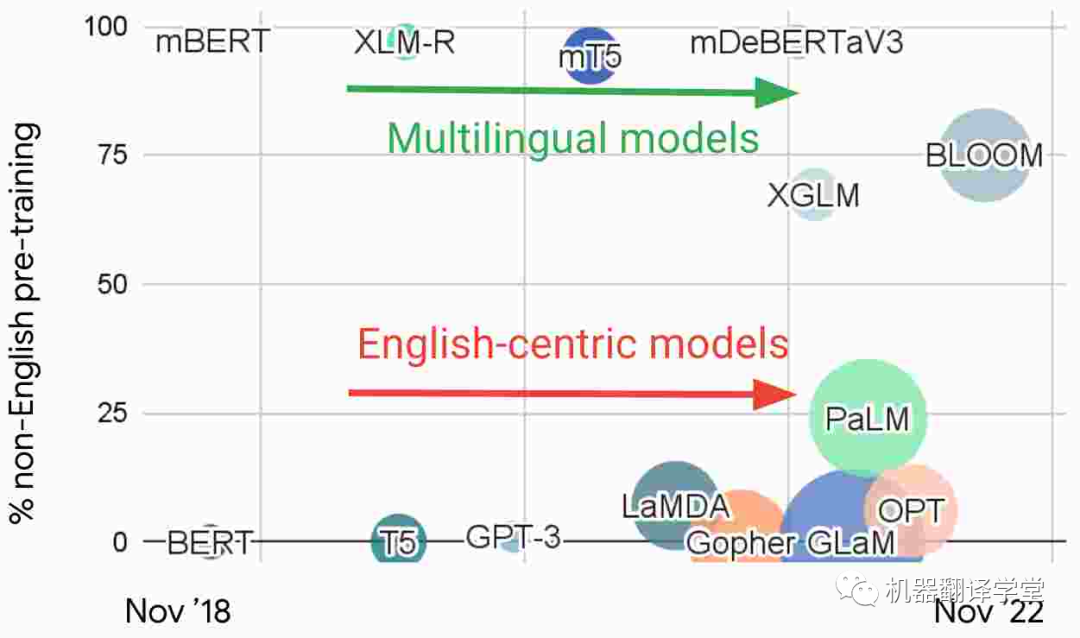
圖4. 近期一些大語(yǔ)言模型中預(yù)訓(xùn)練數(shù)據(jù)中非英語(yǔ)數(shù)據(jù)的比例
以英語(yǔ)為中心的模型構(gòu)成了NLP研究主流的基礎(chǔ),雖然這些模型越來(lái)越大,但它們并沒(méi)有變得更加多語(yǔ)言。例如,GPT-3[35]和 PaLM[36]可以在具有大量數(shù)據(jù)的語(yǔ)言之間翻譯文本。雖然它們已被證明能夠執(zhí)行多語(yǔ)言的few-shot學(xué)習(xí)[37][38][39],但當(dāng)prompt或輸入數(shù)據(jù)被翻譯成英語(yǔ)時(shí),模型表現(xiàn)最佳。在非英語(yǔ)語(yǔ)言對(duì)之間翻譯或翻譯成低資源的語(yǔ)言時(shí),它們的表現(xiàn)也很差。雖然 PaLM 能夠?qū)⒎怯⒄Z(yǔ)文本匯總為英語(yǔ),但在生成其他語(yǔ)言的文本時(shí)卻很困難。
近期進(jìn)展
原博客對(duì)于多語(yǔ)言領(lǐng)域的研究團(tuán)體,領(lǐng)域會(huì)議等進(jìn)行了介紹,由于篇幅原因,我們先略過(guò)這部分,只介紹在數(shù)據(jù)集和模型方面的進(jìn)展,感興趣的同學(xué)可以去原博客學(xué)習(xí)。
數(shù)據(jù)集 :在研究方面,在一些代表性比較低的語(yǔ)言上,出現(xiàn)了一系列新的數(shù)據(jù)集,它們包含了許多任務(wù),包括文本分類(lèi)[40],情感分析[41],ASR,命名實(shí)體識(shí)別[42],問(wèn)答[43]和摘要[44]等等。

圖5. MasakhaNER中非洲語(yǔ)言的命名實(shí)體注釋。PER、LOC 和 DATE 實(shí)體分別為紫色、橙色和綠色(Adelani 等人,2021 年)[42]
模型 :在多語(yǔ)言領(lǐng)域開(kāi)發(fā)的新模型特別關(guān)注代表性不足的語(yǔ)言。有專(zhuān)注于非洲語(yǔ)言的基于文本(text-based)的語(yǔ)言模型,如AfriBERTa[45],AfroXLM-R[46]和KinyaBERT[47],以及印度尼西亞語(yǔ)言的模型,如IndoBERT[48][49]和IndoGPT[50]。對(duì)于印度語(yǔ)言,有IndicBERT[51]和MuRIL[52],以及語(yǔ)音模型,如CLSRIL[53]和IndicWav2Vec[54]。其中許多模型是先在幾種相關(guān)語(yǔ)言上進(jìn)行訓(xùn)練,因此能夠利用遷移學(xué)習(xí),并且比較大的多語(yǔ)言模型更有效。論文[55]和[56]中論述了最近NLP和語(yǔ)音中的多語(yǔ)言模型的進(jìn)展。
