 2D Transformer 可以幫助3D表示學習嗎?
2D Transformer 可以幫助3D表示學習嗎?
與2D視覺和NLP相比,基于基礎的視覺計算在3D社區中發展滯后。提出以下問題:是什么使得3D表示學習比2D視覺或NLP更具挑戰性?
深度學習的成功在很大程度上依賴于具有全面標簽的大規模數據,在獲取3D數據方面比2D圖像或自然語言更昂貴且耗時。這促使我們有可能利用用于不同模態知識轉移的以3D數據為基礎的預訓練模型作為教師。
本文以統一的知識蒸餾方式重新考慮了掩碼建模,并且展示了基于2D圖像或自然語言預訓練的基礎
Transformer模型如何通過訓練作為跨模態教師的自編碼器(ACT)來幫助無監督學習的3D表示學習。本文首次證明了預訓練的基礎
Transformer可以幫助3D表示學習,而無需訪問任何2D、語言數據或3D下游標注。
筆者個人體會
這篇論文的動機是解決3D數據表示學習中存在的挑戰,即3D數據與2D圖像或語言具有不同的結構,使得在細粒度知識的關聯方面存在困難。作者希望通過自監督學習的方式,將來自圖像領域的豐富知識應用于3D數據的表示學習中,從而提高3D任務的性能。作者提出一種自監督學習框架,用于跨模態的知識傳遞和特征蒸餾,以改善3D數據的表示學習和下游任務性能。
核心創新點是框架中的ACT(Autoencoding Cross-Transformers),它將預訓練的基礎Transformer模型轉化為跨模態的3D教師模型,并通過自編碼和掩碼建模將教師模型的特征蒸餾到3D Transformer學生模型中。
作者通過以下方式設計和實現ACT框架:
-
首先,使用3D自編碼器將預訓練的基礎
Transformer轉化為3D教師模型。這個自編碼器通過自監督訓練從3D數據中學習特征表示,并生成語義豐富的潛在特征。 -
接著,設計了掩碼建模方法,其中教師模型的潛在特征被用作3D
Transformer學生模型的掩碼建模目標。學生模型通過優化掩碼建模任務來學習表示,以捕捉3D數據中的重要特征。 -
使用預訓練的2D圖像
Transformer作為教師模型,因為它們在2D圖像領域表現出色,并且作者認為它們可以學習遷移的3D特征。
ACT框架包括以下主要部分:
-
預訓練的2D圖像或語言Transformer:作為基礎
Transformer模型,具有豐富的特征表示能力。作者選擇了先進的2DTransformer模型作為基礎模型,例如VisionTransformers(ViTs) 或者語言模型(如BERT)。訓練:使用大規模的2D圖像或語言數據集進行預訓練,通過自監督學習任務(如自編碼器或掩碼建模)來學習模型的特征表示能力。
-
3D自動編碼器:通過自監督學習,將2D圖像或語言Transformer調整為3D自動編碼器,用于學習3D幾何特征。作者將預訓練的2D圖像或語言
Transformer模型轉換為3D自動編碼器。通過將2D模型的參數復制到3D模型中,并添加適當的層或模塊來處理3D數據。使用3D數據集進行自監督學習,例如預測點云數據的遮擋部分、點云重建或其他3D任務。通過自監督學習任務,3D自動編碼器可以學習到3D數據的幾何特征。
-
跨模態教師模型:將預訓練的3D自動編碼器作為跨模態教師模型,通過掩碼建模的方式將潛在特征傳遞給3D
Transformer學生模型。特征傳遞:通過掩碼建模的方式,將3D自動編碼器的潛在特征傳遞給3D
Transformer學生模型。教師模型生成的潛在特征被用作學生模型的蒸餾目標,以引導學生模型學習更好的3D表示。 -
3D Transformer學生模型:接收來自教師模型的潛在特征,并用于學習3D數據的表示。
