") Spark 3.4用于分布式模型訓(xùn)練和大規(guī)模模型推理
Spark 3.4用于分布式模型訓(xùn)練和大規(guī)模模型推理
Apache Spark是一個業(yè)界領(lǐng)先的平臺,用于大規(guī)模數(shù)據(jù)的分布式提取、轉(zhuǎn)換和加載( ETL )工作負載。隨著深度學(xué)習(xí)( DL )的發(fā)展,許多 Spark 從業(yè)者試圖將 DL 模型添加到他們的數(shù)據(jù)處理管道中,以涵蓋各種用例,如銷售預(yù)測、內(nèi)容推薦、情緒分析和欺詐檢測。
然而,結(jié)合 DL 培訓(xùn)和推理,從歷史上看,大規(guī)模數(shù)據(jù)一直是 Spark 用戶面臨的挑戰(zhàn)。大多數(shù) DL 框架都是為單節(jié)點環(huán)境設(shè)計的,它們的分布式訓(xùn)練和推理 API 通常是經(jīng)過深思熟慮后添加的。
為了解決單節(jié)點 DL 環(huán)境和大規(guī)模分布式環(huán)境之間的脫節(jié),有多種第三方解決方案,如 Horovod-on-Spark、TensorFlowOnSpark 和 SparkTorch,但由于這些解決方案不是在 Spark 中本地構(gòu)建的,因此用戶必須根據(jù)自己的需求評估每個平臺。
隨著 Spark 3.4 的發(fā)布,用戶現(xiàn)在可以訪問內(nèi)置的 API,用于分布式模型訓(xùn)練和大規(guī)模模型推理,如下所述。
分布式培訓(xùn)
對于分布式培訓(xùn),有一個新的 TorchDistributor PyTorch 的 API,它遵循 spark-tensorflow-distributorTensorFlow 的 API。這些 API 通過利用 Spark 的屏障執(zhí)行模式,在 Spark executors 上生成分布式 DL 集群節(jié)點,從而簡化了將分布式 DL 模型訓(xùn)練代碼遷移到 Spark 的過程。
一旦 Spark 啟動了 DL 集群,控制權(quán)就基本上通過main_fn傳遞給TorchDistributorAPI
如下面的代碼所示,使用這個新的 API 在 Spark 上運行標(biāo)準(zhǔn)的分布式 DL 培訓(xùn)只需要進行最小的代碼更改。
from pyspark.ml.torch.distributor import TorchDistributor
def main_fn(checkpoint_dir):
# standard distributed PyTorch code
...
# Set num_processes = NUM_WORKERS * NUM_GPUS_PER_WORKER
output_dist = TorchDistributor(num_processes=2, local_mode=False, use_gpu=True).run(main_fn, checkpoint_dir)
一旦啟動,運行在執(zhí)行器上的流程就依賴于其各自 DL 框架的內(nèi)置分布式訓(xùn)練 API 。將現(xiàn)有的分布式訓(xùn)練代碼移植到 Spark 應(yīng)該很少或不需要修改。然后,這些進程可以在訓(xùn)練期間相互通信,還可以直接訪問與 Spark 集群相關(guān)的分布式文件系統(tǒng)(圖 1 )。
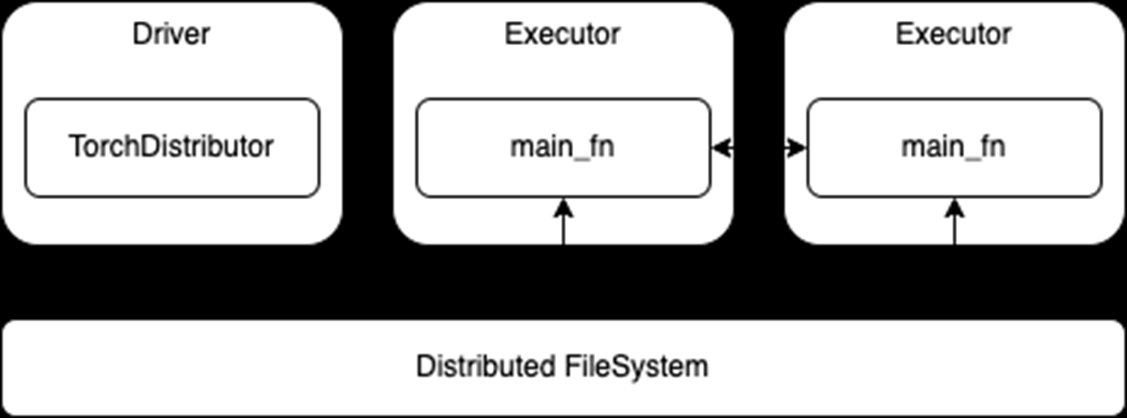 圖 1 。分布式培訓(xùn)使用TorchDistributorAPI
圖 1 。分布式培訓(xùn)使用TorchDistributorAPI
然而,這種遷移的方便性也意味著這些 API 不使用 Spark RDD 或 DataFrames 進行數(shù)據(jù)傳輸。雖然這消除了在 Spark 和 DL 框架之間轉(zhuǎn)換或序列化數(shù)據(jù)的任何需要,但它也要求在啟動訓(xùn)練作業(yè)之前完成任何 Spark 預(yù)處理并持久化到存儲中。主要訓(xùn)練功能可能還需要適于從分布式文件系統(tǒng)而不是本地存儲讀取。
