 深度剖析ARM內核寄存器及基本匯編語言3
深度剖析ARM內核寄存器及基本匯編語言3
三、代碼反匯編簡析
- 匯編 匯編文件轉換為目標文件(里面是機器碼,機器碼是給CPU使用的,燒錄保存在Flash空間的就是機器碼)。
- 反匯編 可執行文件(目標文件,里面是機器碼),轉換為匯編文件。
3.1 不同編譯器的反匯編
3.1.1 Keil下面生成反匯編文件
fromelf –text -a -c –output=(改成你想生成的反匯編名字一般是工程名字).dis (需要的axf文件,根據你工程生成axf的路徑填寫).axf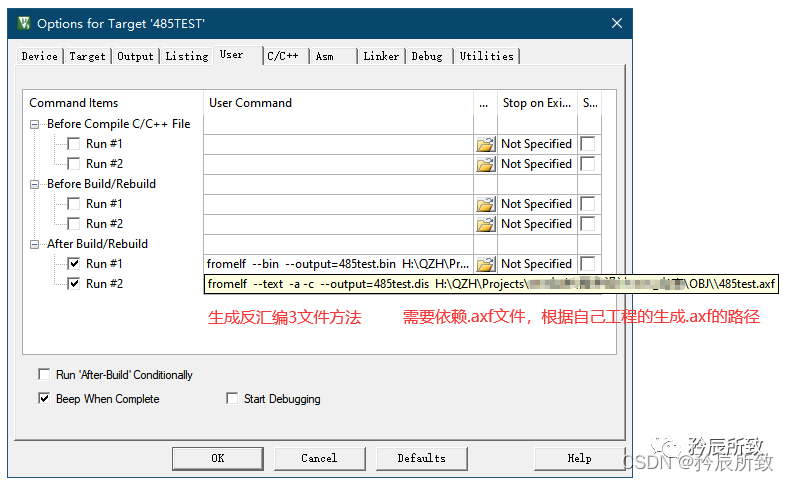 設置好以后編譯之后就會生成反匯編.dis文件:
設置好以后編譯之后就會生成反匯編.dis文件:
打開如下所示: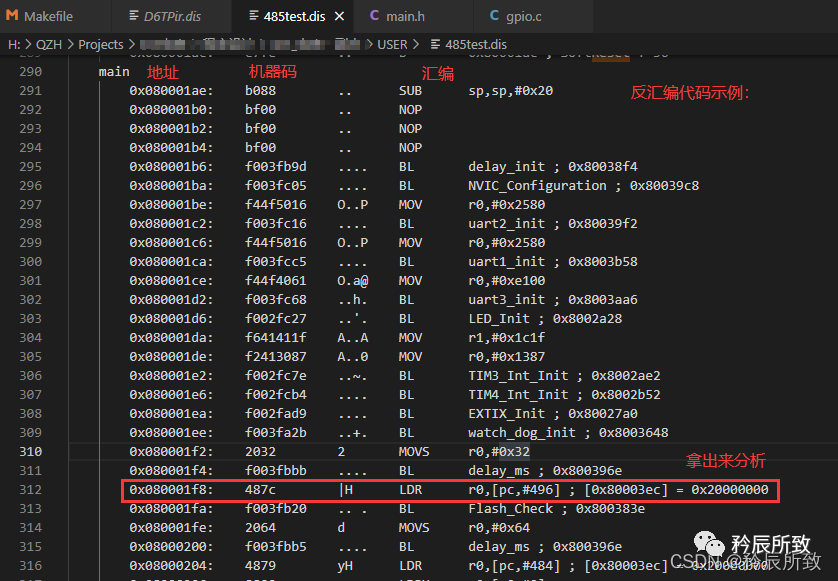 對于上圖中的紅色圈出來的語句,我們可以根據本文 第 二 章節的第2小節 ARM匯編格式中的介紹來分析一下:
對于上圖中的紅色圈出來的語句,我們可以根據本文 第 二 章節的第2小節 ARM匯編格式中的介紹來分析一下: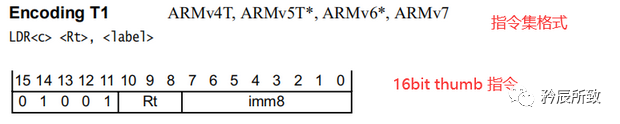
簡單分析如下(立即數就不分析了= =!):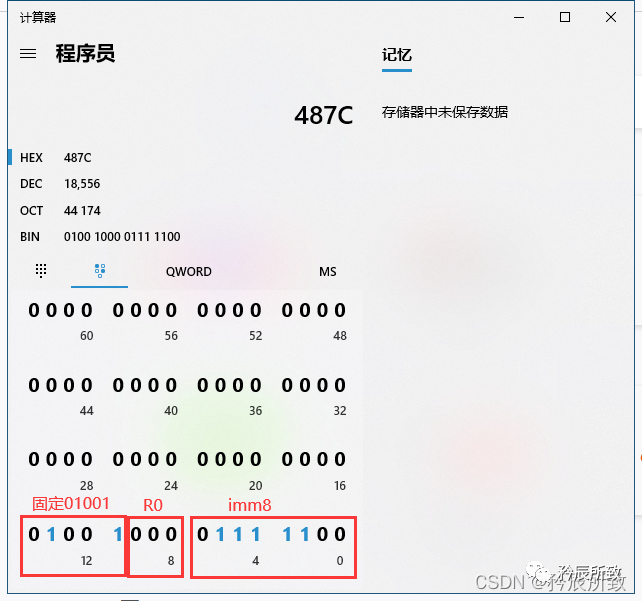
3.1.2 gcc下生成反匯編文件
- 使用交叉編譯工具鏈 指定-S選項可以生成匯編中間文件。ex:gcc -S test.c
- 使用 objdump 反匯編 arm二進制文件。
上述兩種方法的區別為:
(1)反匯編可以生成ARM指令操作碼,-S生成的匯編沒有指令碼 (2)反匯編的代碼是經過編譯器優化過的。(3)反匯編代碼量很大。
對于ARM Cortex-M,使用的是 arm-none-eabi-objdump,常用指令如下:
- arm-none-eabi-objdump -d -S(可省) a1.o 查看a1.o反匯編可執行段代碼
- arm-none-eabi-objdump -D -S(可省) a1.o 查看a1.o反匯編所有段代碼
- arm-none-eabi-objdump -D -b binary -m arm ab.bin 查看ab.bin反匯編所有代碼段
對于使用 arm-none-eabi-gcc 工具鏈(以STM32CUbeMX)的內核來說,使用如下方式生成反匯編文件:
$(OBJDUMP) -D -b binary -m arm (需要的elf文件,一般是工程名字).elf > (改成你想生成的反匯編名字,一般是工程名字).dis # OBJDUMP = arm-none-eabi-objdump
-D表示對全部文件進行反匯編,-b表示二進制,-m表示指令集架構