特征蒸餾:學生模型通過特征蒸餾的方式,利用教師模型的潛在特征作為監督信號,從而學習到更準確和具有豐富語義的3D表示。
這種設計和實現帶來了多個好處:
- ACT框架能夠實現跨模態的知識傳遞,將來自圖像領域的知識應用于3D數據中的表示學習,提高了3D任務的性能。
-
通過使用預訓練的2D圖像
Transformer作為教師模型,ACT能夠利用圖像領域已有的豐富特征表示,提供更有語義的特征編碼。 - 自編碼和掩碼建模任務使得學生模型能夠通過無監督學習捕捉3D數據中的重要特征,從而更好地泛化到不同的下游任務。
總的來說,ACT框架的核心創新在于將自監督學習和特征蒸餾方法應用于3D數據中,實現了知識傳遞和表示學習的改進,為跨模態學習和深度學習模型的發展提供了新的思路和方法。
摘要
深度學習的成功在很大程度上依賴于具有全面標簽的大規模數據,在獲取3D數據方面比2D圖像或自然語言更昂貴且耗時。這促使我們有可能利用用于不同模態知識轉移的以3D數據為基礎的預訓練模型作為教師。
本文以統一的知識蒸餾方式重新考慮了掩碼建模,并且展示了基于2D圖像或自然語言預訓練的基礎Transformer模型如何通過訓練作為跨模態教師的自編碼器(ACT)來幫助無監督學習的3D表示學習。
-
預訓練的
Transformer模型通過使用離散變分自編碼的自監督來作為跨模態的3D教師進行轉移,在此過程中,Transformer模型被凍結并進行提示調整,以實現更好的知識傳承。 -
由3D教師編碼的潛在特征被用作掩碼點建模的目標,其中暗知識被提煉到作為基礎幾何理解的3D
Transformer學生中。
預訓練的ACT 3D學習者在各種下游基準測試中實現了最先進的泛化能力,例如在ScanObjectNN上的 %整體準確率。
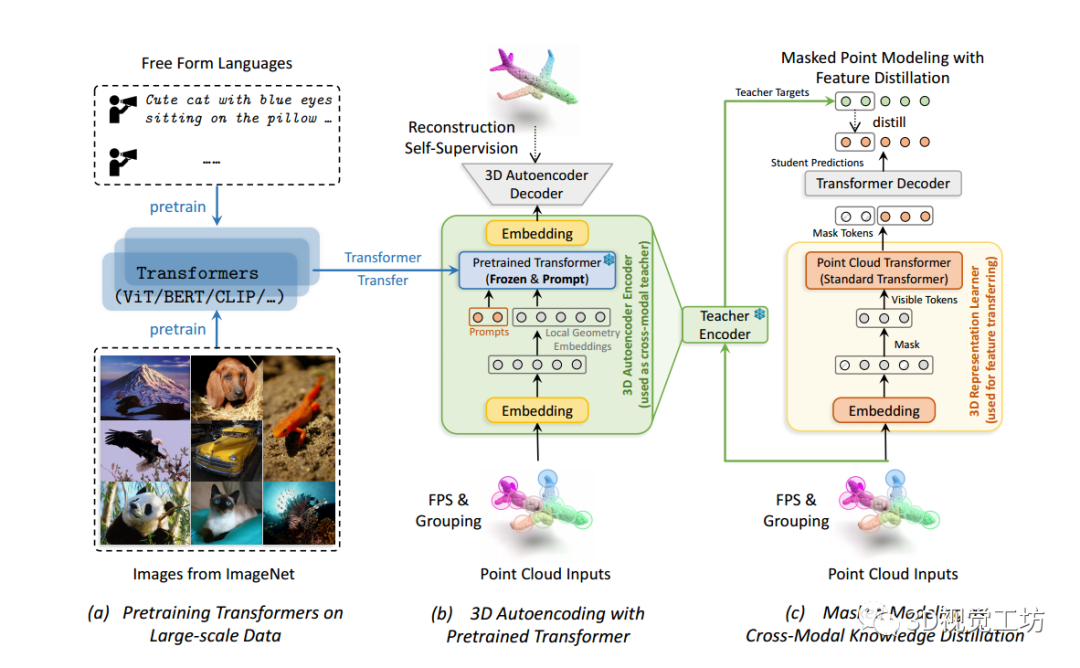
圖1
ACT框架的概述。
- (a)
ACT利用在大規模數據上預訓練的Transformer模型,例如使用2D圖像預訓練的ViT或使用語言預訓練的BERT。- (b)
ACT的第一階段(第4.1節),預訓練的Transformer模型通過帶提示的自監督3D自編碼進行微調。- (c)
ACT的第二階段(第4.2節),3D自編碼器編碼器被用作跨模態教師,將潛在特征編碼為掩碼點建模目標,用于3DTransformer學生的表示學習。
一、引言
近年來,數據驅動的深度學習在人工智能系統中得到廣泛應用。計算硬件的進步極大地推動了機器智能的發展,并促進了一種新興的范式,即基于廣泛數據訓練的模型的知識轉移。
- 自然語言處理 (NLP) 取得了巨大的成功,其中的模型旨在通過對極大規模數據進行自監督學習來獲取通用表示。
-
自從
Transformer在視覺領域取得成功后,人們已經做出了許多努力,將這種趨勢從NLP領域擴展到基于2D視覺理解的基礎模型中。
與2D視覺和NLP相比,基于基礎的視覺計算在3D社區中發展滯后。提出以下問題:是什么使得3D表示學習比2D視覺或NLP更具挑戰性?
從以下三個角度提供一些分析性答案:
i. 架構不統一。先驅性架構如PointNet只能對3D坐標進行編碼,而無法應用于在NLP和2D視覺中取得成功的掩碼去噪自編碼(DAE)。然而,Transformer架構現在已經彌補了這種架構上的差距,實現了跨所有模態格式的統一表示,并為擴展3D中的DAE帶來了巨大潛力。
ii. 數據稀缺。與圖像和自由形式語言相比,收集和標注3D或4D數據更加困難,通常需要更昂貴且密集的工作。此外,考慮到數據規模,3D數據嚴重匱乏。這促使了跨模態知識轉移的使用。最近的研究要么與其他模態一起進行聯合訓練以實現更有效的對比,要么直接對在圖像數據上預訓練的2D Transformers進行微調。