-03-
挑戰(zhàn)與機(jī)遇
挑戰(zhàn)1:有限的數(shù)據(jù)
可以說(shuō),多語(yǔ)言研究面臨的最大挑戰(zhàn)是世界上大多數(shù)語(yǔ)言可用的數(shù)據(jù)量有限。Joshi等人[57]根據(jù)其中可用的標(biāo)記和未標(biāo)記數(shù)據(jù)量將世界語(yǔ)言分為六個(gè)不同的類(lèi)別。如下圖所示,世界上 88% 的語(yǔ)言屬于資源組 0,幾乎沒(méi)有可用的文本數(shù)據(jù),而 5% 的語(yǔ)言屬于資源組 1,可用的文本數(shù)據(jù)非常有限。
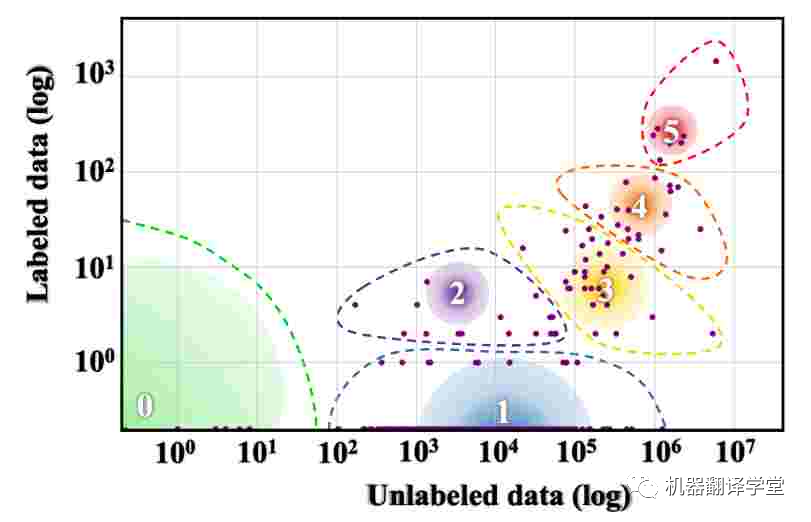
圖6. 世界語(yǔ)言的資源分布。漸變圓圈的大小表示該類(lèi)中的語(yǔ)言數(shù)。(Joshi 等人,2020 年)[57]。
機(jī)遇1:真實(shí)世界的數(shù)據(jù)
我們?nèi)绾慰朔澜缯Z(yǔ)言資源分布的巨大差異?創(chuàng)建新數(shù)據(jù)的成本很高,尤其是在標(biāo)注很少的語(yǔ)言中。出于這個(gè)原因,許多現(xiàn)有的多語(yǔ)言數(shù)據(jù)集,如XNLI[58],XQuAD[59]和XCOPA[60]都是基于已創(chuàng)建的英語(yǔ)數(shù)據(jù)集的翻譯。然而,這種基于翻譯的數(shù)據(jù)是有問(wèn)題的。一種語(yǔ)言的翻譯文本可以被認(rèn)為是該語(yǔ)言的一種“方言”,稱(chēng)為“translationese”,它不同于這種語(yǔ)言本身[61]。因此基于翻譯的測(cè)試集可能會(huì)高估在類(lèi)似數(shù)據(jù)上訓(xùn)練的模型的性能,而這些模型在真實(shí)場(chǎng)景中的表現(xiàn)可能不盡人意[62]。
西方概念的過(guò)度學(xué)習(xí) :除了這些問(wèn)題之外,翻譯現(xiàn)有數(shù)據(jù)集會(huì)繼承原始數(shù)據(jù)的偏差。特別是,翻譯數(shù)據(jù)不同于不同語(yǔ)言用戶自然創(chuàng)建的數(shù)據(jù)。由于現(xiàn)有的數(shù)據(jù)集大多是由西方國(guó)家的工作者或研究人員創(chuàng)建的,因此它們主要反映了以西方為中心的概念。例如,ImageNet[63]是ML中最具影響力的數(shù)據(jù)集之一,它基于英語(yǔ)WordNet。因此,它包含了一些過(guò)于針對(duì)英語(yǔ)、但是不存在于其他文化中的概念[64]。