Makefile修改如下:
...
TARGET = D6TPir
#######################################
# paths
#######################################
# Build path
BUILD_DIR = build
...
PREFIX = arm-none-eabi-
...
OBJDUMP = $(PREFIX)objdump
dis:
$(OBJDUMP) -D -b binary -m arm $(BUILD_DIR)/$(TARGET).elf > $(BUILD_DIR)/$(TARGET).dis
# $(OBJDUMP) -D -b binary -m arm $(BUILD_DIR)/$(TARGET).bin > $(BUILD_DIR)/$(TARGET).dis
執行 make dis 即可生成 .dis 文件: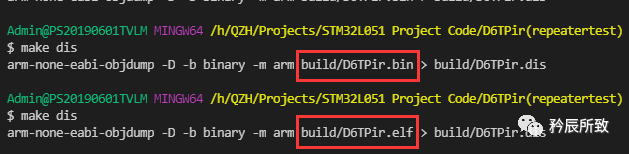
 打開文件查看,發現怎么這個匯編語言有點不一樣:
打開文件查看,發現怎么這個匯編語言有點不一樣: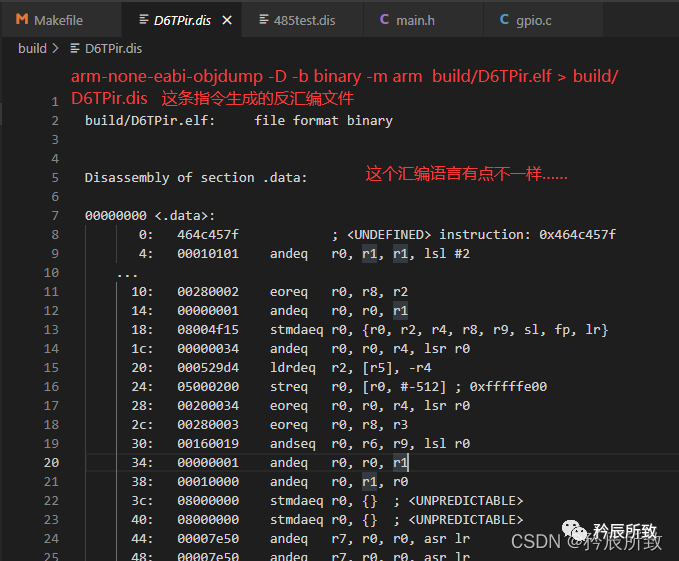 經過研究了一段時間,加上了
經過研究了一段時間,加上了-M force-thumb后稍微有點樣子了: ! 在網上有各種參考,但是我都測試過了,并沒有找到合適的生成完全和標準匯編一致的那種,-M后面的參數也不能亂加,需要根據自己的交叉編譯器,因為這里用的是 arm-none-eabi-gcc,所以可以通過
! 在網上有各種參考,但是我都測試過了,并沒有找到合適的生成完全和標準匯編一致的那種,-M后面的參數也不能亂加,需要根據自己的交叉編譯器,因為這里用的是 arm-none-eabi-gcc,所以可以通過arm-none-eabi-objdump --help 查看能用的命令和參數: gcc工具鏈下的匯編還是不太熟悉,所以我們下面反匯編文件與 C語言的對比,使用Keil下的反匯編進行說明。
3.2 C 和 匯編 比較分析
前面介紹了那么多,最終用一個簡單的程序對比一下C語言反匯編后的匯編語言,加深一下印象,當作個實戰總結。
基于STM32L051(Cortex-M0)內核,目的是為了比較C和匯編,用了個最簡單的程序來分析,沒有用到任務外設,程序如下:
//前面省略...
void delay(u32 count)
{
while(count--);
}
u32 add(u16 val1,u16 val2)
{
u32 add_val;
add_val = val1 + val2;
return add_val;
}
int main(void)
{
u16 a,b;
