 關于SQL優化的硬核文章
關于SQL優化的硬核文章
分享一篇關于SQL優化的硬核文章,全文有點長,建議收藏后慢慢看。
很多朋友在做數據分析時,分析兩分鐘,跑數兩小時?
在使用SQL過程中不僅要關注數據結果,同樣要注意SQL語句的執行效率。
本文涉及三部分:
- SQL介紹
- SQL優化方法
- SQL優化實例
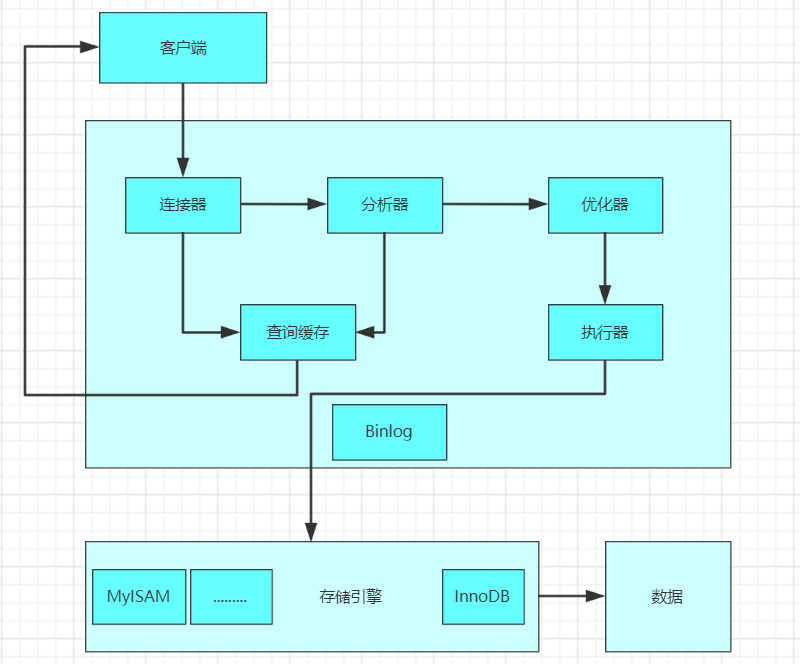
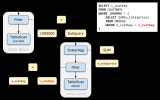
1、MySQL的基本架構
1)MySQL的基礎架構圖
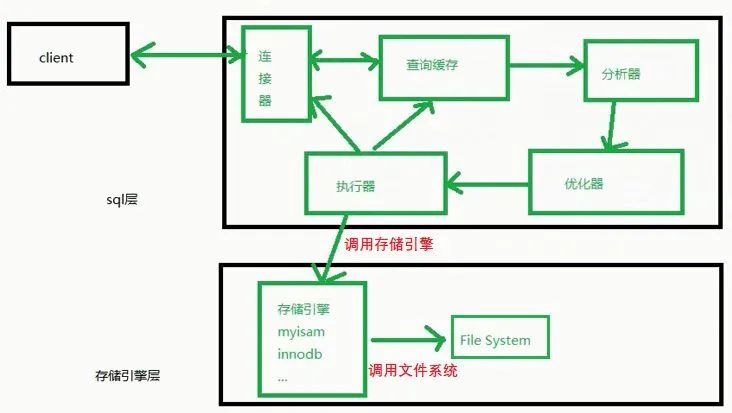
左邊的client可以看成是客戶端,客戶端有很多,像我們經常你使用的CMD黑窗口,像我們經常用于學習的WorkBench,像企業經常使用的Navicat工具,它們都是一個客戶端。右邊的這一大堆都可以看成是Server(MySQL的服務端),我們將Server在細分為sql層和存儲引擎層。
當查詢出數據以后,會返回給執行器。執行器一方面將結果寫到查詢緩存里面,當你下次再次查詢的時候,就可以直接從查詢緩存中獲取到數據了。另一方面,直接將結果響應回客戶端。
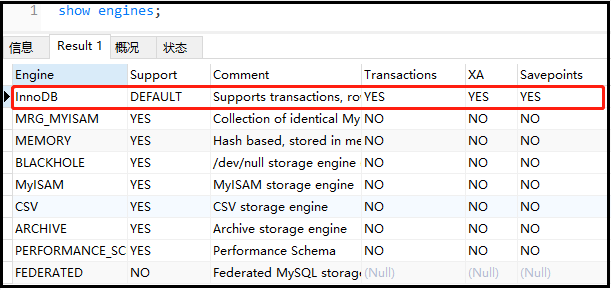
2)查詢數據庫的引擎
① show engines;
② show variables like “%storage_engine%”;
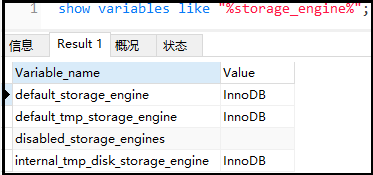
3)指定數據庫對象的存儲引擎
createtabletb(
idint(4)auto_increment,
namevarchar(5),
deptvarchar(5),
primarykey(id)
)engine=myISAMauto_increment=1defaultcharset=utf8;
SQL優化
1)為什么需要進行SQL優化?
在進行多表連接查詢、子查詢等操作的時候,由于你寫出的SQL語句欠佳,導致的服務器執行時間太長,我們等待結果的時間太長。基于此,我們需要學習怎么優化SQL。
2)mysql的編寫過程和解析過程
① 編寫過程
selectdinstinct..from..join..on..where..groupby..having..orderby..limit..
② 解析過程
from..on..join..where..groupby..having..selectdinstinct..orderby..limit..
提供一個網站,詳細說明了mysql解析過程:
https://www.cnblogs.com/annsshadow/p/5037667.html
3)SQL優化—主要就是優化索引
優化SQL,最重要的就是優化SQL索引。
索引相當于字典的目錄。利用字典目錄查找漢字的過程,就相當于利用SQL索引查找某條記錄的過程。有了索引,就可以很方便快捷的定位某條記錄。
① 什么是索引?
索引就是幫助MySQL高效獲取數據的一種【數據結構】。索引是一種樹結構,MySQL中一般用的是【B+樹】。
② 索引圖示說明(這里用二叉樹來幫助我們理解索引)
樹形結構的特點是:子元素比父元素小的,放在左側;子元素比父元素大的,放在右側。
這個圖示只是為了幫我們簡單理解索引的,真實的關于【B+樹】的說明,我們會在下面進行說明。
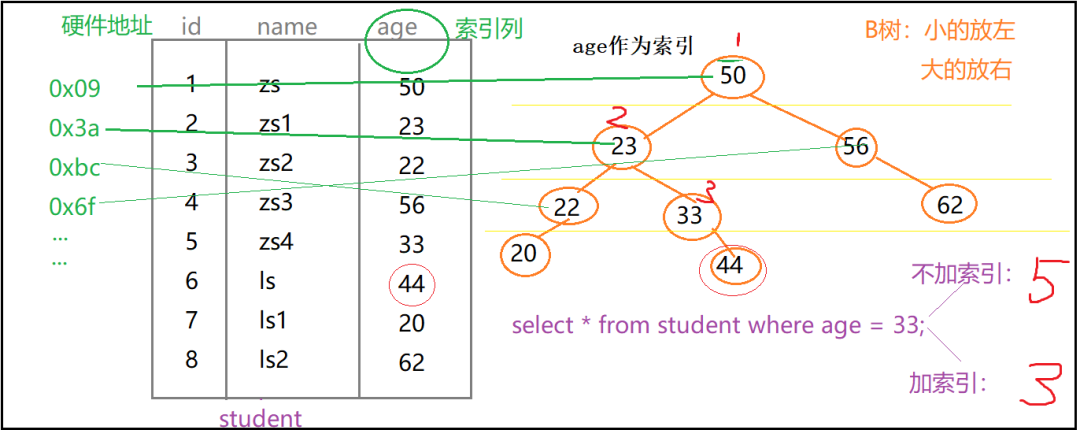
索引是怎么查找數據的呢?兩個字【指向】,上圖中我們給age列指定了一個索引,即類似于右側的這種樹形結構。mysql表中的每一行記錄都有一個硬件地址,例如索引中的age=50,指向的就是源表中該行的標識符(“硬件地址”)。
也就是說,樹形索引建立了與源表中每行記錄硬件地址的映射關系,當你指定了某個索引,這種映射關系也就建成了,這就是為什么我們可以通過索引快速定位源表中記錄的原因。
以【select * from student where age=33】查詢語句為例。當我們不加索引的時候,會從上到下掃描源表,當掃描到第5行的時候,找到了我們想要找到了元素,一共是查詢了5次。
當添加了索引以后,就直接在樹形結構中進行查找,33比50小,就從左側查詢到了23,33大于23,就又查詢到了右側,這下找到了33,整個索引結束,一共進行了3次查找。是不是很方便,假如我們此時需要查找age=62,你再想想“添加索引”前后,查找次數的變化情況。
4)索引的弊端
1.當數據量很大的時候,索引也會很大(當然相比于源表來說,還是相當小的),也需要存放在內存/硬盤中(通常存放在硬盤中),占據一定的內存空間/物理空間。
2.索引并不適用于所有情況:a.少量數據;b.頻繁進行改動的字段,不適合做索引;c.很少使用的字段,不需要加索引;
3.索引會提高數據查詢效率,但是會降低“增、刪、改”的效率。當不使用索引的時候,我們進行數據的增刪改,只需要操作源表即可,但是當我們添加索引后,不僅需要修改源表,也需要再次修改索引,很麻煩。盡管是這樣,添加索引還是很劃算的,因為我們大多數使用的就是查詢,“查詢”對于程序的性能影響是很大的。
5)索引的優勢
1.提高查詢效率(降低了IO使用率)。當創建了索引后,查詢次數減少了。
2.降低CPU使用率。比如說【…order by age desc】這樣一個操作,當不加索引,會把源表加載到內存中做一個排序操作,極大的消耗了資源。但是使用了索引以后,第一索引本身就小一些,第二索引本身就是排好序的,左邊數據最小,右邊數據最大。
6)B+樹圖示說明
MySQL中索引使用的就是B+樹結構。
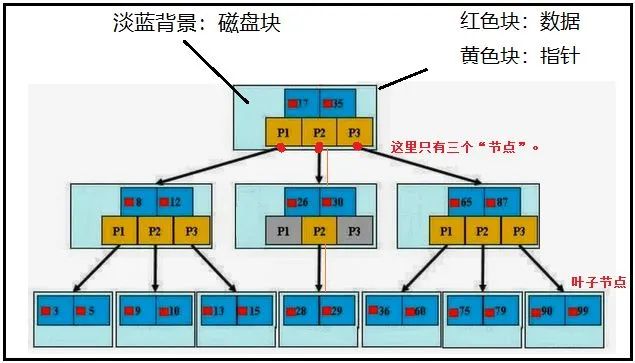
關于B+樹的說明:
首先,Btree一般指的都是【B+樹】,數據全部存放在葉子節點中。對于上圖來說,最下面的第3層,屬于葉子節點,真實數據部份都是存放在葉子節點當中的。
那么對于第1、2層中的數據又是干嘛的呢?答:用于分割指針塊兒的,比如說小于26的找P1,介于26-30之間的找P2,大于30的找P3。
其次,三層【B+樹】可以存放上百萬條數據。這么多數據怎么放的呢?增加“節點數”。圖中我們只有三個節點。
最后,【B+樹】中查詢任意數據的次數,都是n次,n表示的是【B+樹】的高度。
3、索引的分類與創建
