 基于Prometheus的全方位監控平臺設計
基于Prometheus的全方位監控平臺設計
一、背景:
Kubernetes集群規模大、動態變化快,而且容器化應用部署和服務治理機制的普及,傳統的基礎設施監控方式已經無法滿足Kubernetes集群的監控需求。
需要使用專門針對Kubernetes集群設計的監控工具來監控集群的狀態和服務質量。
Prometheus則是目前Kubernetes集群中最常用的監控工具之一,它可以通過Kubernetes API中的 metrics-server 獲取 Kubernetes 集群的指標數據,從而實現對Kubernetes集群的應用層面監控,以及基于它們的水平自動伸縮對象 HorizontalPodAutoscaler。
二、Metrics-server
資源指標管道 Metrics API | Kubernetes
Metrics Server 是一個專門用來收集 Kubernetes 核心資源指標(metrics)的工具,它定時從所有節點的 kubelet 里采集信息,但是對集群的整體性能影響極小,每個節點只大約會占用 1m 的 CPU 和 2MB 的內存,所以性價比非常高。
Metrics Server 工作原理:
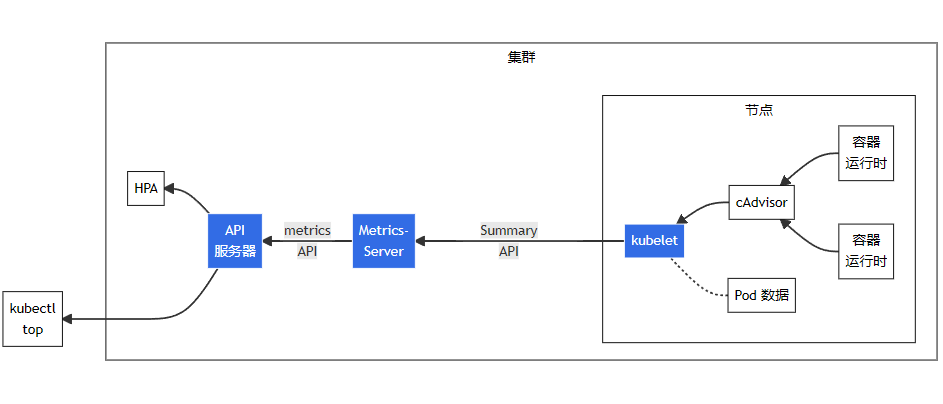
圖中從右到左的架構組件包括以下內容:
cAdvisor: 用于收集、聚合和公開 Kubelet 中包含的容器指標的守護程序。
kubelet: 用于管理容器資源的節點代理。可以使用 /metrics/resource 和 /stats kubelet API 端點訪問資源指標。
Summary API: kubelet 提供的 API,用于發現和檢索可通過 /stats 端點獲得的每個節點的匯總統計信息。
metrics-server: 集群插件組件,用于收集和聚合從每個 kubelet 中提取的資源指標。API 服務器提供 Metrics API 以供 HPA、VPA 和 kubectl top 命令使用。Metrics Server 是 Metrics API 的參考實現。
Metrics API: Kubernetes API 支持訪問用于工作負載自動縮放的 CPU 和內存。要在你的集群中進行這項工作,你需要一個提供 Metrics API 的 API 擴展服務器。
2.1、Metrics-server部署配置
Metrics Server 的項目網址(https://github.com/kubernetes-sigs/metrics-server)
$ wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml && mv components.yaml metrics-server.yaml
修改 YAML 文件
apiVersion: apps/v1 kind: Deployment metadata: name: metrics-server namespace: kube-system spec: ... ... template: spec: containers: - args: - --kubelet-insecure-tls ... ...