實(shí)用數(shù)據(jù) :因此,根據(jù)實(shí)際使用情況提供的信息來(lái)創(chuàng)建數(shù)據(jù)集是十分重要的。一方面,數(shù)據(jù)應(yīng)反映講該語(yǔ)言的人的背景比如文化背景、語(yǔ)言使用背景。一方面,它還減少了研究和實(shí)際場(chǎng)景之間的分布偏移,并使在學(xué)術(shù)數(shù)據(jù)集、或者在金融、法律等專(zhuān)業(yè)領(lǐng)域上開(kāi)發(fā)的模型性能更好。
多模態(tài)數(shù)據(jù) :世界上許多語(yǔ)言更常用而不是書(shū)面語(yǔ)言。我們可以通過(guò)關(guān)注來(lái)自多模態(tài)數(shù)據(jù)源(如無(wú)線電廣播和在線視頻)的信息以及組合來(lái)自多種模態(tài)的信息來(lái)克服對(duì)文本數(shù)據(jù)的依賴(lài)(和缺乏)。最近的語(yǔ)音和文本模型[65][66]在語(yǔ)音任務(wù)(如ASR,語(yǔ)音翻譯和文本到語(yǔ)音)上有了很大的進(jìn)步。但是它們?cè)诩兾谋救蝿?wù)上的表現(xiàn)還是很差[67]。利用多模態(tài)數(shù)據(jù)以及研究不同語(yǔ)言的語(yǔ)言特征及其在文本和語(yǔ)音中的相互作用有很大的潛力[68]。
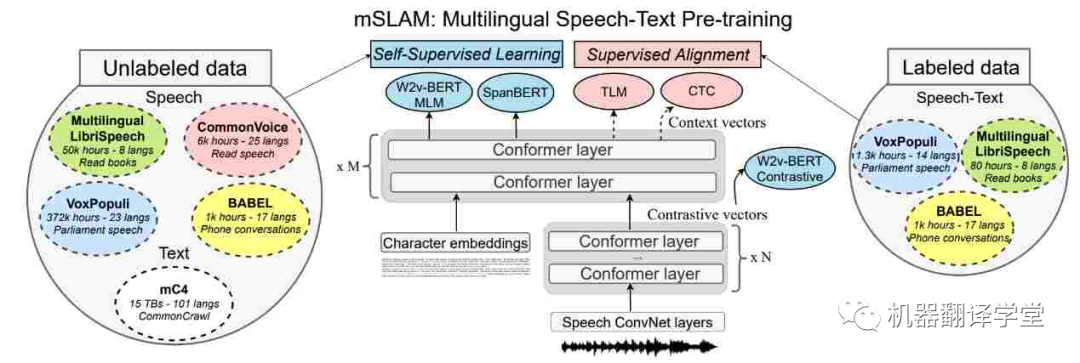
圖7. mSLAM 中的多語(yǔ)言語(yǔ)音文本預(yù)訓(xùn)練模型,在未標(biāo)記和標(biāo)記的文本和語(yǔ)音數(shù)據(jù)集上聯(lián)合預(yù)訓(xùn)練模型(Bapna 等人,2022 年)[67]。
最后,在為一些代表性不足的語(yǔ)言收集數(shù)據(jù)和開(kāi)發(fā)模型時(shí),人工智能面臨的挑戰(zhàn)包括數(shù)據(jù)管理、安全、隱私等等。為了應(yīng)對(duì)這些挑戰(zhàn),需要回答以下問(wèn)題:如何保證數(shù)據(jù)和技術(shù)的適當(dāng)使用和所有權(quán)[69]?是否有適當(dāng)?shù)姆椒▉?lái)檢測(cè)和過(guò)濾有偏差的數(shù)據(jù),并檢測(cè)模型中的偏差?在數(shù)據(jù)收集和使用過(guò)程中如何保護(hù)隱私?如何使數(shù)據(jù)和技術(shù)開(kāi)發(fā)參與[70]?