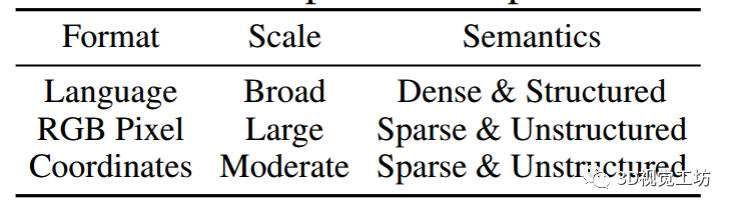
iii. 模式差異。表1顯示了語言、2D圖像和3D點云的數據模式比較。可以觀察到:
- (i)3D點云通常是非結構化的,包含稀疏語義,不同于語言。這導致在點云上進行掩碼去噪自編碼更加困難;
- (ii)2D圖像在網格上均勻分布,而3D點云則是從對象表面不規則采樣。這種結構上的差異導致了單模態增強和跨模態對應的對比目標構建的困難;
- (iii)如何設計具有豐富語義的更好表示成為自監督3D理解的主要目標。
在上述分析的推動下,作者提出了將Autoencoders作為跨模態教師進行訓練。
-
ACT利用基于2D圖像或自然語言預訓練的基礎Transformers作為跨模態教師,具有豐富的知識和強大的表示能力。通過這種方式,3D中的數據稀缺問題得到緩解。 -
Transformer被用作通用的3D學習器,彌補了掩碼建模表示學習方面的架構差距。通過以自監督的方式在3D數據上微調預訓練的
Transformers作為自編碼器,Transformers可以將3D點云轉化為具有豐富語義的表示形式。為了保留和繼承預訓練的基礎知識,使用了提示微調。
因此,ACT使預訓練的Transformers成為自發的跨模態教師,為3D點云提供了語義豐富的掩碼建模目標。
-
由于預訓練的
Transformers被微調為3D自編碼器,在這種跨模態Transformer轉移過程中不需要任何圖像、語言數據或3D下游標注。 -
此外,由于調整后的
Transformers僅用作3DTransformer學生的教師,該方法在下游特征轉移過程中不會引入額外的計算或存儲成本。
此外,進行了各種任務的大量實驗證明了ACT預訓練3D Transformers具有出色的泛化性能。
-
例如,在
ScanObjectNN數據集上實現了平均準確率提高%。
據知,本文首次證明了預訓練的基礎Transformer可以幫助3D表示學習,而無需訪問任何2D、語言數據或3D下游標注。ACT是一個自監督的框架,可以推廣到其他模態和任務,期望這能夠推動更多類似ACT風格的表示學習的探索。
表1: 數據模式比較
二、相關背景
自監督的3D幾何處理表示學習
自監督的3D幾何處理表示學習目前在學術界引起了極大的興趣。
-
傳統方法是基于重建的幾何理解預任務構建的,例如點云部分重排序,方向估計,局部和全局重建,流一致性,變形和遮擋。
-
與此同時,Xie等人在
PointContrast中提出了學習增強點云之間的區分性視角一致性的方法。在這個方向上,還提出了許多相關工作。
最近,許多工作提出了應用點云Transformer的自編碼器(DAE)預訓練的方法,并取得了顯著的成功。
-
Yu等人通過擴展
BERT-style預訓練的思想,結合全局對比目標,開創了這個方向。 - Liu等人提出了添加一些噪聲點,并對每個掩碼位置的掩碼標記進行真假分類的方法,這與Selfie的模式相似,后者對掩碼圖像塊進行真假分類。
- Pang等人提出了通過對3D點云坐標進行掩碼建模,在點云上探索MAE的方法。
作者遵循這種DAE-style表示學習范式,但與之前的方法不同,工作旨在使用由預訓練基礎Transformer編碼的潛在特征作為掩碼建模目標。
跨模態的3D表示學習
跨模態的3D表示學習旨在利用除了3D點云之外的更多模態內在的學習信號,例如,2D圖像被認為具有豐富的上下文和紋理知識,而自由形式的語言則具有密集的語義信息。主流方法基于全局特征匹配的對比學習進行開發。
- 例如,Jing等人提出了一種判別性中心損失函數,用于點云、網格和圖像的特征對齊。
