 基于一步步蒸餾(Distilling step-by-step)機制
基于一步步蒸餾(Distilling step-by-step)機制
為優化LLM為“小模型/少數據/好效果”,提供了一種新思路:”一步步蒸餾”(Distillingstep-by-step)
具體做法:訓練出一個更小的模型,同時輸出推理過程和標簽
總結
大模型部署耗費內存/算力,訓練特定任務的小模型采用:
微調(BERT、T5)
蒸餾(Vicuna)
但仍需要大量數據
本文提出”一步步蒸餾”(Distillingstep-by-step)機制:
模型更小
數據更少
實驗證明效果更佳(770M的T5,效果優于540B的PaLM)
引言
1. LLM的作用
以LLM作為粗標注,同時標注時會給出推理過程,如“思維鏈”CoT
e.g.:
“Agentlemaniscarryingequipmentforgolf,whatdoeshelikelyhave?
(a)club,(b)assemblyhall,(c)meditationcenter,(d)meeting,(e)church”
答案是(a),在上述選擇中,只有球桿用于高爾夫球。
上述邏輯會用于多任務訓練的額外數據
2. 任務準確性&所需訓練數據
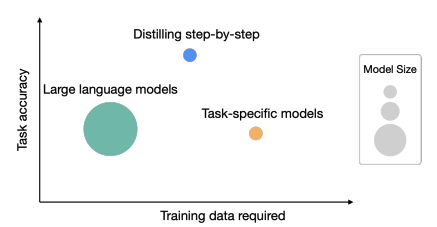
相關工作
1. 知識蒸餾
從大的“老師模型”蒸餾出“學生模型”,缺點是“老師模型”產生的數據有噪聲
本文做法:蒸餾標簽、老師模型的推理過程,以降低對無標簽數據的需求量
2. 人類推理過程
規范模型行為
作為額外的模型輸入
作為高質量標簽
缺點:代價高昂
3. 大模型推理過程
可用于產生高質量的推理步驟,作為提示輸入到大模型
作為微調數據,進行“self-improve”大模型
一步步蒸餾
概覽圖: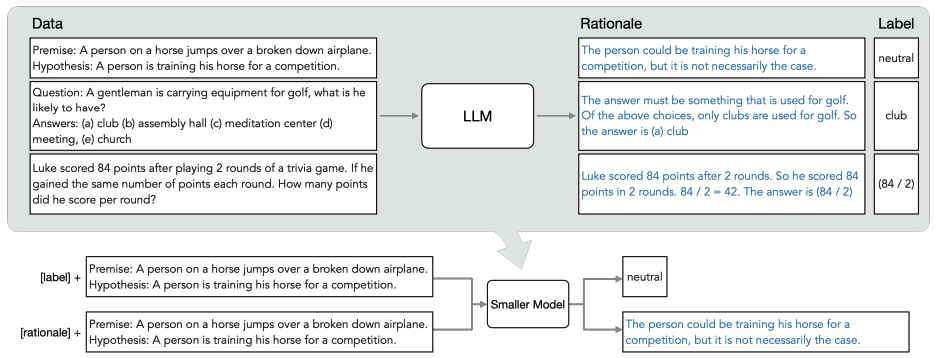
分為兩步:
已有LLM和無標簽數據,利用推理過程,輸出標簽
以推理過程作為額外數據(細節信息較多),訓練更小的模型
基于這樣一個特性:LLM產生的推理過程能夠用于它自身的預測
假設prompt是個三元組,其中是輸入,是標簽,是推理過程
數據集記作,x是輸入,y是標簽,且二者都是自然語言