挑戰(zhàn)2:有限的計(jì)算
代表性不足的語(yǔ)言的應(yīng)用面臨的限制不僅僅是數(shù)據(jù)的缺乏,還有計(jì)算資源的匱乏。例如,GPU服務(wù)器即使在許多國(guó)家的頂尖大學(xué)中也很稀缺[4],而在使用代表性不足的語(yǔ)言的國(guó)家,計(jì)算的成本更高[71]。
機(jī)遇2:高效性
為了更好地利用有限的計(jì)算,我們必須開(kāi)發(fā)更有效的方法。有關(guān)高效Transformer架構(gòu)和高效NLP方法的綜述,請(qǐng)參閱[72]和[73]。由于預(yù)訓(xùn)練模型廣泛可用,一個(gè)有前景的方向是通過(guò)參數(shù)高效方法優(yōu)化這些模型,這已被證明比in-context learning更有效[74]。
一種常見(jiàn)的方法是是使用adapter[75][76],這是插入預(yù)訓(xùn)練模型權(quán)重之間的小模塊。這些參數(shù)高效的方法可以通過(guò)分配額外模型容量給特定的語(yǔ)言來(lái)提升多語(yǔ)言的能力。它們還能夠讓多語(yǔ)言預(yù)訓(xùn)練模型在預(yù)訓(xùn)練期間沒(méi)見(jiàn)過(guò)的語(yǔ)言上有更好的表現(xiàn)[77][78]。
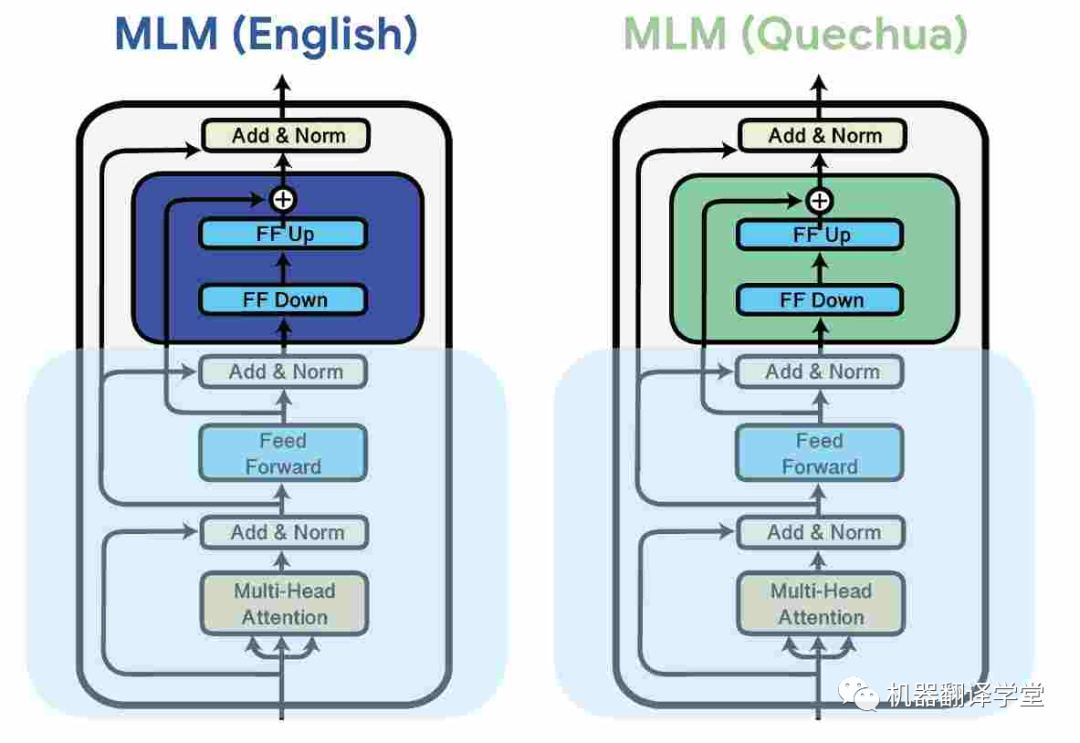
圖8.通過(guò)對(duì)每種語(yǔ)言的數(shù)據(jù)進(jìn)行掩碼語(yǔ)言建模 (MLM) 學(xué)習(xí)針對(duì)特定于語(yǔ)言的adapter,同時(shí)凍結(jié)模型的其余參數(shù)(Pfeiffer 等人,2020 年)。[79]
與對(duì)模型進(jìn)行微調(diào)[80]相比,adapter已被證明可以提高模型的魯棒性[81][82],從而提高學(xué)習(xí)效率,并且優(yōu)于其他參數(shù)高效方法[83][84]。
跨語(yǔ)言參數(shù)高效遷移學(xué)習(xí)不只有adapter,還可以采用其他形式[85],例如稀疏子網(wǎng)[86]。這些方法已被應(yīng)用于各種領(lǐng)域,比如機(jī)器翻譯[87][88]、ASR [89]和語(yǔ)音翻譯[90]。
挑戰(zhàn)3 語(yǔ)言類(lèi)型特征