- Afham等人提出了一種在增強的點云和相應渲染的2D圖像之間進行的模態內和模態間對比學習框架。
通過利用幾何先驗信息進行密集關聯,另一項工作探索了細粒度的局部特征匹配。
- Liu等人提出了一種對比知識蒸餾方法,用于對齊細粒度的2D和3D特征。
- Li等人提出了一個簡單的對比學習框架,用于模態內和模態間的密集特征對比,并使用匈牙利算法進行更好的對應。
最近,通過直接使用經過監督微調的預訓練2D圖像編碼器取得了很大的進展。
- Image2Point 提出了通過卷積層膨脹來傳遞預訓練權重的方法。
- P2P 提出了將3D點云投影到2D圖像,并通過可學習的上色模塊將其作為圖像主干網絡的輸入。
一些工作也探索了預訓練基礎模型是否可以幫助3D學習。然而,本文作者的方法:
(1)不使用預訓練的2D或語言模型作為推斷的主干模型;
(2)在無下游3D標注的自監督預訓練過程中探索使用來自其他模態的預訓練基礎模型;
(3)不需要成對的點-圖像或點-語言數據。
除了2D圖像之外,還有一些工作提出利用自然語言進行對比的3D表示學習,零樣本學習,以及場景理解。
三、預備知識
3.1 基于Transformer的3D點云表示
與規則網格上的圖像不同,點云被認為是不規則和結構較弱的。許多工作致力于為點云數據設計深度學習架構,利用點集的排列和平移不變性進行特征學習。
-
不僅僅依賴于這樣的專門主干,還利用
Transformer主干,這樣更容易與其他模態(如圖像和語言)統一,并促進跨模態的知識傳遞。 -
使用專門的點網絡計算局部幾何塊嵌入,并將其饋送給
Transformer以輸出更有效的幾何表示。
局部幾何塊嵌入
假設有一個點云 ,其中N個坐標編碼在 笛卡爾空間中,
- 按照Yu等人(2022)的方法,首先使用最遠點采樣(FPS)選擇個種子點。
- 然后將點云 P 分組為 個鄰域 ,其中種子點集 的中心作為組的中心。每個鄰域包含 K 個點,這些點是通過搜索對應種子點的K個最近鄰點生成的。
- 在每個種子點 周圍計算局部幾何特征 ,通過在鄰域內對每個點的特征進行最大池化得到:
其中:
- 是一個具有參數 的點特征提取器,例如中的逐點MLP,是鄰域 中第 j 個鄰點 的特征。
-
將鄰域特征作為標記特征,用于輸入接下來的
Transformer塊。
Transformer點特征編碼
使用標準的Transformer塊作為編碼器,進一步轉換局部塊嵌入 ,其中C是嵌入大小。
按照Yu等人的方法,使用一個具有可學習參數ρ的兩層MLP 作為位置嵌入,應用于每個塊以實現穩定的訓練。
式中,MSA表示多頭自注意的交替層,LN表示分層范數,MLP為兩層,其中GELU為非線性。 是一種可學習的全局表示嵌入,以 作為其可學習的位置嵌入。
3.2 知識蒸餾:掩碼建模的統一視角
掩碼建模可以看作是經典自編碼器(DAE)的擴展,其中采用了掩碼損失,最近已經在語言模型和視覺領域進行了探索。
- 形式上,給定一個由 個 token 組成的序列 ,例如RGB圖像或點云數據的標記嵌入。
- 目標是訓練一個學生編碼器 來預測/重建來自教師編碼器 的輸出,其中教師可以是離散變分自編碼器(dVAE)或簡單的恒等映射。
通過這種方式,學生在教師的指導下學習數據中的深層知識。
-
為了損壞輸入數據,為每個位置生成一組掩碼 ,指示標記是否被掩碼。
-
使用可學習的損壞嵌入 來替換被掩碼的位置,將損壞的表示 輸入到編碼器或解碼器。這里,表示Hadamard乘積, 是指示函數。
在某個度量空間 中定義了距離函數 ,作為解碼器,目標是最小化以下距離:
解碼器隨著建模目標的不同而變化,例如,它是BERT的非線性投影,帶有softmax ,其中度量函數變成交叉熵。可以看作是掩模建模的統一公式。
因此,考慮如何在掩碼3D建模中建立一個知識淵博的老師是很自然的。作者的想法是利用2D或語言基礎模型中的跨模式教師。
四、ACT: 自編碼器作為跨模態教師
目標是通過預訓練的2D圖像或語言Transformer來促進3D表示學習,該模型具備從大規模數據中吸收的深層知識。
然而,3D點云與2D圖像或語言具有不同的結構,這使得細粒度知識的關聯變得困難。
為了解決這個問題,采用了一個兩階段的訓練過程。ACT框架的概述如圖1所示。
-
階段I:調整預訓練的2D或語言
Transformer作為3D自編碼器,通過自監督的提示調整來學習理解3D幾何。 -
階段II:使用預訓練的3D自編碼器作為跨模態教師,通過掩碼建模將潛在特征蒸餾到3D點云
Transformer學生中。
4.1 3D自編碼與預訓練基礎Transformer
Transformer是最近在各個領域中主導的架構,可以以統一的方式對任何模態的序列數據進行建模。
- 因此,可以直接使用預訓練的Transformer塊,將順序標記與輸入點云的3D位置嵌入一起進行輸入。
- 本文使用輕量級的DGCNN對點云進行處理,其中的邊緣卷積層通過參數 表示。
跨模態嵌入與提示
- 首先,使用DGCNN風格的補丁嵌入網絡對點云進行編碼,產生一組標記嵌入:。
-
然后,通過提示這些標記嵌入,并將其輸入到預訓練且凍結的
Transformer塊的D層中,例如2DTransformer:。在這里,使用 來表示 2DTransformer的第 層。
使用 個可學習的提示嵌入 ,應用于Transformer 的每一層。具體來說,Transformer的第 層 將隱含表示 從第 層轉換為 ,如下所示:
使用這種參數高效的快速調整策略,能夠調整預訓練的基礎Transformer,同時保留盡可能多的預訓練知識。
點云自編碼
另一個DGCNN網絡 用于從基礎Transformer嵌入的隱藏表示中提取局部幾何特征。然后,利用FoldingNet 對輸入點云進行重構。
將以上3D自編碼器作為離散變分自編碼器(dVAE)進行訓練,以最大化對數似然 。這里 表示原始和重構的點云。
整體優化目標是最大化證據下界(ELBO),當時成立:
其中:
- 表示離散的3D dVAE tokenizer;
- 是給定離散點標記的dVAE解碼器;
- 以自編碼方式重構輸入點云。
4.2 掩碼點建模作為跨模態的知識蒸餾
通過訓練3D自編碼器,預訓練Transformer的強表示被轉化為3D特征空間,使自編碼器自動成為一個跨模態教師。
將在4.1節中介紹的預訓練點云編碼器作為教師 ,將3D Transformer 作為學生。
通過掩碼建模作為跨模態知識蒸餾,最小化編碼后的教師特征與學生特征之間的負余弦相似度 :
五、實驗
5.1下游任務遷移學習
遷移學習設置
在分類任務中使用遷移學習的三種變體:
(a) FULL: 通過更新所有骨干和分類頭來微調預訓練模型。
(b) MLP- linear: 分類頭是單層線性MLP,只在微調時更新該分類頭參數。
(c) MLP-3: 分類頭是一個三層非線性MLP(與FULL中使用的相同),只在微調時更新這個頭的參數。
3D真實數據集分類
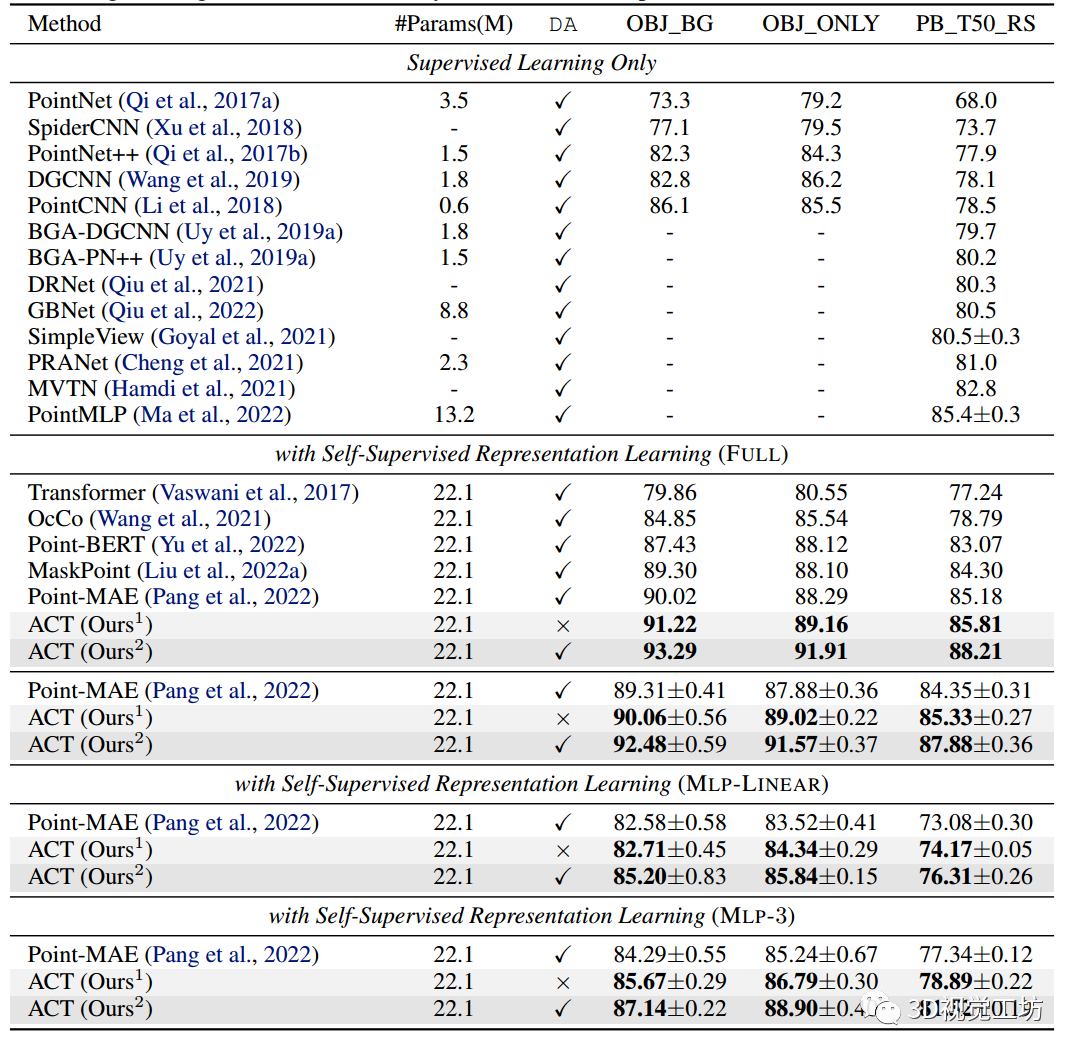
首先展示了在具有挑戰性的現實數據集ScanObjectNN上對3D形狀識別的評估。結果如表2所示,其中可以觀察到:
(i) 與FULL調優協議下從頭開始的Transformer基線相比,ACT在三個不同的ScanObjectNN基準測試上平均獲得了+10.4%的顯著改進。此外,通過簡單的點云旋轉,ACT實現了+11.9%的平均改進;
