 GPT-4 的模型結構和訓練方法
GPT-4 的模型結構和訓練方法
在 GPT-4 的發布報道上,GPT-4 的多模態能力讓人印象深刻,它可以理解圖片內容給出圖片描述,甚至能在圖片內容的基礎上理解其中的隱喻或推斷下一時刻的發展。無疑,面向所謂的 AGI(通用人工智能),多模態顯然是必經之路。但是遺憾 GPT-4 的圖片輸入能力尚且沒有完全放開,而即使放開我們對 GPT-4 的模型結構和訓練方法也知之甚少。
而最近,中科院自動化所帶來了一項有趣的工作,推出了多模態的大規模語言模型 X-LLM,同時支持圖片、語音以及視頻等多種模態信息作為大模型的輸入,并且展現了類似于 GPT-4 的表現。比如當輸入圖像時,X-LLM 可以識別圖像位置、理解圖像中的食物。當輸入視頻時,X-LLM 也可以總結視頻內容,檢索電影片段的電影名稱,基于視頻內容結合圖像回答問題等等。以論文中的一張圖片為例,當用戶希望 X-LLM 介紹輸入的圖片時,X-LLM 準確的理解了圖片相關于游戲王者榮耀,并且給出了一定的介紹。
從性能來看,作者團隊使用了 30 張模型未見過的圖像,每張圖像都與相關于對話、詳細描述以及推理三類的問題,從而形成了 90 個指令-圖像對以測試 X-LLM 與 GPT-4 的表現。可以看到,通過使用 ChatGPT 從 1 到 10 為模型回復進行評分,與 GPT-4 相比 X-LLM 取得了 84.5% 的相對分數,表明了模型在多模態的環境中是有效的。