與現(xiàn)實(shí)世界的語(yǔ)言分布相比,現(xiàn)有數(shù)據(jù)集中的語(yǔ)言分布嚴(yán)重偏斜,并且具有可用數(shù)據(jù)的語(yǔ)言不能代表世界上大多數(shù)語(yǔ)言。代表性不足的語(yǔ)言具有許多西方語(yǔ)言中不存在的語(yǔ)言特征比如聲調(diào),它存在于大約80%的非洲語(yǔ)言中。在Yorùbá中,詞匯音調(diào)區(qū)分了含義,例如,在以下單詞中:igbá(“葫蘆”,“籃子”),igba(“200”),ìgbà(“時(shí)間”),ìgbá(“花園雞蛋”)和igbà(“繩子”)。在阿坎語(yǔ)氣中,語(yǔ)法語(yǔ)氣區(qū)分習(xí)慣動(dòng)詞和狀態(tài)動(dòng)詞,例如Ama dá ha(“Ama睡在這里”)和Ama dàha(“Ama睡在這里”)。現(xiàn)有的NLP模型對(duì)于語(yǔ)言的音調(diào)研究還較少。
機(jī)遇3 特殊化處理
對(duì)于大多數(shù)代表性不足的語(yǔ)言,計(jì)算和數(shù)據(jù)是有限的。因此,將一定數(shù)量的先驗(yàn)知識(shí)納入我們的語(yǔ)言模型以使它們對(duì)這些語(yǔ)言更有用是合理的。
比如說(shuō)在tokenize的過(guò)程中,因?yàn)槊鎸?duì)具有豐富的詞匯形態(tài)或者有數(shù)據(jù)有限的語(yǔ)言,不夠好的tokenize方法會(huì)導(dǎo)致分詞結(jié)果較差。我們可以修改算法以首選多種語(yǔ)言共享的token[91],保留token的形態(tài)結(jié)構(gòu)[92],或者使tokenize的算法面對(duì)錯(cuò)誤的分割時(shí)更魯棒[93]。
除此之外,許多代表性不足的語(yǔ)言屬于類(lèi)似語(yǔ)言的群體,即某一個(gè)語(yǔ)系。因此,專(zhuān)注于這些語(yǔ)系的模型可以更容易地共享跨語(yǔ)言的信息。模型可以從相關(guān)語(yǔ)言的遷移學(xué)習(xí)中得到有用的知識(shí)。
過(guò)去的基于掩碼的一些算法對(duì)于多語(yǔ)言的學(xué)習(xí)有一定的效果,比如whole word masking[94]和PMI-masking[95],但考慮到語(yǔ)言的一些特征(如豐富的詞形結(jié)構(gòu)或語(yǔ)氣),融入這些特征的預(yù)訓(xùn)練目標(biāo)可能會(huì)使得模型能夠更高效地學(xué)習(xí)。比如在基尼亞盧旺達(dá)語(yǔ)的KinyaBERT模型[47]中,它調(diào)整了模型的結(jié)構(gòu)以融合有關(guān)語(yǔ)言形態(tài)的信息,使得模型在低資源但是詞形豐富的吉尼亞盧旺達(dá)語(yǔ)上有了更優(yōu)秀的翻譯結(jié)果。