分布式推理
對于分布式推理,有一個新的predict_batch_udfAPI ,它建立在Spark Pandas UDF以便為 DL 模型推斷提供更簡單的接口。 pandas 與基于行的 UDF 相比, UDF 提供了一些優(yōu)勢,包括通過Apache Arrow以及通過Pandas。有關(guān)詳細信息,請參閱Introducing Pandas UDF for PySpark.
然而,盡管 pandas UDF API 可能是 ETL 用例的一個很好的解決方案,但它仍然不適合 DL 推理用例。首先, pandas UDF API 將數(shù)據(jù)表示為 pandas 系列或數(shù)據(jù)幀,這同樣適用于執(zhí)行 ETL 操作,如選擇、排序、數(shù)學(xué)轉(zhuǎn)換和聚合。
然而,大多數(shù) DL 框架都期望NumPy數(shù)組或標(biāo)準(zhǔn) Python 數(shù)組作為輸入,這些數(shù)組通常由自定義張量變量包裝。因此,pandas UDF 實現(xiàn)至少需要將傳入的 pandas 數(shù)據(jù)轉(zhuǎn)換為 NumPy 數(shù)組。不過,根據(jù)用例和數(shù)據(jù)集的不同,準(zhǔn)確的轉(zhuǎn)換可能會有很大的差異。
其次, pandas UDF API 通常在數(shù)據(jù)分區(qū)上運行,數(shù)據(jù)分區(qū)的大小由數(shù)據(jù)集的原始寫入者或分布式文件系統(tǒng)決定。因此,很難對傳入的數(shù)據(jù)進行適當(dāng)?shù)呐幚硪赃M行優(yōu)化計算。
最后,仍然存在在 Spark 執(zhí)行器和任務(wù)之間加載 DL 模型的問題。在正常的 Spark ETL 工作中,工作負載遵循函數(shù)編程范式,其中可以對數(shù)據(jù)應(yīng)用無狀態(tài)函數(shù)。然而,對于 DL 推理,預(yù)測函數(shù)通常需要從磁盤加載其 DL 模型權(quán)重。
Spark 具有通過任務(wù)序列化和廣播變量將變量從驅(qū)動程序序列化到執(zhí)行器的能力。然而,這兩者都依賴于 Python pickle 序列化,這可能不適用于所有 DL 模型。此外,如果操作不當(dāng),加載和序列化非常大的模型可能會帶來極高的性能成本。
解決當(dāng)前限制
為了解決這些問題predict_batch_udf引入了以下方面的標(biāo)準(zhǔn)化代碼:
將 Spark 數(shù)據(jù)幀轉(zhuǎn)換為 NumPy 數(shù)組,因此最終用戶 DL 推理代碼不需要從 pandas 數(shù)據(jù)幀進行轉(zhuǎn)換。
為 DL 框架批處理傳入的 NumPy 數(shù)組。
在執(zhí)行器上加載模型,避免了任何模型序列化問題,同時利用 Sparkspark.python.worker.reuse配置以在 Spark 執(zhí)行器中緩存模型。
下面的代碼演示了這個新的 API 如何隱藏將 DL 推理代碼轉(zhuǎn)換為 Spark 的復(fù)雜性。用戶只需定義make_predict_fn函數(shù),使用標(biāo)準(zhǔn)的 DL API 加載模型并返回predict作用然后predict_batch_udf函數(shù)生成一個標(biāo)準(zhǔn)PandasUDF,負責(zé)處理幕后的其他一切。