除此之外,這篇工作也開源了相關的代碼和一個簡潔高質量的中文多模態指令數據集,幫助后續工作使用 X-LLM 的框架進行研究,
在進入論文之前,首先來想想一個問題,GPT-4 是如何獲得其強大的多模態能力的呢?論文作者給出了一個假設:“GPT-4 的多模態能力來源于其更先進,更大的語音模型,即 GPT-4 是用語言的形式表達出了其他模態的內容”。
這個假設也就是講,需要將多模態的數據“對齊”到語言數據之中,然后再投入大模型以獲得多模態能力,在這個假設的基礎上,作者提出了 X2L 接口,其中 X 意味著多模態數據,而 L 則表示語言,X2L 接口即將多個單模態編碼器與一個大規模語言模型(LLM)進行對齊。其中,圖像接口 I2L 采用 BLIP-2 中的 Q-Former,視頻接口 V2L 復用圖像接口的參數,但是考慮了編碼后的視頻特征,語言接口 S2L 采用 CIF 與 Transformer 結構將語音轉換為語言。整個 X-LLM 的訓練包含三個階段,分別是(1)轉換多模態信息;(2)將 X2L 對齊到 LLM;(3)將多模態數據整合到 LLM 中。
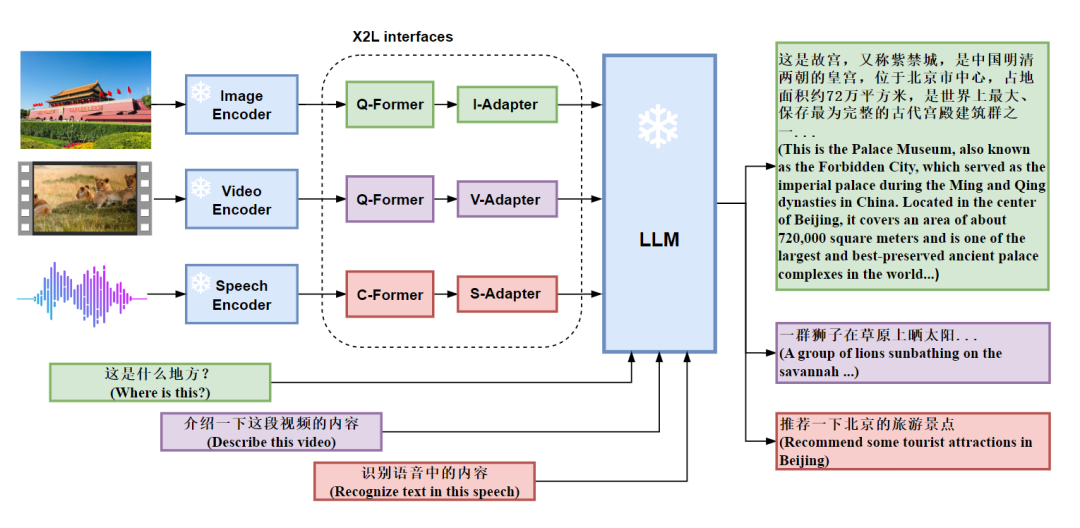
具體而言,多模態信息轉換的三個接口設計如下:
圖像接口:圖像接口由 Q-Formers 和 I-Adapter 模塊組成。Q-Formers的目標是將圖像轉換為語言,將從圖像編碼器獲得的圖像特征轉換為長度為 L 的準語言嵌入的序列。I-Adapter 模塊旨在對齊準語言嵌入的維數和 LLM 的嵌入維數;
視頻接口:視頻接口與圖像接口采用相同的結構,并且均勻采樣使用 T 幀表示每個視頻,再將每幀視頻視為圖像,構建長度為 T x L 的準語言嵌入序列;
語言接口:語音接口由兩部分組成,即 C-Former 和 S-Adaptor。C-Former 是 CIF 模塊和 12 層 Transformer 模塊的組合。CIF 模塊通過變長下采樣將語音編碼器的語音特征序列壓縮為相同長度的令牌級語音嵌入序列,而 Transformer 結構為令牌級語音嵌入提供了更強的上下文建模。S-Adaptor 用于將 Transformer 結構的輸出投影到 LLM 的輸入向量空間,從而進一步縮小了語音與語言之間的差距。
而在第二階段,Q-Former 的參數來源于 BLIP2 中的 Q-Former 的參數。為了使得 Q-Former 適應中文 LLM,作者們使用了一個總共包括約 1400 萬個中文圖片-文本對的數據集進行訓練,并使用圖片中訓練好的接口初始化視頻中的 Q-Former 和 V-Adapter,最后,使用 ASR 數據訓練語音接口,使語音界面的輸出與 LLM 對齊。在整個過程中,Encoder 部分與 LLM 部分都不參與訓練,只有接口部分進行訓練。
而最后第三階段,論文使用多模態聯合訓練增強 X-LLM 的多模態能力,但是可以看到,在沒有進行聯合訓練時,X-LLM 已經具有了識別多模態的能力,這種能力很有可能是來自于 LLM。而為了進行聯合訓練,作者構建了一個多模態指令數據集對接口進行微調,包含(1) 圖像-文本指令數據,(2)語音-文本指令數據,(3) 視頻-文本指令數據以及 (4) 圖像-文本-語音指令數據。整個數據集主要來源于 MiniGPT-4(圖像,3.5k)、AISHELL-2(語音,2k)以及 ActivityNet(視頻,1k)。
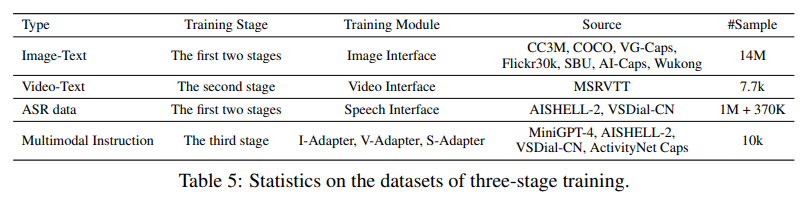
而在實驗方面,論文作者開發了一個聊天界面,用以與其他開源的多模態大規模語言模型( LLaVA 與 MiniGPT-4)做對比,整體而言,X-LLM 具備了相當不錯的閱讀和理解圖片的能力,并且可以更好的捕捉其中具有“中國特色”的預料,如下圖問答所示,當輸入天安門的圖片時,X-LLM 準確的識別出了它是北京的故宮,并且給出了一些歷史的介紹,而相應 LLaVA 與 MiniGPT-4 僅僅識別出來了中國的宮殿和旗幟,但是并沒有提到 Forbidden City。
同時,X-LLM 也能準確的識別和理解語音信息,這里的“詳細描述一下這個“照片”是以語音形式進行的輸入,可以看到 X-LLM 也能給出相當不錯的回答,并且可以進行延申交流。
此外,在視頻問答方面,X-LLM 也表現得相當不錯,對于輸入的水母游動的視頻,X-LLM 可以頗為準確的為視頻做出標題,并配以文字。
對于敏感信息,X-LLM 也能做到識別
除了 X-LLM 這樣一個將大規模語音模型向多模態方向扎實推進了一步的框架外,作者也意外的發現,在英文數據集上訓練的 Q-former 的參數可以轉移到其他語言(漢語),并仍然保持有效性。這種語言的可傳遞性極大地增加了使用英語圖像文本數據和其訓練的模型參數平移到其他語言中的可能性,并提高了在其他語言中訓練多模態 LLM 的效率。
透過這篇工作,或許我們可以一窺多模態大模型光明的未來,回到開頭,多模型必然是 AGI 的必經之路,那么以語言為基準統一多模態可不可以實現呢?那就要看跟隨這篇工作出現的未來了吧!
-
數據
+關注
關注
8文章
7139瀏覽量
89579 -
模型
+關注
關注
1文章
3309瀏覽量
49224 -
語言模型
+關注
關注
0文章
538瀏覽量
10341
原文標題:中科院發布多模態 ChatGPT,圖片、語言、視頻都可以 Chat ?中文多模態大模型力作
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ChatGPT升級 OpenAI史上最強大模型GPT-4發布
GPT-4多模態模型發布,對ChatGPT的升級和斷崖式領先
最新、最強大的模型GPT-4將向美國政府機構開放
人工通用智能的火花:GPT-4的早期實驗
GPT-4已經會自己設計芯片了嗎?
GPT-4催生的接口IP市場空間
爆了!GPT-4模型架構、訓練成本、數據集信息都被扒出來了

OpenAI宣布GPT-4 API全面開放使用!
GPT-3.5 vs GPT-4:ChatGPT Plus 值得訂閱費嗎 國內怎么付費?
GPT-4沒有推理能力嗎?
OpenAI最新大模型曝光!劍指多模態,GPT-4之后最大升級!

ChatGPT plus有什么功能?OpenAI 發布 GPT-4 Turbo 目前我們所知道的功能






 工商網監
工商網監
評論