這個文本到文本的框架包括的自然語言處理任務有:分類、自然語言推理、問答等等
常見的做法:用監督數據微調預訓練模型。
缺少人工標簽,特定任務的蒸餾是用LLM教師模型生成偽噪聲訓練標簽,代替
待降低交叉熵損失:
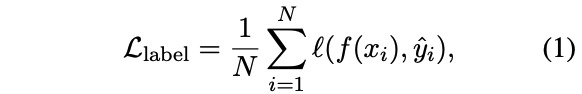
其中hat{y_i}$是模型蒸餾得到的標簽
將推理過程hat{r_i}$融入訓練過程的方式:
放到input后面,一同輸入到模型,此時的損失計算: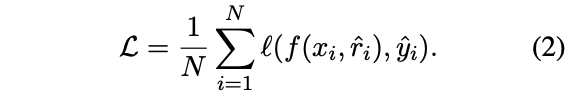
需要先用LLM產生推理過程,此時LLM是必要條件
(本文)轉化為多任務學習問題,訓練模型: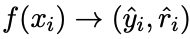
同時產生標簽、推理過程
采用后者的方式,此時的損失計算為: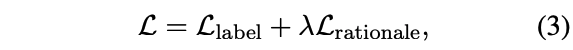
其中,推理過程生成的損失為: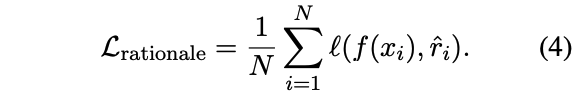
推理過程生成是預測之前的中間一步,而不是測試過程中產生的(如同公式2),所以測試時不再需要LLM,這就是所謂的"一步步蒸餾"。
另外,預先定義任務前綴,如[label]是標簽,[rationale]是推理過程
實驗
從兩方面證明“一步步蒸餾”的有效性:
與傳統的微調和蒸餾對比,效果有所提升
模型更小、部署代價更小
以最小的模型規模、數據量作為標準,“一步步蒸餾”的模型優于LLM
基準模型
LLM:540B的PaLM
下游模型:T5
T5-Base(220M)
T5-Large(770M)
T5-XXL(11B)
數據集
e-SNLI (自然語言推理):https://github.com/OanaMariaCamburu/e-SNLI
ANLI(自然語言推理):https://huggingface.co/datasets/anli
CQA(問答):https://www.tau-nlp.sites.tau.ac.il/commonsenseqa
SVAMP(算術數學詞問題):https://github.com/arkilpatel/SVAMP