(ii) 與明確以三維幾何理解為目的設計的方法相比,ACT`始終取得更好的結果。
(iii) 與其他自監督學習(SSL)方法相比,在ScanObjectNN上,ACT在所有方法中實現了最好的泛化。此外,在ScanObjectNN上使用純3D Transformer架構的方法中,ACT成功地達到了最先進(SOTA)的性能,例如,在最具挑戰性的PB_T50_RS基準測試中,ACT比Point-MAE的準確率高出+3.0%。
表2:
ScanObjectNN上的分類結果。our1:沒有數據增強的訓練結果。Ours2:簡單點云旋轉訓練的結果。DA:在微調訓練期間使用數據增強。報告總體精度,即OA(%)。
3D場景分割
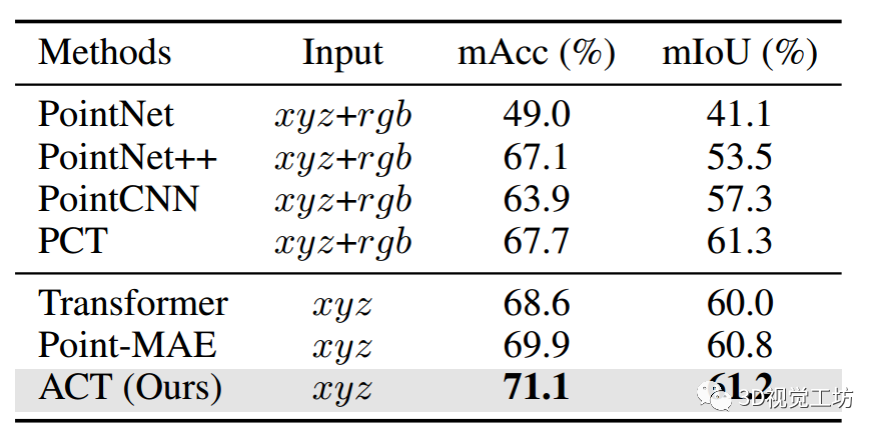
大規模3D場景的語義分割具有挑戰性,需要對上下文語義和局部幾何關系的理解。在表4中,報告了S3DIS數據集的結果。可以看到:
(i) ACT顯著提高了從零開始的基線,mAcc和mIoU分別提高了+2.5%和+1.2%。
(ii) ACT比SSL對應的Point-MAE分別高出+1.2%和+0.4%的mAcc和mIoU,在大場景數據集上顯示出優越的傳輸能力。
(iii) 僅使用幾何輸入xyz, ACT可以實現與使用xyz+rgb數據進行細致設計的架構相當或更好的性能,包括3d特定的Transformer架構。
表4:
S3DIS區域5上的語義分割結果。報告了所有類別的平均準確性和平均IoU,即mAcc(%)和mIoU(%)。使用Xyz:點云坐標。xyz+rgb:同時使用坐標和rgb顏色。
3D合成數據集分類
展示了在合成數據集ModelNet40上對三維形狀分類的評估。為了證明在有限的訓練樣例下ACT的數據效率特性,首先遵循Sharma & Kaul(2020)來評估 few-shot 學習。
從表5中,可以看到:
(i) 與從頭開始的FULL轉移基線相比,ACT在四種設置下分別帶來了+9.0%,+4.7%,+8.7%,+6.2%的顯著改進。
(ii) 與其他SSL方法相比,ACT始終實現最佳性能。
然后,在表3中展示了完整數據集上的結果,在表3中我們觀察到,與FULL協議下的從頭基線相比,ACT實現了+2.5%的準確率提高,并且結果與所有協議中的其他自監督學習方法相當或更好。
表3:
ModelNet40數據集上的分類結果。報告總體精度,即OA(%)。[ST]:標準Transformer架構。
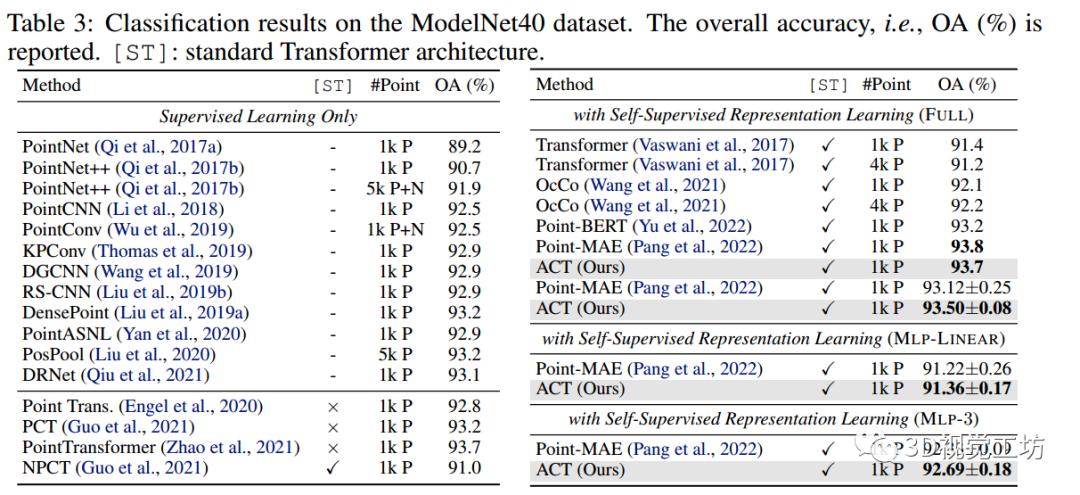
表5:在
ModelNet40上的Few-shot分類,報告了總體準確率(%)。
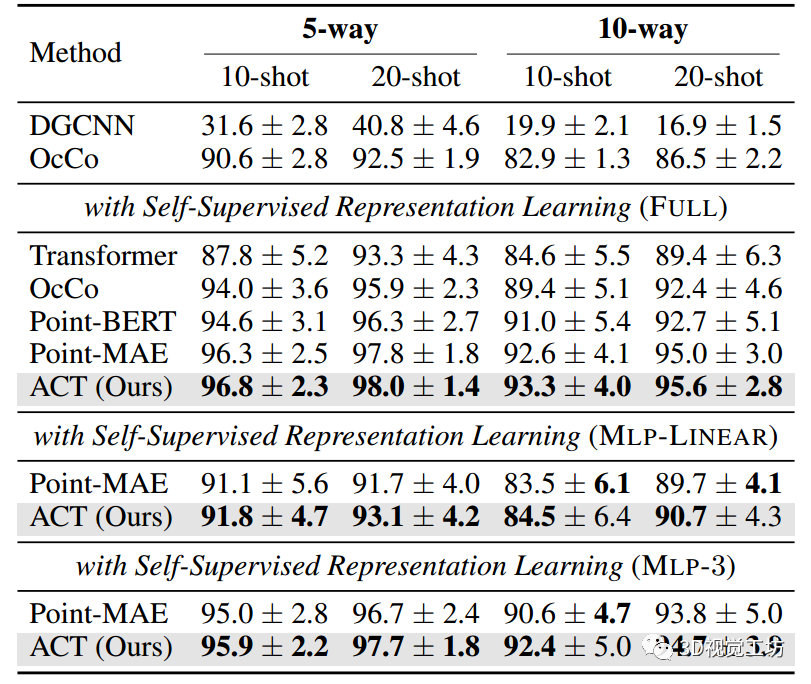
5.2 消融研究
解碼器深度
表6展示了使用不同解碼器深度的ACT在ScanObjectNN上的平均微調準確率。可以看出,性能對解碼器深度不敏感,我們發現具有2個塊的解碼器取得了最高的結果。
-
需要注意的是,當解碼器深度為0時,我們采用了類似BERT的掩碼建模架構,其中沒有解碼器,編碼器可以看到所有的標記,包括被掩碼的標記。
-
我們發現這導致了較差的結果,與在2D上觀察到的數據的低語義性需要一個非平凡解碼器的觀察一致。
表6: 預訓練解碼器深度的消融研究。
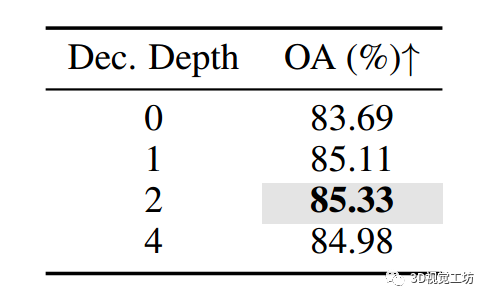
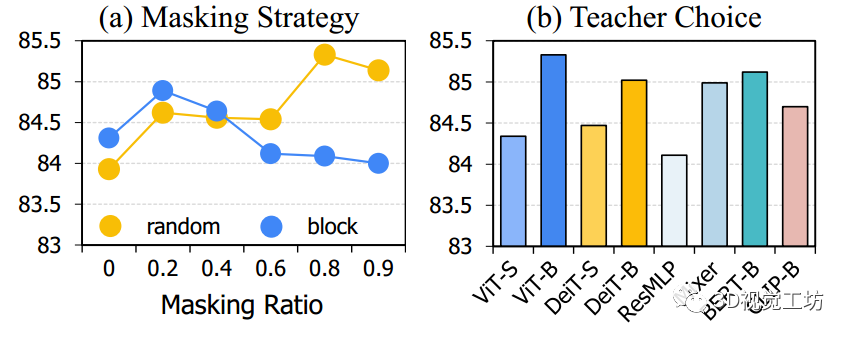
圖2: 掩碼比 消融研究和跨模
