 教你如何用兩行代碼搞定YOLOv8各種模型推理
教你如何用兩行代碼搞定YOLOv8各種模型推理
前言
大家好,YOLOv8 框架本身提供的API函數是可以兩行代碼實現 YOLOv8 模型推理,這次我把這段代碼封裝成了一個類,只有40行代碼左右,可以同時支持YOLOv8對象檢測、實例分割、姿態評估模型的GPU與CPU上推理演示。

程序實現
使用PyQT5開發一個簡單的YOLOv8 框架本身提供的API函數演示交互界面,支持從界面上選擇模型文件、測試圖像或者視頻文件,點擊開始推理 按鈕就可以運行了,整個程序的界面如下:
YOLOv8框架支持的函數推理會自動識別模型的類型是對象檢測、實例分割、姿態評估中哪一種,有GPU支持的情況下,默認會使用GPU推理。
推理運行在一個單獨的PyQT線程中,通過信號與槽機制實現推理結果返回與更新。實現的線程代碼如下:
classInferenceThread(QtCore.QThread): fire_stats_signal=QtCore.pyqtSignal(dict) def__init__(self,settings): super(InferenceThread,self).__init__() self.settings=settings self.detector=YOLOv8PtInference(settings) self.input_image=settings.input_image defrun(self): ifself.detectorisNone: return ifself.input_image.endswith(".mp4"): cap=cv.VideoCapture(self.input_image) whileTrue: ret,frame=cap.read() ifretisTrue: self.detector.infer_image(frame) self.fire_stats_signal.emit({"result":frame}) else: break else: frame=cv.imread(self.input_image) self.detector.infer_image(frame) self.fire_stats_signal.emit({"result":frame}) self.fire_stats_signal.emit({"done":"done"}) return直接通過PT模型推理的好處有兩點,一個是不需要寫部署代碼了,二是精度不會在模型轉化中有細微損失了。特別適合Python開發者
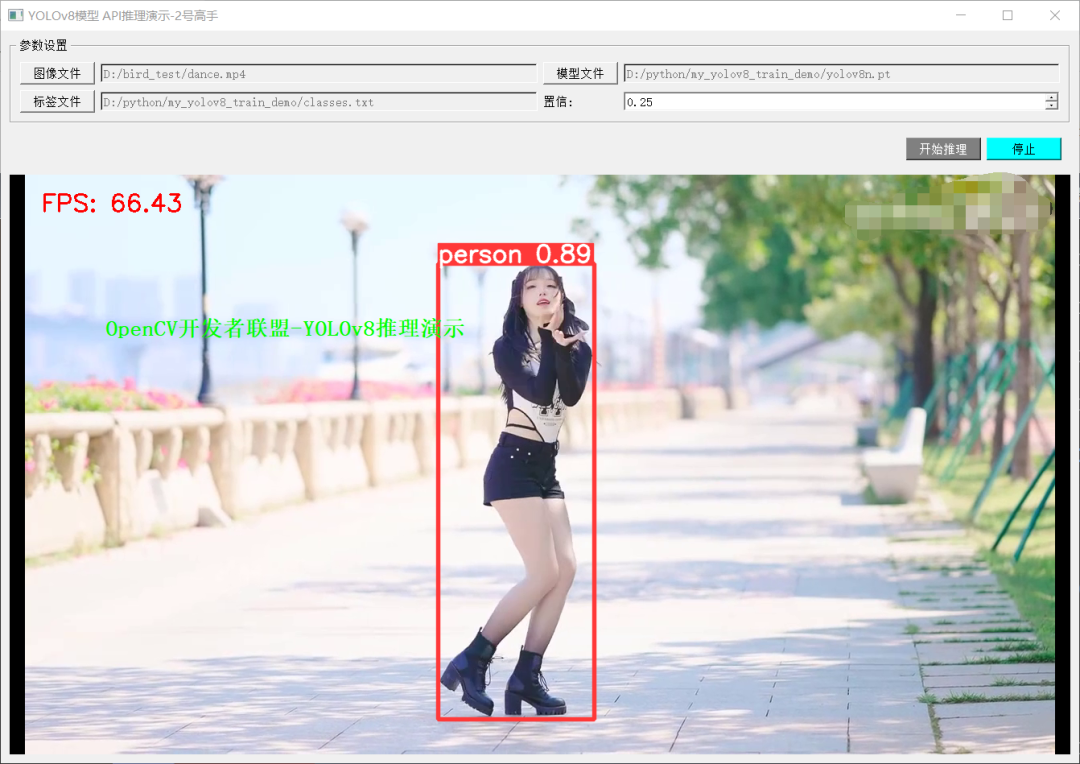
對象檢測 - 運行截圖如下:
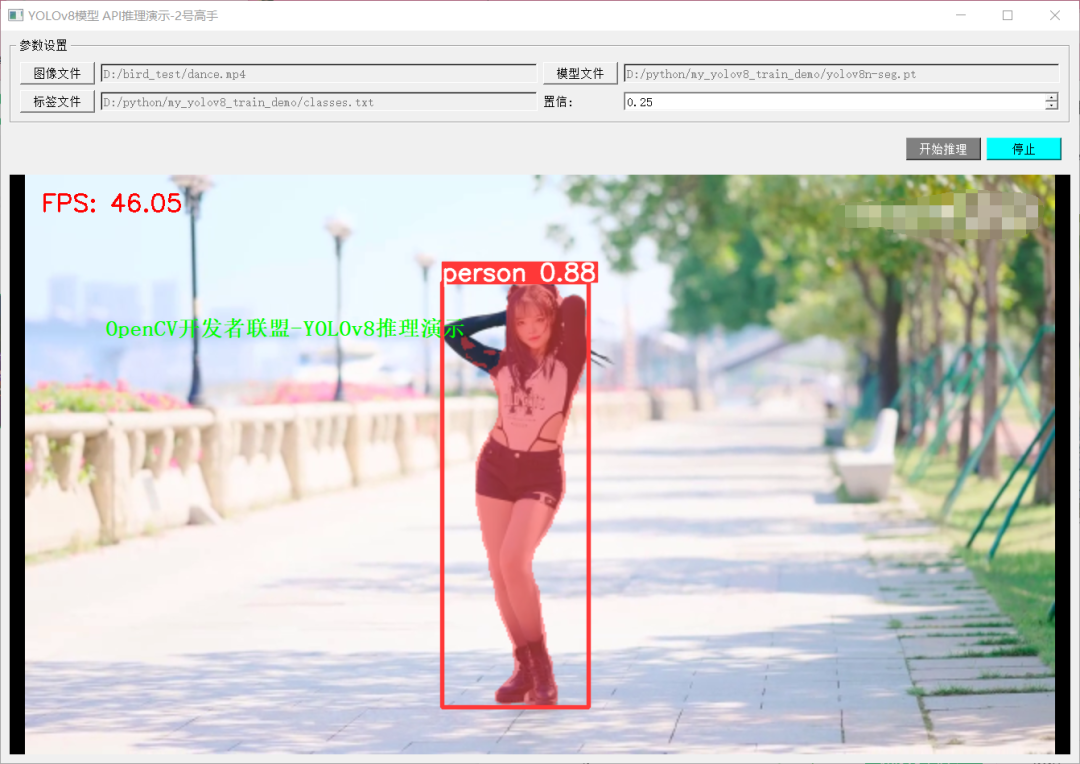
實例分割-運行截圖如下:
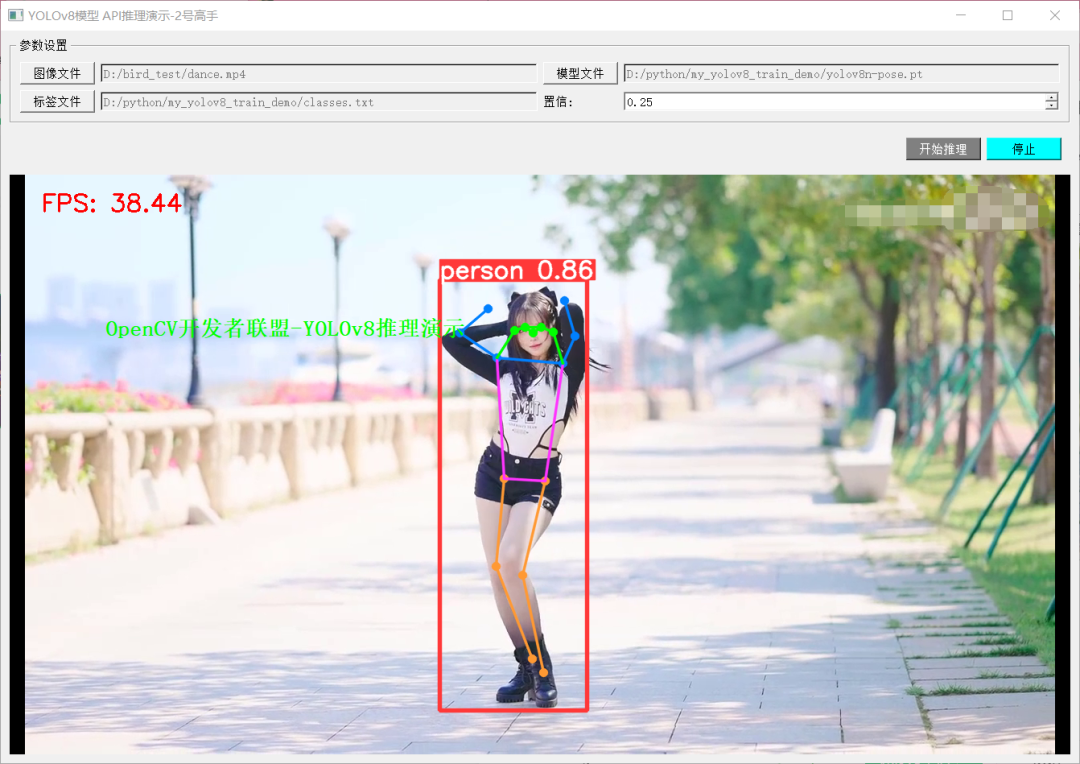
姿態評估-運行截圖如下:
審核編輯:劉清
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
gpu
+關注
關注
28文章
4774瀏覽量
129350 -
python
+關注
關注
56文章
4807瀏覽量
85037 -
pyqt5
+關注
關注
0文章
25瀏覽量
3407
原文標題:兩行代碼搞定YOLOv8各種模型推理
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于YOLOv8實現自定義姿態評估模型訓練
Hello大家好,今天給大家分享一下如何基于YOLOv8姿態評估模型,實現在自定義數據集上,完成自定義姿態評估模型的訓練與推理。