from pyspark.ml.functions import predict_batch_udf def make_predict_fn(): # load model from checkpoint import torch device = torch.device("cuda") model = Net().to(device) checkpoint = load_checkpoint(checkpoint_dir) model.load_state_dict(checkpoint['model']) # define predict function in terms of numpy arrays def predict(inputs: np.ndarray) -> np.ndarray: torch_inputs = torch.from_numpy(inputs).to(device) outputs = model(torch_inputs) return outputs.cpu().detach().numpy() return predict # create standard PandasUDF from predict function mnist = predict_batch_udf(make_predict_fn, input_tensor_shapes=[[1,28,28]], return_type=ArrayType(FloatType()), batch_size=1000) df = spark.read.parquet("/path/to/test/data") preds = df.withColumn("preds", mnist('data')).collect()
請注意,此 API 使用標(biāo)準(zhǔn) Spark DataFrame 進行推斷,因此執(zhí)行器將從分布式文件系統(tǒng)讀取數(shù)據(jù)并將該數(shù)據(jù)傳遞給predict函數(shù)(圖 2 )。這也意味著,根據(jù)需要,數(shù)據(jù)的任何處理都可以與模型預(yù)測一起進行。
還要注意,這是一個data-parallel體系結(jié)構(gòu),其中每個執(zhí)行器加載模型并對數(shù)據(jù)集的各自部分進行預(yù)測,因此模型必須適合執(zhí)行器內(nèi)存。
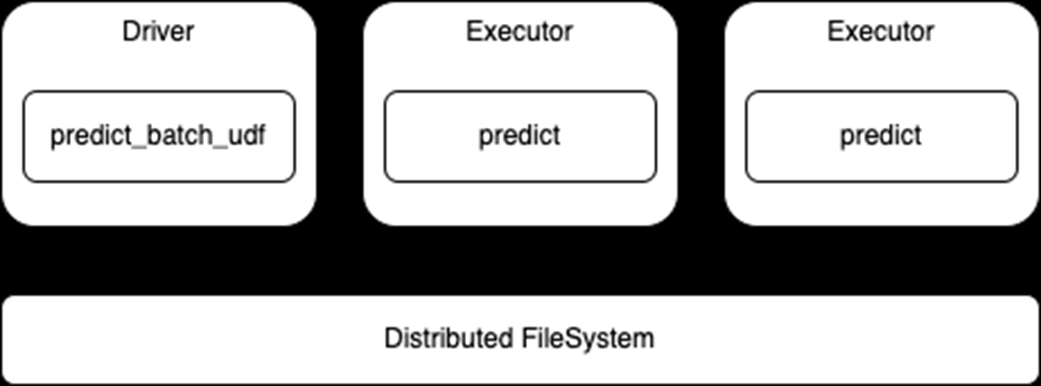 圖 2 :分布式推理使用predict_batch_udfAPI
圖 2 :分布式推理使用predict_batch_udfAPI
Spark 深度學(xué)習(xí)的端到端示例
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5076瀏覽量
103728 -
人工智能
+關(guān)注
關(guān)注
1796文章
47683瀏覽量
240302 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5516瀏覽量
121553
發(fā)布評論請先 登錄
相關(guān)推薦
名單公布!【書籍評測活動NO.30】大規(guī)模語言模型:從理論到實踐
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
【大語言模型:原理與工程實踐】大語言模型的基礎(chǔ)技術(shù)
分布式對象調(diào)試中的事件模型
基于代理模型的分布式聚類算法
大規(guī)模分布式機器學(xué)習(xí)系統(tǒng)分析

如何向大規(guī)模預(yù)訓(xùn)練語言模型中融入知識?

Google Brain和DeepMind聯(lián)手發(fā)布可以分布式訓(xùn)練模型的框架
如何使用TensorFlow進行大規(guī)模和分布式的QML模擬
超大Transformer語言模型的分布式訓(xùn)練框架

探究超大Transformer語言模型的分布式訓(xùn)練框架
DGX SuperPOD助力助力織女模型的高效訓(xùn)練
使用NVIDIA DGX SuperPOD訓(xùn)練SOTA大規(guī)模視覺模型
基于PyTorch的模型并行分布式訓(xùn)練Megatron解析






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論