Metrics Server 默認使用 TLS 協議,要驗證證書才能與 kubelet 實現安全通信,而我們的內網環境里沒有這個必要。
默認鏡像源非國內,如有下載失敗的小伙伴,更改鏡像為如下阿里云提供的即可:
registry.aliyuncs.com/google_containers/metrics-server:v0.6.1
部署:
$ kubectl apply -f metrics-server.yaml
測試驗證:
$ kubectl top node $ kubectl top pod -n kube-system
三、HorizontalPodAutoscaler
HorizontalPodAutoscaler (HPA)是Kubernetes中的一個控制器,用于動態地調整Pod副本的數量。HPA可以根據Metrics-server提供的指標(如CPU使用率、內存使用率等)或內部指標(如每秒的請求數)來自動調整Pod的副本數量,以確保應用程序具有足夠的資源,并且不會浪費資源。
HPA是Kubernetes擴展程序中非常常用的部分,特別是在負載高峰期自動擴展應用程序時。
3.1、使用HorizontalPodAutoscaler
創建一個 Nginx 應用,定義 Deployment 和 Service,作為自動伸縮的目標對象:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ngx-hpa-dep
spec:
replicas: 1
selector:
matchLabels:
app: ngx-hpa-dep
template:
metadata:
labels:
app: ngx-hpa-dep
spec:
containers:
- image: nginx:alpine
name: nginx
ports:
- containerPort: 80
resources:
requests:
cpu: 50m
memory: 10Mi
limits:
cpu: 100m
memory: 20Mi
---
apiVersion: v1
kind: Service
metadata:
name: ngx-hpa-svc
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: ngx-hpa-dep
注意在它的 spec 里一定要用 resources 字段寫清楚資源配額,否則 HorizontalPodAutoscaler 會無法獲取 Pod 的指標,也就無法實現自動化擴縮容。
接下來我們要用命令 kubectl autoscale 創建一個 HorizontalPodAutoscaler 的樣板 YAML 文件,它有三個參數:
min,Pod 數量的最小值,也就是縮容的下限。
max,Pod 數量的最大值,也就是擴容的上限。
cpu-percent,CPU 使用率指標,當大于這個值時擴容,小于這個值時縮容。
現在我們就來為剛才的 Nginx 應用創建 HorizontalPodAutoscaler,指定 Pod 數量最少 2 個,最多 8 個,CPU 使用率指標設置的小一點,5%,方便我們觀察擴容現象:
$ kubectl autoscale deploy ngx-hpa-dep --min=2 --max=8 --cpu-percent=5 --dry-run=client -o yaml > nginx-demo-hpa.yaml
YAML 描述文件:
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: ngx-hpa spec: maxReplicas: 8 minReplicas: 2 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: ngx-hpa-dep targetCPUUtilizationPercentage: 5
通過kubectl apply創建這個 HorizontalPodAutoscaler 后,它會發現 Deployment 里的實例只有 1 個,不符合 min 定義的下限的要求,就先擴容到 2 個:
# kubectl get deploy NAME READY UP-TO-DATE AVAILABLE AGE ngx-hpa-dep 1/2 2 1 95s
3.2、測試驗證
下面我們來給 Nginx 加上壓力流量,運行一個測試 Pod,使用的鏡像是httpd:alpine,它里面有 HTTP 性能測試工具 ab(Apache Bench):
$ kubectl run test -it --image=httpd:alpine -- sh
然后我們向 Nginx 發送一百萬個請求,持續 1 分鐘,再用 kubectl get hpa 來觀察 HorizontalPodAutoscaler 的運行狀況:
$ ab -c 10 -t 60 -n 1000000 'http://ngx-hpa-svc/'
Metrics Server 大約每 15 秒采集一次數據,所以 HorizontalPodAutoscaler 的自動化擴容和縮容也是按照這個時間點來逐步處理的。
當它發現目標的 CPU 使用率超過了預定的 5% 后,就會以 2 的倍數開始擴容,一直到數量上限,然后持續監控一段時間;
如果 CPU 使用率回落,就會再縮容到最小值 (默認會等待五分鐘如果負載沒有上去,就會縮小到最低水平,防止抖動)。
$ kubectl get po NAME READY STATUS RESTARTS AGE ngx-hpa-dep-7984687bb9-86cg5 0/1 ContainerCreating 0 14s ngx-hpa-dep-7984687bb9-9wpr8 1/1 Running 0 29s ngx-hpa-dep-7984687bb9-gjzwl 0/1 ContainerCreating 0 14s ngx-hpa-dep-7984687bb9-k4dpj 0/1 ContainerCreating 0 14s ngx-hpa-dep-7984687bb9-qkhpq 1/1 Running 0 4m45s ngx-hpa-dep-7984687bb9-sgxtc 0/1 ContainerCreating 0 14s ngx-hpa-dep-7984687bb9-xq6xk 1/1 Running 0 6m11s ngx-hpa-dep-7984687bb9-xs9q8 0/1 ContainerCreating 0 29s
四、總結
1、Metrics Server是Kubernetes中的一個組件,它可以將集群中的散布的資源使用情況數據收集并聚合起來。收集的數據包括節點的CPU和內存使用情況等。
2、通過API提供給Kubernetes中的其它組件(如HPA)使用。Metrics Server可以幫助集群管理員和應用程序開發者更好地了解集群中資源的使用情況,并根據這些數據做出合理的決策,例如調整Pod副本數、擴展集群等。
3、Metrics Server對于Kubernetes中的資源管理和應用程序擴展非常重要。
-
API
+關注
關注
2文章
1511瀏覽量
62404 -
容器
+關注
關注
0文章
499瀏覽量
22125 -
監控平臺
+關注
關注
0文章
28瀏覽量
8555 -
Prometheus
+關注
關注
0文章
27瀏覽量
1730
原文標題:基于Prometheus的全方位監控平臺--HPA自動伸縮
文章出處:【微信號:aming_linux,微信公眾號:阿銘linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Prometheus的架構原理從“監控”談起
[分享]全方位剖析BGA布線規則與技巧
全方位智能小車通訊應該使用什么方式?
Glance360全方位智能展示
什么是全方位汽車安全解決方案?
關于全方位立體電容傳感器的設計
prometheus做監控服務的整個流程介紹
介紹一種全方位測量和檢驗的軟件
安全監控電路提供全方位監測,確保系統的安全性

prometheus下載安裝教程
基于kube-prometheus的大數據平臺監控系統設計
基于Prometheus開源的完整監控解決方案






 工商網監
工商網監
評論