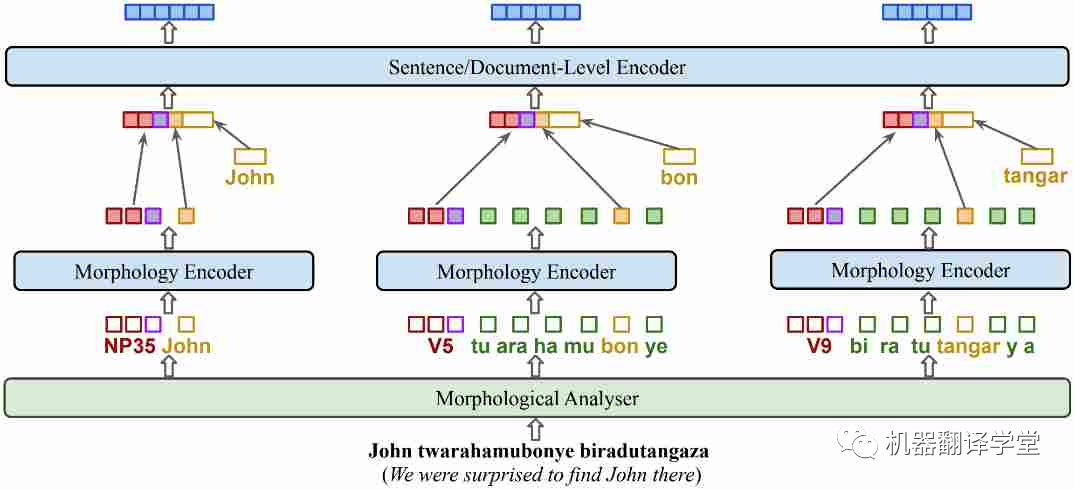
圖9.KinyaBERT模型。添加了針對(duì)不同詞形、單詞內(nèi)部結(jié)構(gòu)的encoder,對(duì) POS 標(biāo)簽、詞干和詞綴使用不同的嵌入
-05-
總結(jié)
雖然最近的多語(yǔ)言人工智能取得了巨大的進(jìn)展,但仍有很多任務(wù)作要做。最重要的是,我們應(yīng)該專(zhuān)注于創(chuàng)建反映語(yǔ)言用戶真實(shí)世界情況的數(shù)據(jù),并開(kāi)發(fā)滿足全球語(yǔ)言用戶需求的語(yǔ)言技術(shù)。雖然人們?cè)絹?lái)越意識(shí)到這項(xiàng)工作很重要,但需要一個(gè)團(tuán)體來(lái)為世界語(yǔ)言開(kāi)發(fā)公平的語(yǔ)言技術(shù)。Masakhane(祖魯語(yǔ)中的“讓我們一起建設(shè)”)!
審核編輯 :李倩
-
AI
+關(guān)注
關(guān)注
87文章
31513瀏覽量
270330 -
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
538瀏覽量
10341 -
自然語(yǔ)言處理
+關(guān)注
關(guān)注
1文章
619瀏覽量
13646
原文標(biāo)題:多語(yǔ)言AI的現(xiàn)狀
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
多語(yǔ)言開(kāi)發(fā)的流程詳解
這個(gè)多語(yǔ)言包 怎么搜不到
HarmonyOS低代碼開(kāi)發(fā)-多語(yǔ)言支持及屏幕適配
多語(yǔ)言綜合信息服務(wù)系統(tǒng)研究與設(shè)計(jì)
華碩 M3A78-EH主板多語(yǔ)言版說(shuō)明書(shū)
SoC多語(yǔ)言協(xié)同驗(yàn)證平臺(tái)技術(shù)研究
基于Toradex多語(yǔ)言image的編譯與MUI切換演示
Multilingual多語(yǔ)言預(yù)訓(xùn)練語(yǔ)言模型的套路
螞蟻集團(tuán)開(kāi)源高性能多語(yǔ)言序列化框架Fury解讀

基于LLaMA的多語(yǔ)言數(shù)學(xué)推理大模型
如何在TSMaster面板和工具箱中實(shí)現(xiàn)多語(yǔ)言切換

大語(yǔ)言模型(LLMs)如何處理多語(yǔ)言輸入問(wèn)題






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論