Transformer教師選擇。
掩碼策略和教師選擇
圖2(a)展示了使用不同掩碼策略在ScanObjectNN上的平均微調準確率。
- 可以觀察到,使用隨機掩碼的較高掩碼比例會產生更好的結果,而塊掩碼則對較低掩碼比例更為適用。
- 需要注意的是,當掩碼比例為零時,對所有標記使用基準知識蒸餾,并且導致性能較差。
-
圖2(b)展示了使用不同教師
Transformer的ACT在ScanObjectNN上的平均微調準確率,包括VisionTransformers、全MLP架構、語言模型和視覺語言模型。觀察到較大的教師模型始終能夠獲得更好的性能。
此外,令人驚訝的是,ACT使用語言模型BERTB(即BERTbase)作為跨模態教師,可以達到平均準確率85.12±0.54%(最高可達85.88%),這表明ACT可以推廣到任何模態。
表7: dVAE標記器不同訓練策略的消融研究。
- 報告了F-Score,使用l1范數和l2范數的倒角距離,即CD- l1和CD- l2
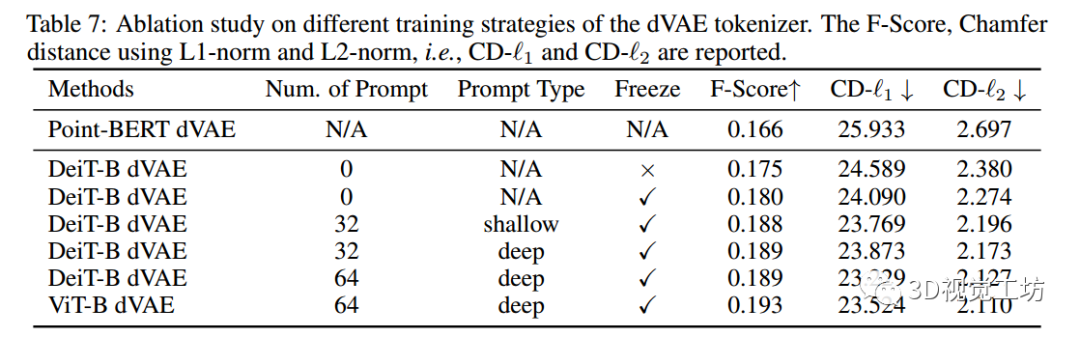
3D自編碼器訓練
表7展示了使用預訓練的2D圖像Transformer進行不同訓練配置的3D自編碼器的重構結果。觀察到:
(i)帶有預訓練圖像Transformer的3D dVAE模型在重構結果上明顯優于Point-BERT。這表明預訓練的2D圖像Transformer具有強大的對3D的表示能力。
(ii) 提示調整或凍結模型可以獲得比完全調整更好的結果,我們認為這是因為某些預訓練的2D知識被遺忘了,而提示調整有效地解決了這個問題。重構可視化結果可以在附錄D中找到。
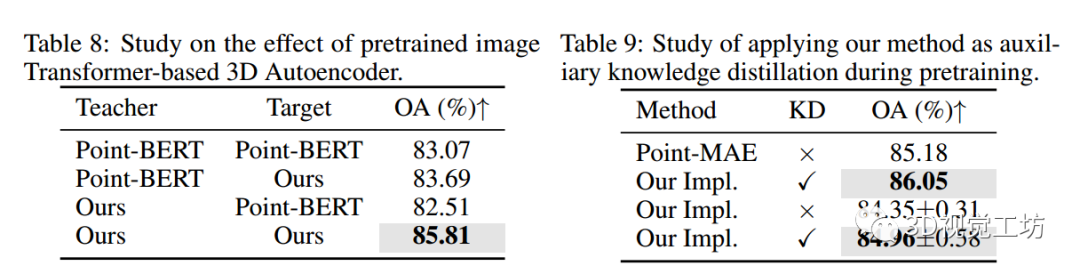
六、討論
6.1 是所需要更強大的標記器嗎?
為了了解預訓練的2D圖像Transformer在3D dVAE模型中的必要性,我們用不同的dVAE教師和掩模建模配置進行了實驗。
從表8中,可以看到:
(i) 當使用沒有預訓練的2D圖像變壓器的Point-BERT dVAE模型時,通過提取潛在特征而不是離散令牌,可以實現+0.62%的改進。分析認為,離散令牌識別學習起來更具挑戰性3D數據。
(ii) 當使用Point-BERT離散標記作為掩碼建模目標時,通過應用帶有預訓練2D圖像Transformer的dVAE模型,得到了最差的性能。這表明,無論標記器有多強大,離散標記都不適用于語義稀疏的點云數據。
(iii) 當使用ACT時,性能顯著提高。這表明,帶有預訓練2D圖像Transformer`的3D dVAE能夠編碼具有豐富語義的特征,更適合于掩碼點建模。
表10: 二維圖像轉換器在dVAE模型中不同位置嵌入的研究。
(a)無:不使用位置嵌入。(b) 2D/z:僅使用2D xy平面坐標的位置嵌入。
(c) 3D:所有3D xyz坐標的位置嵌入。
報告了F-Score,使用l1范數和l2范數的倒角距離,即CD- l1和CD-l2,以及
ScanObjectNN上的OA。

6.2 ACT是否可以用作輔助知識蒸餾方法?
由于ACT使用編碼特征作為掩碼建模目標,它具有將我們的方法作為輔助特征蒸餾的潛力。
表9顯示了在Point-MAE模型中,使用ACT作為中間特征的輔助深度監督訓練的結果,其中ACT編碼的潛在特征被蒸餾到Point-MAE的編碼器特征中。
可以觀察到,ACT能夠顯著提高Point-MAE在ScanObjectNN上的準確率,提高了0.87%,表明ACT作為一種知識蒸餾方法具有可擴展性和有效性。
6.3 2D Vision Transformer如何理解3D點云?