u32 c;
a = 12345;
b = 45678;
c = add(a,b);
while(1)
{
c--;
delay(200000);
}
}
反匯編的代碼對應部分如下(因為基于硬件平臺,其他異常中斷,堆,棧,包括其他一些也有匯編代碼,這里省略):
;省略前面
delay
0x080001ae: bf00 .. NOP
0x080001b0: 1e01 .. SUBS r1,r0,#0
0x080001b2: f1a00001 .... SUB r0,r0,#1
0x080001b6: d1fb .. BNE 0x80001b0 ; delay + 2
0x080001b8: 4770 pG BX lr
add
0x080001ba: 4602 .F MOV r2,r0
0x080001bc: 1850 P. ADDS r0,r2,r1
0x080001be: 4770 pG BX lr
main
0x080001c0: f2430439 C.9. MOV r4,#0x3039
0x080001c4: f24b256e K.n% MOV r5,#0xb26e
0x080001c8: 4629 )F MOV r1,r5
0x080001ca: 4620 F MOV r0,r4
0x080001cc: f7fffff5 .... BL add ; 0x80001ba
0x080001d0: 4606 .F MOV r6,r0
0x080001d2: e003 .. B 0x80001dc ; main + 28
0x080001d4: 1e76 v. SUBS r6,r6,#1
0x080001d6: 4804 .H LDR r0,[pc,#16] ; [0x80001e8] = 0x30d40
0x080001d8: f7ffffe9 .... BL delay ; 0x80001ae
0x080001dc: e7fa .. B 0x80001d4 ; main + 20
$d
0x080001de: 0000 .. DCW 0
0x080001e0: e000ed0c .... DCD 3758157068
0x080001e4: 05fa0000 .... DCD 100270080
0x080001e8: 00030d40 @... DCD 200000
;省略后面
3.2.1 MOV后面 立即數的疑問
在對比分析這段代碼前,在 main 函數中的第一句:
0x080001c0: f2430439 C.9. MOV r4,#0x3039
就有一個大大的疑問, MOV r4,#0x3039中 0x3039 并不是立即數(按照我們第二章 立即數的說明) ,包括接下來的 0xb26e 也不是立即數,怎么可以直接用 mov,按理來說需要用 LDR偽指令的??