【愛芯派 Pro 開發板試用體驗】yolov8模型轉換
嘗試將最新的yolov8模型轉換為愛芯派的模型。
環境準備
準備Docker環境
首先自己在任意機器上準備好docker環境,詳細步驟見官網。
Docker 鏡像文件
準備 yolo8
發表于 11-20 12:19
TensorRT 8.6 C++開發環境配置與YOLOv8實例分割推理演示
對YOLOv8實例分割TensorRT 推理代碼已經完成C++類封裝,三行代碼即可實現YOLOv8
在AI愛克斯開發板上用OpenVINO?加速YOLOv8目標檢測模型
《在 AI 愛克斯開發板上用 OpenVINO 加速 YOLOv8 分類模型》介紹了在 AI 愛克斯開發板上使用 OpenVINO 開發套件部署并測評 YOLOv8 的分類模型,本文將

YOLOv8版本升級支持小目標檢測與高分辨率圖像輸入
YOLOv8版本最近版本又更新了,除了支持姿態評估以外,通過模型結構的修改還支持了小目標檢測與高分辨率圖像檢測。原始的YOLOv8模型結構如下。
AI愛克斯開發板上使用OpenVINO加速YOLOv8目標檢測模型
《在AI愛克斯開發板上用OpenVINO加速YOLOv8分類模型》介紹了在AI愛克斯開發板上使用OpenVINO 開發套件部署并測評YOLOv8的分類模型,本文將介紹在AI愛克斯開發板

Pytorch Hub兩行代碼搞定YOLOv5推理
模型。支持模型遠程加載與本地推理、當前Pytorch Hub已經對接到Torchvision、YOLOv5、YOLOv8、pytorchvi

三種主流模型部署框架YOLOv8推理演示
深度學習模型部署有OpenVINO、ONNXRUNTIME、TensorRT三個主流框架,均支持Python與C++的SDK使用。對YOLOv5~YOLOv8的系列模型,均可以通過C+
如何修改YOLOv8的源碼
很多人也想跟修改YOLOv5源碼一樣的方式去修改YOLOv8的源碼,但是在github上面卻發現找到的YOLOv8項目下面TAG分支是空的,然后就直接從master/main下面把源碼克隆出來一通
YOLOv8實現任意目錄下命令行訓練
當你使用YOLOv8命令行訓練模型的時候,如果當前執行的目錄下沒有相關的預訓練模型文件,YOLOv8就會自動下載模型權重文件。這個是一個正常
OpenCV4.8+YOLOv8對象檢測C++推理演示
自從YOLOv5更新成7.0版本,YOLOv8推出以后,OpenCV4.6以前的版本都無法再加載導出ONNX格式模型了,只有OpenCV4.7以上版本才可以支持最新版本YOLOv5與
基于YOLOv8的自定義醫學圖像分割
YOLOv8是一種令人驚嘆的分割模型;它易于訓練、測試和部署。在本教程中,我們將學習如何在自定義數據集上使用YOLOv8。但在此之前,我想告訴你為什么在存在其他優秀的分割模型時應該使用

基于OpenCV DNN實現YOLOv8的模型部署與推理演示
基于OpenCV DNN實現YOLOv8推理的好處就是一套代碼就可以部署在Windows10系統、烏班圖系統、Jetson的Jetpack系統





 工商網監
工商網監
評論