為了更好地理解2D圖像Transformer如何通過自編碼器訓練理解3D輸入,研究了ViT-B在我們的ACT dVAE模型中使用的位置嵌入的效果。從表10可以看出:
(i) 在沒有任何位置嵌入的情況下,預訓練的ViT仍然可以學習可遷移的3D特征(準確率為84.21±0.45%)。我們認為這是因為位置幾何信息已經包含在輸入的3D坐標中,預訓練的2D Transformer可以通過幾何特征純粹處理3D數據,而不需要顯式的位置提示。
(ii) 當僅使用2D xy平面坐標的位置嵌入時,準確率顯著提高了0.89%。我們認為2D位置嵌入是為了適應凍結的圖像Transformer而學習的,使圖像Transformer能夠將3D輸入編碼為具有高語義的預訓練2D特征空間。
(iii) 當使用所有3D坐標進行位置嵌入時,2D圖像Transformer成功利用了附加坐標信息來進行更好的特征編碼。
七、總結
本文提出了一種自監督學習框架ACT,通過預訓練的基礎Transformer進行掩碼建模,將特征蒸餾傳遞給3D Transformer學生模型。ACT首先通過自監督的3D自編碼將預訓練的基礎Transformer轉化為跨模態的3D教師模型。
然后,來自調整后的3D自編碼器的語義豐富的潛在特征被用作3D Transformer學生模型的掩碼建模目標,展現了在各種下游3D任務上卓越的泛化性能。作為一種通用的自監督學習框架,相信ACT可以輕松擴展到除3D數據之外的其他模態。
這種自監督方式展示了跨模態知識轉移的巨大潛力,這可能在數據驅動的深度學習時代極大地促進了基礎建模的發展。
附錄:
可視化
圖3比較了基于2D圖像Transformer的3D dVAE和Point-BERT 3D dVAE模型的重建結果。
- 實驗結果表明,所設計的三維自編碼器能夠高質量地重建物體細節。
- 對于一些相對簡單的物體,如第二行矩形表,我們的方法和Point-BERT都可以很好地重建它們。然而,對于細節相對復雜的點集,如第三排的薄架子和扶手椅,我們的方法仍然可以用詳細的局部幾何信息重建物體。
- 這些定性觀察結果與表7中的定量結果一致。
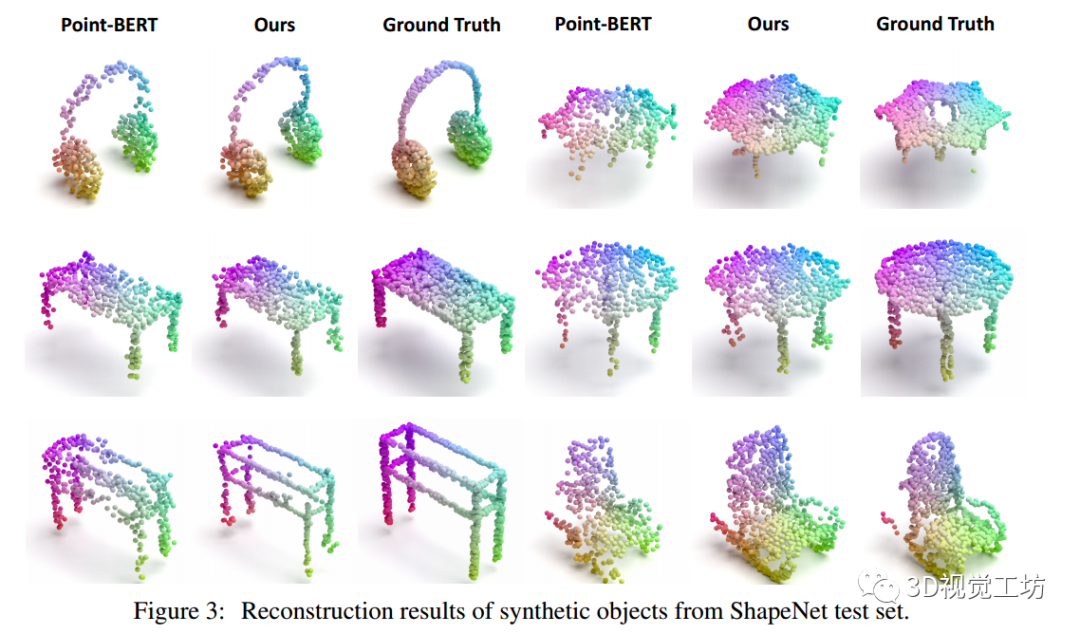
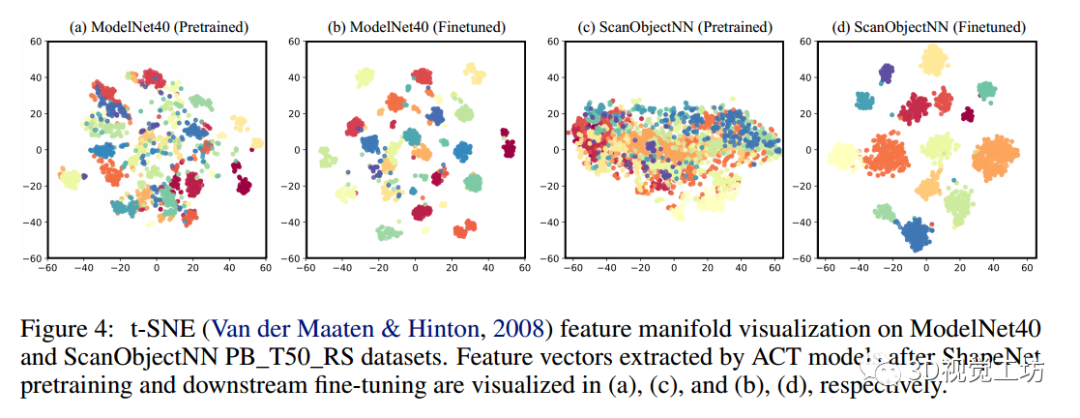
圖4顯示了t-SNE在ShapeNet上進行預訓練并在ModelNet40和ScanObjectNN PB_T50_RS數據集上進行微調后的模型特征可視化。
可以觀察到:
(i) 在ShapeNet上進行預訓練后,由于相對較小的域間隙,模型已經可以在ModelNet上產生判別特征。
(ii) 在對下游數據集進行微調后,在ModelNet40和具有挑戰性的ScanObjectNN數據集上都獲得了判別特征。
(iii) Shapenet預訓練ACT在ScanObjectNN上提取的特征分布看起來不那么判別性。我們認為有兩個原因導致它: (i)合成的ShapeNet和真實的ScanObjectNN數據集之間的大域差距,以及(ii) ACT使用的不是對比損失,例如區分(例如,Point-BERT使用的MoCo損失)。有趣的是,這在ScanObjectNN上產生了更好的泛化性能(ACT的OA為88.21%,而Point-BERT為83.07%)。
-
模型
+關注
關注
1文章
3305瀏覽量
49217 -
數據集
+關注
關注
4文章
1209瀏覽量
24829 -
Transformer
+關注
關注
0文章
145瀏覽量
6047
原文標題:ICLR2023 | 2D Transformer 可以幫助3D表示學習嗎?
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
針對顯示屏的2D/3D觸摸與手勢開發工具包DV102014
如何同時獲取2d圖像序列和相應的3d點云?
2D到3D視頻自動轉換系統
適用于顯示屏的2D多點觸摸與3D手勢模塊
如何把OpenGL中3D坐標轉換成2D坐標
阿里研發全新3D AI算法,2D圖片搜出3D模型
基于神經網絡的2D到3D的機器學習
探討一下2D和3D拓撲絕緣體
2D與3D視覺技術的比較
一文了解3D視覺和2D視覺的區別
有了2D NAND,為什么要升級到3D呢?






 工商網監
工商網監
評論