至于這個問題,網上簡單查找了一下,找到一篇有關說明的文章:ARM 匯編的mov操作立即數的疑問 其中有說到,在 keil 公司方網站里關于arm匯編的說明里有這么一段:
Syntax MOV{cond} Rd, #imm16 where: imm16 is any value in the range 0-65535.
所以是不是在 Keil 中的arm匯編 立即數可以使16位的?
為了驗證一下,我稍微修改了一下程序,就是把a的值賦值超過16位(當然定義函數之類的也要跟著改,測試代碼中a為u16的無符號整形),測試了一下。
a賦值為 65535,結果如下(65535不是立即數,也可以直接mov):
0x080001c0: f64f75ff O..u MOV r5,#0xffff
a賦值為 65536,結果如下(65536是立即數,可以直接mov):
0x080001c0: f44f3580 O..5 MOV r5,#0x10000
a賦值為一個大于16位的,不是立即數的數,比如:0x1FFFF :
0x080001c0: 4d08 .M LDR r5,[pc,#32] ; [0x80001e4] = 0x1ffff
果然,最后當 a 大于16位,不是立即數時候,會使用偽指令 LDR,所以我們可以得出結論:
在 Keil 中的arm匯編中,16位內(包括16位)的數都直接使用 MOV 賦值,大于16位,如果是立即數,直接使用MOV,不是立即數用LDR (立即數的判斷方式還是前面講的那樣)
3.2.2 反匯編文件解析
對于上面的示例程序的匯編碼,簡單解析如下:添加一個有意思的測試對于
delay函數中的語句,上圖是while(count--);改成while(--count);后匯編代碼如下:
對于上面的測試程序,匯編中并沒有使用到 PUSH 和 POP 指令,因為程序太簡單了,不需要使用到棧,為了能夠熟悉下單片機中必須且經常需要用到的 棧,我們稍微修改一下add函數,在add函數中調用了delay函數:
u32 add(u16 val1,u16 val2)
{
u32 add_val;
add_val = val1 + val2;
delay(10);
return add_val;
}
對于的add函數匯編代碼如下:
add
0x080001ba: b530 0. PUSH {r4,r5,lr} ;把r4 r5 lr的值入棧
0x080001bc: 4603 .F MOV r3,r0
0x080001be: 460c .F MOV r4,r1
0x080001c0: 191d .. ADDS r5,r3,r4
0x080001c2: 200a . MOVS r0,#0xa
0x080001c4: f7fffff3 .... BL delay ; 0x80001ae
0x080001c8: 4628 (F MOV r0,r5
0x080001ca: bd30 0. POP {r4,r5,pc} ;把r4 r5 lr的值出棧,
(匯編中可以看到指令后面后面加了個S ,MOVS 、ADDS,這就是我們前面說到的,帶了S 會影響 xPSR 寄存器中的值)
可以看到,因為存在函數的多次調用,main函數中調用add函數,add函數中調用delay函數,所以在add函數運行之前,通過 push 把 r4,r5,lr 寄存器的值先存入棧中,等待程序執行完(函數調用結束)再吧 r4,r5,lr 寄存器的值恢復。
上面的程序雖然簡單,但是通過我們C程序 與 匯編程序的對比分析,能夠讓我們更加深入的理解匯編語言。
-
ARM
+關注
關注
134文章
9169瀏覽量
369239 -
寄存器
+關注
關注
31文章
5363瀏覽量
121194 -
PC
+關注
關注
9文章
2104瀏覽量
154679 -
匯編語言
+關注
關注
14文章
410瀏覽量
35962
發布評論請先 登錄
相關推薦
如何用C語言寄存器與匯編語言去實現流水燈
ARM匯編語言與指令格式資料分享
匯編語言教程-段寄存器的說明語句
[從零學習匯編語言] -寄存器詳解
![[從零學習<b class='flag-5'>匯編語言</b>] -<b class='flag-5'>寄存器</b>詳解](https://file.elecfans.com/web1/M00/D9/4E/pIYBAF_1ac2Ac0EEAABDkS1IP1s689.png)





 工商網監
工商網監
評論