1)索引分類
單值索引
唯一索引
復合索引
① 單值索引
利用表中的某一個字段創建單值索引。一張表中往往有多個字段,也就是說每一列其實都可以創建一個索引,這個根據我們實際需求來進行創建。還需要注意的一點就是,一張表可以創建多個“單值索引”。
假如某一張表既有age字段,又有name字段,我們可以分別對age、name創建一個單值索引,這樣一張表就有了兩個單值索引。
② 唯一索引
也是利用表中的某一個字段創建單值索引,與單值索引不同的是:創建唯一索引的字段中的數據,不能有重復值。像age肯定有很多人的年齡相同,像name肯定有些人是重名的,因此都不適合創建“唯一索引”。像編號id、學號sid,對于每個人都不一樣,因此可以用于創建唯一索引。
③ 復合索引
多個列共同構成的索引。比如說我們創建這樣一個“復合索引”(name,age),先利用name進行索引查詢,當name相同的時候,我們利用age再進行一次篩選。注意:復合索引的字段并不是非要都用完,當我們利用name字段索引出我們想要的結果以后,就不需要再使用age進行再次篩選了。
2)創建索引
① 語法
語法:create 索引類型 索引名 on 表(字段);
建表語句如下:
查詢表結構如下:
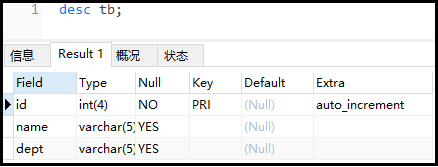
② 創建索引的第一種方式
Ⅰ 創建單值索引
createindexdept_indexontb(dept);
Ⅱ 創建唯一索引:這里我們假定name字段中的值都是唯一的
createuniqueindexname_indexontb(name);
Ⅲ 創建復合索引
createindexdept_name_indexontb(dept,name);
③ 創建索引的第二種方式
先刪除之前創建的索引以后,再進行這種創建索引方式的測試;
語法:alter table 表名 add 索引類型 索引名(字段)
Ⅰ 創建單值索引
altertabletbaddindexdept_index(dept);
Ⅱ 創建唯一索引:這里我們假定name字段中的值都是唯一的
altertabletbadduniqueindexname_index(name);
Ⅲ 創建復合索引
altertabletbaddindexdept_name_index(dept,name);
④ 補充說明
如果某個字段是primary key,那么該字段默認就是主鍵索引。
主鍵索引和唯一索引非常相似。相同點:該列中的數據都不能有相同值;不同點:主鍵索引不能有null值,但是唯一索引可以有null值。
3)索引刪除和索引查詢
① 索引刪除
語法:drop index 索引名 on 表名;
dropindexname_indexontb;
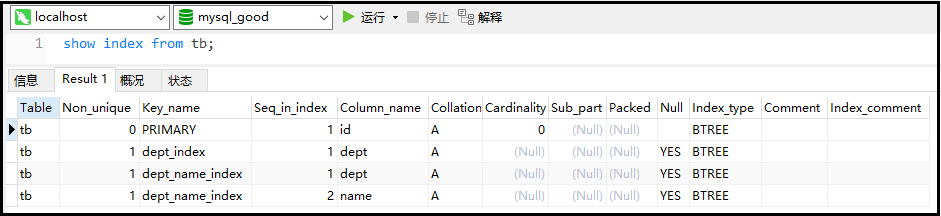
② 索引查詢
語法:show index from 表名;
showindexfromtb;
結果如下:
4、SQL性能問題的探索
人為優化: 需要我們使用explain分析SQL的執行計劃。該執行計劃可以模擬SQL優化器執行SQL語句,可以幫助我們了解到自己編寫SQL的好壞。
SQL優化器自動優化: 最開始講述MySQL執行原理的時候,我們已經知道MySQL有一個優化器,當你寫了一個SQL語句的時候,SQL優化器如果認為你寫的SQL語句不夠好,就會自動寫一個好一些的等價SQL去執行。
SQL優化器自動優化功能【會干擾】我們的人為優化功能。當我們查看了SQL執行計劃以后,如果寫的不好,我們會去優化自己的SQL。當我們以為自己優化的很好的時候,最終的執行計劃,并不是按照我們優化好的SQL語句來執行的,而是有時候將我們優化好的SQL改變了,去執行。
SQL優化是一種概率問題,有時候系統會按照我們優化好的SQL去執行結果(優化器覺得你寫的差不多,就不會動你的SQL)。有時候優化器仍然會修改我們優化好的SQL,然后再去執行。
1)查看執行計劃
語法:explain + SQL語句
eg:explain select * from tb;
2)“執行計劃”中需要知道的幾個“關鍵字”
id :編號
select_type :查詢類型
table :表
type :類型
possible_keys :預測用到的索引
key :實際使用的索引
key_len :實際使用索引的長度
ref :表之間的引用
rows :通過索引查詢到的數據量
Extra :額外的信息
建表語句和插入數據:
#建表語句
createtablecourse
(
cidint(3),
cnamevarchar(20),
tidint(3)
);
createtableteacher
(
tidint(3),
tnamevarchar(20),
tcidint(3)
);
createtableteacherCard
(
tcidint(3),
tcdescvarchar(200)
);
#插入數據
insertintocoursevalues(1,'java',1);
insertintocoursevalues(2,'html',1);
insertintocoursevalues(3,'sql',2);
insertintocoursevalues(4,'web',3);
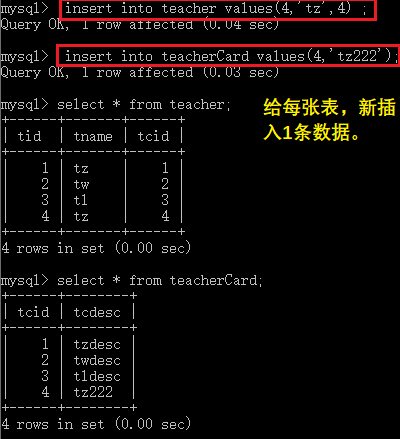
insertintoteachervalues(1,'tz',1);
insertintoteachervalues(2,'tw',2);
insertintoteachervalues(3,'tl',3);
insertintoteacherCardvalues(1,'tzdesc');
insertintoteacherCardvalues(2,'twdesc');
insertintoteacherCardvalues(3,'tldesc');
explain執行計劃常用關鍵字詳解
1)id關鍵字的使用說明
① 案例:查詢課程編號為2 或 教師證編號為3 的老師信息:
#查看執行計劃
explainselectt.*
fromteachert,coursec,teacherCardtc
wheret.tid=c.tidandt.tcid=tc.tcid
and(c.cid=2ortc.tcid=3);
結果如下:

接著,在往teacher表中增加幾條數據。
insertintoteachervalues(4,'ta',4);
insertintoteachervalues(5,'tb',5);
insertintoteachervalues(6,'tc',6);
再次查看執行計劃。
#查看執行計劃
explainselectt.*
fromteachert,coursec,teacherCardtc
wheret.tid=c.tidandt.tcid=tc.tcid
and(c.cid=2ortc.tcid=3);
結果如下:

表的執行順序 ,因表數量改變而改變的原因:笛卡爾積。
abc
234
最終:2 * 3 * 4 = 6 * 4 = 24
cba
432
最終:4 * 3 * 2 = 12 * 2 = 24
分析:最終執行的條數,雖然是一致的。但是中間過程,有一張臨時表是6,一張臨時表是12,很明顯6 < 12,對于內存來說,數據量越小越好,因此優化器肯定會選擇第一種執行順序。
結論:id值相同,從上往下順序執行。表的執行順序因表數量的改變而改變。
② 案例:查詢教授SQL課程的老師的描述(desc)
#查看執行計劃
explainselecttc.tcdescfromteacherCardtc
wheretc.tcid=
(
selectt.tcidfromteachert
wheret.tid=
(selectc.tidfromcoursecwherec.cname='sql')
);
結果如下:

結論:id值不同,id值越大越優先查詢。這是由于在進行嵌套子查詢時,先查內層,再查外層。
③ 針對②做一個簡單的修改
#查看執行計劃
explainselectt.tname,tc.tcdescfromteachert,teacherCardtc
wheret.tcid=tc.tcid
andt.tid=(selectc.tidfromcoursecwherecname='sql');
結果如下:

結論:id值有相同,又有不同。id值越大越優先;id值相同,從上往下順序執行。
2)select_type關鍵字的使用說明:查詢類型
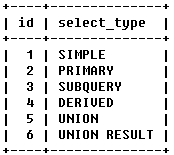
① simple:簡單查詢
不包含子查詢,不包含union查詢。
explainselect*fromteacher;
結果如下:

② primary:包含子查詢的主查詢(最外層)
③ subquery:包含子查詢的主查詢(非最外層)
④ derived:衍生查詢(用到了臨時表)
a.在from子查詢中,只有一張表;
b.在from子查詢中,如果table1 union table2,則table1就是derived表;
explainselectcr.cname
from(select*fromcoursewheretid=1unionselect*fromcoursewheretid=2)cr;
結果如下:

⑤ union:union之后的表稱之為union表,如上例
⑥ union result:告訴我們,哪些表之間使用了union查詢
3)type關鍵字的使用說明:索引類型
system、const只是理想狀況,實際上只能優化到index --> range --> ref這個級別。要對type進行優化的前提是,你得創建索引。
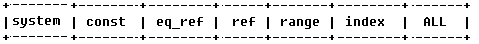
① system
源表只有一條數據(實際中,基本不可能);
衍生表只有一條數據的主查詢(偶爾可以達到)。
② const
僅僅能查到一條數據的SQL ,僅針對Primary key或unique索引類型有效。
explainselecttidfromtest01wheretid=1;
結果如下:

刪除以前的主鍵索引后,此時我們添加一個其他的普通索引:
createindextest01_indexontest01(tid);
#再次查看執行計劃
explainselecttidfromtest01wheretid=1;
結果如下:

③ eq_ref
唯一性索引,對于每個索引鍵的查詢,返回匹配唯一行數據(有且只有1個,不能多 、不能0),并且查詢結果和數據條數必須一致。
此種情況常見于唯一索引和主鍵索引。
deletefromteacherwheretcid>=4;
altertableteacherCardaddconstraintpk_tcidprimarykey(tcid);
altertableteacheraddconstraintuk_tciduniqueindex(tcid);
explainselectt.tcidfromteachert,teacherCardtcwheret.tcid=tc.tcid;
結果如下:

總結:以上SQL,用到的索引是t.tcid,即teacher表中的tcid字段;如果teacher表的數據個數和連接查詢的數據個數一致(都是3條數據),則有可能滿足eq_ref級別;否則無法滿足。條件很苛刻,很難達到。
④ ref
非唯一性索引,對于每個索引鍵的查詢,返回匹配的所有行(可以0,可以1,可以多)
準備數據:
創建索引,并查看執行計劃:
#添加索引
altertableteacheraddindexindex_name(tname);
#查看執行計劃
explainselect*fromteacherwheretname='tz';
結果如下:

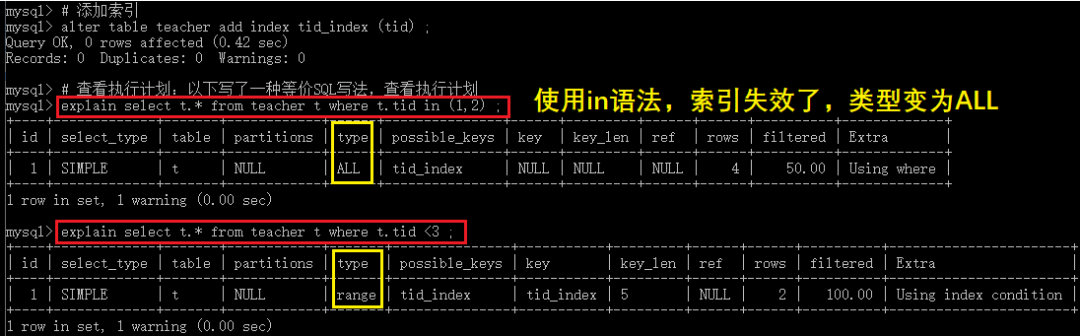
⑤ range
檢索指定范圍的行 ,where后面是一個范圍查詢(between, >, <, >=, in)
in有時候會失效,從而轉為無索引時候的ALL
#添加索引
altertableteacheraddindextid_index(tid);
#查看執行計劃:以下寫了一種等價SQL寫法,查看執行計劃
explainselectt.*fromteachertwheret.tidin(1,2);
explainselectt.*fromteachertwheret.tid<3?;
結果如下:
⑥ index
查詢全部索引中的數據(掃描整個索引)
⑦ ALL
查詢全部源表中的數據(暴力掃描全表)
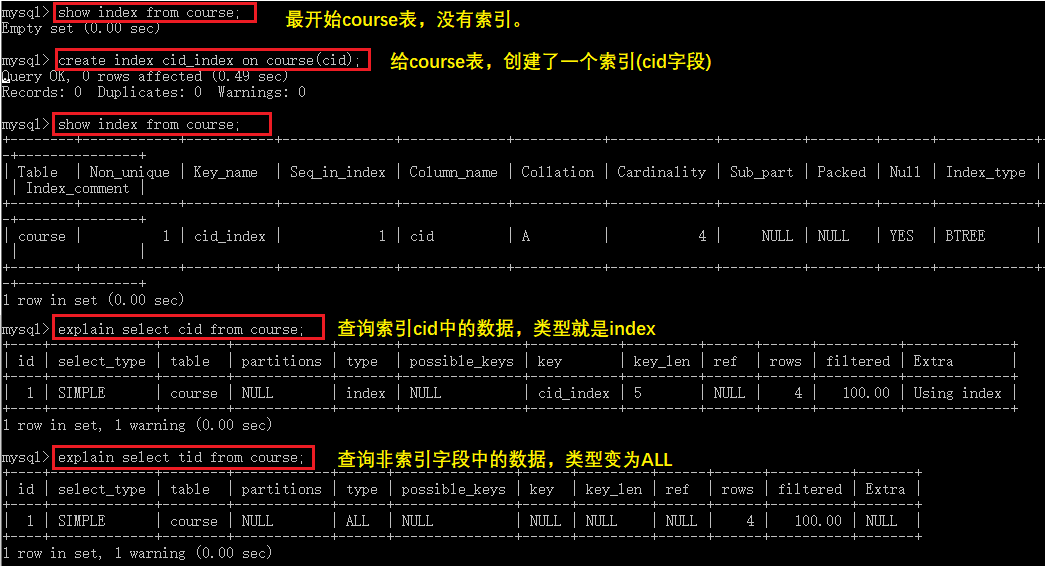
注意:cid是索引字段,因此查詢索引字段,只需要掃描索引表即可。但是tid不是索引字段,查詢非索引字段,需要暴力掃描整個源表,會消耗更多的資源。
4)possible_keys和key
possible_keys可能用到的索引。是一種預測,不準。了解一下就好。
key指的是實際使用的索引。
#先給course表的cname字段,添加一個索引
createindexcname_indexoncourse(cname);
#查看執行計劃
explainselectt.tname,tc.tcdescfromteachert,teacherCardtc
wheret.tcid=tc.tcid
andt.tid=(selectc.tidfromcoursecwherecname='sql');
結果如下:

有一點需要注意的是:如果possible_key/key是NULL,則說明沒用索引。
5)key_len
索引的長度,用于判斷復合索引是否被完全使用(a,b,c)。
① 新建一張新表,用于測試
#創建表
createtabletest_kl
(
namechar(20)notnulldefault''
);
#添加索引
altertabletest_kladdindexindex_name(name);
#查看執行計劃
explainselect*fromtest_klwherename='';
結果如下:
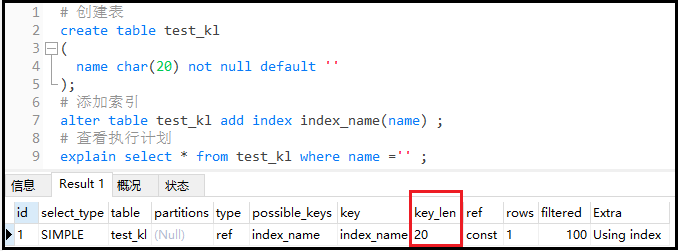
結果分析:因為我沒有設置服務端的字符集,因此默認的字符集使用的是latin1,對于latin1一個字符代表一個字節,因此這列的key_len的長度是20,表示使用了name這個索引。
② 給test_kl表,新增name1列,該列沒有設置“not null”
結果如下:
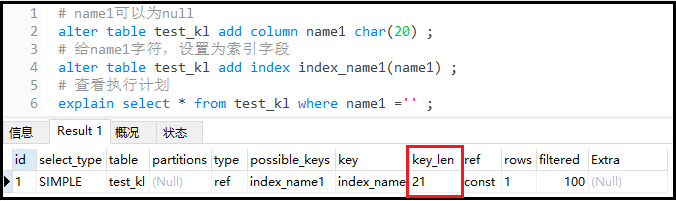
結果分析:如果索引字段可以為null,則mysql底層會使用1個字節用于標識。
③ 刪除原來的索引name和name1,新增一個復合索引
#刪除原來的索引name和name1
dropindexindex_nameontest_kl;
dropindexindex_name1ontest_kl;
#增加一個復合索引
createindexname_name1_indexontest_kl(name,name1);
#查看執行計劃
explainselect*fromtest_klwherename1='';--121
explainselect*fromtest_klwherename='';--60
結果如下:
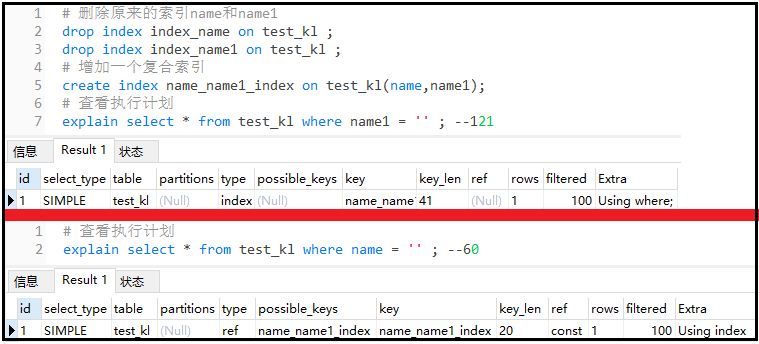
結果分析: 對于下面這個執行計劃,可以看到我們只使用了復合索引的第一個索引字段name,因此key_len是20,這個很清楚。再看上面這個執行計劃,我們雖然僅僅在where后面使用了復合索引字段中的name1字段,但是你要使用復合索引的第2個索引字段,會默認使用了復合索引的第1個索引字段name,由于name1可以是null,因此key_len = 20 + 20 + 1 = 41呀!
④ 再次怎加一個name2字段,并為該字段創建一個索引。
不同的是:該字段數據類型是varchar
#新增一個字段name2,name2可以為null
altertabletest_kladdcolumnname2varchar(20);
#給name2字段,設置為索引字段
altertabletest_kladdindexname2_index(name2);
#查看執行計劃
explainselect*fromtest_klwherename2='';
結果如下:
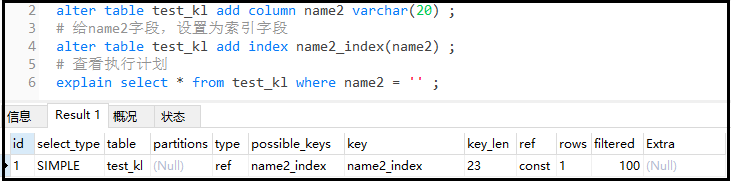
結果分析: key_len = 20 + 1 + 2,這個20 + 1我們知道,這個2又代表什么呢?原來varchar屬于可變長度,在mysql底層中,用2個字節標識可變長度。
6)ref
這里的ref的作用,指明當前表所參照的字段。
注意與type中的ref值區分。在type中,ref只是type類型的一種選項值。
#給course表的tid字段,添加一個索引
createindextid_indexoncourse(tid);
#查看執行計劃
explainselect*fromcoursec,teachert
wherec.tid=t.tid
andt.tname='tw';
結果如下:
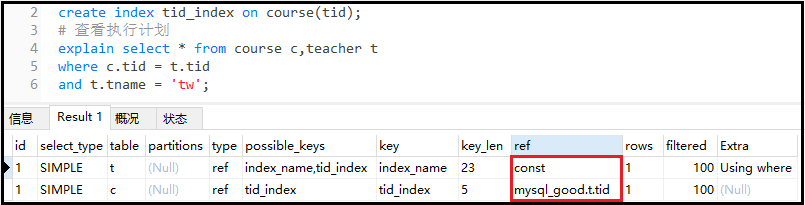
結果分析: 有兩個索引,c表的c.tid引用的是t表的tid字段,因此可以看到顯示結果為【數據庫名.t.tid】,t表的t.name引用的是一個常量"tw",因此可以看到結果顯示為const,表示一個常量。
7)rows(這個目前還是有點疑惑)
被索引優化查詢的數據個數 (實際通過索引而查詢到的數據個數)
explainselect*
fromcoursec,teachert
wherec.tid=t.tid
andt.tname='tz';
結果如下:
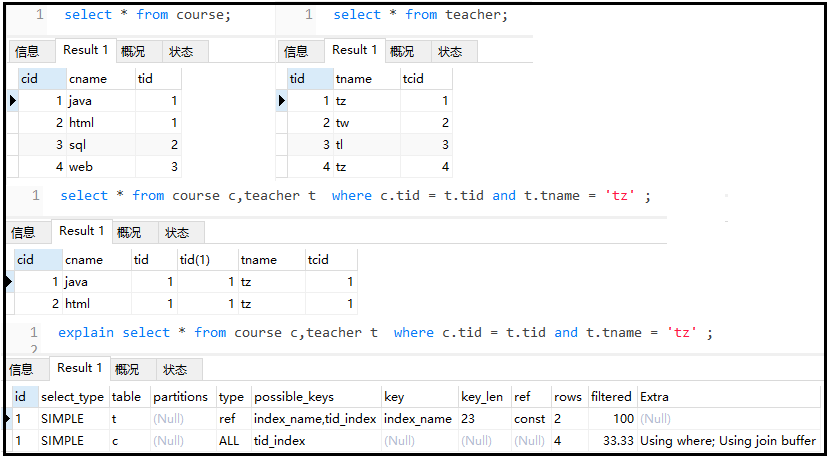
8)extra
表示其他的一些說明,也很有用。
① using filesort:針對單索引的情況
當出現了這個詞,表示你當前的SQL性能消耗較大。表示進行了一次“額外”的排序。常見于order by語句中。
Ⅰ 什么是“額外”的排序?
為了講清楚這個,我們首先要知道什么是排序。我們為了給某一個字段進行排序的時候,首先你得先查詢到這個字段,然后在將這個字段進行排序。
緊接著,我們查看如下兩個SQL語句的執行計劃。
#新建一張表,建表同時創建索引
createtabletest02
(
a1char(3),
a2char(3),
a3char(3),
indexidx_a1(a1),
indexidx_a2(a2),
indexidx_a3(a3)
);
#查看執行計劃
explainselect*fromtest02wherea1=''orderbya1;
explainselect*fromtest02wherea1=''orderbya2;
結果如下:

結果分析: 對于第一個執行計劃,where后面我們先查詢了a1字段,然后再利用a1做了依次排序,這個很輕松。但是對于第二個執行計劃,where后面我們查詢了a1字段,然而利用的卻是a2字段進行排序,此時myql底層會進行一次查詢,進行“額外”的排序。
總結:對于單索引,如果排序和查找是同一個字段,則不會出現using filesort;如果排序和查找不是同一個字段,則會出現using filesort;因此where哪些字段,就order by哪些些字段。
② using filesort:針對復合索引的情況
不能跨列(官方術語:最佳左前綴)
#刪除test02的索引
dropindexidx_a1ontest02;
dropindexidx_a2ontest02;
dropindexidx_a3ontest02;
#創建一個復合索引
altertabletest02addindexidx_a1_a2_a3(a1,a2,a3);
#查看下面SQL語句的執行計劃
explainselect*fromtest02wherea1=''orderbya3;--usingfilesort
explainselect*fromtest02wherea2=''orderbya3;--usingfilesort
explainselect*fromtest02wherea1=''orderbya2;
結果如下:
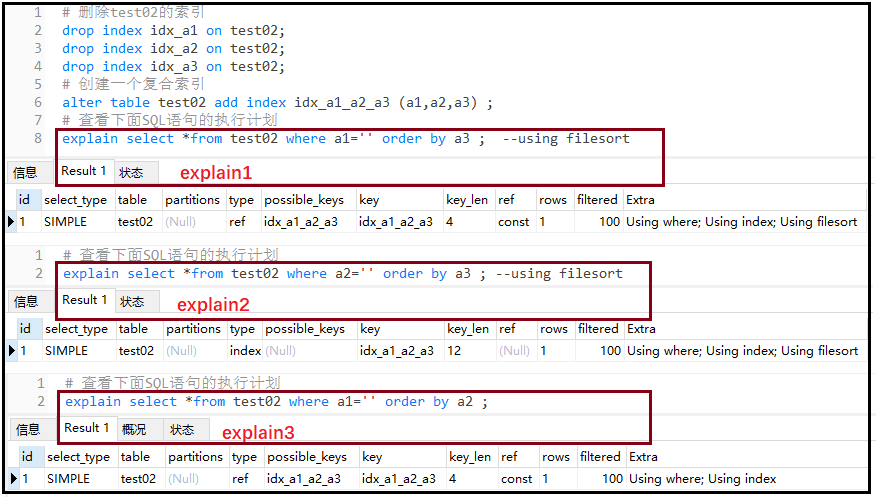
結果分析: 復合索引的順序是(a1,a2,a3),可以看到a1在最左邊,因此a1就叫做“最佳左前綴”,如果要使用后面的索引字段,必須先使用到這個a1字段。對于explain1,where后面我們使用a1字段,但是后面的排序使用了a3,直接跳過了a2,屬于跨列;對于explain2,where后面我們使用了a2字段,直接跳過了a1字段,也屬于跨列;對于explain3,where后面我們使用a1字段,后面使用的是a2字段,因此沒有出現【using filesort】。
③ using temporary
當出現了這個詞,也表示你當前的SQL性能消耗較大。這是由于當前SQL用到了臨時表。一般出現在group by中。
explainselecta1fromtest02wherea1in('1','2','3')groupbya1;
explainselecta1fromtest02wherea1in('1','2','3')groupbya2;--usingtemporary
結果如下:
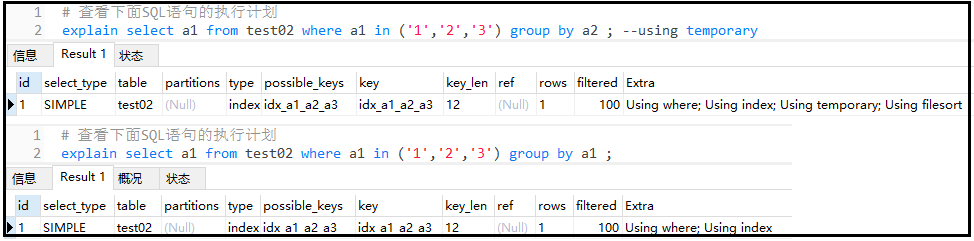
結果分析: 當你查詢哪個字段,就按照那個字段分組,否則就會出現using temporary。
針對using temporary,我們在看一個例子:
using temporary表示需要額外再使用一張表,一般出現在group by語句中。雖然已經有表了,但是不適用,必須再來一張表。
再次來看mysql的編寫過程和解析過程。
Ⅰ 編寫過程
selectdinstinct..from..join..on..where..groupby..having..orderby..limit..
Ⅱ 解析過程
from..on..join..where..groupby..having..selectdinstinct..orderby..limit..
很顯然,where后是group by,然后才是select。基于此,我們再查看如下兩個SQL語句的執行計劃。
explainselect*fromtest03wherea2=2anda4=4groupbya2,a4;
explainselect*fromtest03wherea2=2anda4=4groupbya3;
分析如下: 對于第一個執行計劃,where后面是a2和a4,接著我們按照a2和a4分組,很明顯這兩張表已經有了,直接在a2和a4上分組就行了。但是對于第二個執行計劃,where后面是a2和a4,接著我們卻按照a3分組,很明顯我們沒有a3這張表,因此有需要再來一張臨時表a3。因此就會出現using temporary。
④ using index
當你看到這個關鍵詞,恭喜你,表示你的SQL性能提升了。
using index稱之為“索引覆蓋”。
當出現了using index,就表示不用讀取源表,而只利用索引獲取數據,不需要回源表查詢。
只要使用到的列,全部出現在索引中,就是索引覆蓋。
#刪除test02中的復合索引idx_a1_a2_a3
dropindexidx_a1_a2_a3ontest02;
#重新創建一個復合索引
idx_a1_a2createindexidx_a1_a2ontest02(a1,a2);
#查看執行計劃
explainselecta1,a3fromtest02wherea1=''ora3='';
explainselecta1,a2fromtest02wherea1=''anda2='';
結果如下:
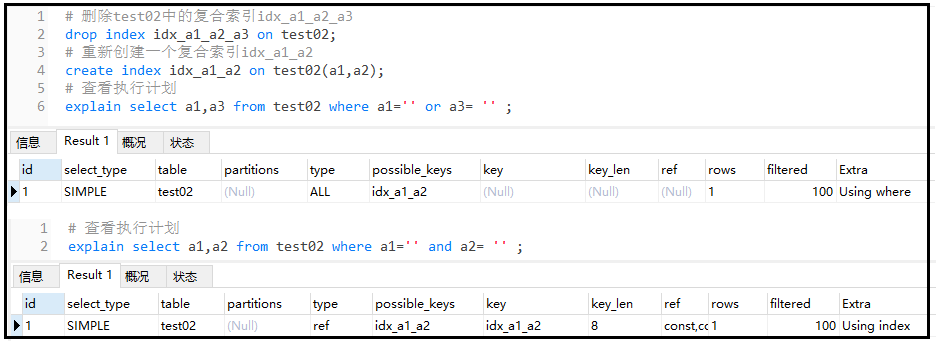
結果分析: 我們創建的是a1和a2的復合索引,對于第一個執行計劃,我們卻出現了a3,該字段并沒有創建索引,因此沒有出現using index,而是using where,表示我們需要回表查詢。對于第二個執行計劃,屬于完全的索引覆蓋,因此出現了using index。
針對using index,我們在查看一個案例:
explainselecta1,a2fromtest02wherea1=''ora2='';
explainselecta1,a2fromtest02;
結果如下:
如果用到了索引覆蓋(using index時),會對possible_keys和key造成影響:
a.如果沒有where,則索引只出現在key中;
b.如果有where,則索引 出現在key和possible_keys中。
⑤ using where
表示需要【回表查詢】,表示既在索引中進行了查詢,又回到了源表進行了查詢。
#刪除test02中的復合索引idx_a1_a2
dropindexidx_a1_a2ontest02;
#將a1字段,新增為一個索引
createindexa1_indexontest02(a1);
#查看執行計劃
explainselecta1,a3fromtest02wherea1=""anda3="";
結果如下:

結果分析: 我們既使用了索引a1,表示我們使用了索引進行查詢。但是又對于a3字段,我們并沒有使用索引,因此對于a3字段,需要回源表查詢,這個時候出現了using where。
⑥ impossible where(了解)
當where子句永遠為False的時候,會出現impossible where
#查看執行計劃
explainselecta1fromtest02wherea1="a"anda1="b";
結果如下:

6、優化示例
1)引入案例
#創建新表
createtabletest03
(
a1int(4)notnull,
a2int(4)notnull,
a3int(4)notnull,
a4int(4)notnull
);
#創建一個復合索引
createindexa1_a2_a3_test03ontest03(a1,a2,a3);
#查看執行計劃
explainselecta3fromtest03wherea1=1anda2=2anda3=3;
結果如下:
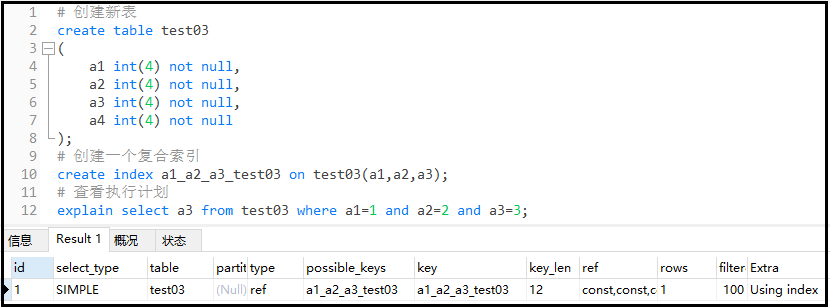
推薦寫法: 復合索引順序和使用順序一致。
下面看看【不推薦寫法】:復合索引順序和使用順序不一致。
#查看執行計劃
explainselecta3fromtest03wherea3=1anda2=2anda1=3;
結果如下:

結果分析: 雖然結果和上述結果一致,但是不推薦這樣寫。但是這樣寫怎么又沒有問題呢?這是由于SQL優化器的功勞,它幫我們調整了順序。
最后再補充一點:對于復合索引,不要跨列使用
#查看執行計劃
explainselecta3fromtest03wherea1=1anda3=2groupbya3;
結果如下:

結果分析: a1_a2_a3是一個復合索引,我們使用a1索引后,直接跨列使用了a3,直接跳過索引a2,因此索引a3失效了,當使用a3進行分組的時候,就會出現using where。
2)單表優化
#創建新表
createtablebook
(
bidint(4)primarykey,
namevarchar(20)notnull,
authoridint(4)notnull,
publicidint(4)notnull,
typeidint(4)notnull
);
#插入數據
insertintobookvalues(1,'tjava',1,1,2);
insertintobookvalues(2,'tc',2,1,2);
insertintobookvalues(3,'wx',3,2,1);
insertintobookvalues(4,'math',4,2,3);
結果如下:
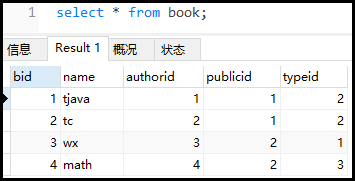
案例:查詢authorid=1且typeid為2或3的bid,并根據typeid降序排列。
explain
selectbidfrombook
wheretypeidin(2,3)andauthorid=1
orderbytypeiddesc;
結果如下:
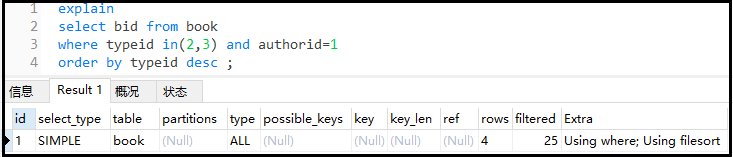
這是沒有進行任何優化的SQL,可以看到typ為ALL類型,extra為using filesort,可以想象這個SQL有多恐怖。
優化:添加索引的時候,要根據MySQL解析順序添加索引,又回到了MySQL的解析順序,下面我們再來看看MySQL的解析順序。
from..on..join..where..groupby..having..selectdinstinct..orderby..limit..
① 優化1:基于此,我們進行索引的添加,并再次查看執行計劃。
#添加索引
createindextypeid_authorid_bidonbook(typeid,authorid,bid);
#再次查看執行計劃
explain
selectbidfrombook
wheretypeidin(2,3)andauthorid=1
orderbytypeiddesc;
結果如下:
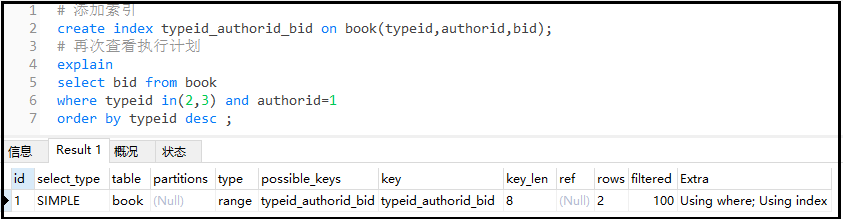
結果分析: 結果并不是和我們想象的一樣,還是出現了using where,查看索引長度key_len=8,表示我們只使用了2個索引,有一個索引失效了。
② 優化2:使用了in有時候會導致索引失效,基于此有了如下一種優化思路。
將in字段放在最后面。需要注意一點:每次創建新的索引的時候,最好是刪除以前的廢棄索引,否則有時候會產生干擾(索引之間)。
#刪除以前的索引
dropindextypeid_authorid_bidonbook;
#再次創建索引
createindexauthorid_typeid_bidonbook(authorid,typeid,bid);
#再次查看執行計劃
explain
selectbidfrombook
whereauthorid=1andtypeidin(2,3)
orderbytypeiddesc;
結果如下:

結果分析: 這里雖然沒有變化,但是這是一種優化思路。
總結如下:
a.最佳做前綴,保持索引的定義和使用的順序一致性
b.索引需要逐步優化(每次創建新索引,根據情況需要刪除以前的廢棄索引)
c.將含In的范圍查詢,放到where條件的最后,防止失效。
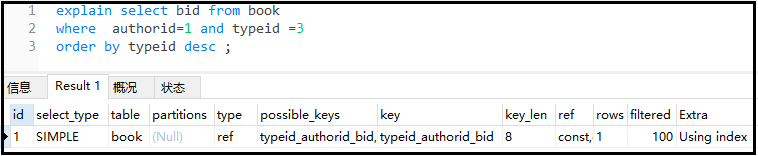
本例中同時出現了Using where(需要回原表); Using index(不需要回原表):原因,where authorid=1 and typeid in(2,3)中authorid在索引(authorid,typeid,bid)中,因此不需要回原表(直接在索引表中能查到);而typeid雖然也在索引(authorid,typeid,bid)中,但是含in的范圍查詢已經使該typeid索引失效,因此相當于沒有typeid這個索引,所以需要回原表(using where);
例如以下沒有了In,則不會出現using where:
explainselectbidfrombook
whereauthorid=1andtypeid=3
orderbytypeiddesc;
結果如下:
3)兩表優化
#創建teacher2新表
createtableteacher2
(
tidint(4)primarykey,
cidint(4)notnull
);
#插入數據
insertintoteacher2values(1,2);
insertintoteacher2values(2,1);
insertintoteacher2values(3,3);
#創建course2新表
createtablecourse2
(
cidint(4),
cnamevarchar(20)
);
#插入數據
insertintocourse2values(1,'java');
insertintocourse2values(2,'python');
insertintocourse2values(3,'kotlin');
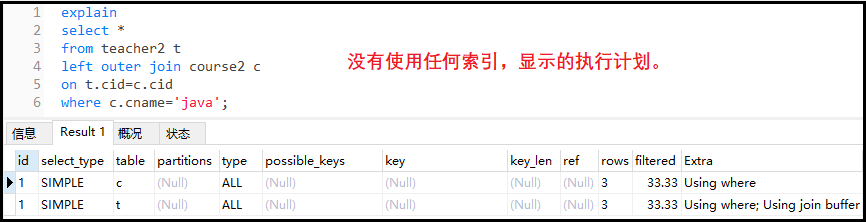
案例:使用一個左連接,查找教java課程的所有信息。
explain
select*
fromteacher2t
leftouterjoincourse2c
ont.cid=c.cid
wherec.cname='java';
結果如下:
① 優化
對于兩張表,索引往哪里加?答:對于表連接,小表驅動大表。索引建立在經常使用的字段上。
為什么小表驅動大表好一些呢?
小表:10
大表:300
#小表驅動大表
select...where小表.x10=大表.x300;
for(inti=0;i<小表.length10;i++)
{???
????for(intj=0;j<大表.length300;j++)??
????{???????
????????...???
????}
}
#大表驅動小表
select...where大表.x300=小表.x10;
for(inti=0;i<大表.length300;i++)
{??
????for(intj=0;j<小表.length10;j++)???
????{?????
????????...???
????}
}
分析: 以上2個FOR循環,最終都會循環3000次;但是對于雙層循環來說:一般建議,將數據小的循環,放外層。數據大的循環,放內層。不用管這是為什么,這是編程語言的一個原則,對于雙重循環,外層循環少,內存循環大,程序的性能越高。
結論:當編寫【…on t.cid=c.cid】時,將數據量小的表放左邊(假設此時t表數據量小,c表數據量大。)
我們已經知道了,對于兩表連接,需要利用小表驅動大表,例如【…on t.cid=c.cid】,t如果是小表(10條),c如果是大表(300條),那么t每循環1次,就需要循環300次,即t表的t.cid字段屬于,經常使用的字段,因此需要給cid字段添加索引。
更深入的說明: 一般情況下,左連接給左表加索引。右連接給右表加索引。其他表需不需要加索引,我們逐步嘗試。
#給左表的字段加索引
createindexcid_teacher2onteacher2(cid);
#查看執行計劃
explain
select*
fromteacher2t
leftouterjoincourse2c
ont.cid=c.cid
wherec.cname='java';
結果如下:

當然你可以下去接著優化,給cname添加一個索引。索引優化是一個逐步的過程,需要一點點嘗試。
#給cname的字段加索引
createindexcname_course2oncourse2(cname);
#查看執行計劃
explain
selectt.cid,c.cname
fromteacher2t
leftouterjoincourse2c
ont.cid=c.cid
wherec.cname='java';
結果如下:

最后補充一個:Using join buffer是extra中的一個選項,表示Mysql引擎使用了“連接緩存”,即MySQL底層動了你的SQL,你寫的太差了。
4)三表優化
- 大于等于張表,優化原則一樣
- 小表驅動大表
- 索引建立在經常查詢的字段上
7、避免索引失效的一些原則
① 復合索引需要注意的點
- 復合索引,不要跨列或無序使用(最佳左前綴)
- 復合索引,盡量使用全索引匹配,也就是說,你建立幾個索引,就使用幾個索引
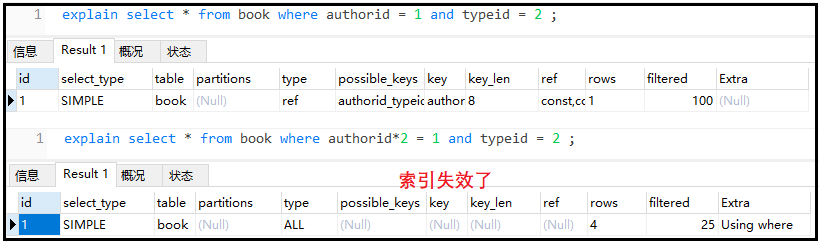
② 不要在索引上進行任何操作(計算、函數、類型轉換),否則索引失效
explainselect*frombookwhereauthorid=1andtypeid=2;
explainselect*frombookwhereauthorid*2=1andtypeid=2;
結果如下:
③ 索引不能使用不等于(!= <>)或is null (is not null),否則自身以及右側所有全部失效(針對大多數情況)。復合索引中如果有>,則自身和右側索引全部失效。
#針對不是復合索引的情況
explainselect*frombookwhereauthorid!=1andtypeid=2;
explainselect*frombookwhereauthorid!=1andtypeid!=2;
結果如下:
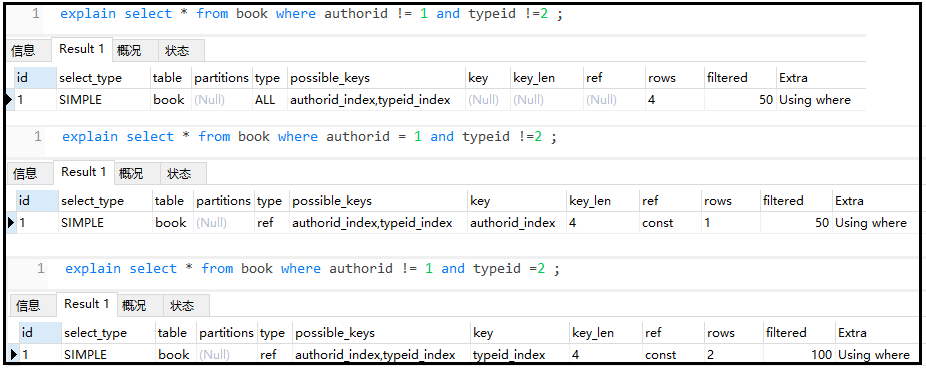
再觀看下面這個案例:
#刪除單獨的索引
dropindexauthorid_indexonbook;
dropindextypeid_indexonbook;
#創建一個復合索引
altertablebookaddindexidx_book_at(authorid,typeid);
#查看執行計劃
explainselect*frombookwhereauthorid>1andtypeid=2;
explainselect*frombookwhereauthorid=1andtypeid>2;
結果如下:
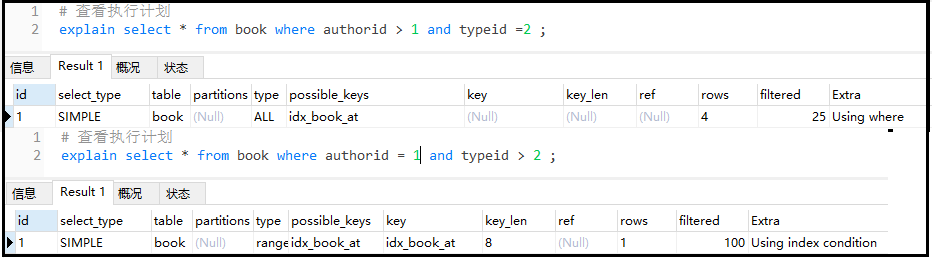
結論:復合索引中如果有【>】,則自身和右側索引全部失效。
在看看復合索引中有【<】的情況:
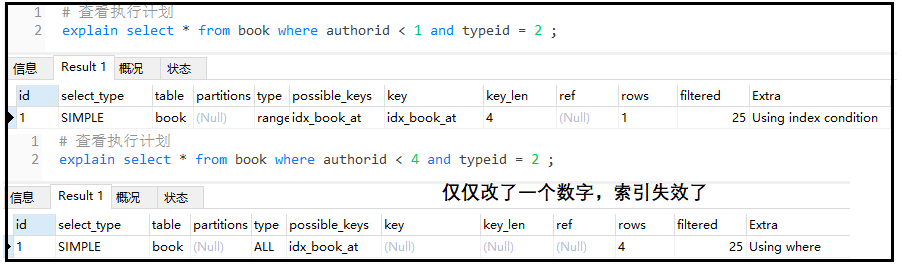
我們學習索引優化 ,是一個大部分情況適用的結論,但由于SQL優化器等原因 該結論不是100%正確。一般而言, 范圍查詢(> < in),之后的索引失效。
④ SQL優化,是一種概率層面的優化。至于是否實際使用了我們的優化,需要通過explain進行推測。
#刪除復合索引
dropindexauthorid_typeid_bidonbook;
#為authorid和typeid,分別創建索引
createindexauthorid_indexonbook(authorid);
createindextypeid_indexonbook(typeid);
#查看執行計劃
explainselect*frombookwhereauthorid=1andtypeid=2;
結果如下:

結果分析: 我們創建了兩個索引,但是實際上只使用了一個索引。因為對于兩個單獨的索引,程序覺得只用一個索引就夠了,不需要使用兩個。
當我們創建一個復合索引,再次執行上面的SQL:
#查看執行計劃
explainselect*frombookwhereauthorid=1andtypeid=2;
結果如下:

⑤ 索引覆蓋,百分之百沒問題
⑥ like盡量以“常量”開頭,不要以’%'開頭,否則索引失效
explainselect*fromteacherwheretnamelike"%x%";
explainselect*fromteacherwheretnamelike'x%';
explainselecttnamefromteacherwheretnamelike'%x%';
結果如下:
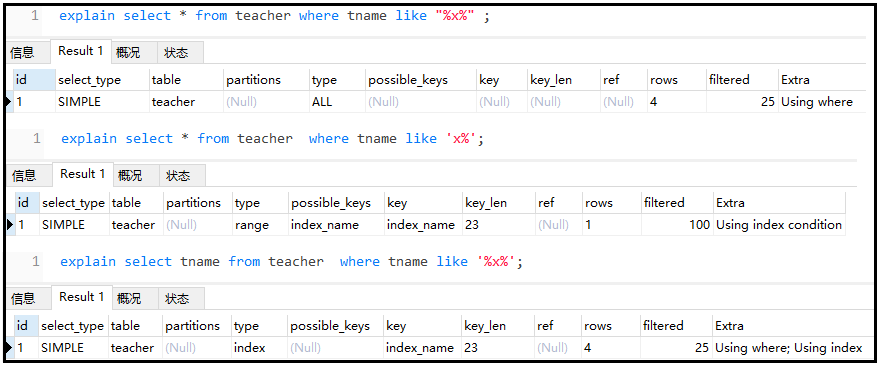
結論如下: like盡量不要使用類似"%x%"情況,但是可以使用"x%"情況。如果非使用 "%x%"情況,需要使用索引覆蓋。
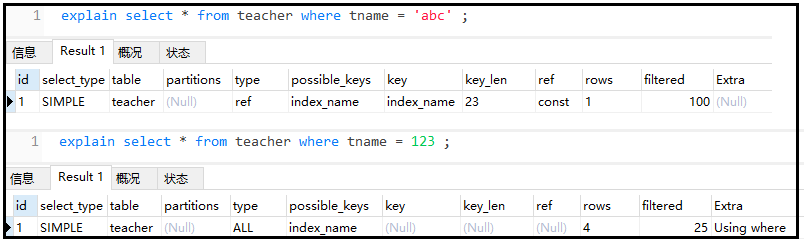
⑦ 盡量不要使用類型轉換(顯示、隱式),否則索引失效
explainselect*fromteacherwheretname='abc';
explainselect*fromteacherwheretname=123;
結果如下:
⑧ 盡量不要使用or,否則索引失效
explainselect*fromteacherwheretname=''andtcid>1;
explainselect*fromteacherwheretname=''ortcid>1;
結果如下:
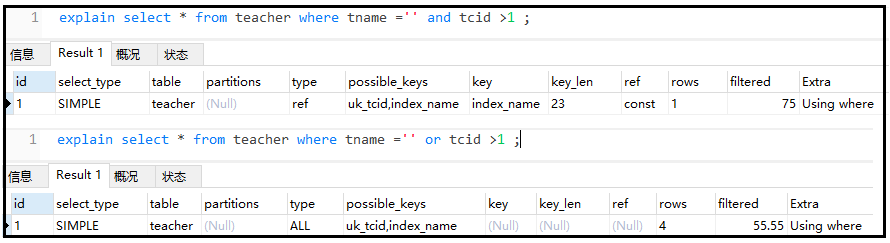
注意:or很猛,會讓自身索引和左右兩側的索引都失效。
8、一些其他的優化方法
1)exists和in的優化
如果主查詢的數據集大,則使用i關鍵字,效率高。
如果子查詢的數據集大,則使用exist關鍵字,效率高。
select..fromtablewhereexist(子查詢);
select..fromtablewhere字段in(子查詢);
2)order by優化
- IO就是訪問硬盤文件的次數
- using filesort 有兩種算法:雙路排序、單路排序(根據IO的次數)
- MySQL4.1之前默認使用雙路排序;雙路:掃描2次磁盤(1:從磁盤讀取排序字段,對排序字段進行排序(在buffer中進行的排序)2:掃描其他字段)
- MySQL4.1之后默認使用單路排序:只讀取一次(全部字段),在buffer中進行排序。但種單路排序會有一定的隱患(不一定真的是“單路/1次IO”,有可能多次IO)。原因:如果數據量特別大,則無法將所有字段的數據一次性讀取完畢,因此會進行“分片讀取、多次讀取”。
- 注意:單路排序 比雙路排序 會占用更多的buffer。
- 單路排序在使用時,如果數據大,可以考慮調大buffer的容量大小:
#不一定真的是“單路/1次IO”,有可能多次IO
setmax_length_for_sort_data=1024
如果max_length_for_sort_data值太低,則mysql會自動從 單路->雙路(太低:需要排序的列的總大小超過了max_length_for_sort_data定義的字節數)
① 提高order by查詢的策略:
- 選擇使用單路、雙路 ;調整buffer的容量大小
- 避免使用select * …(select后面寫所有字段,也比寫*效率高)
- 復合索引,不要跨列使用 ,避免using filesort保證全部的排序字段,排序的一致性(都是升序或降序)
篇幅很長,內容較多,建議收藏。
審核編輯 :李倩
-
服務器
+關注
關注
12文章
9304瀏覽量
86066 -
SQL
+關注
關注
1文章
774瀏覽量
44251 -
數據庫
+關注
關注
7文章
3846瀏覽量
64686
原文標題:1.8w 字的 SQL 優化大全
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
數據庫SQL的優化
內存條配置優化SQL Server服務器性能
SQL后悔藥,SQL性能優化和SQL規范優雅
30種SQL語句優化方法
SQL子查詢優化是怎么回事

sql優化常用的幾種方法
一文終結SQL子查詢優化





 工商網監
工商網監
評論