與一步步蒸餾對比的其他方法
標準的微調(有標簽)
標準的任務蒸餾(無標簽)
減少訓練數據
對比結果1
在標簽較少時,一步步蒸餾優于標準微調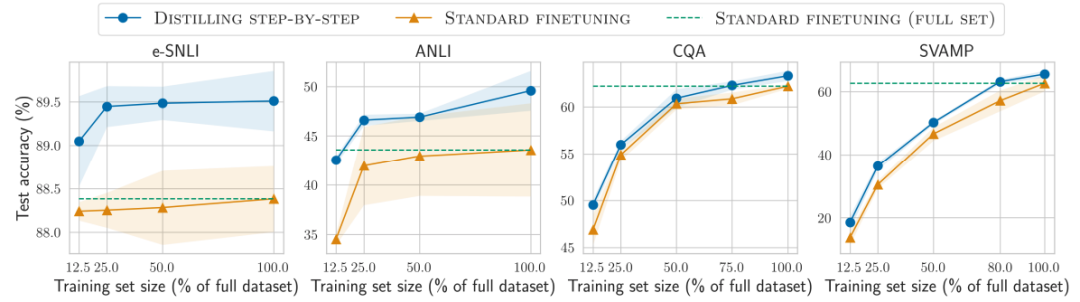
對比結果2
在標簽較少時,一步步蒸餾優于標準蒸餾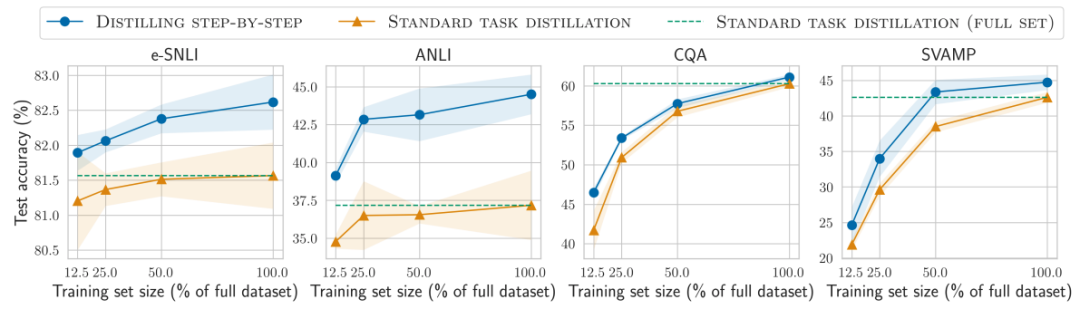
降低模型大小
各種baseline模型大小不一時,一步步蒸餾都更優
通過使用更小的特定任務模型一步步蒸餾逐步優于LLM
對比結果3
在所有考慮的4個數據集上總是可以優于少樣本CoT、PINTO調優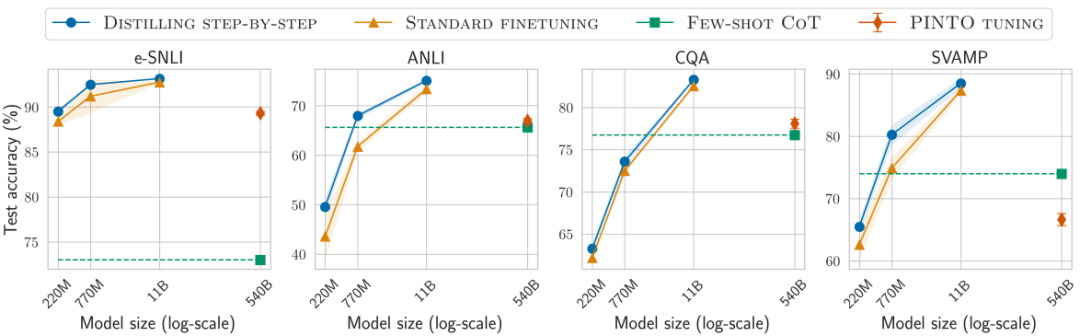
對比結果4
在4個數據集中的3個上也優于教師模型LLM
增強無標簽數據,可進一步改進一步步蒸餾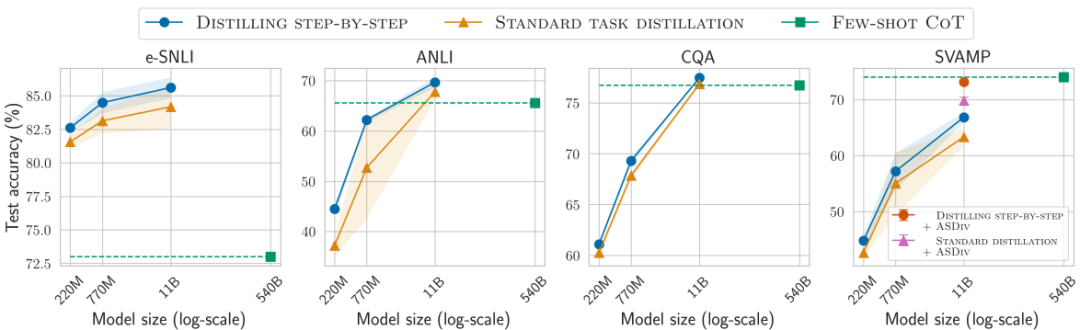
使用最小模型大小和最小訓練數據
對比結果5
用更小模型、更少數據,一步步蒸餾優于LLM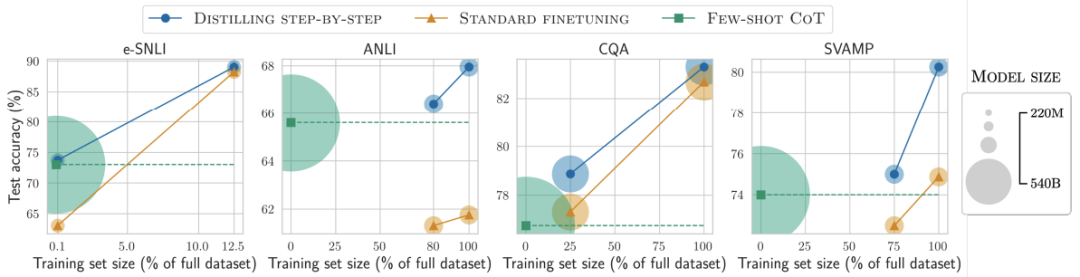
對比結果6
標準的微調和蒸餾需要更多的數據和更大的模型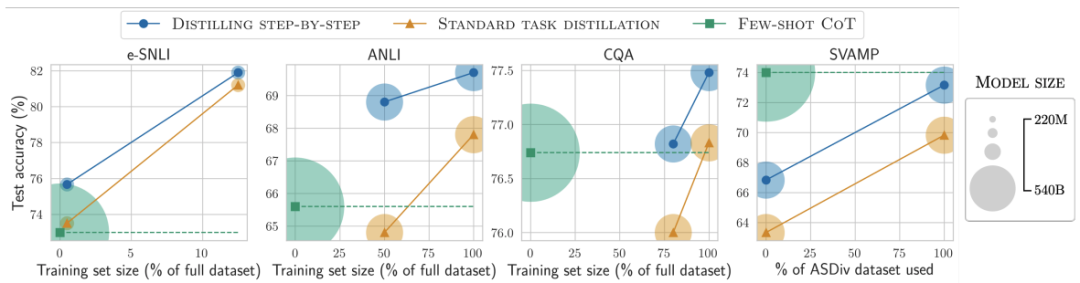
總結
實驗證明,一步步蒸餾降低了訓練數據量、特定任務的模型大小、優于初始LLM的性能
局限性:
用戶需要提供帶標簽數據
LLM推理能力有限,尤其面對復雜推理和規劃問題
-
數據
+關注
關注
8文章
7137瀏覽量
89562 -
模型
+關注
關注
1文章
3303瀏覽量
49216
原文標題:小模型媲美2000倍體量大模型,谷歌提出新思路:蒸餾也能Step-by-Step
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
虛擬現實正一步步向我們走來
CC2530一步步演示程序燒寫
一步步進行調試GPRS模塊
ARM嵌入式系統如何入門?怎樣一步步的去學習
看電工技術是如何一步步淪為勤雜工的
看電路是怎么把電壓一步步頂上去的?資料下載

ROM與RAM 單片機上電后如何一步步執行?資料下載





 工商網監
工商網監
評論